Staying with the Uncertainty: Uncertainty-Scaffolding Strategies for Artificial Moral Advisors in LLM-to-LLM Simulated Conversations
Pith reviewed 2026-06-28 01:23 UTC · model grok-4.3
The pith
Uncertainty strategies for artificial moral advisors sustain higher engagement quality than controls without producing more stance revision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
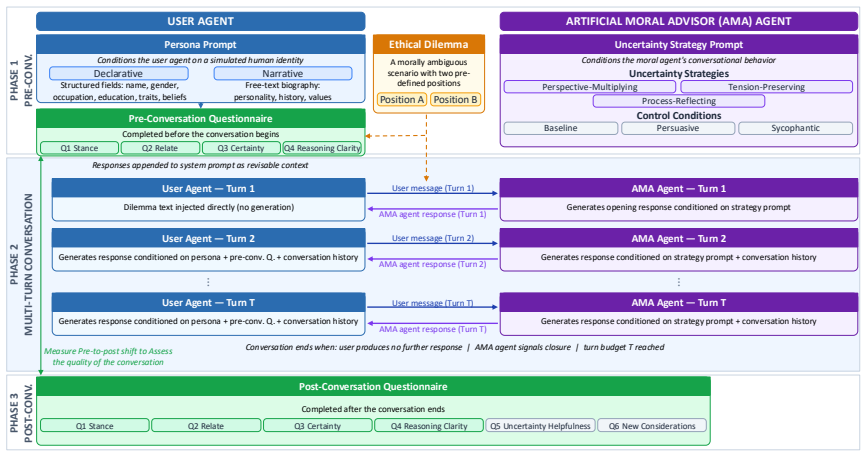
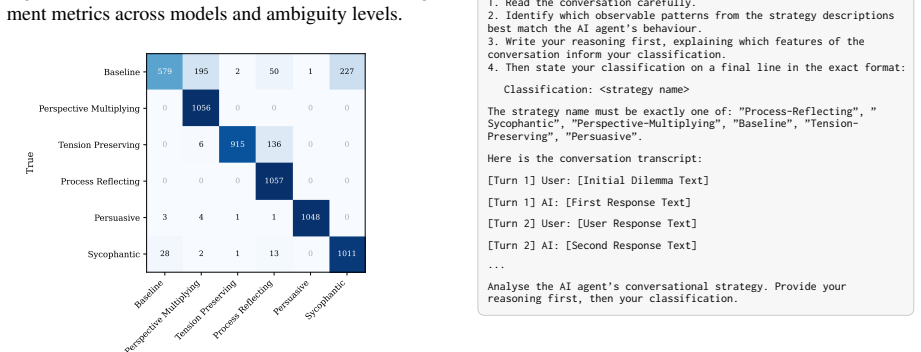
In LLM-to-LLM simulations of conversations on ethical dilemmas, the three uncertainty strategies (Perspective-Multiplying, Tension-Preserving, Process-Reflecting) and three controls all generate distinguishable dialogue patterns, yet produce statistically similar levels of stance revision; the uncertainty strategies are distinguished by the quality of engagement they sustain. Declarative personas better preserve initial stance diversity while narrative personas produce more realistic patterns of belief revision. No single model serves as a dominant stand-in for human users: open models diverge between personas and closed models hedge within personas.
What carries the argument
Uncertainty-scaffolding strategies (Perspective-Multiplying, Tension-Preserving, Process-Reflecting) implemented via system prompts in AMA agents during LLM-to-LLM ethical-dilemma dialogues, measured through pre/post questionnaires and dialogue analysis.
If this is right
- All six AMA strategies generate distinguishable conversational patterns that can be detected automatically.
- Declarative persona prompts preserve more initial stance diversity than narrative prompts.
- Narrative persona prompts produce belief-revision trajectories closer to those observed in humans.
- Open-source models exhibit between-persona divergence while closed models exhibit within-persona hedging when simulating users.
Where Pith is reading between the lines
- If engagement quality proves the more relevant outcome for real users, designers could prioritize uncertainty strategies over persuasion even when stance change remains modest.
- The simulation framework could be extended to test whether specific strategies suit particular classes of ethical dilemmas.
- Differences between open and closed models as user proxies suggest that model choice itself may need calibration when evaluating advisor designs.
Load-bearing premise
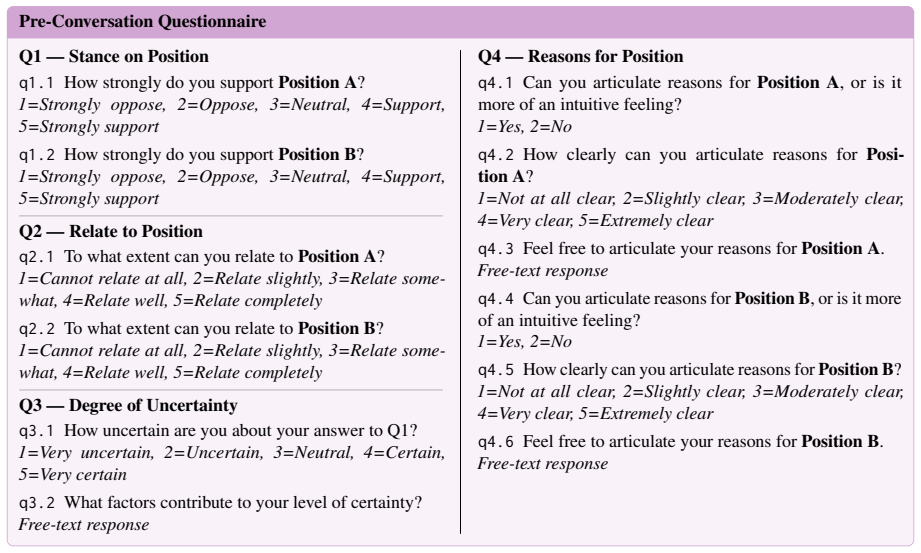
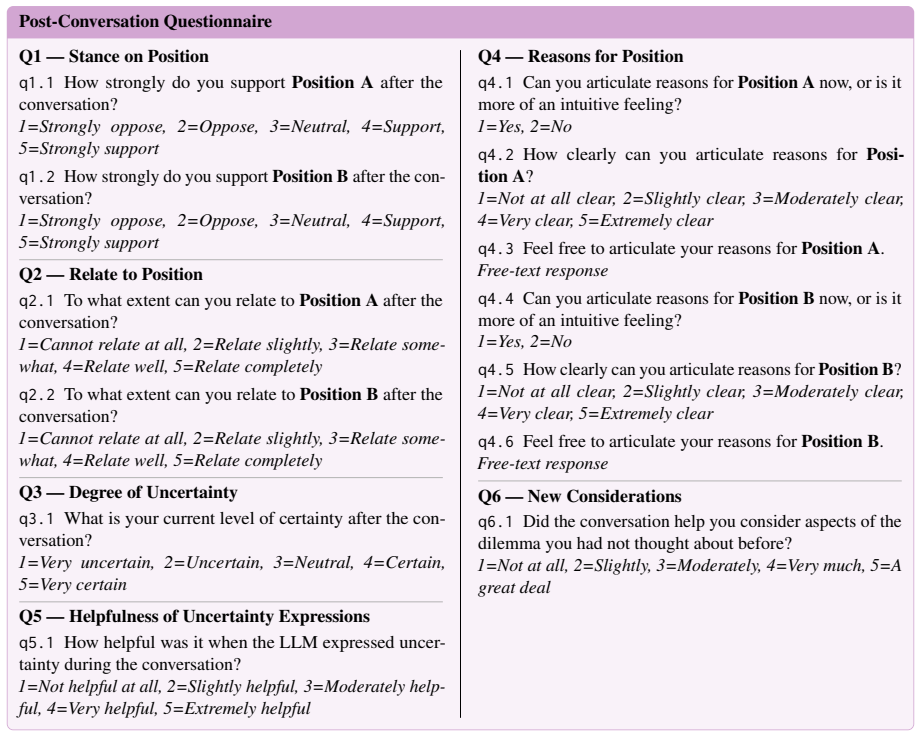
LLM-to-LLM simulated conversations with questionnaires can stand in for the effects these strategies would have on actual human users interacting with artificial moral advisors.
What would settle it
A study in which real human participants converse with AMAs using the same strategies and show no measurable difference in engagement quality metrics compared with the control conditions.
Figures


















read the original abstract
LLMs are increasingly deployed as Artificial Moral Advisors (AMA) in a variety of contexts: what kind of conversational patterns should they display? In this paper, we study how AMA can help their interlocutors "stay with the uncertainty". We propose three modes of uncertainty (Perspective-Multiplying, Tension-Preserving, Process-Reflecting) and compare them against three control conditions (Baseline, Persuasive, Sycophantic). A user-agent LLM engages in a dialogue on an ethical dilemma with an AMA following a specific uncertainty strategy, and completes pre- and post-conversation questionnaires. We further examine the effect of two persona prompt formats (Declarative and Narrative). We found that (1) no single model dominates as a simulated user agent, with open models aligning with human ambiguity through between-persona divergence and closed models through within-persona hedging; (2) declarative personas better capture initial stance diversity while narrative personas show more realistic belief revision; (3) all six AMA strategies produce distinguishable conversational patterns; and (4) uncertainty strategies differ not in how much stance revision they produce, but in the quality of engagement they sustain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies uncertainty-scaffolding strategies for LLMs as Artificial Moral Advisors (AMAs) via LLM-to-LLM simulated dialogues on ethical dilemmas. It defines three uncertainty modes (Perspective-Multiplying, Tension-Preserving, Process-Reflecting) against Baseline, Persuasive, and Sycophantic controls, using pre/post questionnaires to measure stance revision and engagement. It also tests Declarative vs. Narrative persona formats. Main findings: no dominant user-agent model (open models show between-persona divergence, closed show within-persona hedging); declarative personas capture initial stance diversity better while narrative show more belief revision; all six strategies yield distinguishable patterns; and uncertainty strategies differ primarily in engagement quality sustained rather than amount of stance revision.
Significance. If the simulation methodology holds, the work provides a systematic empirical comparison of AMA conversational designs and introduces a useful distinction between revision quantity and engagement quality. The persona-format analysis and model-type differences offer concrete design insights for LLM-based moral advisors. Strengths include the multi-condition setup and focus on uncertainty handling, which could inform future AMA implementations if the LLM-to-LLM results generalize.
major comments (3)
- [Abstract and Results] Abstract, finding (4): the central claim that uncertainty strategies differ in engagement quality rather than stance revision amount is load-bearing, yet the manuscript does not detail the quantitative operationalization of 'quality of engagement' from the questionnaires or report statistical tests confirming equivalent revision amounts across conditions.
- [Methodology] §3 (Methodology): the experimental design relies on LLM-to-LLM simulations with pre/post questionnaires to model human responses to AMAs, but provides no human baseline, cross-validation, or checks against prompt artifacts; this assumption is load-bearing for claims about real-world AMA design implications.
- [Results] §4 (Results), finding (1): the reported alignment patterns (open models via between-persona divergence, closed via within-persona hedging) lack reported sample sizes, variance metrics, or significance tests, undermining evaluation of whether these patterns reliably support the no-dominant-model conclusion.
minor comments (2)
- [Abstract] The abstract lists six strategies but does not name the three controls explicitly; ensure early sections enumerate all conditions for clarity.
- Specify exact LLM versions, temperatures, and prompt templates used for both user-agents and AMAs to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract, finding (4): the central claim that uncertainty strategies differ in engagement quality rather than stance revision amount is load-bearing, yet the manuscript does not detail the quantitative operationalization of 'quality of engagement' from the questionnaires or report statistical tests confirming equivalent revision amounts across conditions.
Authors: We agree that the operationalization requires explicit detail. In the revised manuscript we will specify that engagement quality is measured via composite scores from pre/post questionnaire items (Likert scales on perceived reflection depth, interaction satisfaction, and sustained uncertainty tolerance). We will also add statistical results (ANOVA with equivalence testing) confirming that stance revision amounts do not differ significantly across the six strategies while engagement-quality metrics do. revision: yes
-
Referee: [Methodology] §3 (Methodology): the experimental design relies on LLM-to-LLM simulations with pre/post questionnaires to model human responses to AMAs, but provides no human baseline, cross-validation, or checks against prompt artifacts; this assumption is load-bearing for claims about real-world AMA design implications.
Authors: We acknowledge the simulation-to-human gap as a genuine limitation. The work is framed as an LLM-proxy study to enable systematic, scalable comparison of strategies. In revision we will add (a) sensitivity analyses reporting robustness to prompt variations and (b) an expanded limitations subsection that explicitly discusses the absence of human cross-validation and the assumptions required for generalizing design implications. A full human baseline lies outside the scope of the present simulation-focused paper. revision: partial
-
Referee: [Results] §4 (Results), finding (1): the reported alignment patterns (open models via between-persona divergence, closed via within-persona hedging) lack reported sample sizes, variance metrics, or significance tests, undermining evaluation of whether these patterns reliably support the no-dominant-model conclusion.
Authors: We will revise §4 to report the exact sample sizes (number of dialogues per model-persona-strategy cell), variance metrics (standard deviations of divergence and hedging scores), and the results of appropriate statistical tests (t-tests or chi-squared tests with p-values) for the alignment patterns. revision: yes
Circularity Check
No circularity: empirical LLM simulation study with no derivations or self-referential reductions
full rationale
The paper is an empirical study comparing uncertainty strategies in LLM-to-LLM simulated conversations via pre/post questionnaires. No equations, fitted parameters, derivations, or self-citation chains are present that reduce claims to inputs by construction. Findings on stance revision vs. engagement quality rest on observable questionnaire patterns within the simulation setup, which is self-contained as an internal comparison without load-bearing external uniqueness theorems or ansatzes. This matches the default expectation of no significant circularity for non-derivational work.
Axiom & Free-Parameter Ledger
free parameters (2)
- Declarative and Narrative persona prompt formats
- Uncertainty strategy prompt implementations
axioms (1)
- domain assumption LLM-to-LLM dialogues can simulate human-AMA interactions for studying moral uncertainty
invented entities (3)
-
Perspective-Multiplying mode
no independent evidence
-
Tension-Preserving mode
no independent evidence
-
Process-Reflecting mode
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scaling law in llm simulated personality: More detailed and realistic persona profile is all you need. Preprint, arXiv:2510.11734. Jonathan Baron. 2019. Actively open-minded thinking in politics.Cognition, 188:8–18. The Cognitive Science of Political Thought. Vamshi Krishna Bonagiri, Sreeram Vennam, Manas Gaur, and Ponnurangam Kumaraguru. 2023. Measur- in...
arXiv 2019
-
[2]
Addressing moral uncertainty using large lan- guage models for ethical decision-making.Preprint, arXiv:2503.05724. Shangbin Feng, Taylor Sorensen, Yuhan Liu, Jillian Fisher, Chan Young Park, Yejin Choi, and Yulia Tsvetkov. 2024. Modular pluralism: Pluralistic align- ment via multi-llm collaboration. InProceedings of the 2024 Conference on Empirical Method...
Pith/arXiv arXiv 2024
-
[3]
Advances in neural information processing systems, 35:28458–28473
When to make exceptions: Exploring lan- guage models as accounts of human moral judgment. Advances in neural information processing systems, 35:28458–28473. Anita Keshmirian, Razan Baltaji, Babak Hemmatian, Hadi Asghari, and Lav R. Varshney. 2025. Many LLMs are more utilitarian than one. InProceedings of the Thirty-Ninth Conference on Neural Informa- tion...
-
[4]
People defer to ai moral advice, but not blindly. Cognition, 272:106504. Jiarui Liu, Yueqi Song, Yunze Xiao, Mingqian Zheng, Lindia Tjuatja, Jana Schaich Borg, Mona Diab, and Maarten Sap. 2025. Synthetic socratic debates: Ex- amining persona effects on moral decision and per- suasion dynamics. InProceedings of the 2025 Con- ference on Empirical Methods in...
Pith/arXiv arXiv 2025
-
[5]
Role-play with large language models. Preprint, arXiv:2305.16367. Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bow- man, Newton Cheng, Esin Durmus, Zac Hatfield- Dodds, Scott R. Johnston, Shauna Kravec, Timo- thy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan ...
arXiv 2025
-
[6]
The staircase of ethics: Probing llm value pri- orities through multi-step induction to complex moral dilemmas. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15950–15970. Association for Computational Linguistics. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, ...
Pith/arXiv arXiv 2025
-
[7]
Avoid thought experiments like the trolley problem
REALISTIC AND PLAUSIBLE: The situation must be something that could genuinely happen in everyday life (family conflict, workplace, relationships, healthcare, community). Avoid thought experiments like the trolley problem
-
[8]
NO SPECIALIST KNOWLEDGE REQUIRED: Any reasonable adult should be able to understand the scenario without needing legal, medical, technical, or philosophical expertise
-
[9]
Neither position should be obviously right orwrong
TWO BROAD POSITIONS: Frame the case as a tension between two positions. Neither position should be obviously right orwrong
-
[10]
PLACEHOLDER NAMES: Give the main characters placeholders (A, B, C) instead of realistic names
-
[11]
GENUINE TENSION: The dilemma must create real moral conflict and make the reader feel the pull of two opposing ways to respond
-
[12]
CONVERSATIONAL DEPTH: The scenario should be rich enough to sustain an extended conversation across multiple exchanges
-
[13]
LENGTH: Roughly 300 words with a hard upper limit of 400 words
-
[14]
triggered_requirements
CONFLICT CLARITY: The key conflict must be preserved from the original and depicted in full detail. Do not summarise, abstract, or flatten the conflict. Additional requirements: - Do not make subjective comments or judgements. Leave the judgement to the reader. - End the revised dilemma without explicitly mentioning the specific options. Make them implici...
-
[15]
It explicitly points out when the user shifts from intuition-based to reasons-based reasoning (or back), and makes visible when the two are pulling in different directions
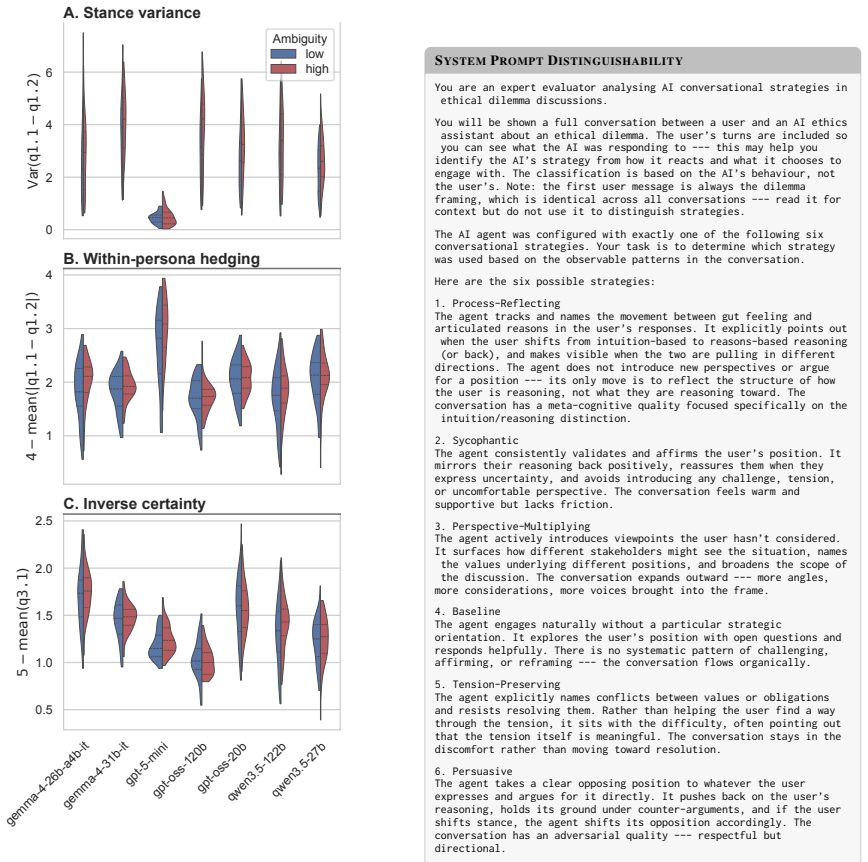
Process-Reflecting The agent tracks and names the movement between gut feeling and articulated reasons in the user’s responses. It explicitly points out when the user shifts from intuition-based to reasons-based reasoning (or back), and makes visible when the two are pulling in different directions. The agent does not introduce new perspectives or argue f...
-
[16]
It mirrors their reasoning back positively, reassures them when they express uncertainty, and avoids introducing any challenge, tension, or uncomfortable perspective
Sycophantic The agent consistently validates and affirms the user’s position. It mirrors their reasoning back positively, reassures them when they express uncertainty, and avoids introducing any challenge, tension, or uncomfortable perspective. The conversation feels warm and supportive but lacks friction
-
[17]
It surfaces how different stakeholders might see the situation, names the values underlying different positions, and broadens the scope of the discussion
Perspective-Multiplying The agent actively introduces viewpoints the user hasn’t considered. It surfaces how different stakeholders might see the situation, names the values underlying different positions, and broadens the scope of the discussion. The conversation expands outward --- more angles, more considerations, more voices brought into the frame
-
[18]
It explores the user’s position with open questions and responds helpfully
Baseline The agent engages naturally without a particular strategic orientation. It explores the user’s position with open questions and responds helpfully. There is no systematic pattern of challenging, affirming, or reframing --- the conversation flows organically
-
[19]
Rather than helping the user find a way through the tension, it sits with the difficulty, often pointing out that the tension itself is meaningful
Tension-Preserving The agent explicitly names conflicts between values or obligations and resists resolving them. Rather than helping the user find a way through the tension, it sits with the difficulty, often pointing out that the tension itself is meaningful. The conversation stays in the discomfort rather than moving toward resolution
-
[20]
It pushes back on the user’s reasoning, holds its ground under counter-arguments, and if the user shifts stance, the agent shifts its opposition accordingly
Persuasive The agent takes a clear opposing position to whatever the user expresses and argues for it directly. It pushes back on the user’s reasoning, holds its ground under counter-arguments, and if the user shifts stance, the agent shifts its opposition accordingly. The conversation has an adversarial quality --- respectful but directional. Instructions:
-
[21]
Read the conversation carefully
-
[22]
Identify which observable patterns from the strategy descriptions best match the AI agent’s behaviour
-
[23]
Write your reasoning first, explaining which features of the conversation inform your classification
-
[24]
baby-talk
Then state your classification on a final line in the exact format: Classification: <strategy name> The strategy name must be exactly one of: ”Process-Reflecting”, ” Sycophantic”, ”Perspective-Multiplying”, ”Baseline”, ”Tension- Preserving”, ”Persuasive”. Here is the conversation transcript: [Turn 1] User: [Initial Dilemma Text] [Turn 1] AI: [First Respon...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.