ProfiLLM: Utility-Aligned Agentic User Profiling for Industrial Ride-Hailing Dispatch
Pith reviewed 2026-06-26 21:18 UTC · model grok-4.3
The pith
ProfiLLM uses agentic LLMs to mine platform logs and generate utility-aligned user profiles that improve ride-hailing dispatch predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
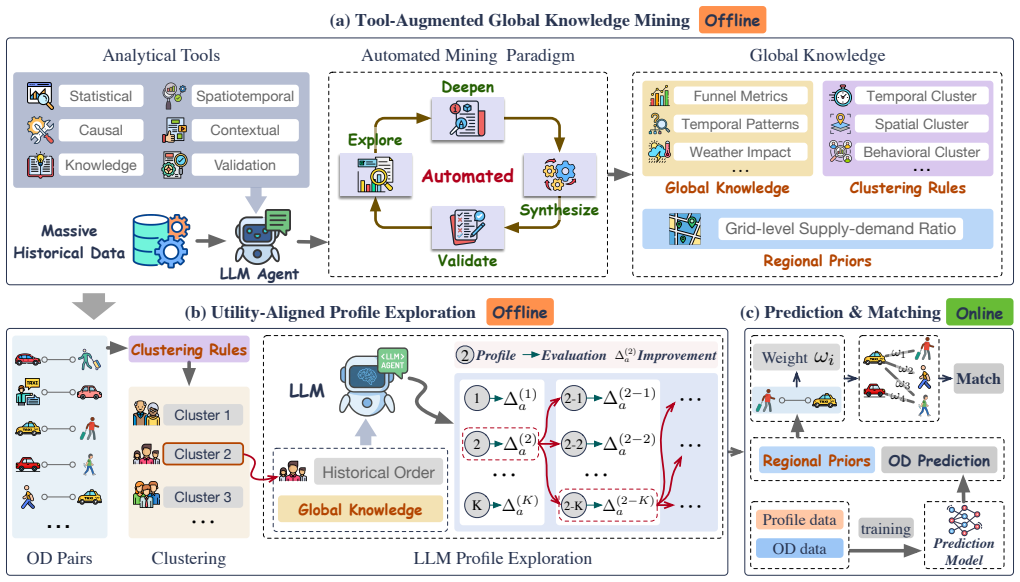
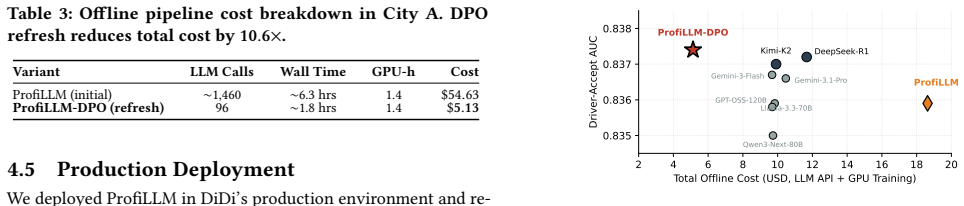
ProfiLLM operationalizes utility-aligned user profiling for production matching through two modules: Tool-Augmented Global Knowledge Mining, which gives an LLM agent 27 analytical tools to produce reusable global knowledge, adaptive clustering rules, and supply-demand priors from platform-scale logs, and Utility-Aligned Profile Exploration, which generates multiple candidate profiles per cluster, scores them with a downstream utility proxy, iteratively refines the best ones, and constructs preference pairs for DPO fine-tuning.
What carries the argument
The two-module agentic pipeline of Tool-Augmented Global Knowledge Mining and Utility-Aligned Profile Exploration that converts platform-scale logs into profiles selected for downstream utility.
If this is right
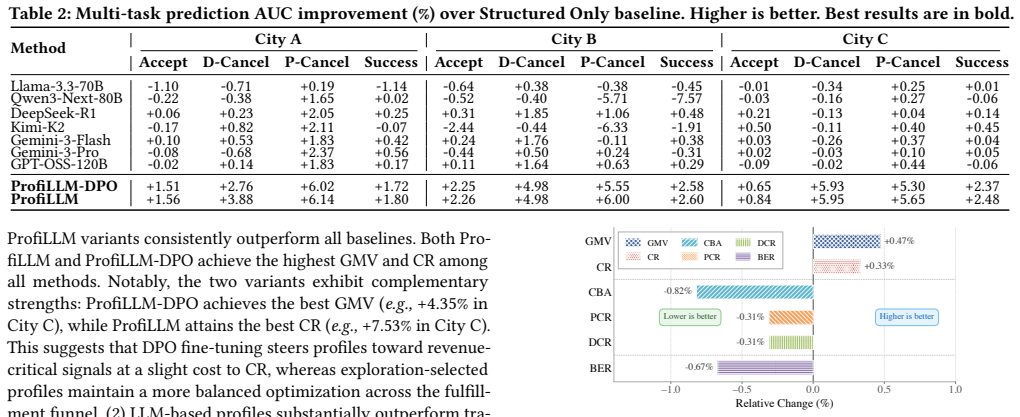
- Outcome prediction AUC improves by up to 6.14 percent relative when the generated profiles are added to the matching model.
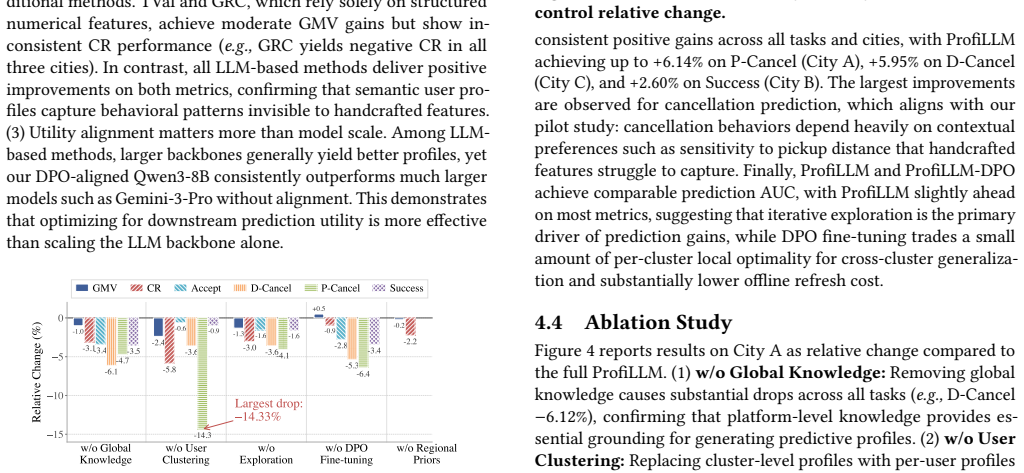
- Dispatching simulation shows up to 4.35 percent GMV gain from the same profiles.
- A 14-day online A/B test records +0.47 percent GMV, +0.33 percent completion rate, and -0.82 percent cancel-before-accept rate.
Where Pith is reading between the lines
- The same agentic pattern could be tested in other large-scale matching domains where behavioral context must be turned into structured features under strict latency limits.
- Replacing the proxy with direct end-to-end optimization on the true objective, if compute budgets allow, would test whether the current two-stage selection is necessary.
- The approach implies that LLMs can serve as semantic feature extractors inside existing numerical pipelines without replacing the pipelines themselves.
Load-bearing premise
The lightweight downstream utility proxy used to evaluate and select candidate profiles is a faithful and stable stand-in for the true production dispatch objective across changing market conditions.
What would settle it
If the profiles chosen by the utility proxy produce no lift or negative lift when the actual long-term dispatch objective is measured directly on a new dataset or market regime, the central alignment claim would be falsified.
Figures




read the original abstract
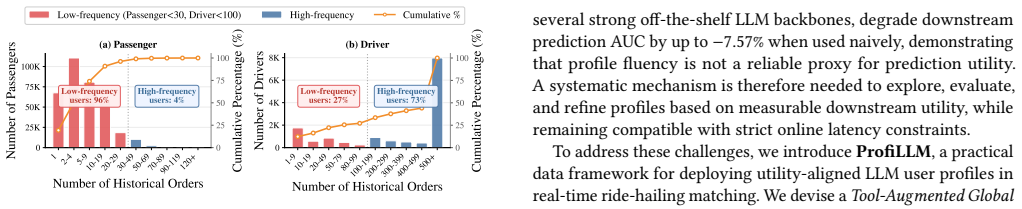
Bringing Large Language Models (LLMs) into industrial ride-hailing dispatch as semantic feature extractors over platform-scale behavioral logs is a compelling but under-explored data systems problem. Production matching pipelines remain dominated by structured numerical features, yet decisive behavioral signals (e.g., a driver's habitual aversion to certain regions) are inherently contextual and naturally expressible as LLM-generated user profiles. However, scaling such profiling to a live, millisecond-latency dispatcher faces three intertwined constraints rarely addressed together: on a platform with millions of daily orders, logs exceed any LLM's context window by orders of magnitude; most users are long-tail, with too few interactions for per-user profiling; and surface-fluent profiles do not necessarily improve downstream prediction utility. We present ProfiLLM, an agentic LLM data pipeline that operationalizes utility-aligned user profiling for production matching systems through two modules. (1) Tool-Augmented Global Knowledge Mining equips an LLM agent with 27 analytical tools to mine platform-scale data, producing reusable global knowledge, adaptive user clustering rules, and region-level supply-demand priors. (2) Utility-Aligned Profile Exploration generates multiple candidate profiles per cluster, evaluates them via a lightweight downstream utility proxy, iteratively refines the best candidates and constructs preference pairs for DPO fine-tuning. Deployed on DiDi's production dispatcher, ProfiLLM achieves up to +6.14% relative AUC improvement in outcome prediction, up to +4.35% GMV gain in dispatching simulation, and consistent improvements in a 14-day online A/B test including +0.47% GMV, +0.33% Completion Rate, and -0.82% Cancel-Before-Accept rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ProfiLLM, an agentic LLM data pipeline for utility-aligned user profiling in ride-hailing dispatch. It comprises two modules: Tool-Augmented Global Knowledge Mining (LLM agent with 27 analytical tools to produce global knowledge, clustering rules, and supply-demand priors) and Utility-Aligned Profile Exploration (generates candidate profiles per cluster, evaluates via a lightweight downstream utility proxy, refines candidates, and constructs preference pairs for DPO fine-tuning). Deployed on DiDi's production dispatcher, it claims up to +6.14% relative AUC improvement in outcome prediction, +4.35% GMV gain in simulation, and gains in a 14-day A/B test (+0.47% GMV, +0.33% Completion Rate, -0.82% Cancel-Before-Accept rate).
Significance. If the results hold after addressing experimental gaps, the work would be significant for demonstrating scalable integration of LLMs as semantic feature extractors in millisecond-latency industrial matching systems, addressing context-window limits, long-tail users, and utility alignment via agentic tooling and DPO. The production deployment and A/B test provide a rare real-world evaluation point for such systems.
major comments (2)
- [Abstract] Abstract: The abstract states numerical improvements from deployment and A/B testing but supplies no baseline descriptions, statistical tests, confidence intervals, or details on how the utility proxy was constructed or validated; the central performance claims therefore rest on unreported experimental controls.
- [Abstract / Utility-Aligned Profile Exploration] Abstract / Utility-Aligned Profile Exploration: Profile selection and DPO fine-tuning are driven by scoring against a downstream utility proxy; if that proxy is trained or tuned on the same outcome data used to measure AUC and GMV gains, the reported improvements are partly by construction. No correlation, rank agreement, or sensitivity analysis is supplied showing the proxy tracks the multi-objective production goal (GMV + completion + cancel rate) under non-stationary conditions.
minor comments (2)
- Clarify the exact construction and validation procedure for the lightweight utility proxy, including any training data overlap with evaluation metrics.
- Provide more detail on how the 27 analytical tools handle platform-scale logs and long-tail users with few interactions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on experimental reporting and proxy validation. We address each point below and commit to revisions that strengthen the clarity of the claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states numerical improvements from deployment and A/B testing but supplies no baseline descriptions, statistical tests, confidence intervals, or details on how the utility proxy was constructed or validated; the central performance claims therefore rest on unreported experimental controls.
Authors: The abstract is intentionally concise. The manuscript body specifies the baseline as the production dispatcher without ProfiLLM profiles, reports paired t-test results (p < 0.05) in Section 5, and details the utility proxy in Section 4.3 as a lightweight model trained on held-out historical logs. We will revise the abstract to briefly reference the baseline and statistical significance, and add confidence intervals to the reported metrics. revision: yes
-
Referee: [Abstract / Utility-Aligned Profile Exploration] Abstract / Utility-Aligned Profile Exploration: Profile selection and DPO fine-tuning are driven by scoring against a downstream utility proxy; if that proxy is trained or tuned on the same outcome data used to measure AUC and GMV gains, the reported improvements are partly by construction. No correlation, rank agreement, or sensitivity analysis is supplied showing the proxy tracks the multi-objective production goal (GMV + completion + cancel rate) under non-stationary conditions.
Authors: The utility proxy is trained exclusively on historical dispatch data from time windows disjoint from all evaluation periods used for AUC, simulation GMV, and the 14-day A/B test. The current manuscript does not include explicit correlation, rank agreement, or sensitivity analyses. We will add these in the revision, including Spearman's correlation with the composite production metric and sensitivity checks under simulated distribution shifts. revision: yes
Circularity Check
No significant circularity; evaluation metrics are independent of the internal proxy.
full rationale
The paper's method uses a lightweight downstream utility proxy solely for candidate profile evaluation, refinement, and DPO preference construction within the Utility-Aligned Profile Exploration module. Reported gains are measured on distinct external benchmarks: AUC on outcome prediction (separate from proxy use), GMV in dispatching simulation, and real-world metrics from a 14-day online A/B test (+0.47% GMV, +0.33% Completion Rate, -0.82% Cancel-Before-Accept). No equations, self-citations, or descriptions show the final reported improvements reducing to the proxy by construction or via fitted inputs renamed as predictions. The derivation chain remains self-contained against these external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents equipped with analytical tools can reliably extract reusable global knowledge and adaptive clustering rules from platform-scale logs that exceed any single context window.
- domain assumption A lightweight downstream utility proxy can be used to rank and select LLM-generated profiles in a way that transfers to live dispatch performance.
invented entities (1)
-
Utility proxy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862(2022)
Pith/arXiv arXiv 2022
-
[2]
M Keith Chen and Michael Sheldon. 2016. Dynamic pricing in a labor market: Surge pricing and flexible work on the Uber platform.Ec16 (2016), 455
2016
-
[3]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
-
[4]
Meihao Fan, Ju Fan, Nan Tang, Lei Cao, Guoliang Li, and Xiaoyong Du. 2025. AutoPrep: Natural Language Question-Aware Data Preparation with a Multi- Agent Framework.Proc. VLDB Endow.18, 10 (2025), 3504–3517. https://doi.org/ 10.14778/3748191.3748211
-
[5]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
Pith/arXiv arXiv 2025
-
[6]
Balázs Hidasi and Ádám Tibor Czapp. 2023. Widespread Flaws in Offline Evalu- ation of Recommender Systems. InProceedings of the 17th ACM Conference on Recommender Systems. https://doi.org/10.1145/3604915.3608839
-
[7]
David Holtz and Sinan Aral. 2020. Limiting Bias from Test-Control Interference in Online Marketplace Experiments.arXiv preprint arXiv:2004.12162(2020)
arXiv 2020
-
[8]
Wei Huang, Anda Cheng, Yinggui Wang, Lei Wang, and Tao Wei. 2026. LLM- AutoDP: Automatic Data Processing via LLM Agents for Model Fine-tuning.Proc. VLDB Endow.19, 5 (2026), 794–807. https://doi.org/10.14778/3796195.3796196
-
[9]
Jie Jiang, Haining Xie, Siqi Shen, Yu Shen, Zihan Zhang, Meng Lei, Yifeng Zheng, Yang Li, Chunyou Li, Danqing Huang, Yinjun Wu, Wentao Zhang, Bin Cui, and Peng Chen. 2025. SiriusBI: A Comprehensive LLM-Powered Solution for Data Analytics in Business Intelligence.Proc. VLDB Endow.18, 12 (2025), 4860–4873. https://doi.org/10.14778/3750601.3750610
-
[10]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[11]
Jintao Ke, Feng Xiao, Hai Yang, and Jieping Ye. 2020. Learning to delay in ride- sourcing systems: A multi-agent deep reinforcement learning framework.IEEE Transactions on Knowledge and Data Engineering34, 5 (2020), 2280–2292
2020
-
[12]
Der-Horng Lee, Hao Wang, Ruey Long Cheu, and Siew Hoon Teo. 2004. Taxi dispatch system based on current demands and real-time traffic conditions. Transportation Research Record1882, 1 (2004), 193–200
2004
-
[13]
Fengxin Li, Yi Li, Yue Liu, Chao Zhou, Yuan Wang, Xiaoxiang Deng, Wei Xue, Dapeng Liu, Lei Xiao, Haijie Gu, Jie Jiang, Hongyan Liu, Biao Qin, and Jun He
-
[14]
VLDB Endow.18, 12 (2025), 4763–
LEADRE: Multi-Faceted Knowledge Enhanced LLM Empowered Display Advertisement Recommender System.Proc. VLDB Endow.18, 12 (2025), 4763–
2025
-
[15]
https://doi.org/10.14778/3750601.3750602
-
[16]
Jiahui Li, Tongwang Wu, Yuren Mao, Yunjun Gao, Yajie Feng, and Huaizhong Liu
-
[17]
VLDB Endow.19, 3 (2025), 292–305
SQL-Factory: A Multi-Agent Framework for High-Quality and Large-Scale SQL Generation.Proc. VLDB Endow.19, 3 (2025), 292–305. https://doi.org/10. 14778/3778092.3778093
arXiv 2025
-
[18]
Qijiong Liu, Nuo Chen, Tetsuya Sakai, and Xiao-Ming Wu. 2024. Once: Boosting content-based recommendation with both open-and closed-source large language models. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 452–461
2024
-
[19]
Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research9, Nov (2008), 2579–2605
2008
-
[20]
Yansong Ning, Shuowei Cai, Wei Li, Jun Fang, Naiqiang Tan, Hua Chai, and Hao Liu. 2025. Dima: An llm-powered ride-hailing assistant at didi. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4728–4739
2025
-
[21]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[22]
Zhiwei Qin, Xiaocheng Tang, Yan Jiao, Fan Zhang, Zhe Xu, Hongtu Zhu, and Jieping Ye. 2020. Ride-hailing order dispatching at didi via reinforcement learning. INFORMS Journal on Applied Analytics50, 5 (2020), 272–286
2020
-
[23]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[24]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems36 (2023), 68539–68551
2023
-
[25]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[26]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
Pith/arXiv arXiv 2017
-
[27]
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing.Proc. VLDB Endow.18, 9 (2025), 3035–3048. https: //doi.org/10.14778/3746405.3746426
-
[28]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[29]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[30]
Xiaocheng Tang, Fan Zhang, Zhiwei Qin, Yansheng Wang, Dingyuan Shi, Bingchen Song, Yongxin Tong, Hongtu Zhu, and Jieping Ye. 2021. Value function is all you need: A unified learning framework for ride hailing platforms. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 3605–3615
2021
-
[31]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
Pith/arXiv arXiv 2023
-
[32]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al . 2025. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534(2025)
Pith/arXiv arXiv 2025
-
[33]
Jing-Peng Wang, Hai Wang, Peng Liu, and Hai-Jun Huang. 2025. Order dispatch- ing strategy and pricing scheme in ride-sourcing markets with consideration of service cancellation.Transportation Research Part B: Methodological199 (2025), 103266
2025
-
[34]
Lu Wang, Di Zhang, Fangkai Yang, Pu Zhao, Jianfeng Liu, Yuefeng Zhan, Hao Sun, Qingwei Lin, Weiwei Deng, Dongmei Zhang, et al. 2025. Lettingo: Explore user profile generation for recommendation system. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 2985–2995
2025
-
[35]
Yansheng Wang, Yongxin Tong, Cheng Long, Pan Xu, Ke Xu, and Weifeng Lv
-
[36]
In2019 IEEE 35th international conference on data engineering (ICDE)
Adaptive dynamic bipartite graph matching: A reinforcement learning approach. In2019 IEEE 35th international conference on data engineering (ICDE). IEEE, 1478–1489
-
[37]
Zixin Wei, Yucan Guo, Jinyang Li, Xiaolin Han, Xiaolong Jin, and Chenhao Ma
-
[38]
VLDB Endow.19, 5 (2026), 973–986
Revisiting Task-Oriented Dataset Search in the Era of Large Language Models: Challenges, Benchmark, and Solution.Proc. VLDB Endow.19, 5 (2026), 973–986. https://doi.org/10.14778/3796195.3796209
-
[39]
Yunjia Xi, Weiwen Liu, Jianghao Lin, Xiaoling Cai, Hong Zhu, Jieming Zhu, Bo Chen, Ruiming Tang, Weinan Zhang, and Yong Yu. 2024. Towards open-world recommendation with knowledge augmentation from large language models. In Proceedings of the 18th ACM Conference on Recommender Systems. 12–22
2024
-
[40]
Zhe Xu, Zhixin Li, Qingwen Guan, Dingshui Zhang, Qiang Li, Junxiao Nan, Chunyang Liu, Wei Bian, and Jieping Ye. 2018. Large-scale order dispatch in on- demand ride-hailing platforms: A learning and planning approach. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 905–913
2018
-
[41]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
Pith/arXiv arXiv 2025
-
[42]
Zhaoxing Yang, Haiming Jin, Guiyun Fan, Min Lu, Yiran Liu, Xinlang Yue, Hao Pan, Zhe Xu, Guobin Wu, Qun Li, et al. 2024. Rethinking order dispatching in online ride-hailing platforms. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3863–3873
2024
-
[43]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
-
[44]
Xinlang Yue, Yiran Liu, Fangzhou Shi, Sihong Luo, Chen Zhong, Min Lu, and Zhe Xu. 2024. An End-to-End Reinforcement Learning Based Approach for Micro-View Order-Dispatching in Ride-Hailing. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 5054–5061
2024
-
[45]
Lingyu Zhang, Tao Hu, Yue Min, Guobin Wu, Junying Zhang, Pengcheng Feng, Pinghua Gong, and Jieping Ye. 2017. A taxi order dispatch model based on combinatorial optimization. InProceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 2151–2159
2017
-
[46]
Siyao Zhang, Daocheng Fu, Wenzhe Liang, Zhao Zhang, Bin Yu, Pinlong Cai, and Baozhen Yao. 2024. Trafficgpt: Viewing, processing and interacting with traffic foundation models.Transport Policy150 (2024), 95–105
2024
-
[47]
Wenqi Zhang, Yongliang Shen, Weiming Lu, and Yueting Zhuang. 2023. Data- copilot: Bridging billions of data and humans with autonomous workflow.arXiv preprint arXiv:2306.07209(2023)
arXiv 2023
-
[48]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068
2018
-
[49]
likely to cancel long-pickup orders,
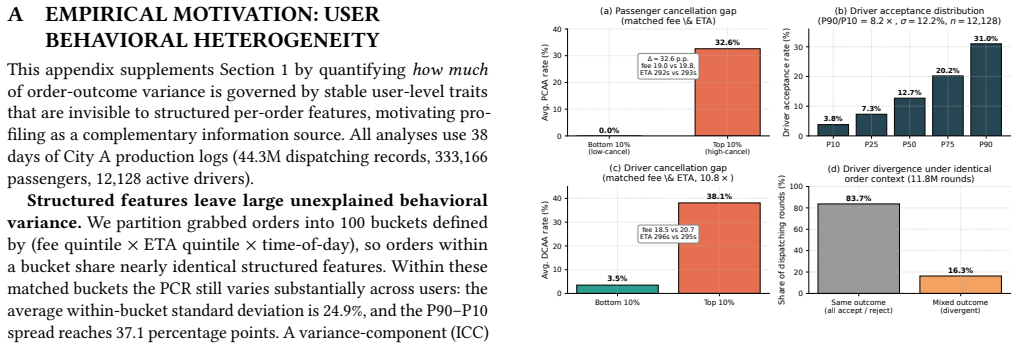
Wei Zhou, Peng Sun, Xuanhe Zhou, Qianglei Zang, Ji Xu, Tieying Zhang, Guo- liang Li, and Fan Wu. 2026. DBAIOps: A Reasoning LLM-Enhanced Database Operation and Maintenance System using Knowledge Graphs.Proc. VLDB Endow. 19, 6 (2026), 1319–1331. https://doi.org/10.14778/3797919.3797937 9 A EMPIRICAL MOTIV ATION: USER BEHA VIORAL HETEROGENEITY This appendix...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.