Trade-offs in Medical LLM Adaptation: An Empirical Study in French QA
Pith reviewed 2026-06-26 20:58 UTC · model grok-4.3
The pith
For French medical multiple-choice QA, supervised fine-tuning alone matches or nearly matches the gains from adding continual pretraining, while open-ended QA shows different trade-offs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
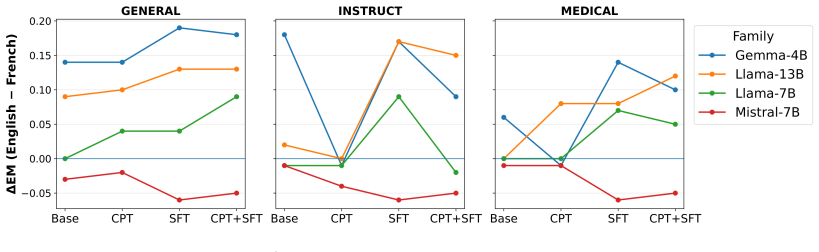
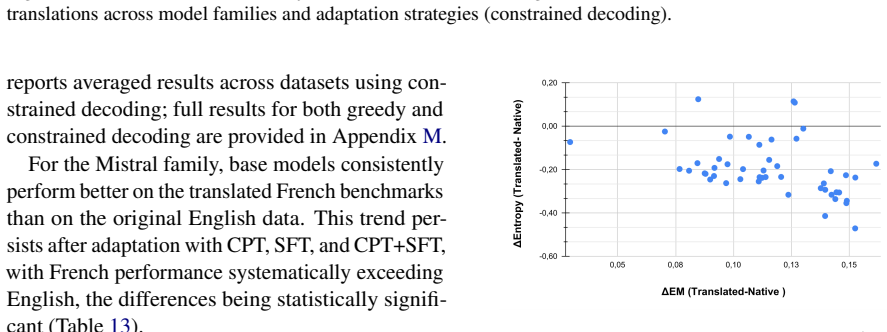
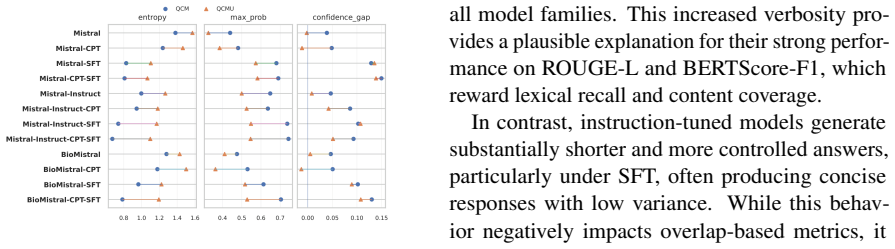
Across three model families, CPT+SFT most often records the highest scores on multiple-choice medical QA, yet the margin over SFT alone is small and frequently fails to reach statistical significance; therefore SFT constitutes a strong, lower-cost default. On open-ended QA, CPT reliably raises overlap-based automatic metrics, whereas SFT tends to reduce generation quality; instruction tuning and the combined CPT+SFT route receive higher preference under LLM-as-a-Judge evaluation. Adaptation performed on French data transfers positively to English medical benchmarks.
What carries the argument
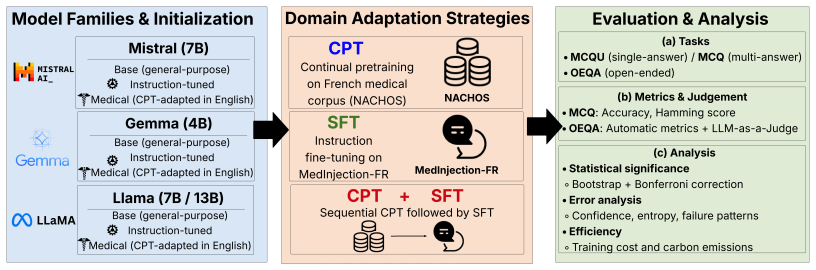
Head-to-head comparison of continual pretraining (CPT), supervised fine-tuning (SFT), and CPT+SFT on French medical MCQA and OEQA datasets, disentangling effects from base model choice and initialization.
If this is right
- Under compute constraints, practitioners can default to SFT for multiple-choice medical QA without expecting large further gains from CPT.
- For open-ended generation, CPT should be retained if overlap metrics matter, while SFT may need to be skipped or paired with instruction tuning.
- French-domain adaptation produces measurable positive transfer to English medical QA benchmarks.
- Model size and family interact with adaptation strategy, so results should be checked per architecture rather than assumed universal.
Where Pith is reading between the lines
- The same trade-off pattern may appear in other low-resource languages when medical corpora are similarly scarce.
- If clinical deployment values factual correctness over surface overlap, the preference for instruction-tuned or combined routes on OEQA would matter more than the automatic scores suggest.
- Future work could test whether the small CPT+SFT margin persists when the base models are already instruction-tuned on general medical English data.
Load-bearing premise
The selected French medical QA datasets together with the automatic metrics and LLM-as-a-Judge protocol give unbiased, representative measures of adaptation quality and clinical utility.
What would settle it
A human expert evaluation of the same model outputs on a held-out clinical French QA set that contradicts the ranking produced by the LLM judge or by the overlap metrics.
Figures

read the original abstract
The development of large language models (LLMs) has led to an increased focus on their adaptation to specialized domains and languages, yet the effectiveness of domain adaptation strategies remains unclear. We present a study of medical domain adaptation using French medical question-answering (QA) as a case study. We compare continual pretraining (CPT), supervised fine-tuning (SFT), and their combination across three model families, multiple sizes, and three initialization types, explicitly disentangling adaptation effects from base model choice. We evaluate both multiple-choice (MCQA) and open-ended QA (OEQA) under greedy and constrained decoding using automatic metrics and LLM-as-a-Judge evaluation. For MCQA, CPT+SFT most often achieves the best scores, but gains over SFT are small and frequently not statistically significant, making SFT a strong and cost-effective default. For OEQA, CPT consistently improves overlap-based metrics, while SFT often degrades generation quality; instruction tuning and CPT+SFT are preferred by LLM-based evaluation. Cross-lingual experiments further show effective transfer from French adaptation to English benchmarks. Overall, we provide practical guidelines for selecting adaptation strategies under computational constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an empirical study of medical domain adaptation for French QA, comparing continual pretraining (CPT), supervised fine-tuning (SFT), and CPT+SFT across three model families, multiple sizes, and initialization types. It disentangles adaptation effects from base model choice and evaluates MCQA and OEQA using automatic metrics plus LLM-as-a-Judge under greedy and constrained decoding, plus cross-lingual transfer to English. Key findings are that CPT+SFT most often wins on MCQA but gains over SFT are small and frequently insignificant (making SFT a cost-effective default), while CPT improves overlap metrics on OEQA but SFT can degrade generation quality (with instruction tuning and CPT+SFT preferred by LLM judges).
Significance. If the comparative results hold, the work supplies actionable guidelines for choosing adaptation strategies under compute constraints in specialized domains. Strengths include the explicit disentanglement of adaptation from base-model effects, the hedging on statistical significance of small gains, the distinction between metric types (overlap vs. LLM judge), and the cross-lingual transfer experiments; these elements make the ablation more informative than typical single-model studies.
major comments (2)
- [Methods / Results] Methods section: the abstract and results claim statistical significance tests and cross-lingual transfer, yet no details appear on dataset sizes, exclusion criteria, exact tests (e.g., paired t-test or bootstrap), multiple-comparison correction, or error bars; this information is load-bearing for the central claim that CPT+SFT gains over SFT are “frequently not statistically significant.”
- [Evaluation / OEQA results] Evaluation protocol (OEQA subsection): reliance on LLM-as-a-Judge without a reported human validation subset or inter-annotator agreement on a medical sample risks systematic bias, especially since the paper notes imperfect correlation with human judgment; this directly affects the claim that instruction tuning and CPT+SFT are preferred.
minor comments (2)
- [Tables] Table captions and axis labels should explicitly state the number of runs or seeds used for each reported score to allow readers to assess variability.
- [Cross-lingual experiments] The cross-lingual transfer paragraph would benefit from a short statement on whether the English benchmarks were seen during any pretraining stage of the base models.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript's significance and for the constructive feedback. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods / Results] Methods section: the abstract and results claim statistical significance tests and cross-lingual transfer, yet no details appear on dataset sizes, exclusion criteria, exact tests (e.g., paired t-test or bootstrap), multiple-comparison correction, or error bars; this information is load-bearing for the central claim that CPT+SFT gains over SFT are “frequently not statistically significant.”
Authors: We agree that the statistical analysis details were insufficiently reported. The revised manuscript will add the missing information, including dataset sizes for each experiment and language, exclusion criteria for QA samples, the precise tests used (paired t-tests with bootstrap resampling), multiple-comparison correction (Bonferroni), and error bars or confidence intervals on all relevant figures and tables. These additions will directly support the claims about the (non-)significance of CPT+SFT gains over SFT alone. revision: yes
-
Referee: [Evaluation / OEQA results] Evaluation protocol (OEQA subsection): reliance on LLM-as-a-Judge without a reported human validation subset or inter-annotator agreement on a medical sample risks systematic bias, especially since the paper notes imperfect correlation with human judgment; this directly affects the claim that instruction tuning and CPT+SFT are preferred.
Authors: We acknowledge the risk of systematic bias when relying solely on LLM-as-a-Judge for medical content. The original text already notes the imperfect correlation with human judgment. In revision we will add a human validation study on a representative subset of the OEQA outputs, reporting inter-annotator agreement, to strengthen the preference claims for instruction tuning and CPT+SFT. If the added study confirms the LLM-judge rankings, we will state this explicitly; otherwise we will qualify the claims accordingly. revision: yes
Circularity Check
No circularity: purely empirical ablation study
full rationale
The paper is an empirical comparison of CPT, SFT, and CPT+SFT across model families, sizes, and initialization types on French medical QA datasets. All reported results (MCQA/OEQA scores, statistical significance, LLM-as-Judge preferences, cross-lingual transfer) are direct experimental outcomes using external benchmarks and standard metrics. No derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the described content. The disentanglement of adaptation effects is achieved through controlled ablations rather than any definitional or self-referential reduction. This is a standard, self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Overlap-based automatic metrics and LLM-as-a-Judge are valid proxies for medical QA quality.
Reference graph
Works this paper leans on
-
[1]
Aryo Gema, Pasquale Minervini, Luke Daines, Tom Hope, and Beatrice Alex
Medical mt5: An open-source multilingual text-to-text llm for the medical domain.Preprint, arXiv:2404.07613. Aryo Gema, Pasquale Minervini, Luke Daines, Tom Hope, and Beatrice Alex. 2024. Parameter-efficient fine-tuning of LLaMA for the clinical domain. In Proceedings of the 6th Clinical Natural Language Processing Workshop, pages 91–104, Mexico City, Mex...
-
[2]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.Preprint, arXiv:2009.03300. Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations. Yining Huang, Keke Tang, Meilian Chen, and Boyuan W...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[3]
K-QA: A real-world medical Q&A benchmark. InProceedings of the 23rd Workshop on Biomedi- cal Natural Language Processing, pages 277–294, Bangkok, Thailand. Association for Computational Linguistics. Yulong Mao, Kaiyu Huang, Changhao Guan, Ganglin Bao, Fengran Mo, and Jinan Xu. 2024. DoRA: En- hancing parameter-efficient fine-tuning with dynamic rank distr...
-
[4]
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
JudgeLM: Fine-tuned large language models are scalable judges. InThe Thirteenth International Conference on Learning Representations. Yuxin Zuo, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. 2025. Medxpertqa: Benchmarking expert-level medical reasoning and understanding. arXiv preprint arXiv:2501.18362. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Text collection through web scraping, raw tex- tual sources, and optical character recognition (OCR)
-
[6]
Sentence splitting using heuristic methods
-
[7]
Aggressive filtering to remove short or low- quality sentences
-
[8]
The dataset comprises 571 436 examples spanning MCQUs, MCQs, and OEQAs
Language classification using a custom classi- fier trained on multilingual corpora B SFT Training Corpus : MedInjection-Fr Description B.1 Overview MedInjection-FR (Belmadani et al., 2026b) is a large-scale French biomedical instruction dataset composed of native, translated, and synthetic instruction–response pairs. The dataset comprises 571 436 example...
-
[9]
an instruction describing the task,
-
[10]
the question (and answer options when appli- cable),
-
[11]
an optional context section, and
-
[12]
a response header indicating where the model output should begin. Task-Specific Constraints.The only variation across task types lies in the expected response for- mat, which is explicitly stated in the instruction. Table 6 summarizes the templates used for each task. Canonical Prompt Format.The following ab- stract template illustrates the prompt structu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.