Urdu Katib Handwritten Dataset: A Historical Document Dataset for Offline Urdu Handwritten Text Recognition with CRNN-Based Baseline Evaluation
Pith reviewed 2026-06-26 21:12 UTC · model grok-4.3
The pith
The Urdu Katib Handwritten Dataset supplies the first offline benchmark of historical Nastalique Urdu lines for CRNN-based recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
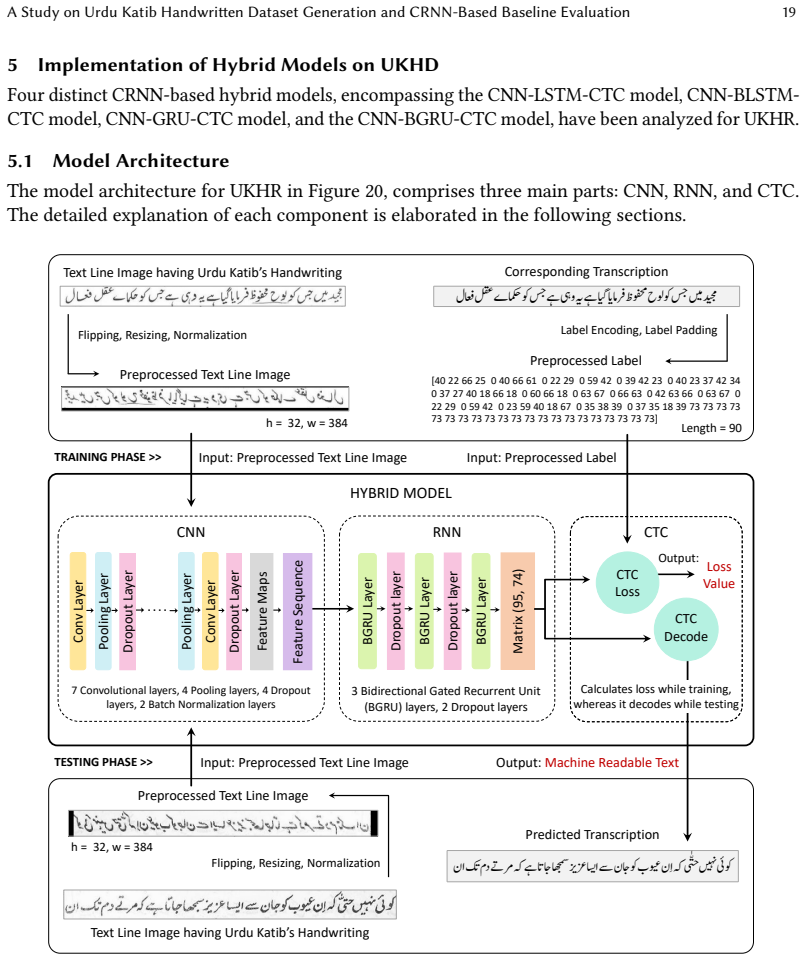
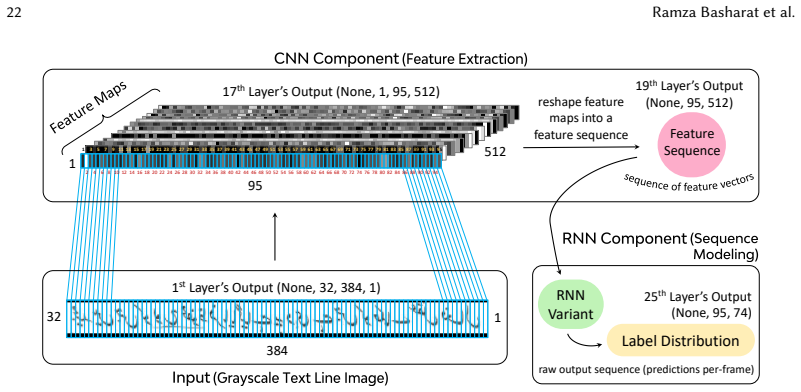
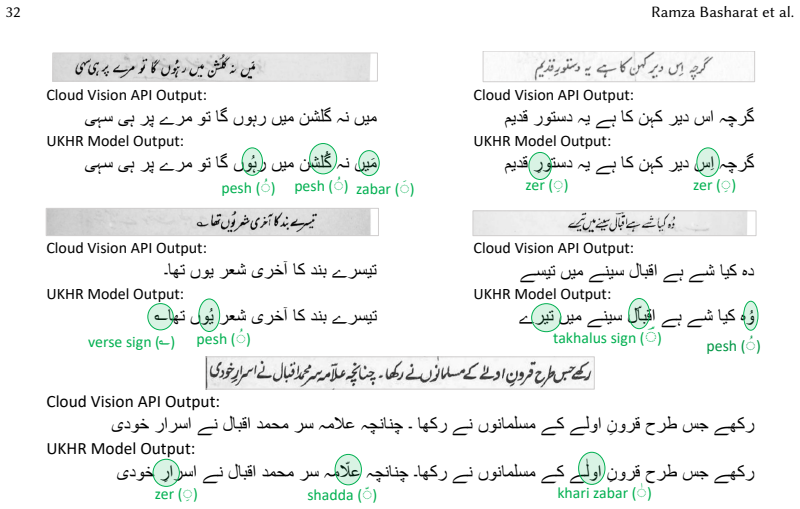
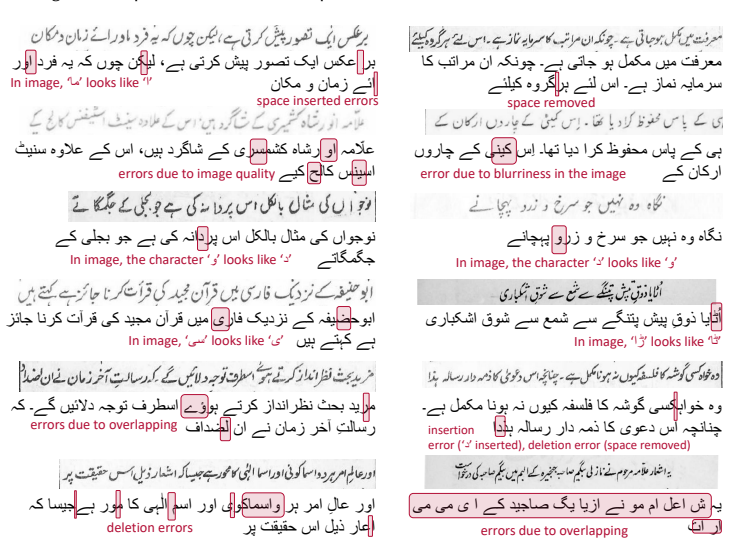
The authors create the UKHD as the first offline Urdu handwritten text lines dataset from historical Katib materials, covering diverse flat nib variations in Nastalique calligraphy, and show that among CRNN models the CNN-BGRU-CTC architecture achieves the most robust performance with low CER and WER.
What carries the argument
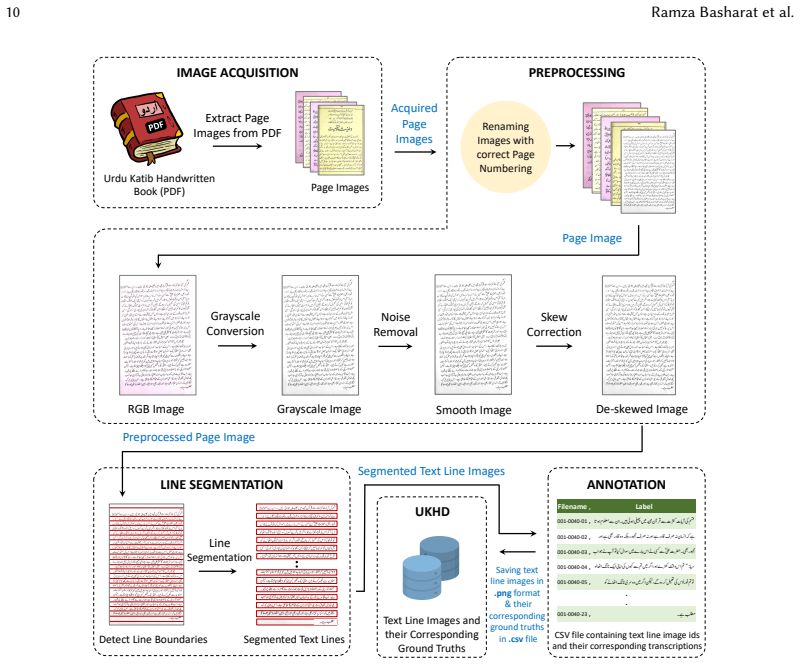
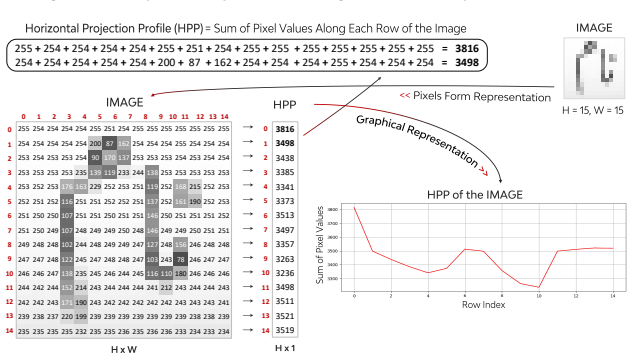
The UKHD dataset of historical Nastalique calligraphic text lines, used to benchmark CRNN hybrid models for Urdu handwriting recognition.
If this is right
- Recognition models can now be trained and tested on authentic historical Urdu samples rather than synthetic or scarce data.
- The CNN-BGRU-CTC model supplies a reproducible baseline architecture for subsequent Urdu text recognition work.
- Automated systems developed from this resource can support digitization and long-term preservation of Urdu literary materials.
- Curation methods used for UKHD can guide creation of comparable datasets for other cursive historical scripts.
Where Pith is reading between the lines
- Supplementing UKHD with contemporary Urdu handwriting samples would likely be needed before claiming coverage of all writing styles.
- Replacing the recurrent layers in the best-performing model with attention or transformer components could be tested directly on the released data.
- The same historical-document sourcing strategy could accelerate benchmark creation for other low-resource cursive scripts facing similar data shortages.
Load-bearing premise
The historical Katib materials encompass a diverse range of flat nib writing variations in the Nastalique calligraphic style that are sufficient to support development of robust general-purpose Urdu handwritten text recognition systems.
What would settle it
A new collection of Urdu handwriting samples drawn from non-Katib sources or different historical periods on which models trained only on UKHD produce markedly higher CER and WER would indicate the dataset does not yet support general-purpose recognition.
Figures
















read the original abstract
Automatic Handwritten Text Recognition (HTR) is inherently a challenging task, and its complexity is further increased when dealing with cursive scripts. Although significant efforts have been made on various cursive scripts, research regarding Urdu Handwritten Text Recognition (UHTR) has been relatively limited. This lag of research is primarily due to the unique challenges posed by its script, and the scarcity and unavailability of benchmark datasets. Therefore, to advance research in UHTR, this study presents a specialized real dataset called the Urdu Katib Handwritten Dataset (UKHD). To the best of our knowledge, this is the first offline Urdu handwritten text lines dataset specifically curated from the materials written by Katibs in historical times. It encompasses a diverse range of flat nib writing variations in the Nastalique calligraphic style. Additionally, the effectiveness of different CRNN-based hybrid models has been evaluated to identify the optimal architecture for Urdu Katib Handwriting Recognition (UKHR). Among the analyzed models, the CNN-BGRU-CTC model showed more robust performance, with low Character Error Rate (CER) and Word Error Rate (WER). This research work aims to support and encourage the research community in developing a robust recognition system for preserving Urdu handwritten literature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Urdu Katib Handwritten Dataset (UKHD), presented as the first offline handwritten text-line dataset curated from historical Katib materials in Nastalique calligraphic style. It evaluates multiple CRNN-based hybrid architectures for Urdu handwritten text recognition and concludes that the CNN-BGRU-CTC model exhibits the most robust performance, characterized by low CER and WER.
Significance. The curation of a specialized historical dataset from Katib sources addresses a documented scarcity of real-world benchmarks for Urdu HTR. If released with complete statistics, splits, and reproducible baselines, the resource could enable targeted progress on Nastalique-style recognition and support preservation of Urdu literature. The empirical model comparison supplies initial architecture rankings, though the absence of quantitative results limits evaluation of claimed robustness.
major comments (2)
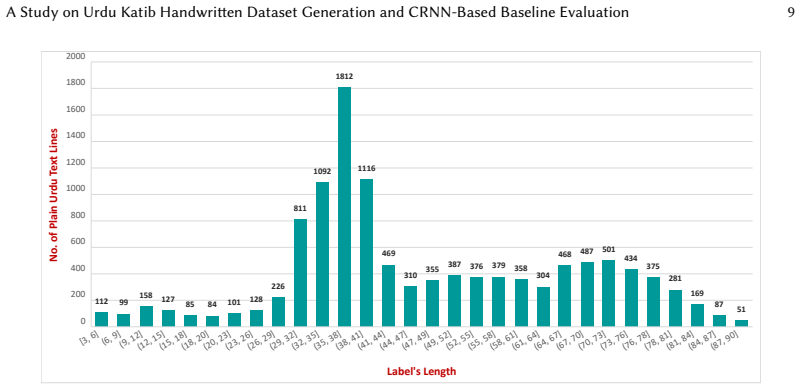
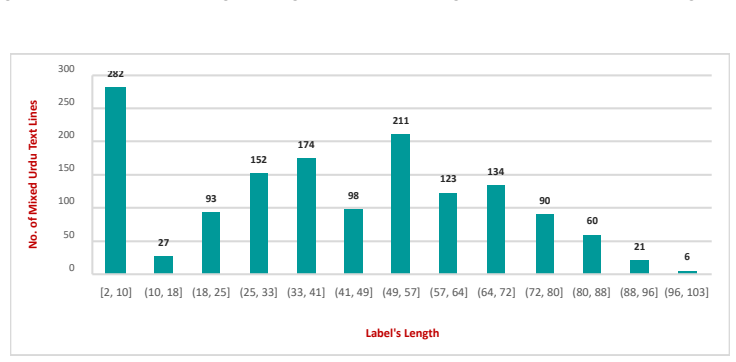
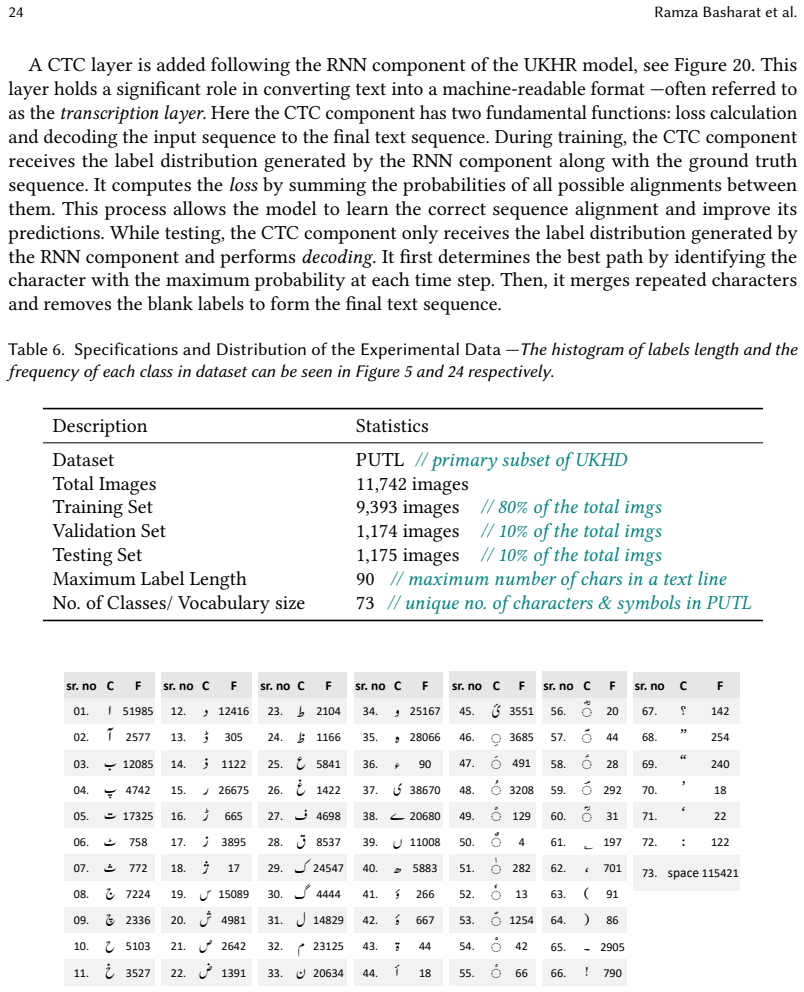
- [Dataset description] Dataset description section: no total number of text lines, number of source documents or writers, train/test split ratios, or statistics on writing variation diversity are supplied. These details are required to substantiate that UKHD constitutes a usable benchmark for the claimed research advancement.
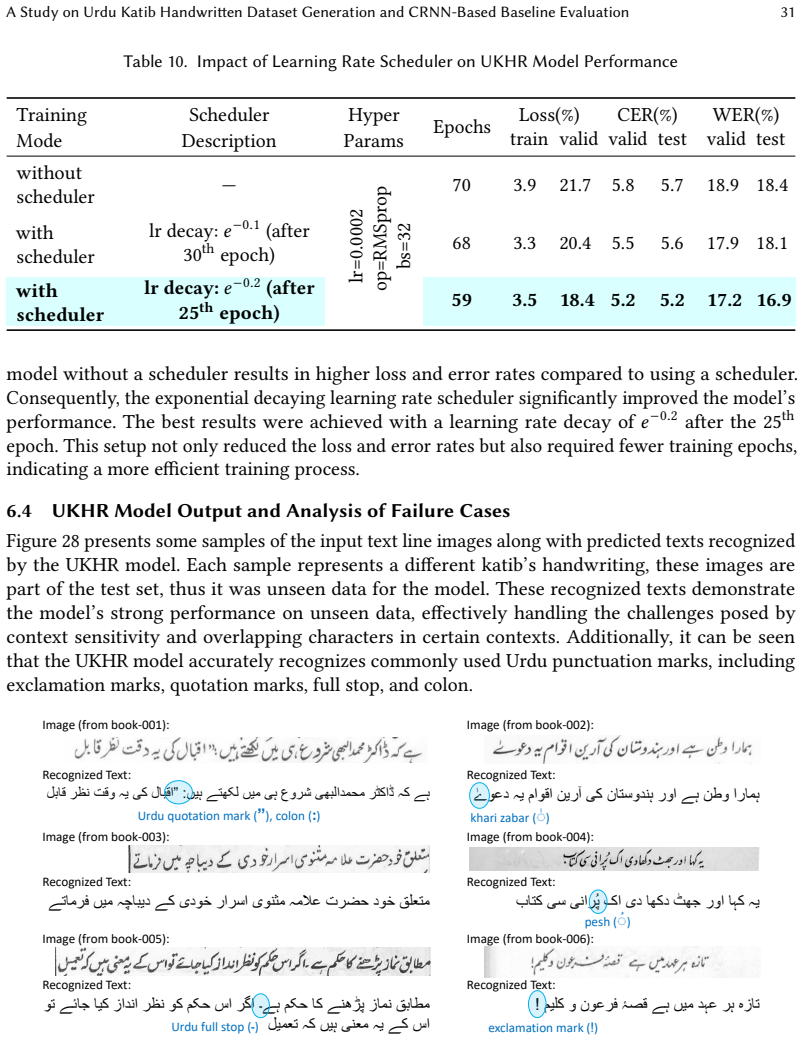
- [Results] Results section: the claim that CNN-BGRU-CTC achieves 'low CER and WER' and 'more robust performance' is unsupported because exact numerical values, comparisons against the other evaluated CRNN variants, and any error bars or statistical tests are omitted. This prevents verification of the model ranking.
minor comments (2)
- The abstract and introduction do not define the threshold for 'low' CER/WER relative to existing Urdu or Nastalique HTR literature, reducing interpretability of the performance claim.
- [Model evaluation] Hyperparameter settings, layer counts, and training protocols for the CRNN variants are not specified, hindering reproducibility of the reported baseline.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and will revise the manuscript to incorporate the requested information.
read point-by-point responses
-
Referee: [Dataset description] Dataset description section: no total number of text lines, number of source documents or writers, train/test split ratios, or statistics on writing variation diversity are supplied. These details are required to substantiate that UKHD constitutes a usable benchmark for the claimed research advancement.
Authors: We agree that these quantitative details are necessary to fully establish UKHD as a usable benchmark. The revised manuscript will add the total number of text lines, number of source documents and writers, explicit train/test split ratios, and statistics on writing variation diversity to the Dataset description section. revision: yes
-
Referee: [Results] Results section: the claim that CNN-BGRU-CTC achieves 'low CER and WER' and 'more robust performance' is unsupported because exact numerical values, comparisons against the other evaluated CRNN variants, and any error bars or statistical tests are omitted. This prevents verification of the model ranking.
Authors: We acknowledge that the Results section currently lacks the specific numerical values and direct comparisons needed to substantiate the performance claims. In the revision we will include the exact CER and WER figures for all CRNN variants evaluated, a clear ranking table, and any available error bars or statistical tests to support the statement that CNN-BGRU-CTC exhibits the most robust performance. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a dataset release plus empirical baseline evaluation on CRNN variants. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described contribution. The central claim (new historical Urdu text-line resource with reproducible model rankings) rests on the released splits and measured CER/WER values, which are externally falsifiable and do not reduce to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Riaz Ahmad, M Zeshan Afzal, S Faisal Rashid, Marcus Liwicki, Thomas Breuel, and Andreas Dengel. 2016. Kpti: Katib’s pashto text imagebase and deep learning benchmark. In2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR). IEEE, 453–458
2016
-
[2]
Saad Bin Ahmed, Saeeda Naz, Salahuddin Swati, and Muhammad Imran Razzak. 2019. Handwritten Urdu character recognition using one-dimensional BLSTM classifier.Neural Computing and Applications31 (2019), 1143–1151
2019
-
[3]
Sana Al-azzawi, Elisa Barney, and Marcus Liwicki. 2026. Cross-Language Learning within Arabic Script for Low- Resource HTR. arXiv:2605.02089 [cs.CV] https://arxiv.org/abs/2605.02089
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Saad Albawi, Tareq Abed Mohammed, and Saad Al-Zawi. 2017. Understanding of a convolutional neural network. In 2017 international conference on engineering and technology (ICET). Ieee, 1–6
2017
-
[5]
Anjum Ali, Mohmood Ahmad, Nasir Rafiq, Javed Akber, Usman Ahmad, and Shahwar Akmal. 2004. Language independent optical character recognition for hand written text. In8th International Multitopic Conference, 2004. Proceedings of INMIC 2004.IEEE, 79–84
2004
-
[6]
Tayaba Anjum and Arifah Azhar. 2025. A Survey on Urdu Handwritten Text Recognition: State of the Art, Challenges, and Future Directions.Journal of Computing and Artificial Intelligence3, 1 (2025)
2025
-
[7]
Tayaba Anjum and Nazar Khan. 2020. An attention based method for offline handwritten Urdu text recognition. In 2020 17th International conference on frontiers in handwriting recognition (ICFHR). IEEE, 169–174
2020
-
[8]
Saad Bin Ahmed, Saeeda Naz, Salahuddin Swati, Imran Razzak, Arif Iqbal Umar, and A Ali Khan. 2017. UCOM offline dataset-an Urdu handwritten dataset generation. (2017)
2017
-
[9]
Lei Chen and Shaobin Li. 2018. Improvement research and application of text recognition algorithm based on CRNN. InProceedings of the 2018 international conference on signal processing and machine learning. 166–170
2018
-
[10]
Liren Chen, Ruijie Yan, Liangrui Peng, Akio Furuhata, and Xiaoqing Ding. 2017. Multi-layer recurrent neural network based offline Arabic handwriting recognition. In2017 1st international workshop on Arabic script analysis and recognition (ASAR). IEEE, 6–10
2017
-
[11]
Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[12]
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. 2014. Empirical evaluation of gated recurrent neural networks on sequence modeling.arXiv preprint arXiv:1412.3555(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[13]
MUHAMMAD FAHAD, MALIK MUHAMMAD SAAD MISSEN, MUJTABA HUSNAIN, ALI SAMAD, DALER ALI, and ASAD ALI. 2023. MULTI-ASPECT URDU HANDWRITING DATA COLLECTION.Tianjin Daxue Xuebao (Ziran Kexue yu Gongcheng Jishu Ban)/Journal of Tianjin University Science and Technology(2023)
2023
-
[14]
Takwa Ben Aïcha Gader and Afef Kacem Echi. 2022. Attention-based deep learning model for Arabic handwritten text recognition.Machine Graphics and Vision31, 1/4 (2022), 49–73
2022
-
[15]
Aejaz Farooq Ganai and Farida Khursheed. 2022. A novel holistic unconstrained handwritten urdu recognition system using convolutional neural networks.International Journal on Document Analysis and Recognition (IJDAR)25, 4 (2022), 351–371
2022
-
[16]
Aejaz Farooq Ganai and Farida Khursheed. 2023. Computationally Efficient Holistic Approach for Handwritten Urdu Recognition using LRCN Model.International Journal of Intelligent Systems and Applications in Engineering11, 4s (2023), 536–551
2023
-
[17]
Aejaz Farooq Ganai and Farida Khursheed. 2023. Computationally efficient recognition of unconstrained handwritten Urdu script using BERT with vision transformers.Neural Computing and Applications35 (2023), 1–17
2023
-
[18]
Alex Graves, Santiago Fernández, Faustino Gomez, and Jürgen Schmidhuber. 2006. Connectionist temporal classifica- tion: labelling unsegmented sequence data with recurrent neural networks. InProceedings of the 23rd international conference on Machine learning. 369–376
2006
-
[19]
Shahbaz Hassan, Ayesha Irfan, Ali Mirza, and Imran Siddiqi. 2019. Cursive handwritten text recognition using bi-directional LSTMs: a case study on Urdu handwriting. In2019 International conference on deep learning and machine learning in emerging applications (Deep-ML). IEEE, 67–72
2019
-
[20]
Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory.Neural computation9, 8 (1997), 1735–1780
1997
-
[21]
S Afaq Husain, Asma Sajjad, and Fareeha Anwar. 2007. Online Urdu Character Recognition System.. InMV A. 98–101. A Study on Urdu Katib Handwritten Dataset Generation and CRNN-Based Baseline Evaluation 35
2007
-
[22]
Sarmad Hussain. 2003. Complexity of Asian writing systems: a case study of Nafees Nasta’leeq for urdu. InProceedings of the 12th AMIC Annual Conference on e-Worlds: Governments, Business and Civil Society, Asian Media Information Center, Singapore
2003
-
[23]
Sergey Ioffe and Christian Szegedy. 2015. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InInternational conference on machine learning. pmlr, 448–456
2015
-
[24]
Iqbal Cyber Library
Iqbal Academy Pakistan. 2023. "Iqbal Cyber Library". [Online]. Available: https://iqbalcyberlibrary.net. Accessed: 2023
2023
-
[25]
Sobia Tariq Javed and Sarmad Hussain. 2009. Improving Nastalique specific pre-recognition process for Urdu OCR. In 2009 IEEE 13th International Multitopic Conference. IEEE, 1–6
2009
-
[26]
Sobia T Javed, Sarmad Hussain, Ameera Maqbool, Samia Asloob, Sehrish Jamil, and Huma Moin. 2010. Segmentation free nastalique urdu ocr.World Academy of Science, Engineering and Technology46 (2010), 456–461
2010
-
[27]
Yuxiang Jiang, Haiwei Dong, and Abdulmotaleb El Saddik. 2018. Baidu Meizu deep learning competition: Arithmetic operation recognition using end-to-end learning OCR technologies.IEEE Access6 (2018), 60128–60136
2018
- [28]
-
[29]
Khalil Khan, Rehan Ullah, Nasir Ahmad Khan, and Khwaja Naveed. 2012. Urdu character recognition using principal component analysis.International Journal of Computer Applications60, 11 (2012)
2012
-
[30]
Naila Habib Khan and Awais Adnan. 2018. Urdu optical character recognition systems: Present contributions and future directions.IEEE Access6 (2018), 46019–46046
2018
-
[31]
Herleen Kour and Naveen Kumar Gondhi. 2020. Machine Learning approaches for Nastaliq style Urdu handwritten recognition: A survey. In2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS). IEEE, 50–54
2020
-
[32]
Gurpreet Singh Lehal and Ankur Rana. 2013. Recognition of nastalique urdu ligatures. InProceedings of the 4th International Workshop on Multilingual OCR. 1–5
2013
-
[33]
LB Mahanta and Alpana Deka. 2013. Skew and slant angles of handwritten signature.International Journal of Innovative Research in Computer and Communication Engineering1, 9 (2013), 2030–2034
2013
-
[34]
Ahmed Muaz. 2010. Urdu optical character recognition system MS thesis.Diss. National University of Computer & Emerging Sciences(2010)
2010
-
[35]
Omar Mukhtar, Srirangaraj Setlur, and Venu Govindaraju. 2010. Experiments on urdu text recognition.Guide to OCR for Indic scripts: Document recognition and retrieval(2010), 163–171
2010
-
[36]
Saeeda Naz, Khizar Hayat, Muhammad Imran Razzak, Muhammad Waqas Anwar, Sajjad A Madani, and Samee U Khan. 2014. The optical character recognition of Urdu-like cursive scripts.Pattern Recognition47, 3 (2014), 1229–1248
2014
-
[37]
Saeeda Naz, Arif I Umar, Riaz Ahmad, Saad B Ahmed, Syed H Shirazi, Imran Siddiqi, and Muhammad I Razzak. 2016. Offline cursive Urdu-Nastaliq script recognition using multidimensional recurrent neural networks.Neurocomputing 177 (2016), 228–241
2016
-
[38]
Saeeda Naz, Arif Iqbal Umar, Riaz Ahmed, Muhammad Imran Razzak, Sheikh Faisal Rashid, and Faisal Shafait. 2016. Urdu Nasta’liq text recognition using implicit segmentation based on multi-dimensional long short term memory neural networks.SpringerPlus5 (2016), 1–16
2016
-
[39]
Keiron O’Shea and Ryan Nash. 2015. An introduction to convolutional neural networks.arXiv preprint arXiv:1511.08458 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[40]
U Pal and Anirban Sarkar. 2003. Recognition of printed Urdu script. InSeventh International Conference on Document Analysis and Recognition, 2003. Proceedings., Vol. 3. Citeseer, 1183–1183
2003
-
[41]
Dhuha Rashid and Naveen Kumar Gondhi. 2022. Scrutinization of Urdu handwritten text recognition with machine learning approach. InInternational Conference on Emerging Technologies in Computer Engineering. Springer, 383–394
2022
-
[42]
Nauman Riaz, Haziq Arbab, Arooba Maqsood, Khuzaeymah Nasir, Adnan Ul-Hasan, and Faisal Shafait. 2022. Conv- transformer architecture for unconstrained off-line Urdu handwriting recognition.International Journal on Document Analysis and Recognition (IJDAR)25, 4 (2022), 373–384
2022
-
[43]
Malik Waqas Sagheer, Chun Lei He, Nicola Nobile, and Ching Y Suen. 2010. Holistic Urdu handwritten word recognition using support vector machine. In2010 20th international conference on pattern recognition. IEEE, 1900–1903
2010
-
[44]
Danish Altaf Satti. 2013. Offline Urdu Nastaliq OCR for printed text using analytical approach.MS thesis report(2013), 141
2013
-
[45]
Danish Altaf Satti and Khalid Saleem. 2012. Complexities and implementation challenges in offline urdu Nastaliq OCR. InProceedings of the Conference on Language & Technology. 85–91
2012
-
[46]
Adnan Hussain Shah, Muhammad Majid Mahmood Bagram, Muhammad Munwar Iqbal, and Farooq Ali. 2021. Urdu Handwritten Words Recognition Using Machine Learning.Technical Journal26, 02 (2021), 81–88
2021
-
[47]
Nabeel Shahzad, Brandon Paulson, and Tracy Hammond. 2009. Urdu Qaeda: recognition system for isolated urdu characters. InProceedings of the IUI Workshop on Sketch Recognition, Sanibel Island, Florida. 36 Ramza Basharat et al
2009
- [48]
-
[49]
Baoguang Shi, Xiang Bai, and Cong Yao. 2016. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition.IEEE transactions on pattern analysis and machine intelligence 39, 11 (2016), 2298–2304
2016
- [50]
-
[51]
Guofeng Tong, Yong Li, Huashuai Gao, Huairong Chen, Hao Wang, and Xiang Yang. 2020. MA-CRNN: a multi-scale attention CRNN for Chinese text line recognition in natural scenes.International Journal on Document Analysis and Recognition (IJDAR)23 (2020), 103–114
2020
-
[52]
Adnan Ul-Hasan, Saad Bin Ahmed, Faisal Rashid, Faisal Shafait, and Thomas M Breuel. 2013. Offline printed Urdu Nastaleeq script recognition with bidirectional LSTM networks. In2013 12th international conference on document analysis and recognition. IEEE, 1061–1065
2013
-
[53]
Noor ul Sehr Zia, Muhammad Ferjad Naeem, Syed Muhammad Kumail Raza, Muhammad Mubasher Khan, Adnan Ul-Hasan, and Faisal Shafait. 2022. A convolutional recursive deep architecture for unconstrained Urdu handwriting recognition.Neural Computing and Applications(2022), 1–14
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.