Is Complex Training Necessary for Long-Tailed OOD Detection? A Re-think from Feature Geometry
Pith reviewed 2026-05-20 12:36 UTC · model grok-4.3
The pith
A post-hoc geometric adjustment on frozen long-tailed features can replace complex specialized training for out-of-distribution detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
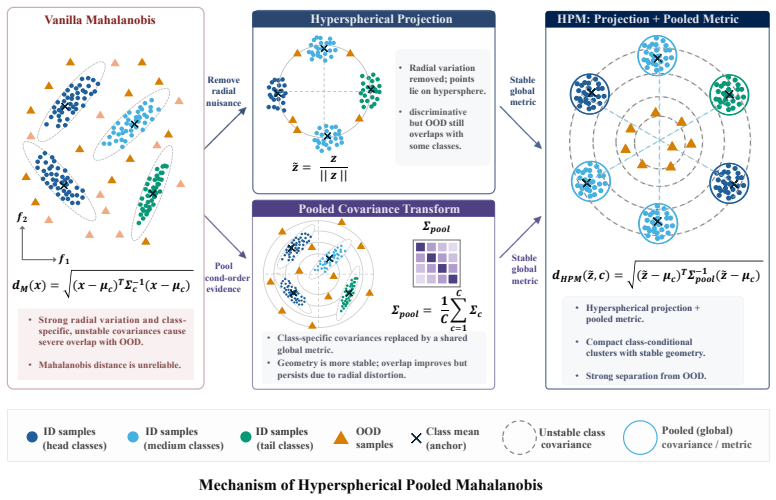
Frozen long-tailed representations already embed useful OOD evidence, yet standard Mahalanobis distance is distorted by frequency-coupled feature radii and under-supported tail covariances. HPM addresses both issues through a post-hoc pipeline: features are normalized to the unit sphere, class-specific covariance matrices are replaced by a single ridge-regularized pooled estimate, and class means are retained as semantic anchors. In CIFAR-LT experiments this lifts AUROC from 46.49 to 85.67 on CIFAR-10-LT and from 50.40 to 78.35 on CIFAR-100-LT for Prior-Calibrated ERM models while achieving the highest Log Efficiency Score at far lower training cost.
What carries the argument
Hyperspherical Pooled Mahalanobis (HPM) detector that projects features onto the unit sphere and substitutes class-specific covariances with a pooled ridge-regularized metric.
If this is right
- Post-hoc geometric corrections can exceed the gains from auxiliary OOD data, contrastive losses, or abstention heads in long-tailed settings.
- LT-OOD evaluation should report representation quality, detector geometry, and training complexity as independent factors.
- Normalizing feature radius removes a frequency bias that otherwise inflates scores for head classes.
- A pooled covariance estimate supplies usable support for tail classes without requiring additional samples.
- High AUROC is achievable while retaining roughly 95 percent of peak performance at substantially reduced training cost.
Where Pith is reading between the lines
- Future representation learning for long-tailed data might prioritize angular separation over magnitude calibration.
- The same normalization-plus-pooling pattern could be tested on other imbalanced tasks such as long-tailed classification or few-shot detection.
- If tail classes exhibit highly anisotropic covariances, a modest per-class adaptation of the pooled matrix might be added without reintroducing full training complexity.
- The efficiency advantage suggests that benchmark suites should include training-time cost as a primary axis alongside AUROC.
Load-bearing premise
Class means remain stable semantic anchors after hyperspherical normalization and a single pooled ridge-regularized covariance can represent the geometry of tail classes despite their small sample counts.
What would settle it
Measure AUROC drop on a long-tailed test set after deliberately shifting class means under hyperspherical projection or after replacing the pooled covariance with per-class estimates for the most frequent classes only.
Figures




read the original abstract
Long-tailed out-of-distribution (LT-OOD) detection is often addressed with specialized training, including auxiliary out-of-distribution (OOD) data, abstention heads, contrastive objectives, energy losses, or gradient-conflict control. We show that these training mechanisms can obscure a simpler issue: frozen long-tailed representations may already contain useful OOD evidence, but raw Mahalanobis distance is distorted by frequency-coupled feature radius and poorly supported tail covariance. We propose Hyperspherical Pooled Mahalanobis (HPM), a post-hoc detector that normalizes features onto the unit sphere and replaces class-specific covariance with a pooled, ridge-regularized metric while keeping class means as semantic anchors. In CIFAR-LT experiments and an ImageNet-100-LT near-OOD boundary analysis, HPM improves raw Mahalanobis scoring; for Prior-Calibrated ERM (PC-ERM), it raises AUROC from 46.49 to 85.67 on CIFAR-10-LT and from 50.40 to 78.35 on CIFAR-100-LT. This simple PC-ERM+HPM pipeline also achieves the best Log Efficiency Score (LES; 3.08) on CIFAR-100-LT, retaining roughly 95% of the best CIFAR-100-LT AUROC observed among the compared post-hoc scores at substantially lower training-time cost. These results argue for evaluating representation quality, detector geometry, and training complexity as separate factors in LT-OOD detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that complex training procedures (auxiliary OOD data, contrastive losses, etc.) are not required for long-tailed out-of-distribution detection. Frozen representations from standard long-tailed training already contain useful OOD signal, but raw Mahalanobis distance is distorted by frequency-dependent feature norms and unreliable tail-class covariances. The proposed post-hoc Hyperspherical Pooled Mahalanobis (HPM) detector normalizes features to the unit sphere, replaces per-class covariances with a single ridge-regularized pooled matrix, and retains class means as semantic anchors. On CIFAR-LT benchmarks this yields large AUROC gains (e.g., 46.49 → 85.67 on CIFAR-10-LT for PC-ERM) and the highest Log Efficiency Score (LES = 3.08) on CIFAR-100-LT while retaining ~95 % of the best observed AUROC at far lower training cost.
Significance. If the reported gains prove robust, the work is significant because it cleanly separates representation quality, detector geometry, and training complexity, showing that inexpensive post-hoc geometric corrections can recover most of the performance previously attributed to elaborate training schemes. The concrete AUROC lifts, the introduction of the LES metric, and the explicit comparison of training-time cost versus detection performance are valuable contributions that could shift evaluation practice in LT-OOD research.
major comments (2)
- [§3 / abstract] The central construction retains per-class means as fixed semantic anchors after L2 normalization (abstract and §3). For tail classes with only a handful of samples the empirical mean direction on the sphere remains high-variance; small perturbations can shift both ID decision boundaries and OOD scores. The pooled ridge-regularized covariance mitigates covariance estimation but does not correct for potentially biased mean locations. An ablation that perturbs or regularizes the tail means (or reports mean-direction variance) is needed to establish that the reported AUROC gains do not depend on these noisy anchors.
- [Experiments / Table 1] Table 1 and the CIFAR-LT results report large AUROC improvements without error bars, without full ablation tables for the ridge parameter, and without cross-backbone verification. The central empirical claim that HPM “improves raw Mahalanobis scoring” and achieves the best LES therefore remains only partially verifiable from the presented data.
minor comments (2)
- Clarify the exact procedure used to select the ridge regularization strength; a sensitivity plot would be helpful.
- [Related Work] The manuscript would benefit from a short paragraph contrasting HPM with prior hyperspherical or normalized Mahalanobis variants in the related-work section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and indicate where revisions will be made to address the concerns.
read point-by-point responses
-
Referee: [§3 / abstract] The central construction retains per-class means as fixed semantic anchors after L2 normalization (abstract and §3). For tail classes with only a handful of samples the empirical mean direction on the sphere remains high-variance; small perturbations can shift both ID decision boundaries and OOD scores. The pooled ridge-regularized covariance mitigates covariance estimation but does not correct for potentially biased mean locations. An ablation that perturbs or regularizes the tail means (or reports mean-direction variance) is needed to establish that the reported AUROC gains do not depend on these noisy anchors.
Authors: We agree that empirical means for tail classes are estimated from few samples and therefore exhibit higher directional variance on the unit sphere. This is an inherent limitation of long-tailed data and could in principle affect boundary stability. At the same time, the large observed gains of HPM over raw Mahalanobis already incorporate these noisy anchors, suggesting that the hyperspherical normalization and pooled covariance are the dominant contributors. To directly test sensitivity, we will add an ablation that injects controlled angular perturbations to the tail-class means and reports the resulting AUROC variance; we will also tabulate per-class mean-direction variance (head vs. tail) in the supplementary material. revision: yes
-
Referee: [Experiments / Table 1] Table 1 and the CIFAR-LT results report large AUROC improvements without error bars, without full ablation tables for the ridge parameter, and without cross-backbone verification. The central empirical claim that HPM “improves raw Mahalanobis scoring” and achieves the best LES therefore remains only partially verifiable from the presented data.
Authors: We acknowledge that the absence of error bars and limited ablation detail reduces verifiability. In the revision we will report standard deviations over multiple random seeds for all AUROC entries in Table 1. We will also expand the ridge-parameter ablation to a denser grid of values and include the corresponding AUROC and LES curves. For cross-backbone verification we will add results on one additional architecture (Wide-ResNet) for the main CIFAR-LT settings. A exhaustive sweep across every possible backbone lies outside the scope of the current study given computational cost; the added experiments should nevertheless provide reasonable support for the central claim. revision: partial
Circularity Check
HPM derivation is self-contained post-hoc geometry adjustment with no reductions to inputs
full rationale
The paper identifies distortions in raw Mahalanobis scoring from frequency-coupled radii and weak tail covariances in frozen long-tailed features, then defines HPM explicitly as L2 normalization to the unit sphere combined with a single ridge-regularized pooled covariance while retaining empirical class means as anchors. This construction is stated directly from geometric analysis and does not invoke any fitted parameter, self-citation chain, or uniqueness theorem that reduces the reported AUROC gains (e.g., 46.49 to 85.67) back to quantities defined by the evaluation data itself. Experiments on CIFAR-LT and ImageNet-100-LT serve as independent empirical checks rather than tautological predictions, confirming the method remains non-circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- ridge regularization strength
axioms (1)
- domain assumption Class means remain reliable semantic anchors after hyperspherical normalization.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks , author=. International Conference on Learning Representations , year=
-
[2]
International Conference on Learning Representations , year=
Enhancing The Reliability of Out-of-distribution Image Detection in Neural Networks , author=. International Conference on Learning Representations , year=
-
[3]
Advances in Neural Information Processing Systems , year=
A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks , author=. Advances in Neural Information Processing Systems , year=
-
[4]
Advances in Neural Information Processing Systems , year=
Energy-based Out-of-distribution Detection , author=. Advances in Neural Information Processing Systems , year=
-
[5]
International Conference on Learning Representations , year=
Deep Anomaly Detection with Outlier Exposure , author=. International Conference on Learning Representations , year=
-
[6]
Advances in Neural Information Processing Systems , year=
Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss , author=. Advances in Neural Information Processing Systems , year=
-
[7]
International Conference on Learning Representations , year=
Decoupling Representation and Classifier for Long-Tailed Recognition , author=. International Conference on Learning Representations , year=
-
[8]
International Conference on Learning Representations , year=
Long-tail Learning via Logit Adjustment , author=. International Conference on Learning Representations , year=
-
[9]
Advances in Neural Information Processing Systems , year=
Balanced Meta-Softmax for Long-Tailed Visual Recognition , author=. Advances in Neural Information Processing Systems , year=
-
[10]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Balanced Contrastive Learning for Long-Tailed Visual Recognition , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[11]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Large-Scale Long-Tailed Recognition in an Open World , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[12]
Proceedings of the 39th International Conference on Machine Learning , pages=
Partial and Asymmetric Contrastive Learning for Out-of-Distribution Detection in Long-Tailed Recognition , author=. Proceedings of the 39th International Conference on Machine Learning , pages=. 2022 , volume=
work page 2022
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Long-Tailed Out-of-Distribution Detection: Prioritizing Attention to Tail , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2025 , doi=
work page 2025
- [14]
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Out-of-Distribution Detection in Long-Tailed Recognition with Calibrated Outlier Class Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2024 , doi=
work page 2024
-
[16]
Advances in Neural Information Processing Systems , year=
Long-Tailed Out-of-Distribution Detection via Normalized Outlier Distribution Adaptation , author=. Advances in Neural Information Processing Systems , year=
-
[17]
Zhang, Xuan and Chin, Sinchee and Xue, Jing-Hao and Yang, Xiaochen and Yang, Wenming , booktitle=. 2025 , doi=
work page 2025
-
[18]
M. Mahalanobis++: Improving. Proceedings of the 42nd International Conference on Machine Learning , pages=. 2025 , volume=
work page 2025
-
[19]
Advances in Neural Information Processing Systems , year=
ReAct: Out-of-distribution Detection With Rectified Activations , author=. Advances in Neural Information Processing Systems , year=
-
[20]
International Conference on Machine Learning , year=
Out-of-Distribution Detection with Deep Nearest Neighbors , author=. International Conference on Machine Learning , year=
-
[21]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
ViM: Out-of-Distribution with Virtual-logit Matching , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[22]
International Conference on Learning Representations , year=
SSD: A Unified Framework for Self-Supervised Outlier Detection , author=. International Conference on Learning Representations , year=
-
[23]
Ming, Yifei and Sun, Yiyou and Dia, Ousmane and Li, Yixuan , booktitle=
-
[24]
Proceedings of the National Academy of Sciences , volume=
Prevalence of Neural Collapse during the Terminal Phase of Deep Learning Training , author=. Proceedings of the National Academy of Sciences , volume=
-
[25]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Do Better ImageNet Models Transfer Better? , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[26]
Advances in Neural Information Processing Systems Datasets and Benchmarks Track , year=
OpenOOD: Benchmarking Generalized Out-of-Distribution Detection , author=. Advances in Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[27]
Advances in Neural Information Processing Systems , year=
Likelihood Ratios for Out-of-Distribution Detection , author=. Advances in Neural Information Processing Systems , year=
-
[28]
International Conference on Learning Representations , year=
Do Deep Generative Models Know What They Don't Know? , author=. International Conference on Learning Representations , year=
-
[29]
International Conference on Machine Learning Workshop , year=
A Simple Fix to Mahalanobis Distance for Improving Near-OOD Detection , author=. International Conference on Machine Learning Workshop , year=
-
[30]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
MOS: Towards Scaling Out-of-distribution Detection for Large Semantic Space , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[31]
Advances in Neural Information Processing Systems , year=
On the Importance of Gradients for Detecting Distributional Shifts in the Wild , author=. Advances in Neural Information Processing Systems , year=
-
[32]
European Conference on Computer Vision , year=
DICE: Leveraging Sparsification for Out-of-Distribution Detection , author=. European Conference on Computer Vision , year=
-
[33]
International Conference on Learning Representations , year=
Extremely Simple Activation Shaping for Out-of-Distribution Detection , author=. International Conference on Learning Representations , year=
-
[34]
International Conference on Machine Learning , year=
Scaling Out-of-Distribution Detection for Real-World Settings , author=. International Conference on Machine Learning , year=
-
[35]
Ming, Yifei and Fan, Ying and Li, Yixuan , booktitle=
-
[36]
Advances in Neural Information Processing Systems , year=
Benchmarking and Analyzing Out-of-Distribution Detection with Vision-Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[37]
Du, Xuefeng and Wang, Zhaoning and Cai, Mu and Li, Yixuan , booktitle=
-
[38]
International Conference on Machine Learning , year=
Mitigating Neural Network Overconfidence with Logit Normalization , author=. International Conference on Machine Learning , year=
-
[39]
International Conference on Machine Learning , year=
Using Pre-Training Can Improve Model Robustness and Uncertainty , author=. International Conference on Machine Learning , year=
-
[40]
International Conference on Machine Learning , year=
Detecting Out-of-Distribution Examples with Gram Matrices , author=. International Conference on Machine Learning , year=
-
[41]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Class-Balanced Loss Based on Effective Number of Samples , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[42]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[43]
Advances in Neural Information Processing Systems , year=
Supervised Contrastive Learning , author=. Advances in Neural Information Processing Systems , year=
-
[44]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Targeted Supervised Contrastive Learning for Long-Tailed Recognition , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[45]
International Conference on Learning Representations , year=
Long-Tailed Recognition by Routing Diverse Distribution-Aware Experts , author=. International Conference on Learning Representations , year=
-
[46]
European Conference on Computer Vision , year=
Learning From Multiple Experts: Self-paced Knowledge Distillation for Long-tailed Classification , author=. European Conference on Computer Vision , year=
-
[47]
Learning Multiple Layers of Features from Tiny Images , author=
-
[48]
NIPS Workshop on Deep Learning and Unsupervised Feature Learning , year=
Reading Digits in Natural Images with Unsupervised Feature Learning , author=. NIPS Workshop on Deep Learning and Unsupervised Feature Learning , year=
-
[49]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Describing Textures in the Wild , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[50]
Russakovsky, Olga and Deng, Jia and Su, Hao and Krause, Jonathan and Satheesh, Sanjeev and Ma, Sean and Huang, Zhiheng and Karpathy, Andrej and Khosla, Aditya and Bernstein, Michael and Berg, Alexander C. and Fei-Fei, Li , journal=
-
[51]
Yu, Fisher and Zhang, Yinda and Song, Shuran and Seff, Ari and Xiao, Jianxiong , howpublished=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.