SymQNet: Amortized Acquisition for Low-Latency Adaptive Hamiltonian Learning
Pith reviewed 2026-06-27 07:48 UTC · model grok-4.3
The pith
SymQNet trains an offline neural policy that selects the next Hamiltonian-learning experiment in one forward pass, cutting acquisition latency by 47x to 72x on Ising benchmarks while preserving Bayesian posterior updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
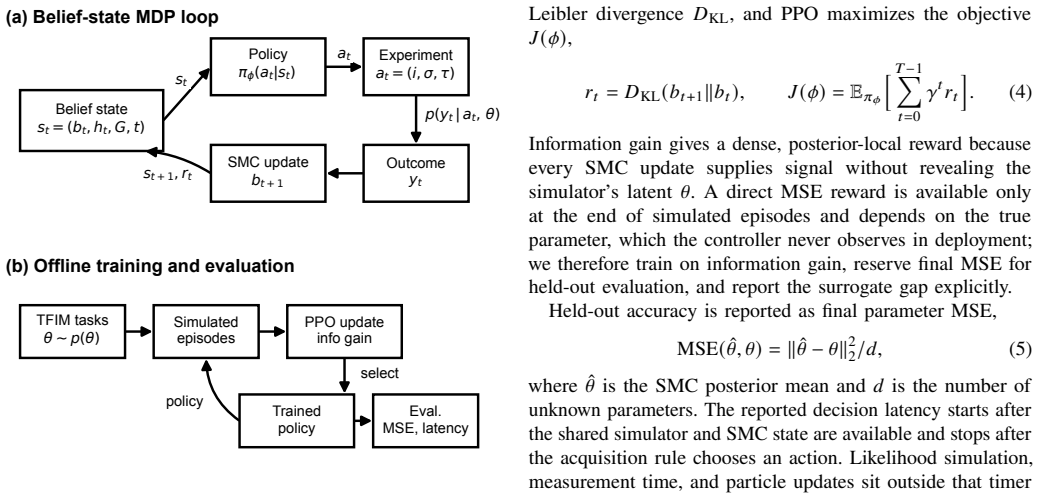
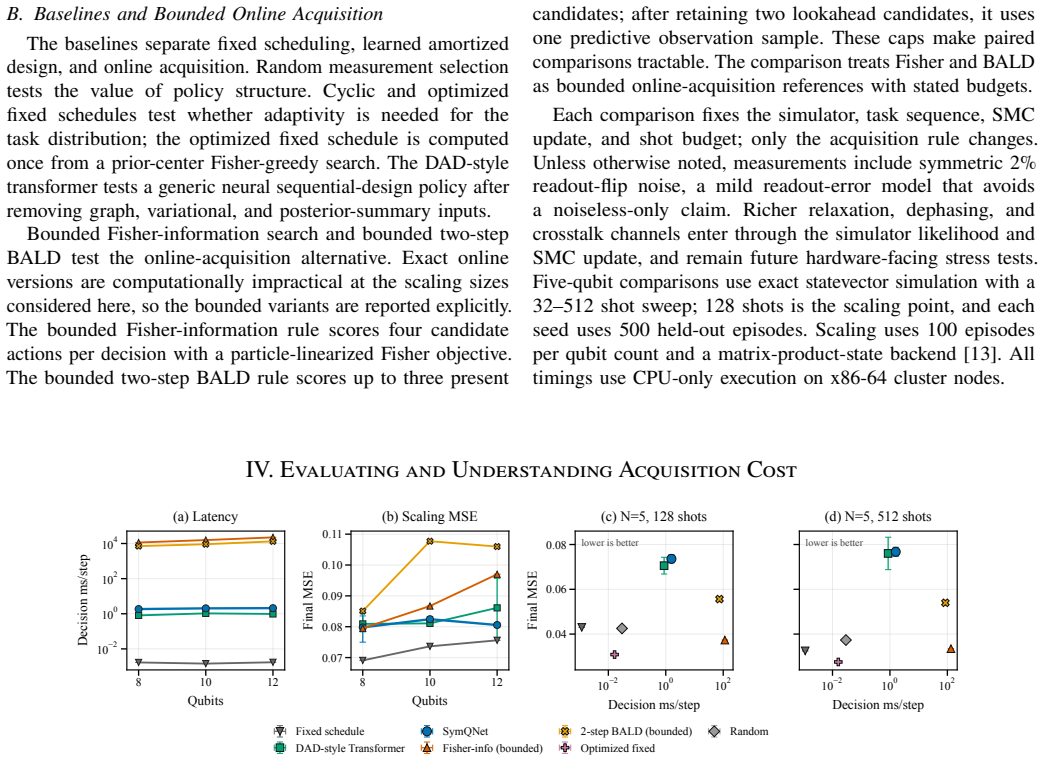
SymQNet learns a posterior-conditioned acquisition policy offline via reinforcement learning. Once trained, the policy selects the next measurement in a single forward pass during live operation, while the Bayesian posterior continues to be updated with each outcome. Benchmarks on transverse-field Ising models show that this amortization reduces acquisition-only decision latency by 47.1 times and 72.6 times at five qubits relative to bounded Fisher-information search and bounded two-step BALD, and enables full simulated steps at twelve qubits to complete in 1.02 seconds versus 13.27 seconds for the BALD baseline.
What carries the argument
A posterior-conditioned neural acquisition policy trained offline with reinforcement learning that replaces repeated online Bayesian design optimization.
If this is right
- Acquisition decisions become fast enough for repeated adaptive calibration loops on quantum hardware.
- Bayesian posterior feedback is retained even though the acquisition step itself is amortized.
- Full experimental steps at twelve qubits complete in roughly one second instead of over thirteen seconds.
- The same offline-trained policy works across the tested qubit counts without retraining during operation.
Where Pith is reading between the lines
- The same amortization pattern could apply to other adaptive quantum tasks that rely on posterior-conditioned experiment selection.
- If the training distribution of posteriors is broad enough, the policy could support continuous, hands-off device calibration without periodic retraining.
- Scaling the method to larger parameter spaces would require checking whether the policy network size and training cost remain manageable.
Load-bearing premise
The policy learned on simulated posteriors stays near-optimal when inserted into a live loop that receives real measurement outcomes.
What would settle it
Run the fixed SymQNet policy on a real quantum device and measure whether the achieved Hamiltonian reconstruction error or convergence speed matches that of online recomputation of the acquisition rule.
Figures
read the original abstract
Adaptive Hamiltonian learning is central to calibrating and characterizing quantum devices. In an adaptive controller, choosing the next experiment is itself a computation. Bayesian design rules are recomputed after every posterior update, and that step can take seconds. Across hundreds of shots, those seconds become a significant wall-clock cost for adaptivity. We introduce SymQNet, an amortized reinforcement-learning approach for low-latency adaptive Hamiltonian learning. SymQNet learns a posterior-conditioned acquisition policy offline, then uses a fast policy forward pass online while retaining Bayesian posterior feedback. On transverse-field Ising benchmarks, SymQNet substantially reduces acquisition latency relative to bounded Fisher-information search and bounded two-step Bayesian active learning by disagreement (BALD). At five qubits, it reduces acquisition-only decision latency by $47.1\times$ and $72.6\times$ relative to these online baselines; at twelve qubits, full simulated steps take $1.02$ s for SymQNet versus $13.27$ s for bounded two-step BALD. Overall, we show that learned acquisition can make adaptive Hamiltonian learning practical for repeated low-latency workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SymQNet, an amortized reinforcement-learning method that learns a posterior-conditioned acquisition policy offline on simulated transverse-field Ising posteriors and deploys a fast forward pass for online decisions in adaptive Hamiltonian learning. It reports acquisition latency reductions of 47.1× and 72.6× at five qubits relative to bounded Fisher-information search and bounded two-step BALD, and full simulated step times of 1.02 s versus 13.27 s at twelve qubits.
Significance. If the learned policy generalizes, the amortization strategy could substantially lower the computational barrier to repeated adaptive Bayesian experiments on quantum devices. The work correctly identifies the online recomputation bottleneck and demonstrates that offline training can yield large wall-clock gains inside simulation; however, the absence of any test under real measurement statistics limits the strength of the practicality claim.
major comments (1)
- [Abstract] Abstract and reported benchmarks: all latency numbers (47.1×, 72.6×, 1.02 s vs. 13.27 s) are measured inside the identical idealized simulation used for policy training. No results or analysis address whether the fixed policy remains near-optimal when real-device outcomes replace simulated likelihoods, which is load-bearing for the claim that SymQNet makes adaptive Hamiltonian learning practical for low-latency workloads.
minor comments (2)
- [Abstract] Abstract: the concrete latency figures are given without error bars, standard deviations across random seeds, or training hyper-parameter details, making it impossible to judge the stability of the reported speedups.
- The manuscript should clarify whether the policy is frozen after training or whether any online adaptation occurs; the current description leaves this ambiguous.
Simulated Author's Rebuttal
We thank the referee for this comment on the scope of our validation. We address it directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract and reported benchmarks: all latency numbers (47.1×, 72.6×, 1.02 s vs. 13.27 s) are measured inside the identical idealized simulation used for policy training. No results or analysis address whether the fixed policy remains near-optimal when real-device outcomes replace simulated likelihoods, which is load-bearing for the claim that SymQNet makes adaptive Hamiltonian learning practical for low-latency workloads.
Authors: We agree that all reported latency numbers were obtained inside the same idealized simulation used to train the policy, and that we provide no experiments or analysis on real-device measurement statistics. The core technical claim is that a fixed, learned policy can replace repeated online optimization while preserving the Bayesian loop; the measured wall-clock savings are therefore a property of the inference procedure (one forward pass versus repeated search or optimization) and do not depend on the origin of the likelihood values. Nevertheless, the referee is correct that we have not verified whether the policy remains near-optimal when the posterior is formed from real-device data that may contain unmodeled noise or distribution shift. This is a genuine limitation for any claim of immediate practicality on hardware. We will revise the abstract, introduction, and conclusion to state explicitly that all results are simulation-based and to list real-device validation as future work. No new experiments will be added. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents SymQNet as an amortized RL policy trained offline on simulated posteriors from the transverse-field Ising model, then deployed for fast online acquisition. Latency claims are direct wall-clock measurements against independent external baselines (bounded Fisher search, bounded two-step BALD), with no equations, fitted parameters, or self-citations that reduce the reported speedups (47.1×/72.6× at 5 qubits; 1.02 s vs 13.27 s at 12 qubits) to a self-referential definition or tautology. The central result is an empirical engineering comparison that remains falsifiable against those baselines and does not rely on any load-bearing self-citation chain or ansatz smuggled from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hamiltonian learning and certification using quantum resources,
N. Wiebe, C. Granade, C. Ferrie, and D. G. Cory, “Hamiltonian learning and certification using quantum resources,”Physical Review Letters, vol. 112, no. 19, p. 190501, 2014
2014
-
[2]
Robust online Hamiltonian learning,
C. E. Granade, C. Ferrie, N. Wiebe, and D. G. Cory, “Robust online Hamiltonian learning,”New Journal of Physics, vol. 14, no. 10, p. 103013, 2012
2012
-
[3]
Adaptive Bayesian quantum tomography,
F. Huszár and N. M. T. Houlsby, “Adaptive Bayesian quantum tomography,” Physical Review A, vol. 85, no. 5, p. 052120, 2012
2012
-
[4]
Bayesianactivelearning for classification and preference learning,
N.Houlsby,F.Huszár,Z.Ghahramani,andM.Lengyel,“Bayesianactivelearning for classification and preference learning,”arXiv preprint arXiv:1112.5745, 2011
Pith/arXiv arXiv 2011
-
[5]
Deep Adaptive Design: Amortizing sequential Bayesian experimental design,
A. Foster, D. R. Ivanova, I. Malik, and T. Rainforth, “Deep Adaptive Design: Amortizing sequential Bayesian experimental design,” inProceedings of the 38th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 139, 2021, pp. 3384–3395
2021
-
[6]
Optimizing sequential experimental design with deep reinforcement learning,
T. Blau, E. V. Bonilla, I. Chades, and A. Dezfouli, “Optimizing sequential experimental design with deep reinforcement learning,” inProceedings of the 39th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 162, 2022, pp. 2107–2128
2022
-
[7]
Proximalpolicy optimization algorithms,
J.Schulman,F.Wolski,P.Dhariwal,A.Radford,andO.Klimov,“Proximalpolicy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[8]
Neural-network heuristics for adaptive Bayesian quantum estimation,
L. J. Fiderer, J. Schuff, and D. Braun, “Neural-network heuristics for adaptive Bayesian quantum estimation,”PRX Quantum, vol. 2, no. 2, p. 020303, 2021
2021
-
[9]
Model-aware reinforcement learning for high-performance Bayesian experimental design in quantum metrology,
F. Belliardo, F. Zoratti, F. Marquardt, and V. Giovannetti, “Model-aware reinforcement learning for high-performance Bayesian experimental design in quantum metrology,”Quantum, vol. 8, p. 1555, 2024
2024
-
[10]
Deep Bayesian experimental design for quantum many-body systems,
L. Sarra and F. Marquardt, “Deep Bayesian experimental design for quantum many-body systems,”Machine Learning: Science and Technology, vol. 4, no. 4, p. 045022, 2023
2023
-
[11]
The one-dimensional Ising model with a transverse field,
P. Pfeuty, “The one-dimensional Ising model with a transverse field,”Annals of Physics, vol. 57, no. 1, pp. 79–90, 1970
1970
-
[12]
Doucet, N
A. Doucet, N. de Freitas, and N. Gordon, Eds.,Sequential Monte Carlo Methods in Practice. Springer, 2001
2001
-
[13]
Efficient simulation of one-dimensional quantum many-body systems,
G. Vidal, “Efficient simulation of one-dimensional quantum many-body systems,” Physical Review Letters, vol. 93, no. 4, p. 040502, 2004
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.