Non-Linear Strategic Classification Made Practical
Pith reviewed 2026-06-29 01:49 UTC · model grok-4.3
The pith
A Lagrangian duality approximation makes best-response computation tractable for non-linear strategic classifiers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By reformulating the strategic response as a constrained optimisation problem, we can construct a Lagrangian that is amenable to first order optimisation methods. This approach reproduces closed-form strategic behaviour in linear settings and can be straight-forwardly applied to non-linear settings. We show how the Implicit Function Theorem can be used in conjunction with our proposed response formulation during classifier learning to compute the total gradient of the loss, yielding a novel training algorithm.
What carries the argument
Lagrangian of the constrained best-response optimization problem, paired with the Implicit Function Theorem to obtain end-to-end gradients.
If this is right
- The same Lagrangian construction recovers the known closed-form best response when the classifier is linear.
- The formulation extends directly to non-linear classifiers without requiring a closed-form solution.
- The Implicit Function Theorem supplies the total derivative needed to train the classifier while accounting for the induced strategic behavior.
- Models trained with the resulting algorithm record higher strategic accuracy on standard machine-learning datasets.
Where Pith is reading between the lines
- The method could be inserted into existing deep-learning pipelines for domains such as credit scoring or content moderation where feature manipulation is plausible.
- Similar duality-based relaxations might address best-response intractability in other game-theoretic learning settings, such as adversarial training or mechanism design.
- Scalability tests on high-dimensional or very non-linear models would reveal whether the first-order Lagrangian solve remains efficient as input dimension grows.
Load-bearing premise
The Lagrangian approximation of the best response is accurate enough that its error does not materially reduce the final classifier's strategic accuracy, and the Implicit Function Theorem applies without differentiability or constraint-qualification failures.
What would settle it
An experiment in which the Lagrangian-derived manipulations differ enough from true best responses that the resulting classifier shows no improvement, or lower strategic accuracy, than a baseline that uses exact or higher-fidelity responses.
Figures
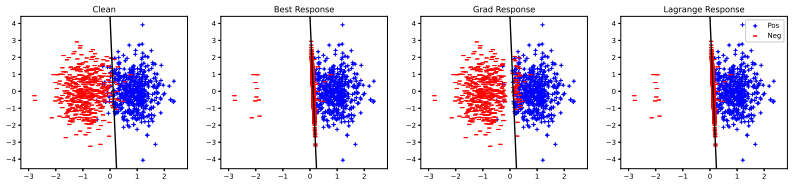
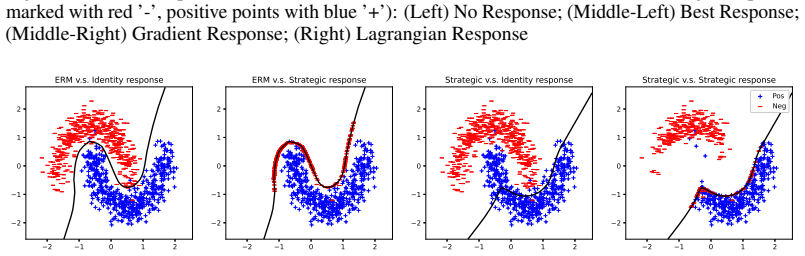
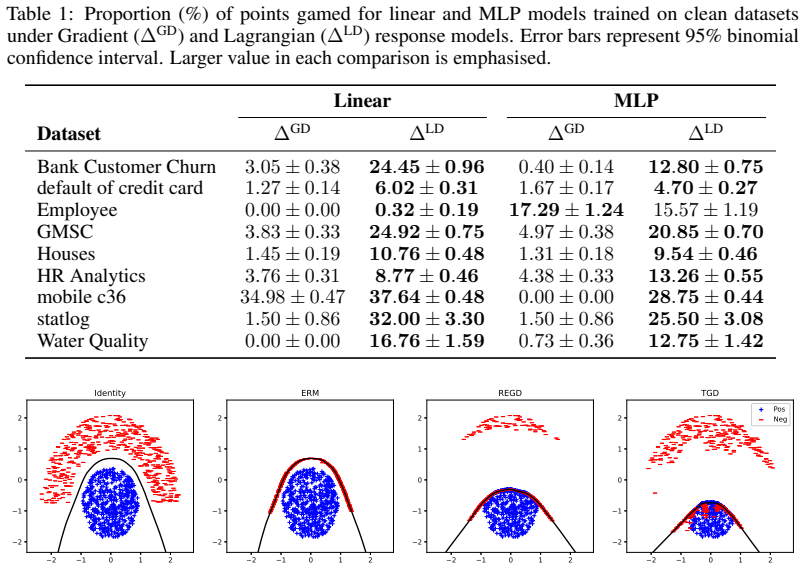
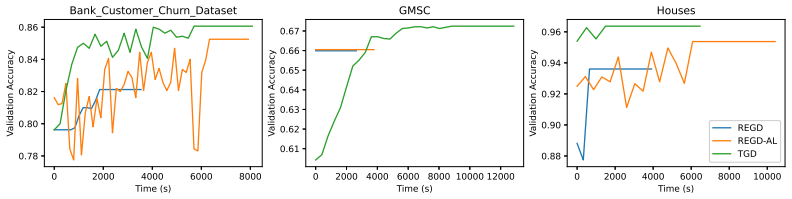
read the original abstract
Algorithmic developments in Strategic Classification have been mostly limited to linear classifiers in settings where the best response has a closed-form solution or can be easily approximated. While some work has explored the role of non-linear classifiers in strategic settings, progress in this direction is impeded by the computational intractability of the strategic behaviour. Addressing this, we present a novel method for approximating the best response by exploiting Lagrangian duality. By reformulating the strategic response as a constrained optimisation problem, we can construct a Lagrangian that is amenable to first order optimisation methods. This approach reproduces closed-form strategic behaviour in linear settings and can be straight-forwardly applied to non-linear settings. We show how the Implicit Function Theorem can be used in conjunction with our proposed response formulation during classifier learning to compute the total gradient of the loss. This connects the classifier parameters directly to the consequent strategic behaviour, yielding a novel training algorithm that can exploit this relationship. Experimental evaluation shows that the resulting models achieve improved strategic accuracy on common machine learning datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that strategic classification has been limited to linear classifiers with closed-form best responses, and addresses intractability for non-linear cases by reformulating the best-response problem as a constrained optimization, constructing a Lagrangian amenable to first-order methods, reproducing linear closed-forms, applying the Implicit Function Theorem to obtain total gradients for a novel training algorithm, and demonstrating improved strategic accuracy on standard ML datasets.
Significance. If the Lagrangian approximation error remains small and the IFT applies without differentiability or constraint-qualification violations, the work would provide the first practical route to training non-linear classifiers under strategic manipulation, extending the field beyond linear models with closed-form solutions and enabling broader use of expressive models in game-theoretic ML settings.
major comments (2)
- [Abstract; IFT section] Abstract and the section on IFT application to the best-response map: the assertion that the construction 'can be straight-forwardly applied to non-linear settings' and that the IFT 'can be used in conjunction with our proposed response formulation' is load-bearing for the gradient-based training algorithm, yet the manuscript supplies no argument, regularity conditions, or empirical verification that x*(θ) is differentiable or that LICQ/MFCQ hold for the non-convex classifiers and costs used in the experiments.
- [Experimental evaluation] Experimental evaluation section: the claim of 'improved strategic accuracy' is unsupported by any reported approximation-error metrics, error bars, baseline comparisons, or discussion of when the duality gap or IFT application fails, leaving the central empirical result without quantitative grounding.
minor comments (1)
- [Abstract] Abstract: 'straight-forwardly' should be 'straightforwardly'.
Simulated Author's Rebuttal
We thank the referee for the constructive report. We address the two major comments below and will revise the manuscript accordingly to strengthen the theoretical and empirical foundations.
read point-by-point responses
-
Referee: [Abstract; IFT section] Abstract and the section on IFT application to the best-response map: the assertion that the construction 'can be straight-forwardly applied to non-linear settings' and that the IFT 'can be used in conjunction with our proposed response formulation' is load-bearing for the gradient-based training algorithm, yet the manuscript supplies no argument, regularity conditions, or empirical verification that x*(θ) is differentiable or that LICQ/MFCQ hold for the non-convex classifiers and costs used in the experiments.
Authors: We agree the manuscript lacks explicit regularity conditions and verification for differentiability of the best-response map x*(θ) and constraint qualifications in non-linear cases. The linear case recovers known closed forms where IFT applies directly, but for non-linear classifiers the claim relies on the Lagrangian formulation being amenable to first-order methods without further proof. In revision we will add a subsection on sufficient conditions (e.g., local strong convexity of the Lagrangian or use of smoothed costs) under which LICQ holds and the IFT applies, plus empirical diagnostics (gradient consistency checks and constraint violation rates) on the experimental datasets. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation section: the claim of 'improved strategic accuracy' is unsupported by any reported approximation-error metrics, error bars, baseline comparisons, or discussion of when the duality gap or IFT application fails, leaving the central empirical result without quantitative grounding.
Authors: The current experiments report strategic accuracy improvements but omit duality-gap estimates, error bars, and failure-case analysis. We will revise the evaluation section to include: (i) duality-gap metrics for the Lagrangian approximation across datasets, (ii) standard error bars over multiple random seeds, (iii) additional baselines (e.g., non-strategic training and heuristic approximations), and (iv) a short discussion of regimes where the approximation degrades (high non-convexity or large duality gaps). These additions will provide the requested quantitative grounding. revision: yes
Circularity Check
No circularity; derivation uses standard Lagrangian duality and IFT as external tools
full rationale
The paper's core construction reformulates the best-response problem via Lagrangian duality (a standard technique) and invokes the Implicit Function Theorem for gradient computation. These are independent mathematical results, not derived from or equivalent to the paper's fitted outputs or self-citations. No equation reduces a reported accuracy gain to a quantity defined by the same data or prior self-work; the linear-case reproduction is a consistency check rather than a definitional loop. The method is presented as applicable to non-linear cases via these tools without load-bearing self-citation chains or ansatzes smuggled from prior author work. This is a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Braverman and S. Garg. The role of randomness and noise in strategic classification.arXiv preprint arXiv:2005.08377, 2020
arXiv 2005
-
[2]
Brückner and T
M. Brückner and T. Scheffer. Stackelberg games for adversarial prediction problems. InKDD, 2011
2011
-
[3]
Cohen, S
L. Cohen, S. Sharifi-Malvajerdi, K. Stang, A. Vakilian, and J. Ziani. Bayesian strategic classification. InNeurIPS, 2024
2024
-
[4]
Cyffers, M
E. Cyffers, M. S. Pydi, J. Atif, and O. Cappé. Optimal classification under performative distribution shift.Advances in Neural Information Processing Systems, 37:68144–68160, 2024
2024
-
[5]
J. Domke. Generic methods for optimization-based modeling. InAISTATS, 2012
2012
- [6]
-
[7]
Franceschi, M
L. Franceschi, M. Donini, P. Frasconi, and M. Pontil. Bilevel programming for hyperparameter optimization and meta-learning. InICML, 2018
2018
-
[8]
Fusion and W
C. Fusion and W. Cukierski. Give me some credit. https://kaggle.com/competitions/ GiveMeSomeCredit, 2011. Kaggle
2011
-
[9]
B. Gao, H. Gouk, H. B. Lee, and T. M. Hospedales. Meta mirror descent: Optimiser learning for fast convergence.arXiv preprint arXiv:2203.02711, 2022
arXiv 2022
-
[10]
B. Gao, H. Gouk, Y . Yang, and T. Hospedales. Loss function learning for domain generalization by implicit gradient. InICML, 2022
2022
-
[11]
J. Geary and H. Gouk. Strategic classification with randomised classifiers.arXiv preprint arXiv:2502.01313, 2025
arXiv 2025
-
[12]
Gordon and R
G. Gordon and R. Tibshirani. Karush-kuhn-tucker conditions.Optimization, 10(725/36):725, 2012
2012
-
[13]
S. Gould, B. Fernando, A. Cherian, and P. Anderson. On differentiating parameterized argmin and argmax problems with application to bi-level optimization.arXiv preprint arXiv:1607.05447, 2016
Pith/arXiv arXiv 2016
-
[14]
Großhans, C
M. Großhans, C. Sawade, M. Brückner, and T. Scheffer. Bayesian games for adversarial regression problems. InICML, 2013
2013
-
[15]
Hardt, N
M. Hardt, N. Megiddo, C. Papadimitriou, and M. Wootters. Strategic classification. In Proceedings of the 2016 ACM conference on innovations in theoretical computer science, pages 111–122, 2016
2016
-
[16]
Z. Izzo, L. Ying, and J. Zou. How to learn when data reacts to your model: performative gradient descent. InICML, 2021
2021
-
[17]
H. W. Kuhn and A. W. Tucker. Linear inequalities and related systems.(am-38), 1957
1957
-
[18]
Levanon and N
S. Levanon and N. Rosenfeld. Strategic classification made practical. InICML, 2021
2021
-
[19]
Levanon and N
S. Levanon and N. Rosenfeld. Generalized strategic classification and the case of aligned incentives. InICML, 2022. 10
2022
-
[20]
Lorraine, P
J. Lorraine, P. Vicol, and D. Duvenaud. Optimizing millions of hyperparameters by implicit differentiation. InAISTATS, 2020
2020
-
[21]
T. R. McIntosh, T. Susnjak, N. Arachchilage, T. Liu, D. Xu, P. Watters, and M. N. Halgamuge. Inadequacies of large language model benchmarks in the era of generative artificial intelligence. IEEE Transactions on Artificial Intelligence, 2025
2025
-
[22]
J. P. Miller, J. C. Perdomo, and T. Zrnic. Outside the echo chamber: Optimizing the performative risk. InInternational Conference on Machine Learning, pages 7710–7720. PMLR, 2021
2021
-
[23]
Milli, J
S. Milli, J. Miller, A. D. Dragan, and M. Hardt. The social cost of strategic classification. In Proceedings of the conference on fairness, accountability, and transparency, pages 230–239, 2019
2019
-
[24]
Mofakhami, I
M. Mofakhami, I. Mitliagkas, and G. Gidel. Performative prediction with neural networks. In AISTATS, 2023
2023
-
[25]
Pedregosa
F. Pedregosa. Hyperparameter optimization with approximate gradient. InICML, 2016
2016
-
[26]
Perdomo, T
J. Perdomo, T. Zrnic, C. Mendler-Dünner, and M. Hardt. Performative prediction. InICML, 2020
2020
-
[27]
Quiñonero-Candela, M
J. Quiñonero-Candela, M. Sugiyama, A. Schwaighofer, and N. D. Lawrence.Dataset shift in machine learning. MIT Press, 2022
2022
-
[28]
Rajeswaran, C
A. Rajeswaran, C. Finn, S. M. Kakade, and S. Levine. Meta-learning with implicit gradients. In NeurIPS, 2019
2019
-
[29]
Rosenfeld.Understanding, Formally Characterizing, and Robustly Handling Real-World Distribution Shift
E. Rosenfeld.Understanding, Formally Characterizing, and Robustly Handling Real-World Distribution Shift. PhD thesis, Carnegie Mellon University, 2023
2023
-
[30]
E. Rosenfeld and N. Rosenfeld. One-shot strategic classification under unknown costs.arXiv preprint arXiv:2311.02761, 2023
arXiv 2023
-
[31]
Sundaram, A
R. Sundaram, A. Vullikanti, H. Xu, and F. Yao. Pac-learning for strategic classification.Journal of Machine Learning Research, 24(192):1–38, 2023
2023
-
[32]
B. Trachtenberg and N. Rosenfeld. Strategic classification with non-linear classifiers.arXiv preprint arXiv:2505.23443, 2025
arXiv 2025
-
[33]
Vanschoren
J. Vanschoren. houses.https://www.openml.org/d/823, 2014. OpenML
2014
-
[34]
B. J. Wittmann, T. Alexanian, C. Bartling, J. Beal, A. Clore, J. Diggans, K. Flyangolts, B. T. Gemler, T. Mitchell, S. T. Murphy, et al. Strengthening nucleic acid biosecurity screening against generative protein design tools.Science, 390(6768):82–87, 2025
2025
- [35]
- [36]
-
[37]
Zucchet and J
N. Zucchet and J. Sacramento. Beyond backpropagation: bilevel optimization through implicit differentiation and equilibrium propagation.Neural Computation, 34(12):2309–2346, 2022. 11 A Proof of Theorem 1 Proof.Without loss of generality, assume every point gamed by∆ 2 is also gamed by∆ 1: fθ(∆2(x, θ))̸=f θ(x) =⇒f θ(∆1(x, θ))̸=f θ(x).(11) Therefore, I θ S(...
2022
-
[38]
Perdomo et al.[26], propose an iterative gradient-based method that they show can be used to approximate the best response in Strategic Classification problems
Such methods involve using gradient ascent to solve the lower level maximisation, and gradient descent to solve the upper level minimisation. Perdomo et al.[26], propose an iterative gradient-based method that they show can be used to approximate the best response in Strategic Classification problems. However, we note that, since f is a binary classifier,...
2080
-
[39]
Both of these responses were optimised with the Adam optimiser with a weight decay specified per dataset
∆LD was learned using an Augmented Lagrangian-based approach to optimise the Lagrangian as proposed in Equation 9. Both of these responses were optimised with the Adam optimiser with a weight decay specified per dataset. Each response was computed by running the iterative optimiser for 1000 iterations per batch of the training dataset with a learning rate...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.