When Does Overlap Help? OSU-Mem and a Cell-Conditional Analysis of Trajectory Memory for LLM Agents
Pith reviewed 2026-06-30 11:02 UTC · model grok-4.3
The pith
Overlapping memory improves LLM agent retrieval when evidence steps share tool calls or entities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
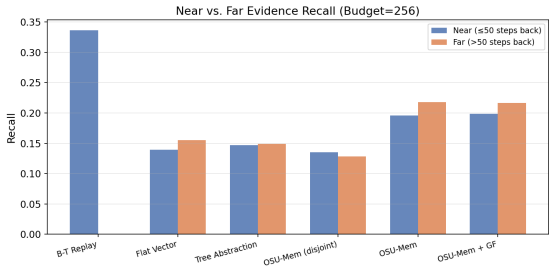
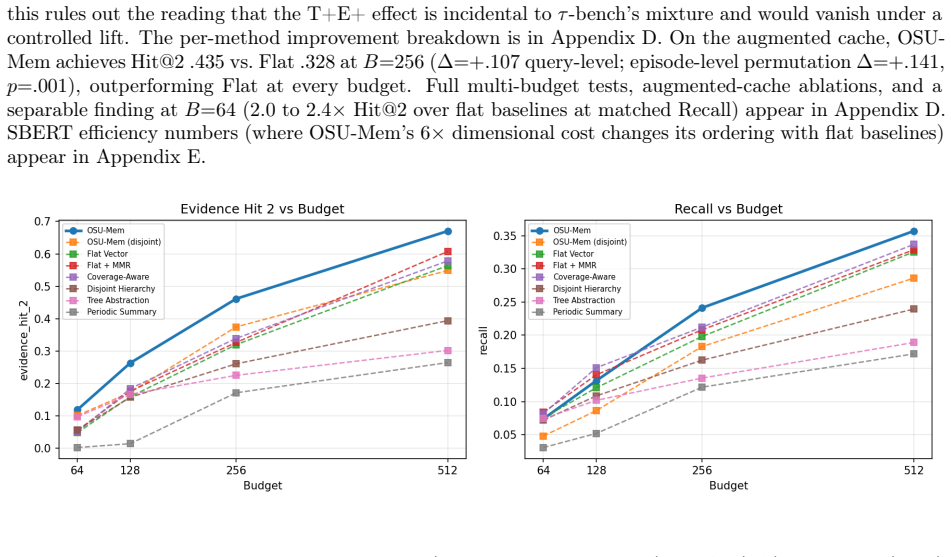
Organizing trajectory memory into overlapping semantic units (OSUs) -- groups of related steps where one step may belong to several units -- helps retrieval over flat or disjoint alternatives when the evidence steps a query needs share tool calls or entities, but hurts when those steps are fully heterogeneous and share neither. OSU-Mem retrieves from an overlapping OSU pool via budgeted coarse-to-fine expansion. On a synthetic benchmark where evidence carries shared structure by construction, OSU-Mem improves over the strongest baseline; on a concatenated unaugmented setting the aggregate advantage vanishes, yet splitting queries by shared tools and entities shows the tie is an artifact of m
What carries the argument
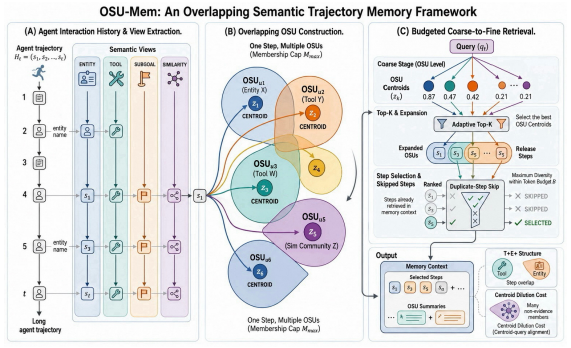
Overlapping semantic units (OSUs), groups of related steps in which one step may belong to several units, retrieved from an OSU pool via budgeted coarse-to-fine expansion.
If this is right
- When evidence steps share tool calls or entities, overlapping memory improves retrieval quality over flat or disjoint methods.
- When evidence steps are fully heterogeneous and share neither, overlapping memory degrades retrieval and downstream decision quality.
- A metadata-based heuristic can predict when overlap is likely to help because the relevant sharing is cheaply estimable from tool and entity metadata.
- On benchmarks where evidence is constructed to carry shared structure, OSU-Mem outperforms the strongest baseline as the conditional theory predicts.
- Aggregate performance comparisons that mix query types mask the conditional nature of the benefit and produce misleading near-ties.
Where Pith is reading between the lines
- The metadata heuristic could be used at runtime to choose between overlapping and flat memory organization depending on the expected query type.
- Similar conditional analyses might apply to memory design for other long-horizon tasks where evidence relevance depends on shared attributes.
- The principle could be tested by constructing benchmarks that vary the degree of tool and entity overlap while holding coverage fixed.
Load-bearing premise
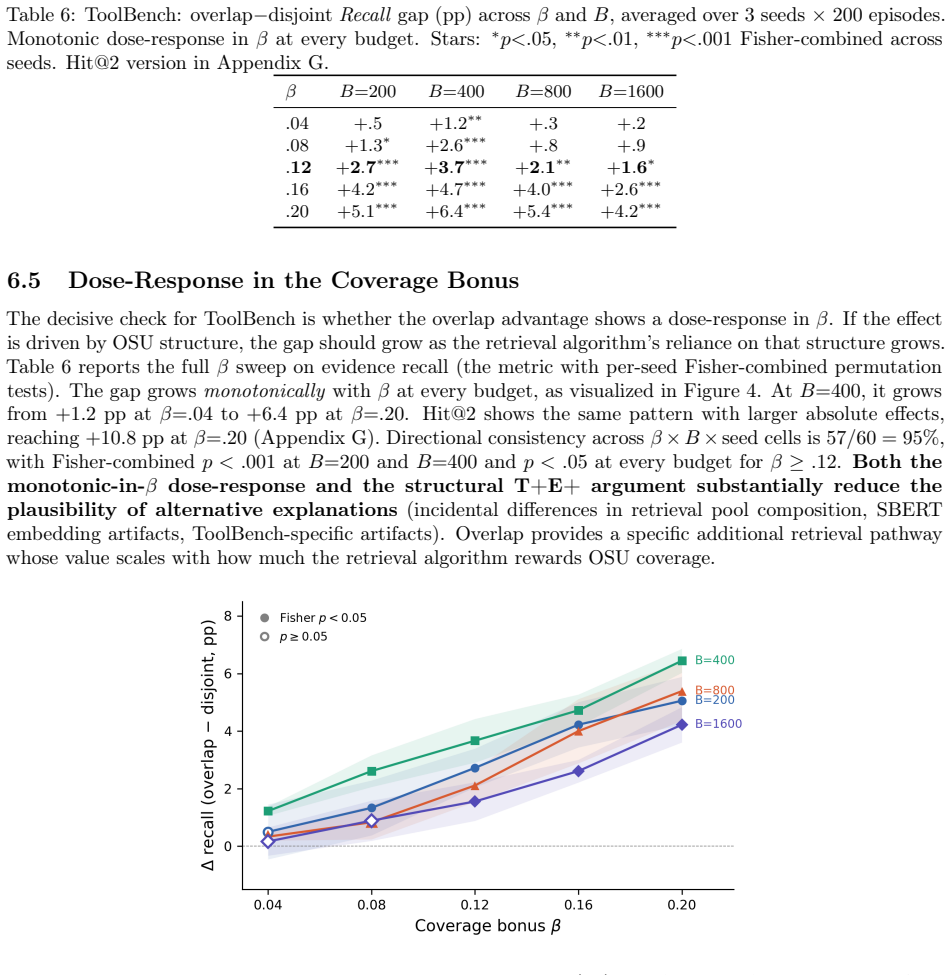
That sharing of tool calls or entities between evidence steps is the dominant structural factor determining overlap benefit, and that the synthetic benchmark and ToolBench construction isolate this factor without confounding artifacts from data generation.
What would settle it
A new benchmark in which queries require evidence steps that share tool calls or entities yet overlapping retrieval fails to improve over flat retrieval, or in which fully heterogeneous steps show clear benefit from overlap.
Figures
read the original abstract
Long-horizon large language model (LLM) agents accumulate interaction trajectories that quickly exceed any practical prompt budget, and existing memory methods either truncate aggressively and lose non-local evidence or retain boilerplate that degrades decision quality. We ask a mechanism question rather than claiming a better general-purpose memory system: when does organizing trajectory memory into overlapping semantic units (OSUs) -- groups of related steps in which one step may belong to several units -- help retrieval over flat or disjoint alternatives? We instantiate this in OSU-Mem, which retrieves from an overlapping OSU pool via budgeted coarse-to-fine expansion, and show its benefit is conditional: overlapping memory helps when the evidence steps a query needs share tool calls or entities, but hurts when those steps are fully heterogeneous and share neither. On a synthetic benchmark where evidence carries such shared structure by construction, OSU-Mem improves over the strongest baseline as the theory predicts; yet on a concatenated, constructed unaugmented $\tau$-bench setting its aggregate advantage over flat retrieval vanishes. Splitting queries by whether their evidence shares tools and entities shows this near-tie to be an artifact of mixing query types rather than a property of either method, and ToolBench, a controlled probe built to carry shared structure by design, corroborates the same mechanism via an overlap-vs.-disjoint construction contrast (under a coverage-guided variant), isolating the construction principle rather than validating the full default system. Because the relevant sharing is cheaply estimable from metadata, the analysis yields a metadata-based heuristic for predicting when overlap is likely to improve retrieval. We deliberately isolate the retrieval layer, assessed by retrieval quality and an LLM-mediated evidence-selection stage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that organizing trajectory memory for LLM agents into overlapping semantic units (OSUs) improves retrieval precisely when the evidence steps needed for a query share tool calls or entities, but hurts performance when those steps are fully heterogeneous and share neither. This conditional mechanism is supported via a synthetic benchmark embedding shared structure by construction, an overlap-vs-disjoint contrast on ToolBench, and query splitting on a concatenated τ-bench setting that shows aggregate near-ties are artifacts of mixing query types; a metadata-based heuristic is derived, with the analysis deliberately isolating the retrieval layer (plus one LLM-mediated selection stage) rather than claiming end-to-end superiority.
Significance. If the conditional claim holds, the work offers a useful mechanistic contribution to memory organization for long-horizon LLM agents by replacing blanket superiority claims with condition-specific guidance. Strengths include the use of controlled constructions that embed the tested property externally to the fitted system, explicit recognition that aggregate results can mislead, and isolation of retrieval quality from full agent performance.
major comments (1)
- [Experimental Setup] Experimental Setup (and associated benchmark construction paragraphs): insufficient detail is provided on the precise generation rules for the synthetic benchmark, the exact metadata-based criteria and implementation for splitting queries by tool/entity sharing in the τ-bench analysis, baseline implementations, and any data exclusion rules. These elements are load-bearing for confirming that the reported conditional effects are not artifacts of post-hoc choices or confounding in data construction.
minor comments (2)
- [Abstract] Abstract: the phrase 'concatenated, constructed unaugmented τ-bench setting' is unclear without a brief gloss on what 'unaugmented' and 'concatenated' specifically entail in the experimental design.
- [Abstract] Abstract: consider noting the scale (number of queries or trajectories) of the main experiments to help readers assess the robustness of the conditional findings.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the mechanistic contribution of the work. We will address the concern regarding insufficient detail in the experimental setup by expanding the relevant sections in the revised manuscript.
read point-by-point responses
-
Referee: [Experimental Setup] Experimental Setup (and associated benchmark construction paragraphs): insufficient detail is provided on the precise generation rules for the synthetic benchmark, the exact metadata-based criteria and implementation for splitting queries by tool/entity sharing in the τ-bench analysis, baseline implementations, and any data exclusion rules. These elements are load-bearing for confirming that the reported conditional effects are not artifacts of post-hoc choices or confounding in data construction.
Authors: We acknowledge that the current manuscript provides insufficient detail on these aspects, which are indeed critical for reproducibility and validating the conditional effects. In the revision, we will add precise descriptions of the synthetic benchmark generation rules, the exact criteria and code-level implementation for the metadata-based query splitting in the τ-bench analysis, full specifications of baseline implementations, and any data exclusion rules. This will be incorporated into the Experimental Setup and benchmark construction paragraphs to eliminate any ambiguity about post-hoc choices. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper proposes a conditional mechanism (overlap benefits when evidence steps share tool calls/entities) and tests it via externally constructed benchmarks (synthetic data with sharing by design, ToolBench overlap-vs-disjoint contrast, τ-bench metadata splits) that are independent of any fitted parameters or self-referential definitions. No equations or steps reduce a claimed prediction to its own inputs by construction, no load-bearing self-citations justify uniqueness or ansatzes, and the retrieval isolation plus metadata heuristic follow directly from the controlled contrasts without renaming known results or smuggling assumptions. The derivation remains self-contained against these external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sharing of tool calls or entities is the primary structural property that determines whether overlap improves retrieval.
invented entities (1)
-
Overlapping Semantic Unit (OSU)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2310.05029. Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey,
-
[2]
Retrieval-Augmented Generation for Large Language Models: A Survey
URL https://arxiv.org/abs/2312.10997. Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. HiAgent: Hierarchical working memory management for solving long-horizon agent tasks with large language model. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of t...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long.1575. URLhttps://aclanthology.org/2025.acl-long.1575/. Minki Kang, Wei-Ning Chen, Dongge Han, Huseyin A. Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan. Acon: Optimizing context compression for long-horizon llm agents,
-
[4]
ACON: Optimizing Context Compression for Long-horizon LLM Agents
URL https://arxiv.org/abs/2510.00615. Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao. Simplemem: Efficient lifelong memory for llm agents,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
SimpleMem: Efficient Lifelong Memory for LLM Agents
URLhttps://arxiv.org/abs/2601.02553. Miao Lu, Weiwei Sun, Weihua Du, Zhan Ling, Xuesong Yao, Kang Liu, and Jiecao Chen. Scaling llm multi- turn rl with end-to-end summarization-based context management,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URLhttps://arxiv.org/abs/ 2510.06727. Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems,
-
[7]
URLhttps://arxiv.org/abs/2310.08560. Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, Vassilis Plachouras, Tim Rocktäschel, and Sebas- tian Riedel. KILT: a benchmark for knowledge intensive language tasks. In Kristina Toutanova, Anna Rumshisky, Luke ...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
doi: 10.18653/v1/2021.naacl-main.200
Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.200. URLhttps://aclanthology.org/2021.naacl-main.200/. Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, dahai li, Zhiyuan Liu, and Maosong Su...
-
[9]
cc/paper_files/paper/2024/file/28e50ee5b72e90b50e7196fde8ea260e-Paper-Conference.pdf
URLhttps://proceedings.iclr. cc/paper_files/paper/2024/file/28e50ee5b72e90b50e7196fde8ea260e-Paper-Conference.pdf. Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A temporal knowledge graph architecture for agent memory,
2024
-
[10]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
URLhttps://arxiv.org/abs/2501.13956. Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. RAPTOR: Recursive abstractive processing for tree-organized retrieval. InThe Twelfth International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar
URLhttps://proceedings.neurips.cc/paper_files/ paper/2023/file/1b44b878bb782e6954cd888628510e90-Paper-Conference.pdf. Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models,
2023
-
[12]
Voyager: An Open-Ended Embodied Agent with Large Language Models
URLhttps: //arxiv.org/abs/2305.16291. Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for LLM agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
A-MEM: Agentic Memory for LLM Agents
doi: 2502.12110. URLhttps://openreview.net/forum?id=FiM0M8gcct. Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z. Pan, Hinrich Schütze, Volker Tresp, and Yunpu Ma. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
URL https://arxiv.org/abs/2508.19828. Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.τ-bench: A bench- mark for Tool-Agent-User interaction in real-world domains. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, pages 9965–10017,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
URLhttps://proceedings.iclr.cc/paper_files/paper/2025/file/ 1b126cc38b8638e07bef37e7b2bb72bf-Paper-Conference.pdf. Rui Ye, Zhongwang Zhang, Kuan Li, Huifeng Yin, Zhengwei Tao, Yida Zhao, Liangcai Su, Liwen Zhang, Zile Qiao, Xinyu Wang, Pengjun Xie, Fei Huang, Jingren Zhou, Siheng Chen, and Yong Jiang. Agentfold: Long-horizon web agents with proactive cont...
2025
-
[16]
Agentfold: Long-horizon web agents with proactive context management
doi: 2510.24699. URLhttps://openreview.net/forum?id=IuZoTgsUws. Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. AAAI’24/IAAI’24/EAAI’24. AAAI Press,
-
[17]
doi: 10.1609/aaai.v38i17.29936
ISBN 978-1-57735-887-9. doi: 10.1609/aaai.v38i17.29936. URLhttps://doi.org/10.1609/aaai.v38i17.29936. 21 A Extended Method Details Hyperparameter defaults.Table 8 lists all OSU-Mem hyperparameters, their default values, and the rationale for each choice. All values are fixed across the three benchmarks (synthetic,τ-bench, ToolBench); none was tuned per-be...
-
[18]
OSU-Mem (no novelty)
λnov (novelty scale) .3Scales the blended novelty contribution in the cost-normalized OSU scoring formula. Part of the default method, active only whenB≥Bnov. Low-sensitivity parameter. Bnov (novelty budget gate) 192Budget threshold below which novelty scoring is disabled. At small budgets the candidate pool is too small for novelty to provide useful sign...
2024
-
[19]
B.3 Efficiency and Footprint (64-d Regime) AtB=256, OSU-Mem runs at8.3ms amortized per query (=retrieve plus amortized build cost) with 209KB total storage including the OSU index. Tree Abstraction runs at57.4ms with363KB, so OSU-Mem is Pareto-dominant over Tree Abstraction on this benchmark. Flat Vector is faster (.9ms) but without structured selection. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.