Load Testing for Machine Learning Model Serving Systems at Scale
Pith reviewed 2026-06-26 11:52 UTC · model grok-4.3
The pith
Workload calibration with recorded traffic cuts ML serving capacity error from 30% to 2-6%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
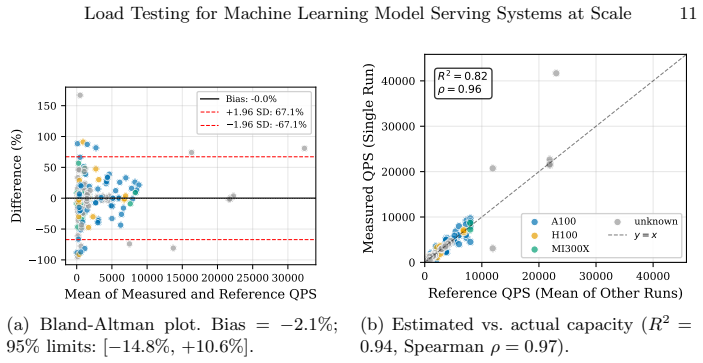
Sys estimates serving capacity for ML models through an adaptive feedback-driven search that identifies maximum sustainable throughput under SLO constraints. Longitudinal analysis of 14 case studies demonstrates that workload calibration using recorded traffic reduces estimation error from approximately 30% to 2-6%, proper warmup handling improves accuracy by 22.2%, and systematic testing substantially reduces under-provisioning incidents and improves GPU resource efficiency and operational reliability.
What carries the argument
Sys, the adaptive feedback-driven load testing framework that uses real-time performance signals with dampening, spike tolerance, and convergence detection to locate maximum sustainable throughput.
If this is right
- Under-provisioned model launches and resulting production incidents decrease substantially after framework adoption.
- GPU resource efficiency rises because capacity estimates become accurate enough to avoid both under- and over-provisioning.
- Operational reliability improves through fewer SLO violations during model serving.
- ML-specific choices such as recorded-traffic calibration and warmup handling become necessary for low-error capacity estimates.
- Six distilled lessons and architectural guidelines can be applied to design future ML load-testing systems.
Where Pith is reading between the lines
- The same calibration and search techniques could be tested on non-ML serving workloads that also run on GPUs.
- Periodic re-calibration after model updates might be required to maintain the reported error reductions over time.
- Integration of the framework output with automated scaling policies could further reduce manual capacity decisions.
- Co-location effects noted in the analysis suggest that testing isolated versus shared-GPU configurations would be informative.
Load-bearing premise
The before-and-after comparison across the 14 case studies isolates the effect of adopting the framework from other simultaneous changes in the production environment or model launches.
What would settle it
A controlled side-by-side deployment of identical models in matched environments, one using Sys and one using prior ad-hoc methods, showing no reduction in under-provisioning incidents or SLO violations.
Figures


read the original abstract
Machine learning (ML) model serving has become a dominant consumer of GPU infrastructure, yet capacity planning in these systems remains largely ad hoc. Under-provisioning leads to service-level objective (SLO) violations and production incidents, while over-provisioning results in substantial resource waste. This paper presents \sys, an industrial load testing framework for ML serving systems that systematically estimates serving capacity through an adaptive, feedback-driven search strategy. The approach leverages real-time performance signals, incorporating dampening, spike tolerance, and convergence detection to efficiently identify maximum sustainable throughput under SLO constraints. We evaluate \sys through a longitudinal analysis of 14 industrial case studies spanning four ML architecture classes: recommendation, ranking, vision, and NLP. This study demonstrates that systematic load testing leads to substantial improvements in GPU resource efficiency and operational reliability. Prior to adopting \sys, a significant fraction of model launches were under-provisioned, resulting in recurring incidents; these issues were substantially reduced after deployment. Our results show that ML-specific design decisions are critical to accurate capacity estimation: workload calibration using recorded traffic reduces estimation error from approximately 30\% to 2--6\%, while proper warmup handling yields a 22.2\% improvement in accuracy. Further analysis reveals key factors influencing prediction error, including model size and co-location effects. This paper distills six lessons and derive architectural guidelines for ML load testing, offering actionable insights for building reliable and efficient ML serving systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sys, an industrial load testing framework for ML model serving that employs an adaptive feedback-driven search incorporating dampening, spike tolerance, and convergence detection to estimate maximum sustainable throughput under SLO constraints. It reports a longitudinal before/after evaluation across 14 case studies spanning recommendation, ranking, vision, and NLP models, claiming that traffic-based workload calibration reduces estimation error from ~30% to 2-6%, warmup handling yields a 22.2% accuracy improvement, and adoption substantially reduces under-provisioning incidents while improving GPU efficiency and reliability. The work distills six lessons and architectural guidelines.
Significance. If the causal claims hold after addressing confounding, the paper offers practical, ML-specific guidance on load testing that could help reduce resource waste and incidents in production serving systems. The focus on real industrial deployments and factors like model size and co-location is a strength for applied ML systems research.
major comments (2)
- [evaluation of 14 case studies] The longitudinal before/after analysis across the 14 case studies (described in the evaluation) cannot isolate the effect of Sys adoption from concurrent changes in model launches, traffic patterns, co-location policies, or operational practices. This design choice directly undermines the central claim of substantial improvements in GPU resource efficiency and operational reliability attributable to the framework.
- [abstract and evaluation] The abstract and evaluation report specific quantitative outcomes (30% to 2-6% error reduction; 22.2% accuracy improvement from warmup) without providing methodology details, raw data, statistical tests, sample sizes per case study, or error bars. This prevents independent verification of the results and is load-bearing for the empirical claims.
minor comments (2)
- [framework description] The term 'Sys' and its core components (dampening, spike tolerance, convergence detection) should be defined with pseudocode or a high-level algorithm box in the framework description section for clarity.
- [tables and figures] Figure captions and tables summarizing the 14 case studies should include explicit before/after metrics and any available confidence intervals to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, acknowledging limitations where appropriate and outlining specific revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [evaluation of 14 case studies] The longitudinal before/after analysis across the 14 case studies (described in the evaluation) cannot isolate the effect of Sys adoption from concurrent changes in model launches, traffic patterns, co-location policies, or operational practices. This design choice directly undermines the central claim of substantial improvements in GPU resource efficiency and operational reliability attributable to the framework.
Authors: We agree that a longitudinal before/after design in production cannot fully isolate Sys effects from concurrent changes, as randomized controls are often infeasible at scale. The manuscript presents the results as observational evidence of correlation with reduced incidents rather than strict causality. In revision we will add an explicit limitations subsection discussing potential confounders (e.g., traffic stability, co-location policy changes) and provide additional context on the timeline of other operational variables. We will also moderate language around attribution while retaining the practical value of the before/after observations. revision: yes
-
Referee: [abstract and evaluation] The abstract and evaluation report specific quantitative outcomes (30% to 2-6% error reduction; 22.2% accuracy improvement from warmup) without providing methodology details, raw data, statistical tests, sample sizes per case study, or error bars. This prevents independent verification of the results and is load-bearing for the empirical claims.
Authors: We accept that the current version lacks sufficient methodological transparency. The revised manuscript will expand the evaluation section with: (1) precise definitions and formulas for estimation error and accuracy improvement, (2) per-case-study sample sizes and number of load-test runs, (3) description of statistical procedures (including any tests or aggregation methods), and (4) error bars or interval estimates. Due to the proprietary nature of production traffic and model configurations, raw traces cannot be released; we will instead supply anonymized summary statistics and a detailed methodology appendix. These additions will enable verification while respecting confidentiality constraints. revision: yes
Circularity Check
No circularity: empirical case studies with no derivations or fitted predictions
full rationale
The paper contains no equations, parameters, or derivations. Its central claims rest on longitudinal before/after observations across 14 deployments and measured error reductions from workload calibration and warmup handling. These are presented as direct empirical outcomes rather than quantities derived from or fitted to the same inputs. No self-citation chains, ansatzes, or renamings of known results appear in the load-bearing steps. The before/after design may be vulnerable to confounding, but that is an issue of causal identification, not circularity by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-time performance signals from ML serving systems can be used to drive an adaptive search for maximum sustainable throughput under SLO constraints.
Reference graph
Works this paper leans on
-
[1]
Apache JMeter.https://jmeter.apache.org/(2024)
2024
-
[2]
k6: Modern load testing for developers and testers.https://k6.io/(2024)
2024
-
[3]
Locust: An open source load testing tool.https://locust.io/(2024)
2024
-
[4]
arXiv preprint arXiv:2403.02310 (2024)
Agrawal, A., Kedia, N., Panwar, A., Mohan, J., Kwatra, N., Gulavani, B.S., Ram- jee, R., Tumanov, A.: Sarathi-serve: Efficient llm serving with chunked prefills. arXiv preprint arXiv:2403.02310 (2024)
-
[5]
In: Proceedings of the 41st International Conference on Software Engineer- ing: Software Engineering in Practice (ICSE-SEIP)
Amershi, S., Begel, A., Bird, C., DeLine, R., Gall, H., Kamar, E., Nagappan, N., Nushi, B., Zimmermann, T.: Software engineering for machine learning: A case study. In: Proceedings of the 41st International Conference on Software Engineer- ing: Software Engineering in Practice (ICSE-SEIP). pp. 291–300 (2019)
2019
-
[6]
Empirical Software Engineering25(6), 5193–5254 (2020)
Braiek, H.B., Khomh, F.: Testing machine learning based systems: A systematic mapping. Empirical Software Engineering25(6), 5193–5254 (2020)
2020
-
[7]
In: Proceedings of the 11th ACM Symposium on Cloud Computing (SoCC)
Crankshaw, D., Sela, G.E., Mo, X., Zuber, C., Stoica, I., Gonzalez, J.E., Tu- manov, A.: InferLine: Latency-aware provisioning and scaling for prediction serv- ing pipelines. In: Proceedings of the 11th ACM Symposium on Cloud Computing (SoCC). pp. 477–491 (2020)
2020
-
[8]
In: Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI)
Crankshaw, D., Wang, X., Zhou, G., Franklin, M.J., Gonzalez, J.E., Stoica, I.: Clipper: A low-latency online prediction serving system. In: Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI). pp. 613–627 (2017)
2017
-
[9]
In: Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI)
Eisenman, A., Cidon, A., Pergament, E., et al.: Check before you change: Pre- venting correlated failures in service updates. In: Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI). pp. 575– 589 (2022)
2022
-
[10]
Addison-Wesley (1994)
Gamma, E., Helm, R., Johnson, R., Vlissides, J.: Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley (1994)
1994
-
[11]
ACM Transactions on Computer Systems30(4), 1–26 (2012)
Gandhi, A., Dube, P., Karve, A., Kochut, A., Zhang, L.: AutoScale: Dynamic, robust capacity management for multi-tier data centers. ACM Transactions on Computer Systems30(4), 1–26 (2012)
2012
-
[12]
Biochemia Medica25(2), 141–151 (2015)
Giavarina, D.: Understanding Bland Altman analysis. Biochemia Medica25(2), 141–151 (2015)
2015
-
[13]
In: Proceed- ings of the 14th USENIX Symposium on Operating Systems Design and Imple- mentation (OSDI)
Gujarati, A., Karber, R., Panigrahy, S., Kozyrakis, C., Olston, C., et al.: Serving DNNs like clockwork: Performance predictability from the bottom up. In: Proceed- ings of the 14th USENIX Symposium on Operating Systems Design and Imple- mentation (OSDI). pp. 443–462 (2020)
2020
-
[14]
In: Proceedings of the 26th IEEE International Symposium on High-Performance Computer Architecture (HPCA)
Gupta, U., Wu, C.J., Wang, X., Naumov, M., et al.: The architectural implications of Facebook’s DNN-based personalized recommendation. In: Proceedings of the 26th IEEE International Symposium on High-Performance Computer Architecture (HPCA). pp. 488–501 (2020)
2020
-
[15]
In: Proceedings of the 24th IEEE International Sympo- sium on High-Performance Computer Architecture (HPCA)
Hazelwood, K., Bird, S., Brooks, D., Chintala, S., Diril, U., Dzhulgakov, D., Fawzy, M., Jia, B., Jia, Y., Kalro, A., Law, J., Lee, K., Lu, J., Noordhuis, P., Smelyanskiy, M., Xiong, L., Wang, X.: Applied machine learning at Facebook: A datacenter infrastructure perspective. In: Proceedings of the 24th IEEE International Sympo- sium on High-Performance Co...
2018
-
[16]
IEEE Transactions on Software Engineering41(11), 1091–1118 (2015)
Jiang, Z.M., Hassan, A.E.: A survey on load testing of large-scale software systems. IEEE Transactions on Software Engineering41(11), 1091–1118 (2015)
2015
-
[17]
Abdelfattah et al
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C.H., Gonzalez, J.E., Zhang, H., Stoica, I.: Efficient memory management for large language model 16 Amr S. Abdelfattah et al. serving with PagedAttention. In: Proceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP). pp. 611–626 (2023)
2023
-
[18]
arXiv preprint arXiv:2404.06512 (2024)
Li, Y., Du, G., Luo, J., et al.: InferBench: An inference benchmark for multi-modal large language models. arXiv preprint arXiv:2404.06512 (2024)
-
[19]
In: Proceedings of the 17th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
Li, Z., Zhuang, L., Huang, S., Zheng, L., Gonzalez, J.E., Stoica, I., et al.: Al- paServe: Statistical multiplexing with model parallelism for deep learning serving. In: Proceedings of the 17th USENIX Symposium on Operating Systems Design and Implementation (OSDI). pp. 663–681 (2023)
2023
-
[20]
In: Proceedings of the 51st Annual International Symposium on Computer Architecture (ISCA)
Patel, P., Choukse, E., Zhang, C., Shah, A., Goiri, ´I., Maleki, S., Bianchini, R.: Splitwise: Efficient generative LLM inference using phase splitting. In: Proceedings of the 51st Annual International Symposium on Computer Architecture (ISCA). pp. 118–132 (2024)
2024
-
[21]
In: Proceedings of the 3rd Conference on Machine Learning and Systems (MLSys)
Reddi, V.J., Cheng, C., Kanter, D., Mattson, P., Schmuelling, G., Wu, C.J., et al.: MLPerf inference benchmark. In: Proceedings of the 3rd Conference on Machine Learning and Systems (MLSys). pp. 446–461 (2020)
2020
-
[22]
In: Proceedings of the 2021 USENIX Annual Technical Confer- ence (ATC)
Romero, F., Li, Q., Yadwadkar, N.J., Kozyrakis, C.: INFaaS: Automated model-less inference serving. In: Proceedings of the 2021 USENIX Annual Technical Confer- ence (ATC). pp. 397–411 (2021)
2021
-
[23]
In: Advances in Neural Information Processing Systems (NeurIPS)
Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V., Young, M., Crespo, J.F., Dennison, D.: Hidden technical debt in machine learn- ing systems. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 2503–2511 (2015)
2015
-
[24]
In: International Workshop on Languages and Compilers for Parallel Computing
Stratton, J.A., Stone, S.S., Hwu, W.M.W.: Mcuda: An efficient implementation of cuda kernels for multi-core cpus. In: International Workshop on Languages and Compilers for Parallel Computing. pp. 16–30. Springer (2008)
2008
-
[25]
Keynote at Strange Loop (2015)
Tene, G.: How NOT to measure latency. Keynote at Strange Loop (2015)
2015
-
[26]
In: Proceedings of the ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems
Urgaonkar, B., Pacifici, G., Shenoy, P., Spreitzer, M., Tantawi, A.: An analytical model for multi-tier internet services and its applications. In: Proceedings of the ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems. pp. 291–302 (2005)
2005
-
[27]
In: Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI)
Weng, Q., Xiao, W., Yu, Y., Wang, W., Wang, C., He, J., Li, Y., Zhang, L., Lin, W., Ding, Y.: MLaaS in the wild: Workload analysis and scheduling in large-scale heterogeneous GPU clusters. In: Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI). pp. 945–960 (2022)
2022
-
[28]
In: Proceedings of the 2021 USENIX Annual Technical Conference (ATC)
Yu, G.X., Gao, Y., Golber, P., Kasikci, B.: Habitat: A runtime-based computational performance predictor for deep neural network training. In: Proceedings of the 2021 USENIX Annual Technical Conference (ATC). pp. 503–517 (2021)
2021
-
[29]
In: Proceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
Yu, G.I., Jeong, J.S., Kim, G.W., Kim, S., Chun, B.G.: Orca: A distributed serv- ing system for transformer-based generative models. In: Proceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI). pp. 521–538 (2022)
2022
-
[30]
IEEE Transactions on Software Engineering48(2), 1– 36 (2022)
Zhang, J.M., Harman, M., Ma, L., Liu, Y.: Machine learning testing: Survey, landscapes and horizons. IEEE Transactions on Software Engineering48(2), 1– 36 (2022)
2022
-
[31]
In: Proceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
Zhong, Y., Liu, S., Chen, J., Hu, J., Zhu, Y., Liu, X., Jin, X., Zhang, H.: DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving. In: Proceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI). pp. 193–210 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.