DiverAge: Reliable Pluralistic Face Aging with Cross-Age Identity Relation Guidance
Pith reviewed 2026-06-28 10:17 UTC · model grok-4.3
The pith
DiverAge generates diverse face appearances at each target age while enforcing reliable identity progression across ordered age sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
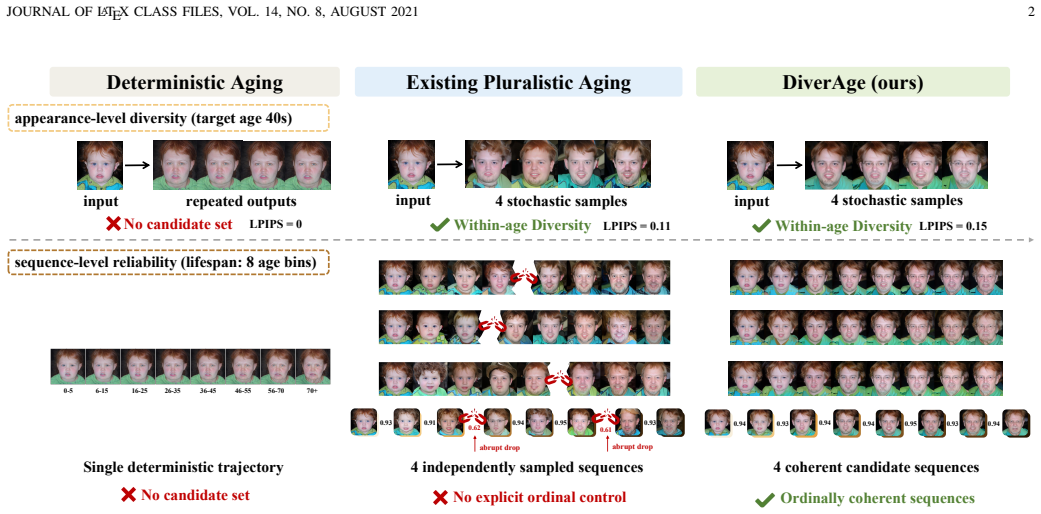
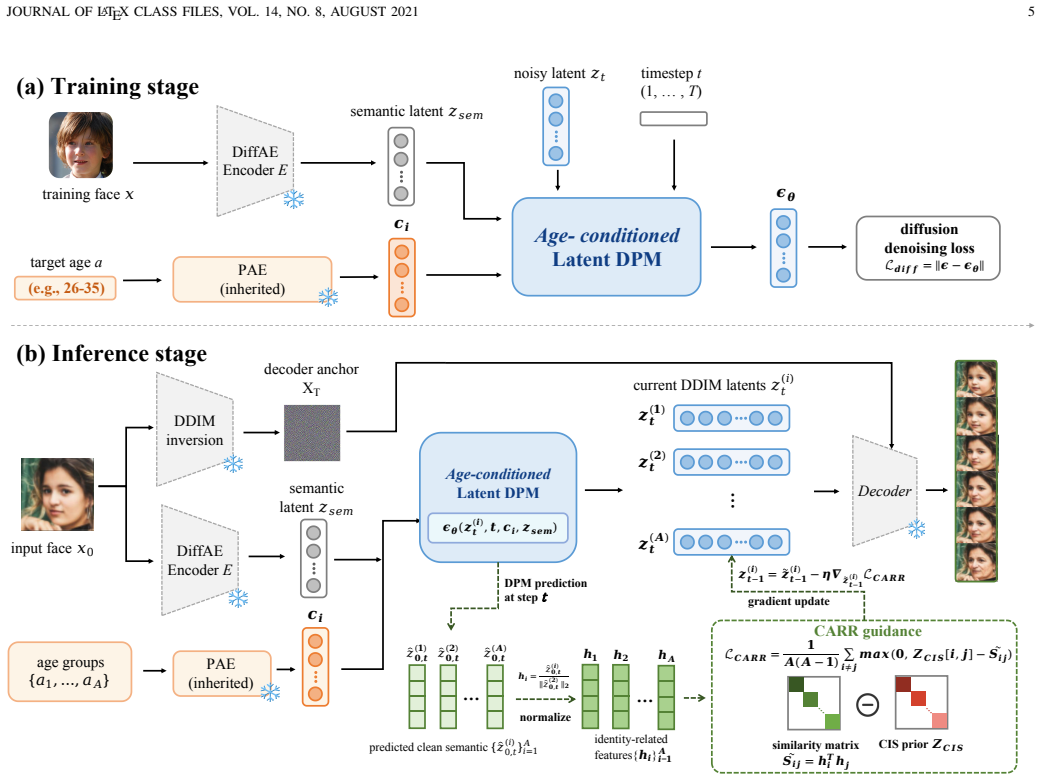
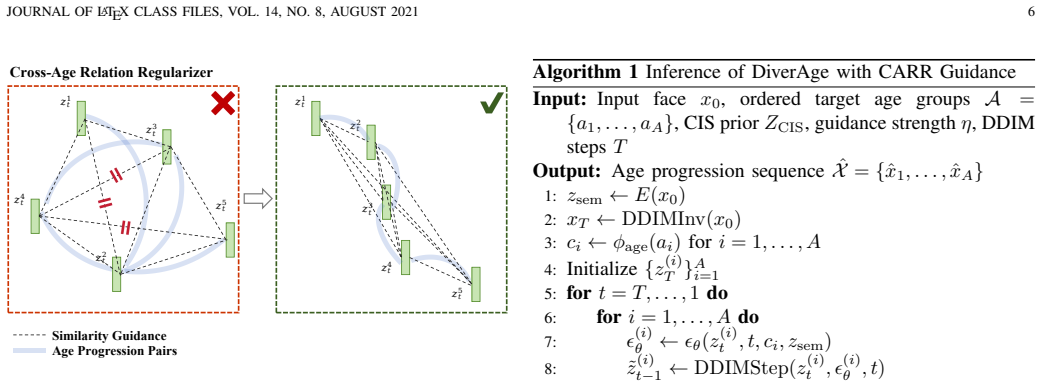
DiverAge is a hierarchical pluralistic face aging framework based on diffusion autoencoding that preserves appearance-level diversity through stochastic diffusion decoding and age-conditioned semantic modulation. To improve sequence-level reliability, it introduces the Cross-age Identity Relation Regulator (CARR), an inference-time guidance strategy that jointly denoises multiple target age groups guided by a Cross-age Identity Similarity (CIS) prior estimated from real same-identity cross-age pairs, suppressing excessive cross-age identity drift through one-sided sampling-time guidance without modifying the training objective or introducing extra trainable parameters.
What carries the argument
The Cross-age Identity Relation Regulator (CARR), an inference-time strategy that jointly denoises images for several target ages at once using a similarity prior drawn from real cross-age pairs to control identity drift across the full sequence.
If this is right
- Pluralistic face aging can satisfy both per-age variation and full-sequence ordinal reliability at the same time.
- Reliability gains come from sampling guidance alone, so the underlying diffusion model stays unchanged.
- Identity preservation, age accuracy, and image quality remain intact while sequence reliability improves.
- The approach supports applications that require coherent aging timelines such as cross-age verification.
Where Pith is reading between the lines
- The same one-sided guidance idea could be tested on other ordered generation tasks such as video frame prediction.
- Applying the regulator to datasets with wider demographic coverage would show how well the real-pair prior generalizes.
- Feeding the multiple consistent candidates into verification pipelines might raise matching rates across large age gaps.
Load-bearing premise
The similarity values measured from real same-identity cross-age image pairs give a trustworthy signal that can steer sampling to reduce drift without creating artifacts or cutting diversity.
What would settle it
Generate matched sets of aging sequences with and without the regulator on a held-out set of identities, then measure whether cross-age identity consistency rises while appearance diversity and image quality stay the same or improve.
Figures




read the original abstract
Face aging plays an important role in long-term biometric analysis, cross-age identity verification, and forensic identity analysis. Since the same subject may exhibit multiple plausible appearances at a target age due to genetic, environmental, and lifestyle factors, face aging is inherently a one-to-many generation problem. However, pluralism alone is insufficient for reliable face aging: a model should provide appearance-level candidate diversity within each age group while maintaining sequence-level ordinal reliability across ordered age groups. Existing deterministic aging methods can synthesize visually plausible age-progressed faces, but usually lack stochastic diversity. In contrast, pluralistic aging methods introduce local appearance variations, but often fail to explicitly regulate the identity evolution of the full aging sequence. In this paper, we propose \textbf{DiverAge}, a hierarchical pluralistic face aging framework based on diffusion autoencoding. DiverAge preserves appearance-level diversity through stochastic diffusion decoding and age-conditioned semantic modulation. To improve sequence-level reliability, we introduce a Cross-age Identity Relation Regulator (CARR), an inference-time guidance strategy that jointly denoises multiple target age groups. CARR is guided by a Cross-age Identity Similarity (CIS) prior estimated from real same-identity cross-age pairs, and suppresses excessive cross-age identity drift through one-sided sampling-time guidance without modifying the training objective or introducing extra trainable parameters. Experiments demonstrate that DiverAge improves sequence-level ordinal reliability while maintaining identity preservation, age accuracy, image quality, and appearance-level diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DiverAge, a hierarchical pluralistic face aging framework based on diffusion autoencoding. It preserves appearance-level diversity via stochastic diffusion decoding and age-conditioned semantic modulation. Sequence-level ordinal reliability is addressed through an inference-time Cross-age Identity Relation Regulator (CARR) that jointly denoises multiple target ages, guided by a Cross-age Identity Similarity (CIS) prior estimated from real same-identity cross-age pairs; the guidance is one-sided and sampling-time only, without altering the training objective or adding trainable parameters. Experiments are reported to show gains in ordinal reliability while preserving identity, age accuracy, image quality, and diversity.
Significance. If the experimental claims hold, the work is significant for biometric and forensic applications that require both candidate diversity at each age and reliable identity evolution across an ordered sequence. The parameter-free, inference-only guidance mechanism is a clear strength, as is the use of an empirical prior derived from real data rather than a fitted model quantity. These features distinguish the approach from prior deterministic or pluralistic aging methods.
major comments (2)
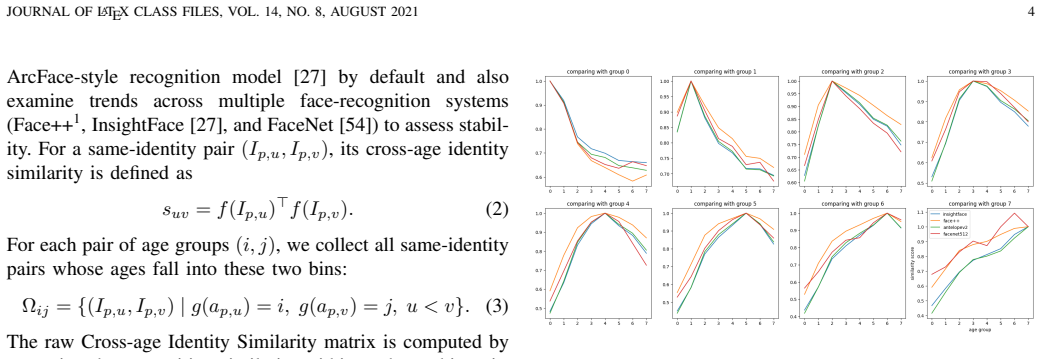
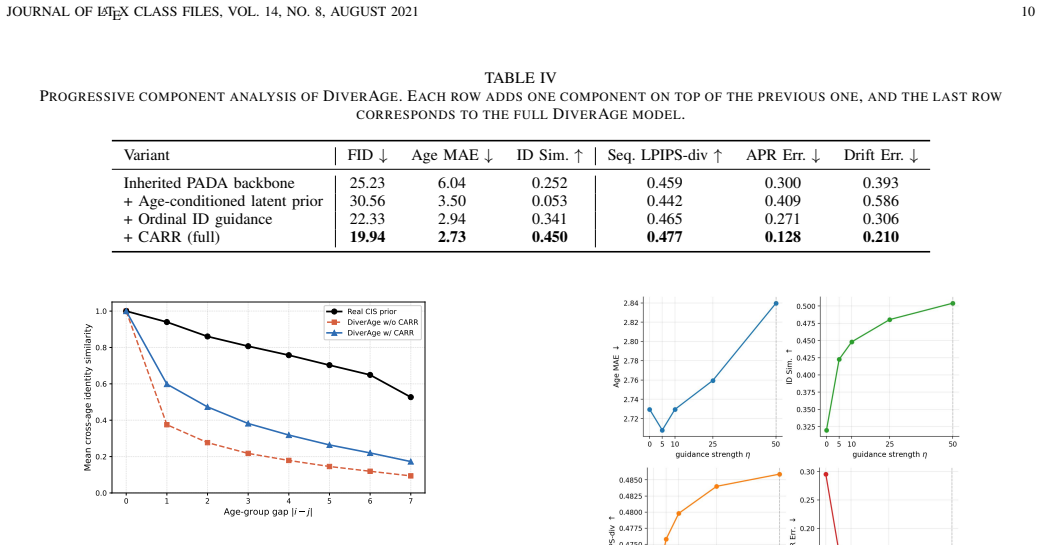
- [Experiments] Experiments section: the central claim that CARR improves sequence-level ordinal reliability without reducing appearance-level diversity or introducing artifacts rests on the CIS prior providing a reliable one-sided signal. The manuscript should report quantitative ablation results isolating the effect of the CIS prior (e.g., with vs. without CARR) together with the exact metric used for ordinal reliability and the full set of baselines.
- [§4] §4 (method): the one-sided sampling-time guidance is described as suppressing drift without new artifacts, yet no analysis is given of how the guidance strength hyper-parameter interacts with the diffusion noise schedule or the number of jointly denoised age groups; this interaction is load-bearing for the claim that diversity is maintained.
minor comments (2)
- Define all acronyms at first use (CARR, CIS) and ensure figure captions explicitly state what each panel shows (e.g., which age groups are jointly denoised).
- Add a short paragraph in the introduction or related-work section contrasting the proposed inference-time regulator with existing guidance techniques in diffusion models for face synthesis.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. We appreciate the recognition of the significance of the inference-only CARR mechanism and the empirical CIS prior. Below we respond point-by-point to the major comments, agreeing to strengthen the experimental evidence and analysis as requested.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that CARR improves sequence-level ordinal reliability without reducing appearance-level diversity or introducing artifacts rests on the CIS prior providing a reliable one-sided signal. The manuscript should report quantitative ablation results isolating the effect of the CIS prior (e.g., with vs. without CARR) together with the exact metric used for ordinal reliability and the full set of baselines.
Authors: We agree that an explicit ablation isolating CARR is valuable. The current manuscript reports comparisons against multiple baselines and shows that CARR improves ordinal reliability while preserving diversity, but does not contain a dedicated with/without CARR table. In the revision we will add quantitative ablation results (with vs. without CARR) using the same metrics, explicitly define the ordinal reliability metric as the average cross-age identity consistency (CIS) across the ordered sequence, and present the complete set of baselines in a single table for clarity. revision: yes
-
Referee: [§4] §4 (method): the one-sided sampling-time guidance is described as suppressing drift without new artifacts, yet no analysis is given of how the guidance strength hyper-parameter interacts with the diffusion noise schedule or the number of jointly denoised age groups; this interaction is load-bearing for the claim that diversity is maintained.
Authors: We acknowledge that the manuscript does not provide a dedicated sensitivity study of the guidance strength hyper-parameter with respect to the noise schedule or the number of jointly denoised age groups. While our main experiments already vary the number of age groups and report stable diversity metrics, we agree an explicit analysis would strengthen the claim. We will add a short sensitivity study (varying guidance strength across noise levels and group counts) either in §4 or the supplementary material of the revised manuscript. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central construction relies on an external empirical CIS prior computed directly from real same-identity cross-age image pairs, combined with standard diffusion autoencoding and one-sided inference-time guidance via CARR. No quantity is defined in terms of itself, no fitted parameter is relabeled as a prediction, and no self-citation chain is invoked to justify uniqueness or the core mechanism. The sequence-level reliability improvement is presented as an empirical outcome of applying the external prior, not as a mathematical identity derived from the model's own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Longitudinal study of automatic face recognition,
L. Best-Rowden and A. K. Jain, “Longitudinal study of automatic face recognition,”IEEE TPAMI, 2018
2018
-
[2]
Global and local consistent age generative adversarial networks,
P. Li, Y . Hu, Q. Li, R. He, and Z. Sun, “Global and local consistent age generative adversarial networks,” inICPR, 2018
2018
-
[3]
Hierarchical face aging through disentangled latent characteristics,
P. Li, H. Huang, Y . Hu, X. Wu, R. He, and Z. Sun, “Hierarchical face aging through disentangled latent characteristics,” inECCV, 2020
2020
-
[4]
Deep label refinement for age estimation,
P. Li, Y . Hu, X. Wu, R. He, and Z. Sun, “Deep label refinement for age estimation,”Pattern Recognition, 2020
2020
-
[5]
When age-invariant face recognition meets face age synthesis: A multi-task learning framework and a new benchmark,
Z. Huang, J. Zhang, and H. Shan, “When age-invariant face recognition meets face age synthesis: A multi-task learning framework and a new benchmark,”IEEE TPAMI, 2022
2022
-
[6]
Learning-to- rank meets language: Boosting language-driven ordering alignment for ordinal classification,
R. Wang, P. Li, H. Huang, C. Cao, R. He, and Z. He, “Learning-to- rank meets language: Boosting language-driven ordering alignment for ordinal classification,” inNeurIPS, 2023
2023
-
[7]
Finding missing children: Aging deep face features,
D. Deb, D. Aggarwal, and A. K. Jain, “Finding missing children: Aging deep face features,” 2019
2019
-
[8]
Exploring 3d-aware lifespan face aging via disentangled shape-texture representations,
Q. Teng, R. Wang, X. Cui, P. Li, and Z. He, “Exploring 3d-aware lifespan face aging via disentangled shape-texture representations,” in ICME, 2024
2024
-
[9]
Global and local consistent wavelet- domain age synthesis,
P. Li, Y . Hu, R. He, and Z. Sun, “Global and local consistent wavelet- domain age synthesis,”IEEE TIFS, 2019
2019
-
[10]
Why some women look young for their age,
D. A. Gunn, H. Rexbye, C. E. M. Griffiths, P. G. Murray, A. Fereday, S. D. Catt, C. C. Tomlin, B. H. Strongitharm, D. I. Perrett, M. Catt, A. E. Mayes, A. G. Messenger, M. R. Green, F. van der Ouderaa, J. W. Vaupel, and K. Christensen, “Why some women look young for their age,”PLoS ONE, 2009
2009
-
[11]
The skin aging exposome,
J. Krutmann, A. Bouloc, G. Sore, B. A. Bernard, and T. Passeron, “The skin aging exposome,”Journal of Dermatological Science, 2017
2017
-
[12]
Facial changes caused by smoking: A comparison between smoking and nonsmoking identical twins,
H. C. Okada, B. Alleyne, K. Varghai, K. Kinder, and B. Guyuron, “Facial changes caused by smoking: A comparison between smoking and nonsmoking identical twins,”Plastic and Reconstructive Surgery, 2013
2013
-
[13]
Face aging via diffusion-based editing,
X. Chen and S. Lathuili `ere, “Face aging via diffusion-based editing,” in BMVC, 2023
2023
-
[14]
Face time traveller: Travel through ages without losing identity,
P. Kar, A. Ghadiya, V . Chudasama, P. Wasnik, and C. V . Jawahar, “Face time traveller: Travel through ages without losing identity,” 2026
2026
-
[15]
TimeMachine: Fine-grained facial age editing with identity preservation,
Y . Mi, Q. Yan, Z.-P. Duan, C. Guo, H. Yin, H. Liu, C. Li, and C. Li, “TimeMachine: Fine-grained facial age editing with identity preservation,” 2025
2025
-
[16]
From cradle to cane: A two-pass framework for high- fidelity lifespan face aging,
T. Liu, D. Zhang, G. Li, S. Liu, Y . Song, S. Li, S. Yang, B. Li, K. Wang, and Y . Wang, “From cradle to cane: A two-pass framework for high- fidelity lifespan face aging,” inNeurIPS, 2025
2025
-
[17]
AgeBooth: Controllable facial aging and rejuvenation via diffusion models,
S. Zhu, B. Cao, Z. Ouyang, Z. Li, P.-T. Jiang, and Q. Hou, “AgeBooth: Controllable facial aging and rejuvenation via diffusion models,” 2025
2025
-
[18]
Pluralistic aging diffusion autoencoder,
P. Li, R. Wang, H. Huang, R. He, and Z. He, “Pluralistic aging diffusion autoencoder,” inICCV, 2023
2023
-
[19]
Age-dependent face diversification via latent space analysis,
T. Ito, Y . Endo, and Y . Kanamori, “Age-dependent face diversification via latent space analysis,”The Visual Computer, 2023
2023
-
[20]
The aging multiverse: Generating condition-aware facial aging tree via training-free diffusion,
B. Gong, L. Qi, J. Wu, Z. Fuet al., “The aging multiverse: Generating condition-aware facial aging tree via training-free diffusion,”arXiv preprint arXiv:2506.21008, 2025
-
[21]
Lifespan age transformation synthesis,
R. Or-El, S. Sengupta, O. Fried, E. Shechtman, and I. Kemelmacher- Shlizerman, “Lifespan age transformation synthesis,” inECCV, 2020
2020
-
[22]
arXiv preprint arXiv:2408.15922 , year=
J. Wahid, F. Zhan, P. Rao, and C. Theobalt, “DiffAge3D: Diffusion- based 3D-aware face aging,”arXiv preprint arXiv:2408.15922, 2024
-
[23]
MyTimeMachine: Personalized facial age transformation,
L. Qi, J. Wu, A. N. Wang, S. Wang, and R. Sengupta, “MyTimeMachine: Personalized facial age transformation,”SIGGRAPH, 2025
2025
-
[24]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,”NeurIPS, vol. 30, 2017
2017
-
[25]
Ssr-encoder: Encoding selective subject represen- tation for subject-driven generation,
Y . Zhang, Y . Song, J. Liu, R. Wang, J. Yu, H. Tang, H. Li, X. Tang, Y . Hu, H. Panet al., “Ssr-encoder: Encoding selective subject represen- tation for subject-driven generation,” inCVPR, 2024
2024
-
[26]
DEX: Deep EXpectation of apparent age from a single image,
R. Rothe, R. Timofte, and L. Van Gool, “DEX: Deep EXpectation of apparent age from a single image,” inICCV Workshop, 2015
2015
-
[27]
Arcface: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” inCVPR, 2019, pp. 4690–4699
2019
-
[28]
Facexformer: A unified transformer for facial analysis,
K. Narayan, V . VS, R. Chellappa, and V . M. Patel, “Facexformer: A unified transformer for facial analysis,” inICCV, 2025
2025
-
[29]
Diffusion autoencoders: Toward a meaningful and decodable represen- tation,
K. Preechakul, N. Chatthee, S. Wizadwongsa, and S. Suwajanakorn, “Diffusion autoencoders: Toward a meaningful and decodable represen- tation,” inCVPR, 2022, pp. 10 619–10 629
2022
-
[30]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inICLR, 2021
2021
-
[31]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” inNeurIPS Workshop, 2021
2021
-
[32]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,”NeurIPS, vol. 34, 2021
2021
-
[33]
Analyzing and improving the image quality of stylegan,
T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila, “Analyzing and improving the image quality of stylegan,” inCVPR, 2020
2020
-
[34]
Only a matter of style: Age transformation using a style-based regression model,
Y . Alaluf, O. Patashnik, and D. Cohen-Or, “Only a matter of style: Age transformation using a style-based regression model,” inACM SIGGRAPH, 2021
2021
-
[35]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inCVPR, 2022
2022
-
[36]
Stablegarment: Garment-centric generation via stable diffusion,
R. Wang, H. Guo, J. Liu, H. Li, H. Zhao, X. Tang, Y . Hu, H. Tang, and P. Li, “Stablegarment: Garment-centric generation via stable diffusion,” arXiv preprint arXiv:2403.10783, 2024
-
[37]
SelfAge: Personalized facial age transformation using self-reference images,
T. Ito, Y . Endo, and Y . Kanamori, “SelfAge: Personalized facial age transformation using self-reference images,”The Visual Computer, vol. 41, pp. 6769–6781, 2025
2025
-
[38]
Age progression/regression by condi- tional adversarial autoencoder,
Z. Zhang, Y . Song, and H. Qi, “Age progression/regression by condi- tional adversarial autoencoder,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 5810–5818
2017
-
[39]
Face aging with identity- preserved conditional generative adversarial networks,
Z. Wang, X. Tang, W. Luo, and S. Gao, “Face aging with identity- preserved conditional generative adversarial networks,” inCVPR, 2018
2018
-
[40]
PFA-GAN: Progressive face aging with generative adversarial network,
Z. Huang, S. Chen, J. Zhang, and H. Shan, “PFA-GAN: Progressive face aging with generative adversarial network,”IEEE TIFS, 2021
2021
-
[41]
High resolution face age editing,
X. Yao, G. Puy, A. Newson, Y . Gousseau, and P. Hellier, “High resolution face age editing,” inICPR, 2021
2021
-
[42]
Re-aging GAN: Toward personalized face age transformation,
F. Makhmudkhujaev, S. Hong, and I. K. Park, “Re-aging GAN: Toward personalized face age transformation,” inICCV, 2021
2021
-
[43]
Multimodal face aging framework via learning disentangled representation,
L. Liu, S. Wang, L. Wan, and H. Yu, “Multimodal face aging framework via learning disentangled representation,”Journal of Visual Communi- cation and Image Representation, 2022
2022
-
[44]
Diverse and lifespan facial age transformation synthesis with identity variation rationality metric,
J.-C. Xie, J. Yang, W. Wang, F. Xu, J. Xiong, and H. Gao, “Diverse and lifespan facial age transformation synthesis with identity variation rationality metric,” 2024
2024
-
[45]
Diffusion posterior sampling for general noisy inverse problems,
H. Chung, J. Kim, M. T. McCann, M. L. Klasky, and J. C. Ye, “Diffusion posterior sampling for general noisy inverse problems,” inICLR, 2023
2023
-
[46]
Loss-guided diffusion models for plug-and-play con- trollable generation,
J. Song, Q. Zhang, H. Yin, M. Mardani, M.-Y . Liu, J. Kautz, Y . Chen, and A. Vahdat, “Loss-guided diffusion models for plug-and-play con- trollable generation,” inICML, 2023
2023
-
[47]
FreeDoM: Training- free energy-guided conditional diffusion model,
J. Yu, Y . Wang, C. Zhao, B. Ghanem, and J. Zhang, “FreeDoM: Training- free energy-guided conditional diffusion model,” inICCV, 2023
2023
-
[48]
Universal guidance for diffusion models,
A. Bansal, H.-M. Chu, A. Schwarzschild, S. Sengupta, M. Goldblum, J. Geiping, and T. Goldstein, “Universal guidance for diffusion models,” inCVPR Workshops, 2023
2023
-
[49]
Manifold preserving guided diffusion,
Y . He, N. Murata, C.-H. Lai, Y . Takida, T. Uesaka, D. Kim, W.-H. Liao, Y . Mitsufuji, J. Z. Kolter, R. Salakhutdinov, and S. Ermon, “Manifold preserving guided diffusion,” inICLR, 2024
2024
-
[50]
End-to-end diffusion latent optimization improves classifier guidance,
B. Wallace, A. Gokul, S. Ermon, and N. Naik, “End-to-end diffusion latent optimization improves classifier guidance,” inICCV, 2023
2023
-
[51]
Diffusion models already have a semantic latent space,
M. Kwon, J. Jeong, and Y . Uh, “Diffusion models already have a semantic latent space,” inICLR, 2023
2023
-
[52]
Cross-age reference coding for age-invariant face recognition and retrieval,
B.-C. Chen, C.-S. Chen, and W. H. Hsu, “Cross-age reference coding for age-invariant face recognition and retrieval,” inECCV, 2014
2014
-
[53]
AgeDB: The first manually collected, in-the-wild age database,
S. Moschoglou, A. Papaioannou, C. Sagonas, J. Deng, I. Kotsia, and S. Zafeiriou, “AgeDB: The first manually collected, in-the-wild age database,” inCVPR Workshops, 2017
2017
-
[54]
FaceNet: A unified embedding for face recognition and clustering,
F. Schroff, D. Kalenichenko, and J. Philbin, “FaceNet: A unified embedding for face recognition and clustering,” inCVPR, 2015
2015
-
[55]
Age-invariant face recognition,
U. Park, Y . Tong, and A. K. Jain, “Age-invariant face recognition,”IEEE TPAMI, 2010
2010
-
[56]
Disentangled lifespan face synthesis,
S. He, W. Liao, M. Y . Yang, Y .-Z. Song, B. Rosenhahn, and T. Xiang, “Disentangled lifespan face synthesis,” inICCV, 2021
2021
-
[57]
Custom structure preservation in face aging,
G. Gomez-Trenado, S. Lathuili `ere, P. Mesejo, and ´O. Cord ´on, “Custom structure preservation in face aging,” inECCV. Springer, 2022
2022
-
[58]
AgeTransGAN for facial age transformation with rectified performance metrics,
G.-S. J. Hsu, R.-C. Xie, Z.-T. Chen, and Y .-H. Lin, “AgeTransGAN for facial age transformation with rectified performance metrics,” inECCV, 2022
2022
-
[59]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in CVPR, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.