DualEval: Joint Model-Item Calibration for Unified LLM Evaluation
Pith reviewed 2026-06-26 01:12 UTC · model grok-4.3
The pith
DualEval jointly calibrates LLMs and items in one latent space from static labels plus preference scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
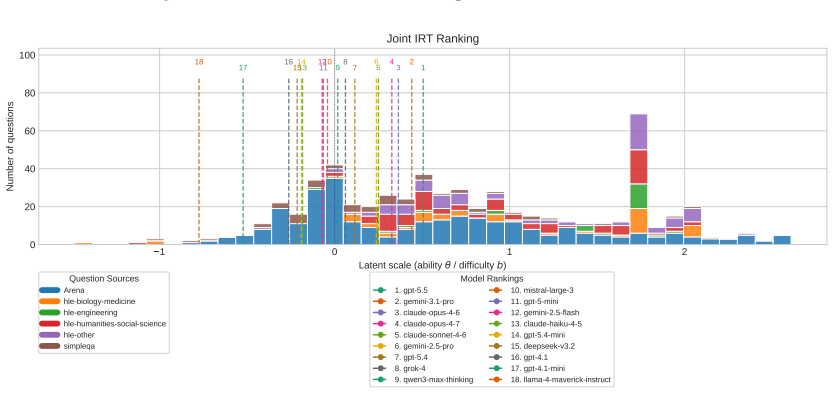
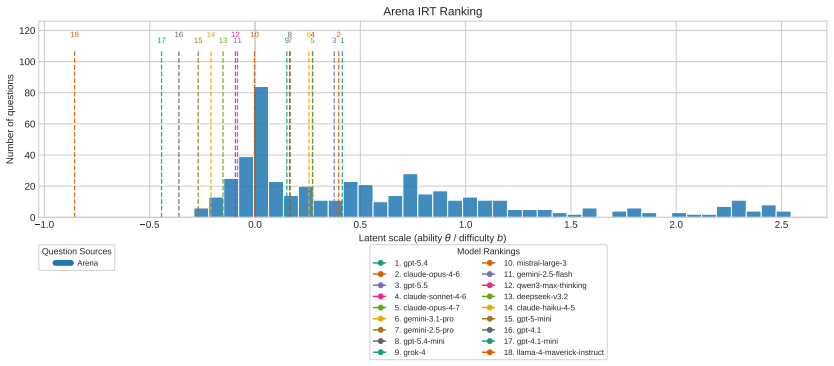
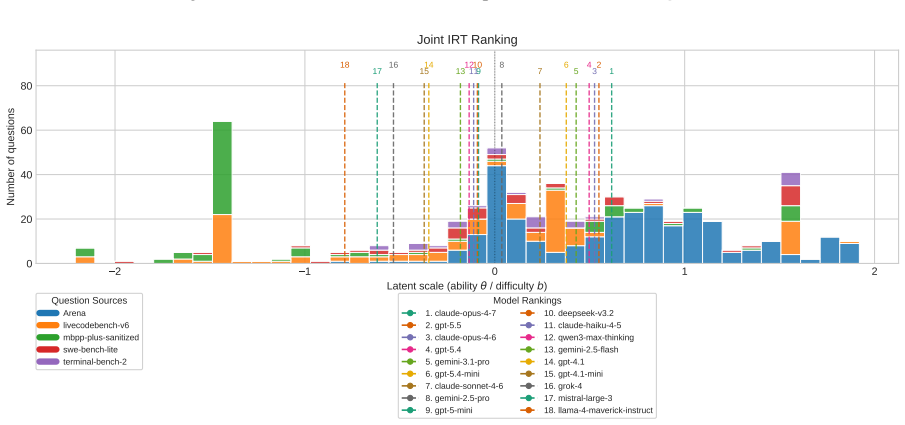
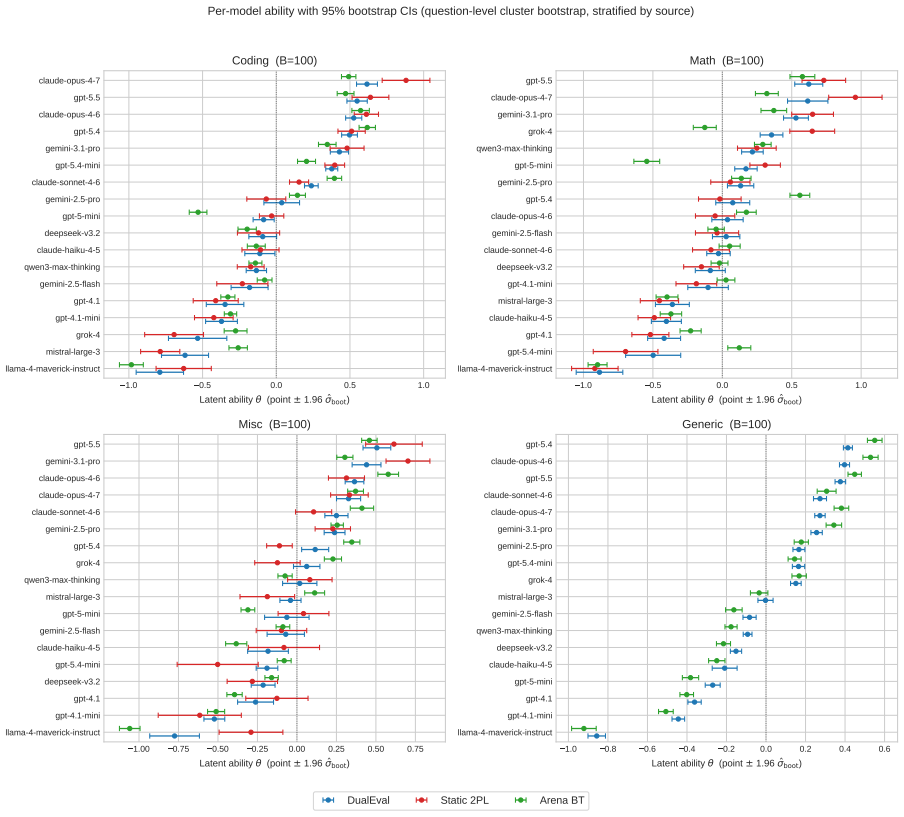
DualEval is a latent model-item calibration framework that represents models and evaluation items in a shared space, jointly estimating model ability together with item difficulty and sharpness from a mixture of static correctness labels and reward-model scores validated against held-out human preferences across coding, math, knowledge, and open-ended query domains.
What carries the argument
The shared latent space in which model ability, item difficulty, and item sharpness are jointly recovered from mixed static and preference signals.
If this is right
- Model rankings become reliable and balanced across four distinct domains using the combined signals.
- Learned item profiles enable benchmark compression that preserves ranking accuracy with fewer samples.
- Item-level diagnostics support anomaly detection for contamination or outlier items.
- The unified pipeline yields more sample-efficient and auditable evaluation than disconnected static or arena methods.
Where Pith is reading between the lines
- The same joint calibration could be tested on non-text modalities to check whether the latent-space approach generalizes.
- Item sharpness estimates might enable adaptive item selection during evaluation to further reduce sample needs.
- The framework's item profiles could be used to track how benchmark difficulty drifts over time as models improve.
Load-bearing premise
Model ability, item difficulty, and sharpness can be jointly recovered from the mixture of static labels and validated reward-model scores.
What would settle it
If DualEval rankings on held-out human preferences match actual preferences no better than rankings from static benchmarks or arena data alone, the joint-calibration benefit is falsified.
Figures
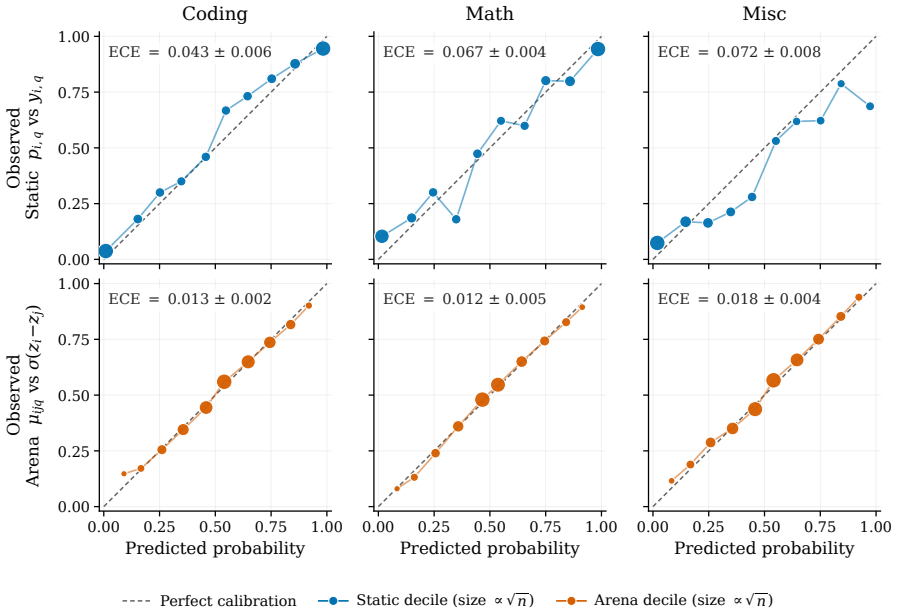
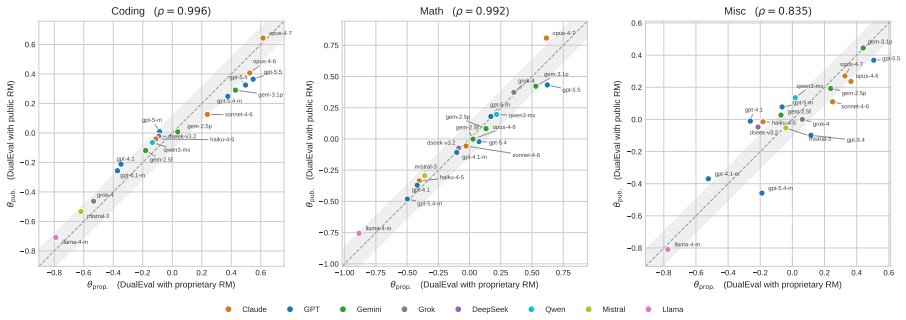
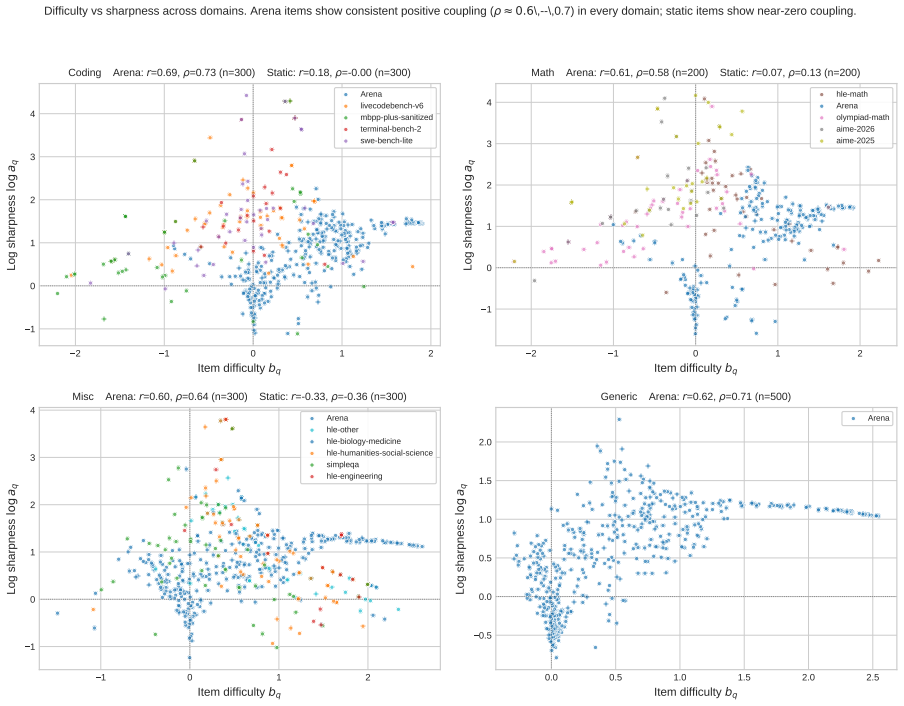
read the original abstract
Current LLM evaluation relies on two complementary but often disconnected signals: static benchmarks with objective correctness labels and arena-style preference data that better reflect open-ended user interactions. We introduce DualEval, a latent model-item calibration framework that represents models and evaluation items in a shared space, jointly estimating model ability together with item difficulty and sharpness. We apply DualEval across four domains: coding, math, miscellaneous domain-knowledge tasks, and generic everyday user queries. Our evaluation uses 18 frontier LLMs, static benchmark labels, and reward-model scores validated against held-out human preferences for open-ended model responses. Empirically, our framework produces reliable and balanced model rankings, and its learned item-level profiles support downstream applications such as benchmark compression for sample-efficient evaluation and anomaly detection for contamination or outlier analysis. Overall, DualEval unifies static and arena-style evaluation through joint model-item calibration, producing model rankings and item-level diagnostics that support more sample-efficient, interpretable, and auditable evaluation pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DualEval, a latent-variable framework for joint model-item calibration that places LLMs and evaluation items in a shared space. It estimates model ability θ together with per-item difficulty b and sharpness a by combining binary correctness labels from static benchmarks with continuous reward-model scores on open-ended responses (validated against held-out human preferences). The method is applied to 18 frontier LLMs across coding, math, miscellaneous knowledge, and everyday-query domains, with claims that the resulting rankings are reliable and balanced while the item profiles enable benchmark compression and anomaly detection.
Significance. If the joint recovery is statistically valid and identifiable, the work would offer a principled unification of objective and preference-based evaluation signals, potentially improving sample efficiency and providing item-level diagnostics that static or arena-only pipelines lack. The use of held-out human preference validation is a constructive element.
major comments (2)
- [Method / Model specification] The manuscript does not state an explicit joint likelihood that maps both binary static correctness observations and continuous reward scores onto the same (θ_model, b_item, a_item) parameters. Without a defined observation model (e.g., logistic for binary, Gaussian or Bradley-Terry for rewards) and a demonstration that the two data types are tied to a common latent space, the recovered quantities may be dominated by the stronger signal or fail to be consistent across domains.
- [Model specification / Experiments] No identifiability argument or anchoring procedure is provided to resolve the inherent scale and location indeterminacy of the latent space when parameters are estimated from the mixed data sources. This directly affects the reliability of the reported model rankings and item profiles.
minor comments (1)
- [Abstract / Introduction] The abstract and early sections should include a short equation or diagram that shows how the two observation types enter the likelihood; this would immediately clarify the construction for readers.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on model specification. We address each major comment below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Method / Model specification] The manuscript does not state an explicit joint likelihood that maps both binary static correctness observations and continuous reward scores onto the same (θ_model, b_item, a_item) parameters. Without a defined observation model (e.g., logistic for binary, Gaussian or Bradley-Terry for rewards) and a demonstration that the two data types are tied to a common latent space, the recovered quantities may be dominated by the stronger signal or fail to be consistent across domains.
Authors: We agree that an explicit joint likelihood was not stated in sufficient detail. The revised manuscript will add a dedicated subsection under the model description that specifies the full observation model: a Bernoulli likelihood with logistic link for the binary static correctness labels and a Gaussian likelihood for the continuous reward-model scores, both parameterized through the shared latent variables (θ, b, a). We will also include a short consistency check across the four domains to address potential signal dominance. revision: yes
-
Referee: [Model specification / Experiments] No identifiability argument or anchoring procedure is provided to resolve the inherent scale and location indeterminacy of the latent space when parameters are estimated from the mixed data sources. This directly affects the reliability of the reported model rankings and item profiles.
Authors: We acknowledge that an explicit identifiability discussion and anchoring procedure were omitted. In the revision we will add a paragraph explaining the indeterminacy and the anchoring strategy we employ (fixing the mean of θ across models to zero while using one reference item per domain to set the location), together with a brief sensitivity analysis showing that the reported rankings remain stable under alternative anchors. revision: yes
Circularity Check
No circularity: joint latent calibration is a standard estimation procedure with external validation cited.
full rationale
The abstract describes DualEval as a latent-variable model jointly estimating ability, difficulty, and sharpness from mixed binary labels and reward scores, with the reward model itself validated on held-out human preferences. No equations, self-citations, or fitted-input-as-prediction steps are present in the provided text. The central outputs (rankings, item profiles) are direct consequences of maximum-likelihood or similar estimation on the observed data, not reductions by definition or self-referential loops. External held-out validation breaks any potential circularity between estimation and reported diagnostics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Forty-first International Conference on Machine Learning , year=
Chatbot arena: An open platform for evaluating llms by human preference , author=. Forty-first International Conference on Machine Learning , year=
-
[2]
arXiv preprint arXiv:2203.08242 , year=
Data contamination: From memorization to exploitation , author=. arXiv preprint arXiv:2203.08242 , year=
-
[3]
Nature Communications , volume=
Mapping global dynamics of benchmark creation and saturation in artificial intelligence , author=. Nature Communications , volume=. 2022 , publisher=
2022
-
[4]
arXiv preprint arXiv:2406.11939 , year=
From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline , author=. arXiv preprint arXiv:2406.11939 , year=
-
[5]
the method of paired comparisons , author=
Rank analysis of incomplete block designs: I. the method of paired comparisons , author=. Biometrika , volume=. 1952 , publisher=
1952
-
[6]
2008 , publisher=
Statistical theories of mental test scores , author=. 2008 , publisher=
2008
-
[7]
Educational Measurement: Issues and Practice , volume=
Using multidimensional item response theory to evaluate educational and psychological tests , author=. Educational Measurement: Issues and Practice , volume=. 2003 , publisher=
2003
-
[8]
Statistical Science , volume=
Item response theory—A statistical framework for educational and psychological measurement , author=. Statistical Science , volume=. 2025 , publisher=
2025
-
[9]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[10]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[11]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[12]
arXiv preprint arXiv:1606.05250 , year=
Squad: 100,000+ questions for machine comprehension of text , author=. arXiv preprint arXiv:1606.05250 , year=
-
[13]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[14]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[15]
Proceedings of the 2015 conference on empirical methods in natural language processing , pages=
A large annotated corpus for learning natural language inference , author=. Proceedings of the 2015 conference on empirical methods in natural language processing , pages=
2015
-
[16]
Proceedings of the 2018 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long papers) , pages=
A broad-coverage challenge corpus for sentence understanding through inference , author=. Proceedings of the 2018 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long papers) , pages=
2018
-
[17]
Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , pages=
GLUE: A multi-task benchmark and analysis platform for natural language understanding , author=. Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , pages=
2018
-
[18]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[19]
arXiv preprint arXiv:2211.09110 , year=
Holistic evaluation of language models , author=. arXiv preprint arXiv:2211.09110 , year=
-
[20]
Handbook of statistics , volume=
18 Multidimensional item response theory , author=. Handbook of statistics , volume=. 2006 , publisher=
2006
-
[21]
2013 , publisher=
Item response theory for psychologists , author=. 2013 , publisher=
2013
-
[22]
Proceedings of the Conference on Empirical Methods in Natural Language Processing
Learning latent parameters without human response patterns: Item response theory with artificial crowds , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing , volume=
-
[23]
Artificial intelligence , volume=
Item response theory in AI: Analysing machine learning classifiers at the instance level , author=. Artificial intelligence , volume=. 2019 , publisher=
2019
-
[24]
arXiv preprint arXiv:2510.04051 , year=
Toward a unified framework for data-efficient evaluation of large language models , author=. arXiv preprint arXiv:2510.04051 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Mixeval: Deriving wisdom of the crowd from llm benchmark mixtures , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
arXiv preprint arXiv:2510.14966 , year=
Identity-Link IRT for Label-Free LLM Evaluation: Preserving Additivity in TVD-MI Scores , author=. arXiv preprint arXiv:2510.14966 , year=
-
[27]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[28]
arXiv preprint arXiv:2108.07732 , year=
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[29]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Lost in benchmarks? rethinking large language model benchmarking with item response theory , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[30]
arXiv preprint arXiv:2511.04689 , year=
Adaptive Testing for LLM Evaluation: A Psychometric Alternative to Static Benchmarks , author=. arXiv preprint arXiv:2511.04689 , year=
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
MetaEval: Measuring the Discrimination of Benchmarks for Efficient LLM Evaluation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[32]
arXiv preprint arXiv:2510.10457 , year=
Rethinking LLM Evaluation: Can We Evaluate LLMs with 200x Less Data? , author=. arXiv preprint arXiv:2510.10457 , year=
-
[33]
Proceedings of Machine Learning Research , volume=
Rethinking math benchmarks for llms using irt , author=. Proceedings of Machine Learning Research , volume=. 2025 , publisher=
2025
-
[34]
arXiv preprint arXiv:2601.11868 , year=
Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces , author=. arXiv preprint arXiv:2601.11868 , year=
-
[35]
International Conference on Learning Representations , volume=
Swe-bench: Can language models resolve real-world github issues? , author=. International Conference on Learning Representations , volume=
-
[36]
Proceedings of the 12th international conference on natural language generation , pages=
Best practices for the human evaluation of automatically generated text , author=. Proceedings of the 12th international conference on natural language generation , pages=
-
[37]
Proceedings of the 1st workshop on benchmarking: past, present and future , pages=
We need to consider disagreement in evaluation , author=. Proceedings of the 1st workshop on benchmarking: past, present and future , pages=
-
[38]
International Conference on Learning Representations , volume=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. International Conference on Learning Representations , volume=
-
[39]
arXiv preprint arXiv:2501.14249 , year=
Humanity's last exam , author=. arXiv preprint arXiv:2501.14249 , year=
-
[40]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[41]
arXiv preprint arXiv:2411.04368 , year=
Measuring short-form factuality in large language models , author=. arXiv preprint arXiv:2411.04368 , year=
-
[42]
Advances in neural information processing systems , volume=
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation , author=. Advances in neural information processing systems , volume=
-
[43]
2026 , howpublished=
American Invitational Mathematics Examination (AIME) , author=. 2026 , howpublished=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.