Harness In-Context Operator Learning with Chain of Operators
Pith reviewed 2026-06-27 10:43 UTC · model grok-4.3
The pith
A chain of explicit transformations around a frozen in-context operator network cuts error on out-of-distribution tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
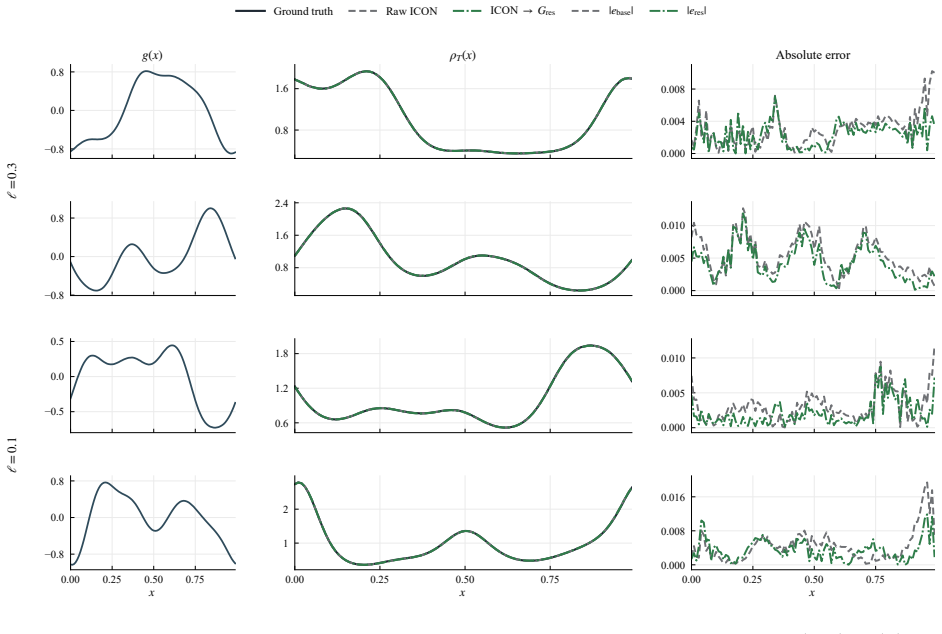
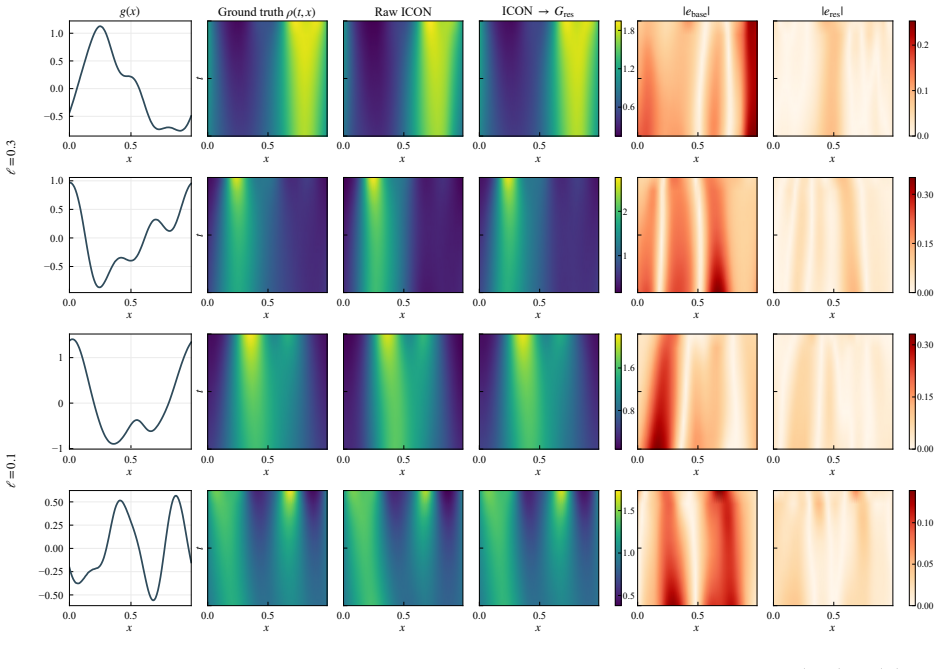
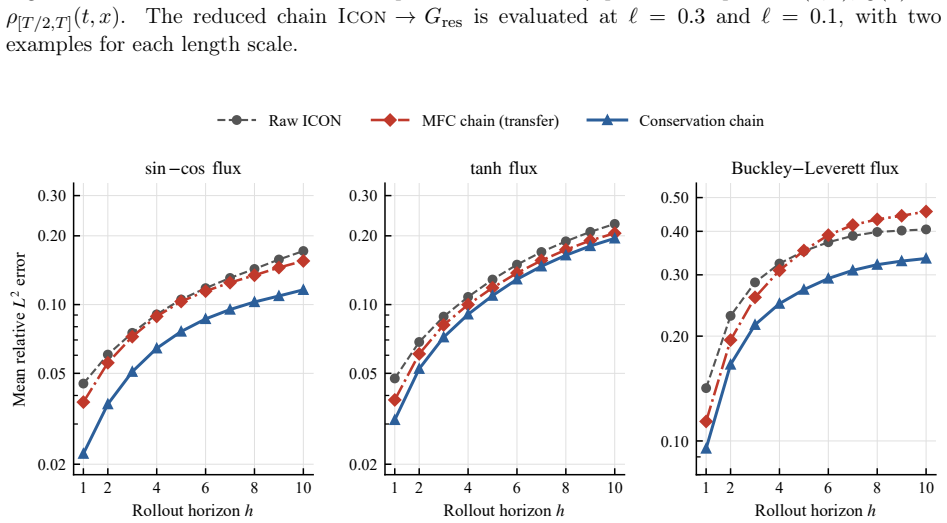
CHOP constructs a chain consisting of explicit elementary transformations and the frozen ICON to harness it for OOD operator tasks without updating parameters. This reduces relative inference error compared to direct ICON evaluation on a scalar conservation law and a mean-field control problem. Each operator in the chain remains interpretable and in closed form. A chain built on one PDE family generalizes to a different family.
What carries the argument
The Chain of Operators (CHOP) framework, which composes explicit elementary transformations with a frozen ICON to form an interpretable chain that adapts the model to new operator tasks.
If this is right
- CHOP achieves lower relative inference error than direct ICON evaluation on the tested OOD tasks.
- Each operator inside the chain stays in closed form and remains interpretable.
- A chain identified for one PDE family transfers directly to operators from a different family.
- No parameter updates or task-specific fine-tuning of the underlying ICON are required.
Where Pith is reading between the lines
- The same chaining pattern could be tested on other in-context models that map between function spaces.
- If chain construction can be automated, the method might extend to wider classes of scientific operator problems.
- Shared mechanisms across PDE families point to possible common structures that future work could exploit.
Load-bearing premise
Suitable chains of explicit elementary transformations exist and can be identified for arbitrary out-of-distribution operator tasks such that the composition yields lower error without any parameter change.
What would settle it
An OOD operator task where no chain of explicit transformations composed with the frozen ICON produces lower error than direct ICON evaluation, or where no such chain can be identified.
Figures
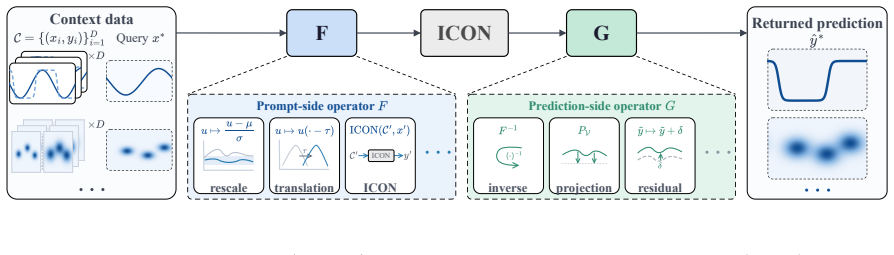

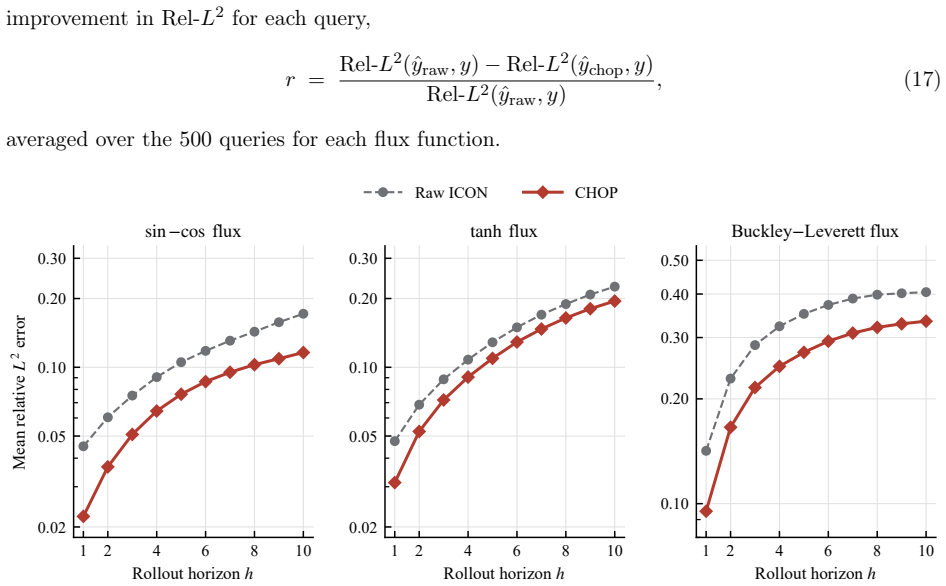
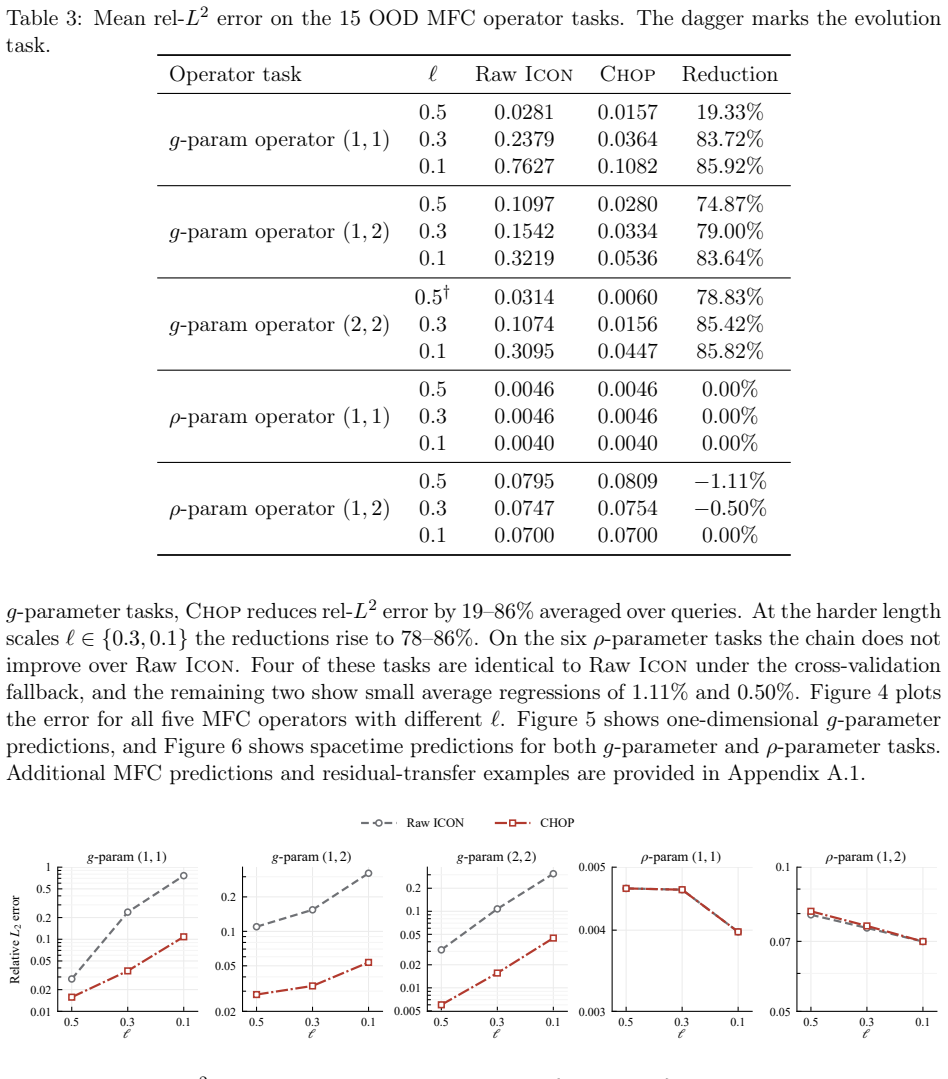
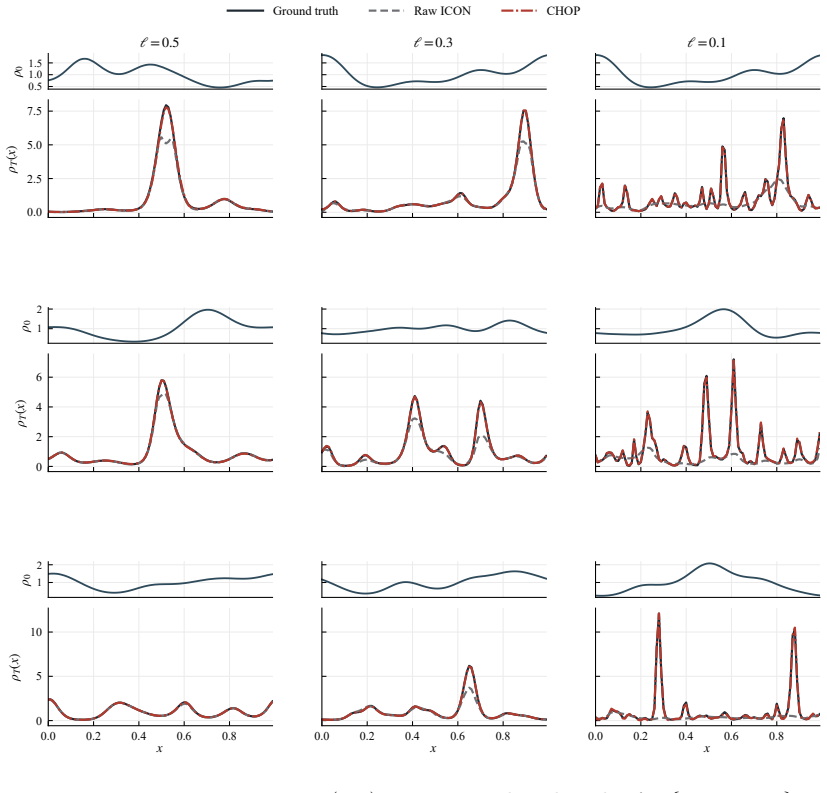
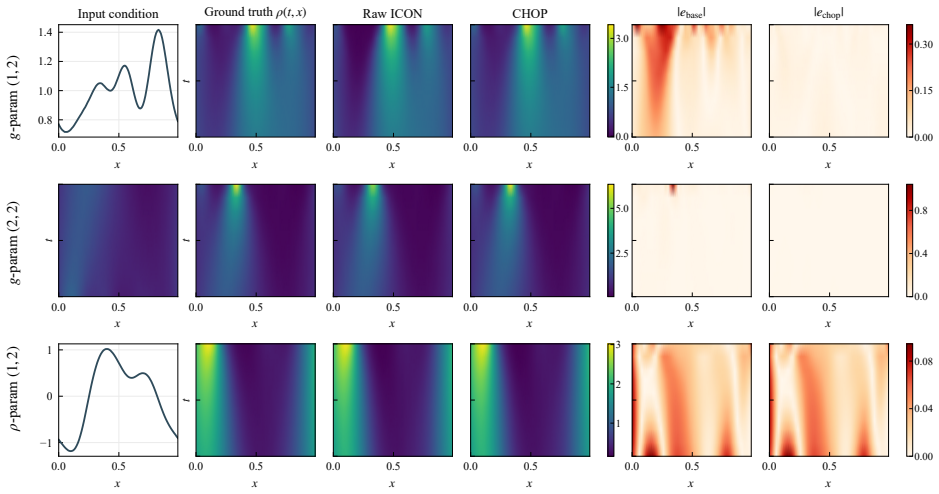
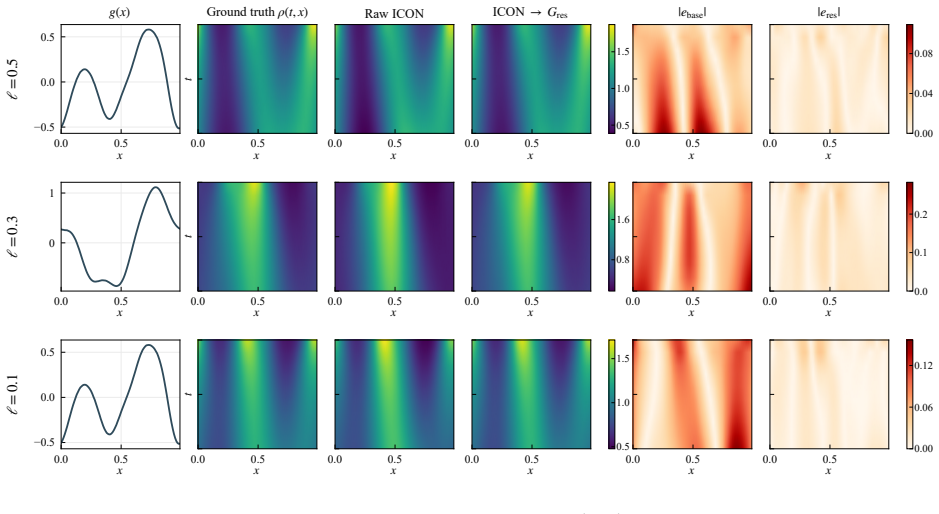
read the original abstract
Neural operators approximate mappings between function spaces, but often generalize poorly to other operators and usually require fine-tuning or retraining. In-Context Operator Networks (ICON) addresses this issue by prompting the model with numerical context so that the model learns specific operators from prompts and adapt to different operators without fine-tuning. However, ICON may still fail to generalize to out-of-distribution (OOD) operator tasks. Inpired by the success of harness engineering of Large Language models (LLMs), we introduce Chain of Operators (CHOP), a framework that harness a frozen ICON to OOD operator tasks without updating its parameters. Specifically, CHOP constructs a chain of operators consisting of explicit elementary transformations and the frozen ICON. Experiments on a scalar conservation law and a mean-field control problem show that CHOP reduces relative inference error over direct ICON evaluation, while each operator in the chain remains interpretable and in closed form. A chain constructed on one PDE family further generalizes to a different family, indicating shared mechanisms across harness systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Chain of Operators (CHOP) as a framework to adapt a frozen In-Context Operator Network (ICON) to out-of-distribution (OOD) operator tasks by composing it with a chain of explicit, closed-form elementary transformations. Experiments on a scalar conservation law and a mean-field control problem are reported to show reduced relative inference error versus direct ICON evaluation; a chain derived on one PDE family is further claimed to generalize to a different family while preserving interpretability.
Significance. If the empirical improvements and cross-family generalization hold under a reproducible chain-construction procedure, the approach would offer a parameter-free, interpretable route to extend neural-operator generalization without retraining or fine-tuning. The explicit closed-form nature of the elementary operators is a methodological strength that distinguishes it from black-box adaptation methods.
major comments (2)
- [Abstract, §3] Abstract and §3 (method): the central claim that CHOP 'constructs a chain' enabling OOD generalization 'without any parameter change or task-specific fine-tuning' is load-bearing, yet no algorithm, search procedure, selection criteria, or automated method for identifying the elementary transformations is described. If chain construction is manual or relies on per-task domain knowledge, the no-fine-tuning property does not extend beyond the two demonstrated cases.
- [Abstract] Abstract: the statement that 'CHOP reduces relative inference error' is presented without any quantitative values, baselines, error bars, number of trials, or description of how the chains were constructed for the scalar conservation law and mean-field control experiments, preventing assessment of effect size or reproducibility.
minor comments (2)
- [Abstract] The abstract uses 'Inpired' (typo for 'Inspired').
- [§2, §3] Notation for the elementary operators and the composition rule should be introduced with explicit mathematical definitions early in §2 or §3 to clarify how the chain is applied to the ICON output.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the major comments point by point below, proposing revisions to improve clarity and completeness where the comments identify gaps in the current manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): the central claim that CHOP 'constructs a chain' enabling OOD generalization 'without any parameter change or task-specific fine-tuning' is load-bearing, yet no algorithm, search procedure, selection criteria, or automated method for identifying the elementary transformations is described. If chain construction is manual or relies on per-task domain knowledge, the no-fine-tuning property does not extend beyond the two demonstrated cases.
Authors: We agree that the manuscript does not describe an automated algorithm or search procedure for chain construction. The chains presented in the experiments were identified manually by leveraging domain knowledge of the underlying scalar conservation laws and mean-field control problems to select explicit elementary operators that compose with the frozen ICON. This is a genuine limitation of the current work: the no-fine-tuning property holds once a suitable chain is provided, but the paper does not claim or demonstrate an automated discovery method. We will revise §3 to explicitly state that chain construction is currently manual and based on interpretability-driven inspection, while clarifying that the framework itself requires no parameter updates. We will also add a discussion of this as a direction for future work on automated harness engineering. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'CHOP reduces relative inference error' is presented without any quantitative values, baselines, error bars, number of trials, or description of how the chains were constructed for the scalar conservation law and mean-field control experiments, preventing assessment of effect size or reproducibility.
Authors: We agree that the abstract lacks the quantitative details needed for immediate assessment. The full experimental results, including relative error reductions, baselines (direct ICON evaluation), and trial counts, are reported in the experiments section, but the abstract does not summarize them. In the revision we will update the abstract to include specific quantitative improvements (e.g., the observed error reductions on the two tasks), mention the number of trials, and briefly note that chains were constructed via manual domain-informed selection. This will make the abstract self-contained while preserving its length constraints. revision: yes
Circularity Check
No significant circularity; empirical framework with explicit operators
full rationale
The paper introduces CHOP as a composition of explicit, closed-form elementary transformations with a frozen ICON model. Reported error reductions are shown via experiments on scalar conservation laws and mean-field control problems, with generalization demonstrated across PDE families. No equations, fitted parameters, or derivations reduce the claimed improvements to inputs by construction. The chain construction is presented as feasible for the tested cases without any self-referential definition or load-bearing self-citation that collapses the result. The framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ICON can learn specific operators from numerical context prompts and adapt without fine-tuning
Reference graph
Works this paper leans on
-
[1]
Neural operator: Learning maps between function spaces with applications to PDEs.Journal of Machine Learning Research, 24(89):1–97, 2023
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to PDEs.Journal of Machine Learning Research, 24(89):1–97, 2023
2023
-
[2]
Physics-informed deep neural operator networks
Somdatta Goswami, Aniruddha Bora, Yue Yu, and George Em Karniadakis. Physics-informed deep neural operator networks. InMachine learning in modeling and simulation: methods and applications, pages 219–254. Springer, 2023
2023
-
[3]
Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
2021
-
[4]
Learning nonlinear operators via deeponet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature machine intelligence, 3(3):218–229, 2021
2021
-
[5]
Fourier neural operator for parametric partial dif- ferential equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial dif- ferential equations. InInternational Conference on Learning Representations, 2021
2021
-
[6]
Lu Lu, Xuhui Meng, Shengze Cai, Zhiping Mao, Somdatta Goswami, Zhongqiang Zhang, and George Em Karniadakis. A comprehensive and fair comparison of two neural operators 16 (with practical extensions) based on fair data.Computer Methods in Applied Mechanics and Engineering, 393:114778, 2022
2022
-
[7]
Physics-informed neural operator for learning partial differential equations.ACM/IMS Journal of Data Science, 1(3):1–27, 2024
Zongyi Li, Hongkai Zheng, Nikola Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kam- yar Azizzadenesheli, and Anima Anandkumar. Physics-informed neural operator for learning partial differential equations.ACM/IMS Journal of Data Science, 1(3):1–27, 2024
2024
-
[8]
Fourier neural op- erator with learned deformations for pdes on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier neural op- erator with learned deformations for pdes on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023
2023
-
[9]
Learning the solution operator of para- metric partial differential equations with physics-informed deeponets.Science advances, 7(40):eabi8605, 2021
Sifan Wang, Hanwen Wang, and Paris Perdikaris. Learning the solution operator of para- metric partial differential equations with physics-informed deeponets.Science advances, 7(40):eabi8605, 2021
2021
-
[10]
Learn- ing nonlinear operators in latent spaces for real-time predictions of complex dynamics in phys- ical systems.Nature Communications, 15(1):5101, 2024
KatianaKontolati, SomdattaGoswami, GeorgeEmKarniadakis, andMichaelDShields. Learn- ing nonlinear operators in latent spaces for real-time predictions of complex dynamics in phys- ical systems.Nature Communications, 15(1):5101, 2024
2024
-
[11]
Convolutional neural operators
Bogdan Raonic, Roberto Molinaro, Tobias Rohner, Siddhartha Mishra, and Emmanuel de Bezenac. Convolutional neural operators. InICLR 2023 workshop on physics for machine learning, 2023
2023
-
[12]
Tapas Tripura and Souvik Chakraborty. Wavelet neural operator for solving parametric partial differential equations in computational mechanics problems.Computer Methods in Applied Mechanics and Engineering, 404:115783, 2023
2023
-
[13]
Reliableextrapolation of deep neural operators informed by physics or sparse observations.Computer Methods in Applied Mechanics and Engineering, 412:116064, 2023
MinZhu, HandiZhang, AnranJiao, GeorgeEmKarniadakis, andLuLu. Reliableextrapolation of deep neural operators informed by physics or sparse observations.Computer Methods in Applied Mechanics and Engineering, 412:116064, 2023
2023
-
[14]
Deep transfer operator learning for partial differential equations under conditional shift.Nature Machine Intelligence, 4(12):1155–1164, 2022
Somdatta Goswami, Katiana Kontolati, Michael D Shields, and George Em Karniadakis. Deep transfer operator learning for partial differential equations under conditional shift.Nature Machine Intelligence, 4(12):1155–1164, 2022
2022
-
[15]
Modno: Multi-operator learning with distributed neural operators.Computer Methods in Applied Mechanics and Engineering, 431:117229, 2024
Zecheng Zhang. Modno: Multi-operator learning with distributed neural operators.Computer Methods in Applied Mechanics and Engineering, 431:117229, 2024
2024
-
[16]
Lemon: Learning to learn multi-operator networks.arXiv preprint arXiv:2408.16168, 2024
Jingmin Sun, Zecheng Zhang, and Hayden Schaeffer. Lemon: Learning to learn multi-operator networks.arXiv preprint arXiv:2408.16168, 2024
arXiv 2024
-
[17]
Data-efficient operator learning via unsupervised pretraining and in-context learning
Wuyang Chen, Jialin Song, Pu Ren, Shashank Subramanian, Dmitriy Morozov, and Michael W Mahoney. Data-efficient operator learning via unsupervised pretraining and in-context learning. Advances in Neural Information Processing Systems, 37:6213–6245, 2024
2024
-
[18]
Poseidon: Efficient foundation models for pdes
Maximilian Herde, Bogdan Raonić, Tobias Rohner, Roger Käppeli, Roberto Molinaro, Em- manuel De Bezenac, and Siddhartha Mishra. Poseidon: Efficient foundation models for pdes. Advances in Neural Information Processing Systems, 37:72525–72624, 2024
2024
-
[19]
Deeponet as a multi-operator extrapolation model: Distributed pretraining with physics-informed fine-tuning
Zecheng Zhang, Christian Moya, Lu Lu, Guang Lin, and Hayden Schaeffer. Deeponet as a multi-operator extrapolation model: Distributed pretraining with physics-informed fine-tuning. Journal of Computational Physics, page 114537, 2026. 17
2026
-
[20]
Parameter-efficient fine-tuning of large-scale pre-trained language models.Nature machine intelligence, 5(3):220–235, 2023
Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, et al. Parameter-efficient fine-tuning of large-scale pre-trained language models.Nature machine intelligence, 5(3):220–235, 2023
2023
-
[21]
Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models
Zhiqiang Hu, Lei Wang, Yihuai Lan, Wanyu Xu, Ee-Peng Lim, Lidong Bing, Xing Xu, Soujanya Poria, and Roy Lee. Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 5254–5276, 2023
2023
-
[22]
Towards foundation models for scientific machine learning: Characterizing scaling and transfer behavior.Advances in Neural Information Pro- cessing Systems, 36:71242–71262, 2023
Shashank Subramanian, Peter Harrington, Kurt Keutzer, Wahid Bhimji, Dmitriy Morozov, Michael W Mahoney, and Amir Gholami. Towards foundation models for scientific machine learning: Characterizing scaling and transfer behavior.Advances in Neural Information Pro- cessing Systems, 36:71242–71262, 2023
2023
-
[23]
PDEformer: Towards a foundation model for one-dimensional partial differential equations
Zhanhong Ye, Xiang Huang, Leheng Chen, Hongsheng Liu, Zidong Wang, and Bin Dong. PDEformer: Towards a foundation model for one-dimensional partial differential equations. arXiv preprint arXiv:2402.12652, 2024
arXiv 2024
-
[24]
Zhongkai Hao, Chang Su, Songming Liu, Julius Berner, Chengyang Ying, Hang Su, Anima Anandkumar, Jian Song, and Jun Zhu. DPOT: Auto-regressive denoising operator transformer for large-scale pde pre-training.arXiv preprint arXiv:2403.03542, 2024
arXiv 2024
-
[25]
Pretraining codomain attention neural operators for solving multiphysics pdes.Advances in Neural Information Processing Systems, 37:104035–104064, 2024
Ashiqur Rahman, Robert J George, Mogab Elleithy, Daniel Leibovici, Zongyi Li, Boris Bonev, Colin White, Julius Berner, Raymond A Yeh, Jean Kossaifi, et al. Pretraining codomain attention neural operators for solving multiphysics pdes.Advances in Neural Information Processing Systems, 37:104035–104064, 2024
2024
-
[26]
Yuxuan Liu, Jingmin Sun, Xinjie He, Griffin Pinney, Zecheng Zhang, and Hayden Schaeffer. Prose-fd: A multimodal pde foundation model for learning multiple operators for forecasting fluid dynamics.arXiv preprint arXiv:2409.09811, 2024
arXiv 2024
-
[27]
In-context operator learning with data prompts for differential equation problems.Proceedings of the National Academy of Sci- ences, 120(39):e2310142120, 2023
Liu Yang, Siting Liu, Tingwei Meng, and Stanley J Osher. In-context operator learning with data prompts for differential equation problems.Proceedings of the National Academy of Sci- ences, 120(39):e2310142120, 2023
2023
-
[28]
Yadi Cao, Yuxuan Liu, Liu Yang, Rose Yu, Hayden Schaeffer, and Stanley Osher. VICON: Vision in-context operator networks for multi-physics fluid dynamics prediction.arXiv preprint arXiv:2411.16063, 2024
arXiv 2024
-
[29]
Louis Serrano, Armand Kassaï Koupaï, Thomas X Wang, Pierre Erbacher, and Patrick Gal- linari. Zebra: In-context generative pretraining for solving parametric pdes.arXiv preprint arXiv:2410.03437, 2024
arXiv 2024
-
[30]
Enma: To- kenwise autoregression for continuous neural pde operators.Advances in Neural Information Processing Systems, 38:127341–127409, 2026
Armand Kassaï Koupaï, Lise Le Boudec, Louis Serrano, and Patrick Gallinari. Enma: To- kenwise autoregression for continuous neural pde operators.Advances in Neural Information Processing Systems, 38:127341–127409, 2026
2026
-
[31]
Benjamin J Zhang, Siting Liu, Stanley J Osher, and Markos A Katsoulakis. Probabilistic operator learning: generative modeling and uncertainty quantification for foundation models of differential equations.arXiv preprint arXiv:2509.05186, 2025
arXiv 2025
-
[32]
Chenghan Wu, Zongmin Yu, Boai Sun, and Liu Yang. Graph in-context operator networks for generalizable spatiotemporal prediction.arXiv preprint arXiv:2603.12725, 2026. 18
Pith/arXiv arXiv 2026
-
[33]
Tingwei Meng, Moritz Voss, Nils Detering, Giulio Farolfi, Stanley Osher, and Georg Menz. Solving optimal execution problems via in-context operator networks.arXiv preprint arXiv:2501.15106, 2025
arXiv 2025
-
[34]
Frank Cole, Dixi Wang, Yineng Chen, Yulong Lu, and Rongjie Lai. In-context operator learning on the space of probability measures.arXiv preprint arXiv:2601.09979, 2026
arXiv 2026
-
[35]
Does in-context operator learning generalize to domain-shifted settings? InThe symbiosis of deep learning and differential equations III, 2023
Jerry Weihong Liu, N Benjamin Erichson, Kush Bhatia, Michael W Mahoney, and Christopher Re. Does in-context operator learning generalize to domain-shifted settings? InThe symbiosis of deep learning and differential equations III, 2023
2023
-
[36]
Frank Cole, Yulong Lu, Wuzhe Xu, and Tianhao Zhang. In-context learning of linear systems: Generalization theory and applications to operator learning.arXiv preprint arXiv:2409.12293, 2024
arXiv 2024
-
[37]
PDE generalization of in-context operator networks: A study on 1d scalar nonlinear conservation laws.Journal of Computational Physics, 519:113379, 2024
Liu Yang and Stanley J Osher. PDE generalization of in-context operator networks: A study on 1d scalar nonlinear conservation laws.Journal of Computational Physics, 519:113379, 2024
2024
-
[38]
Fine-tune language models as multi-modal differ- ential equation solvers.Neural Networks, 188:107455, 2025
Liu Yang, Siting Liu, and Stanley J Osher. Fine-tune language models as multi-modal differ- ential equation solvers.Neural Networks, 188:107455, 2025
2025
-
[39]
Evolutionary ensemble of agents.arXiv preprint arXiv:2605.09018, 2026
Zongmin Yu and Liu Yang. Evolutionary ensemble of agents.arXiv preprint arXiv:2605.09018, 2026
Pith/arXiv arXiv 2026
-
[40]
Efficient implementation of weighted eno schemes
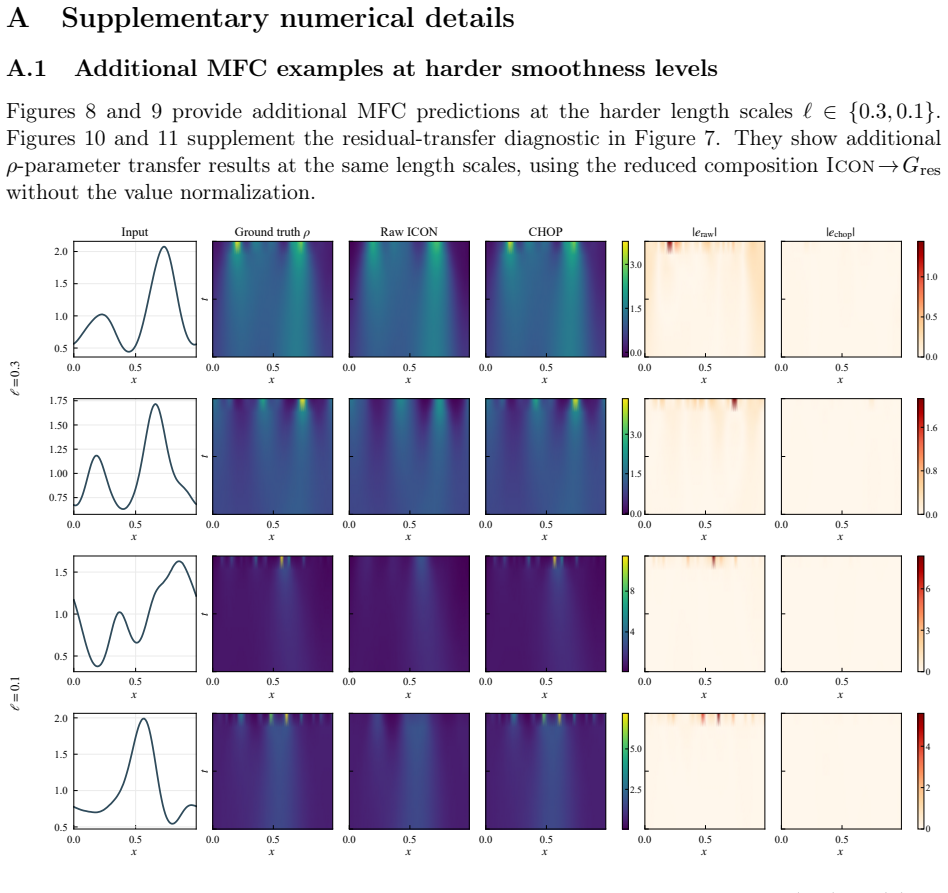
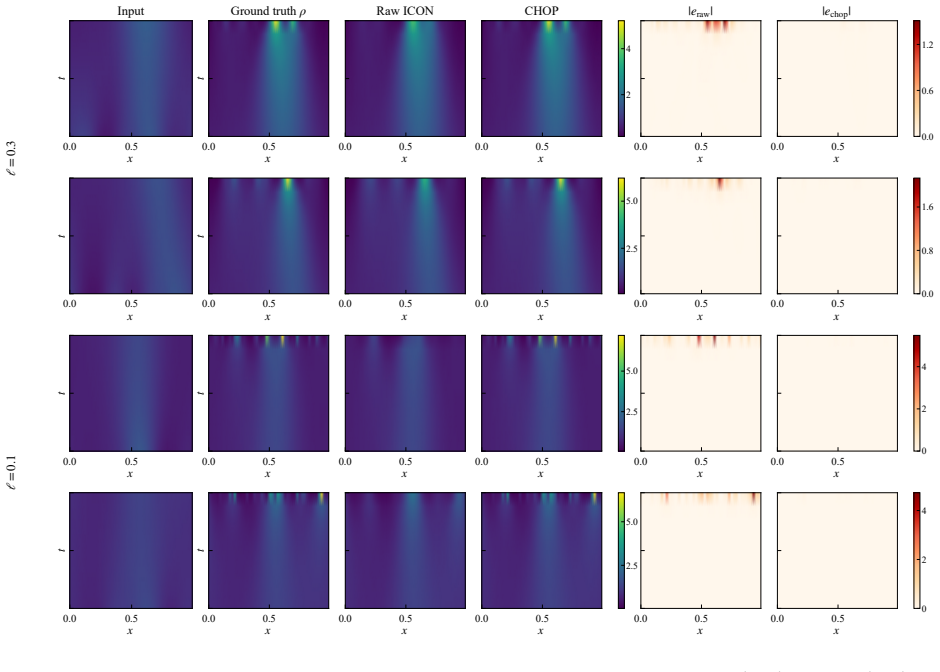
Guang-Shan Jiang and Chi-Wang Shu. Efficient implementation of weighted eno schemes. Journal of computational physics, 126(1):202–228, 1996. 19 A Supplementary numerical details A.1 Additional MFC examples at harder smoothness levels Figures 8 and 9 provide additional MFC predictions at the harder length scalesℓ∈ {0.3,0.1}. Figures 10 and 11 supplement th...
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.