Dense Structural Priors for Sparse Functional Landmark Localization in Surgical Videos
Pith reviewed 2026-07-01 00:41 UTC · model grok-4.3
The pith
A lightweight refinement framework uses non-oracle SAM 3 masks from coarse predictions as structural priors to localize functional landmarks in surgical videos without manual mask annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
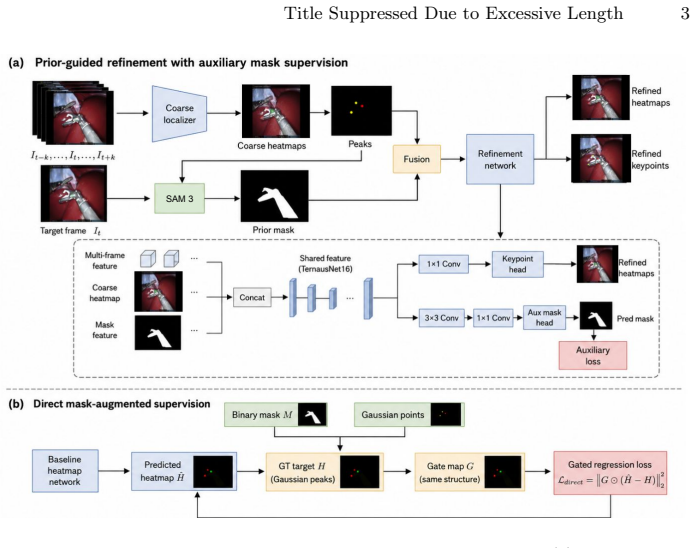
The paper claims that prediction-derived non-oracle SAM 3 masks, when fused as structural priors with visual and heatmap features in a refinement network, supply effective intermediate guidance for action-dependent landmark prediction and enable overall F1 scores of 72.4 percent for tip and 58.0 percent for anchor localization across heterogeneous surgical videos without requiring manual pixel-level mask annotations.
What carries the argument
The prediction-derived mask-prior refinement, in which coarse multi-frame tip and anchor predictions prompt SAM 3 to produce structural masks that are fused into the localization network.
If this is right
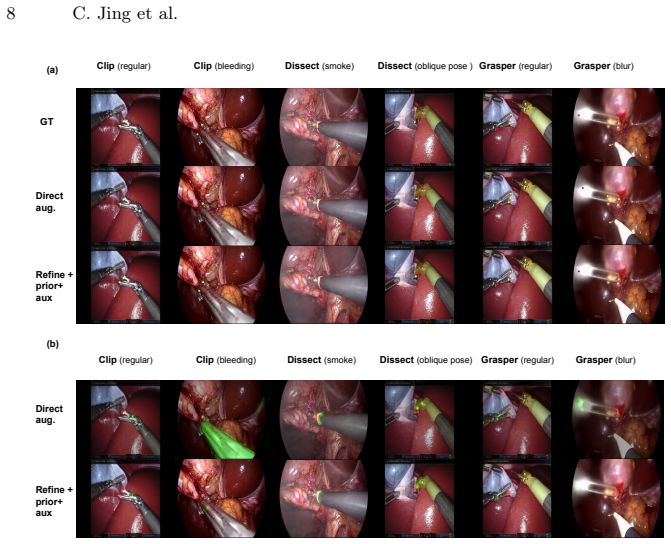
- Directly imposing masks on heatmap targets biases learning toward broad tool regions instead of precise functional landmarks.
- Prediction-derived priors together with auxiliary mask supervision provide more effective structural guidance than direct mask imposition.
- The approach reaches 72.4 percent F1 for tip localization and 58.0 percent F1 for anchor localization without manual pixel-level mask annotations.
- Results remain consistent across 7,867 clips drawn from 60 videos in five sources spanning YouTube and clinical collections.
Where Pith is reading between the lines
- Improving the accuracy of the initial coarse prompt predictions would likely raise the quality of the generated structural masks and the final localization performance.
- The same refinement pattern could be applied to other video domains where foundation models supply general object structure but task-specific sparse points must still be localized.
- Action-conditioned semantics can be added on top of foundation-model structure without any retraining of the foundation model on domain-specific data.
Load-bearing premise
The coarse multi-frame network produces prompts accurate enough that the resulting SAM 3 masks supply useful structural guidance rather than noise for the refinement stage.
What would settle it
An ablation in which removing the SAM 3 mask input from the refinement network yields equal or higher F1 scores for tip and anchor localization would falsify the claimed utility of the structural priors.
Figures
read the original abstract
Vision foundation models such as SAM 3 can provide transferable object-level structure across diverse surgical video conditions, but segmentation outputs do not explicitly encode the action-conditioned semantics that define functional surgical landmarks. Estimating instrument extent and geometry differs from localizing the tip or anchor relevant to clipping, grasping, or dissecting. We investigate vision foundation model-enabled sparse action-aware landmark localization, using zero-shot, point-prompted structural masks to provide dense instrument-level context without manual pixel-level mask annotations. We propose a lightweight refinement framework that uses SAM 3 as a structural prior. A coarse multi-frame network predicts tip and anchor prompts, generating non-oracle masks that are fused with visual and heatmap features to refine functional landmark predictions. We compare direct mask-augmented supervision, prediction-derived mask-prior refinement, and auxiliary mask supervision to examine how vision foundation model-derived structure should enter a precision-oriented localization system. Experiments on 7,867 clips from 60 surgical videos spanning YouTube, Cholec80, HeiChole, SurgVU, and CRCD evaluate the approach under heterogeneous conditions. Without manual pixel-level mask annotations for training, the proposed model achieves overall F1 scores of 72.4% for tip and 58.0% for anchor localization. Directly imposing masks on heatmap targets biases learning toward broad tool regions, whereas prediction-derived priors and auxiliary supervision provide effective intermediate structural guidance for action-dependent landmark prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a lightweight refinement framework leveraging SAM 3 structural masks generated from prompts predicted by a coarse multi-frame network can localize functional surgical landmarks (tip and anchor) without manual pixel-level mask annotations. It compares three mask incorporation strategies (direct mask-augmented supervision, prediction-derived mask-prior refinement, and auxiliary mask supervision) and reports overall F1 scores of 72.4% for tip and 58.0% for anchor on 7,867 clips from 60 videos across YouTube, Cholec80, HeiChole, SurgVU, and CRCD under heterogeneous conditions.
Significance. If the central empirical claim holds, the work would demonstrate a practical route to incorporating vision foundation model priors for annotation-efficient, action-aware landmark localization in surgical videos. The multi-source dataset evaluation spanning diverse conditions is a clear strength. The significance is limited by the absence of supporting ablations on the key mechanism.
major comments (2)
- [Abstract] Abstract: The headline F1 scores of 72.4% (tip) and 58.0% (anchor) are obtained exclusively via prediction-derived, non-oracle SAM 3 masks fed into the refinement stage. No quantitative characterization of the coarse multi-frame network's own tip/anchor localization error is supplied, nor is there an ablation that isolates prompt noise (e.g., oracle point prompts vs. predicted prompts) or compares the three incorporation strategies with numerical results. This directly bears on whether the masks supply useful geometry or noise, which is load-bearing for the central claim.
- [Abstract] Abstract: The manuscript states results on 7,867 clips from 60 videos but provides no dataset splits, train/test partitioning details, cross-validation procedure, or error bars/statistical tests on the reported F1 scores. These omissions prevent assessment of whether the performance differences among the three mask strategies are reliable or generalizable.
minor comments (1)
- [Abstract] The abstract sentence listing the three compared strategies would be clearer if it explicitly named them in the results clause rather than only in the methods description.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each of the major comments below and will revise the manuscript to incorporate additional details and ablations as requested.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline F1 scores of 72.4% (tip) and 58.0% (anchor) are obtained exclusively via prediction-derived, non-oracle SAM 3 masks fed into the refinement stage. No quantitative characterization of the coarse multi-frame network's own tip/anchor localization error is supplied, nor is there an ablation that isolates prompt noise (e.g., oracle point prompts vs. predicted prompts) or compares the three incorporation strategies with numerical results. This directly bears on whether the masks supply useful geometry or noise, which is load-bearing for the central claim.
Authors: The abstract summarizes the performance of the complete proposed system, which relies on the prediction-derived masks. The full manuscript describes the three incorporation strategies and provides reasoning for why prediction-derived mask-prior refinement and auxiliary supervision are preferable based on the observed behavior. However, we recognize that quantitative comparisons are necessary to fully support the claim. In the revision, we will add a table presenting the F1 scores for the coarse multi-frame network alone, as well as for each of the three mask incorporation strategies. We will also include results using oracle point prompts to isolate the impact of prompt noise from the coarse network. These additions will clarify the contribution of the SAM 3 priors. revision: yes
-
Referee: [Abstract] Abstract: The manuscript states results on 7,867 clips from 60 videos but provides no dataset splits, train/test partitioning details, cross-validation procedure, or error bars/statistical tests on the reported F1 scores. These omissions prevent assessment of whether the performance differences among the three mask strategies are reliable or generalizable.
Authors: We agree that these experimental details are important for evaluating the reliability of the results. The dataset consists of clips from 60 videos across five sources, and we used a fixed train/test split to ensure no video overlap between train and test sets. We will provide the exact split details, including the number of clips and videos in each set, in the revised methods section. As the evaluation involves a single split on a multi-source dataset, cross-validation was not performed, but we will report the results with this context. If feasible, we will include error bars from multiple training runs or note the single-run evaluation. These changes will be made in the revision. revision: yes
Circularity Check
No circularity: empirical pipeline evaluated on external data
full rationale
The paper describes a two-stage empirical pipeline (coarse multi-frame network generates point prompts for non-oracle SAM 3 masks; masks are fused as structural priors into a refinement network for tip/anchor localization) and reports F1 scores on held-out clips from YouTube, Cholec80, HeiChole, SurgVU, and CRCD. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would make any reported quantity equivalent to its inputs by construction. The central claim rests on external benchmark performance rather than internal re-derivation, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2017 Robotic Instrument Segmentation Challenge
Allan, M., Shvets, A., Kurmann, T., Zhang, Z., Duggal, R., Su, Y.H., Rieke, N., Laina, I., Kalavakonda, N., Bodenstedt, S., et al.: 2017 robotic instrument segmentation challenge. arXiv preprint arXiv:1902.06426 (2019). https://doi.org/10.48550/arXiv.1902.06426
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1902.06426 2017
-
[2]
arXiv preprint arXiv:2001.11190 (2020)
Allan, M., et al.: 2018 robotic scene segmentation challenge. arXiv preprint arXiv:2001.11190 (2020). https://doi.org/10.48550/arXiv.2001.11190
-
[3]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., Mavroudi, E., Xu, K., Wu, T.H., Zhou, Y., Momeni, L., Hazra, R., Ding, S., Vaze, S., Porcher, F., Li, F., Li, S., Kamath, A., Cheng, H.K., ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.16719 2025
-
[4]
In: Proceedings of the IEEE International Symposium on Biomedical Imaging (ISBI) (2025)
Ghanekar, B., Johnson, L.R., Laughlin, J.L., O’Malley, M.K., Veeraraghavan, A.: Video-based surgical tool-tip and keypoint tracking using multi-frame context- driven deep learning models. In: Proceedings of the IEEE International Symposium on Biomedical Imaging (ISBI) (2025)
2025
-
[5]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Hariharan, B., Arbeláez, P., Girshick, R., Malik, J.: Hypercolumns for object seg- mentation and fine-grained localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 447–456 (2015)
2015
-
[6]
arXiv preprint arXiv:2012.12453 (2020)
Hong, W.Y., Kao, C.L., Kuo, Y.H., Wang, J.R., Chang, W.L., Shih, C.Y.: CholecSeg8k: A semantic segmentation dataset for laparoscopic chole- cystectomy based on Cholec80. arXiv preprint arXiv:2012.12453 (2020). https://doi.org/10.48550/arXiv.2012.12453
-
[7]
RTMPose: Real-time multi-person pose estimation based on MMPose
Jiang, T., Lu, P., Zhang, L., Ma, N., Han, R., Lyu, C., Li, Y., Chen, K.: RTM- Pose: Real-time multi-person pose estimation based on MMPose. arXiv preprint arXiv:2303.07399 (2023). https://doi.org/10.48550/arXiv.2303.07399
-
[8]
In: Proceedings of the 2nd Machine Learning for Healthcare Conference
Law, H., Ghani, K., Deng, J.: Surgeon technical skill assessment using computer vision based analysis. In: Proceedings of the 2nd Machine Learning for Healthcare Conference. Proceedings of Machine Learning Research, vol. 68, pp. 88–99. PMLR (2017)
2017
-
[9]
Ma, J., He, Y., Li, F., Han, L., You, C., Wang, B.: Segment anything in medical images. Nature Communications15, 654 (2024). https://doi.org/10.1038/s41467- 024-44824-z
-
[10]
Frontiers in Robotics and AI9, 1030846 (2022)
Nema, S., Vachhani, L.: Surgical instrument detection and tracking technologies: Automating dataset labeling for surgical skill assessment. Frontiers in Robotics and AI9, 1030846 (2022). https://doi.org/10.3389/frobt.2022.1030846 10 C. Jing et al
-
[11]
arXiv preprint arXiv:2412.12238 (2024)
Oh, K.H., Borgioli, L., Mangano, A., Valle, V., Pangrazio, M.D., Toti, F., Pozza, G., Ambrosini, L., Ducas, A., Žefran, M., et al.: Expanded comprehensive robotic cholecystectomy dataset (CRCD). arXiv preprint arXiv:2412.12238 (2024)
-
[12]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V., Carion, N., Wu, C.Y., Girshick, R., Dollár, P., Feichtenhofer, C.: SAM 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
arXiv preprint arXiv:2304.13014 (2023)
Rueckert, T., Rueckert, D., Palm, C.: Methods and datasets for segmentation of minimally invasive surgical instruments in endoscopic images and videos: A review of the state of the art. arXiv preprint arXiv:2304.13014 (2023). https://doi.org/10.48550/arXiv.2304.13014
-
[14]
International Journal of Com- puter Assisted Radiology and Surgery (2024)
Sheng, Y., Bano, S., Clarkson, M.J., Islam, M.: Surgical-DeSAM: Decoupling SAM for instrument segmentation in robotic surgery. International Journal of Com- puter Assisted Radiology and Surgery (2024). https://doi.org/10.1007/s11548-024- 03163-6
-
[15]
IEEE Transactions on Medical Imaging36(1), 86–97 (2017)
Twinanda, A.P., Shehata, S., Mutter, D., Marescaux, J., de Mathelin, M., Padoy, N.: EndoNet: A deep architecture for recognition tasks on laparo- scopic videos. IEEE Transactions on Medical Imaging36(1), 86–97 (2017). https://doi.org/10.1109/TMI.2016.2593957
-
[16]
Medical Image Analysis86, 102770 (2023)
Wagner, M., Müller-Stich, B.P., Kisilenko, A., Tran, D., Heger, P., Mündermann, L., Lubotsky, D., Müller, B., Davitashvili, T., Capek, M., et al.: Comparative validation of machine learning algorithms for surgical workflow and skill anal- ysis with the HeiChole benchmark. Medical Image Analysis86, 102770 (2023). https://doi.org/10.1016/j.media.2023.102770
-
[17]
arXiv preprint arXiv:2308.07156 (2023)
Wang, A., Islam, M., Xu, M., Zhang, Y., Ren, H.: SAM meets robotic surgery: An empirical study on generalization, robustness and adaptation. arXiv preprint arXiv:2308.07156 (2023). https://doi.org/10.48550/arXiv.2308.07156
-
[18]
In: Proceedings of the European Conference on Computer Vision
Xiao,B.,Wu,H.,Wei,Y.:Simplebaselinesforhumanposeestimationandtracking. In: Proceedings of the European Conference on Computer Vision. pp. 466–481 (2018)
2018
-
[19]
Medical Image Analysis105, 103674 (2025)
Xu, H., Weld, A., Xu, C., Roddan, A., Cartucho, J., Karaoglu, M.A., Ladikos, A., Li, Y., Li, Y., Shen, D., Yang, S., Lee, G., Park, S., Shin, J., Kim, Y.G., Fothergill, L., Jones, D., Valdastri, P., Sarikaya, D., Giannarou, S.: SurgRIPE challenge: Benchmark of surgical robot instrument pose estimation. Medical Image Analysis105, 103674 (2025). https://doi...
-
[20]
Yaseen, M.: What is YOLOv8: An in-depth exploration of the internal features of the next-generation object detector. arXiv preprint arXiv:2408.15857 (2024)
-
[21]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yue, W., Zhang, J., Hu, K., Xia, Y., Luo, J., Wang, Z.: SurgicalSAM: Ef- ficient class promptable surgical instrument segmentation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 7300–7308 (2024). https://doi.org/10.1609/aaai.v38i7.28514
-
[22]
Computer Assisted Surgery22(sup1), 26–35 (2017)
Zhao, Z., Voros, S., Weng, Y., Chang, F., Li, R.: Tracking-by-detection of surgical instruments in minimally invasive surgery via the convolutional neural network deep learning-based method. Computer Assisted Surgery22(sup1), 26–35 (2017). https://doi.org/10.1080/24699322.2017.1378777
-
[23]
Surgical Visual Understanding (SurgVU) Dataset
Zia, A., Berniker, M., Nespolo, R., Perreault, C., Wang, Z., Mueller, B., Schmidt, R., Bhattacharyya, K., Liu, X., Jarc, A.: Surgical visual understanding (SurgVU) dataset. arXiv preprint arXiv:2501.09209 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.