Drowning in Routine: Signal Dilution in Multi-Turn Agent Training
Pith reviewed 2026-06-26 12:15 UTC · model grok-4.3
The pith
Routine turns dilute training signals in multi-turn agents, with signal-to-noise ratio scaling as the inverse square root of decision density.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
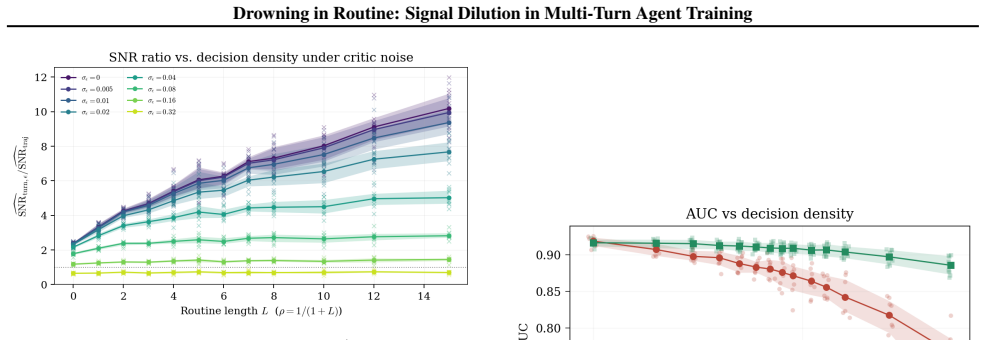
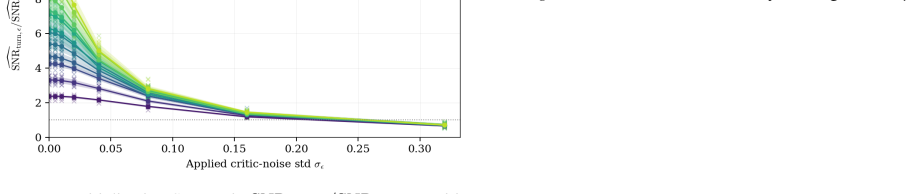
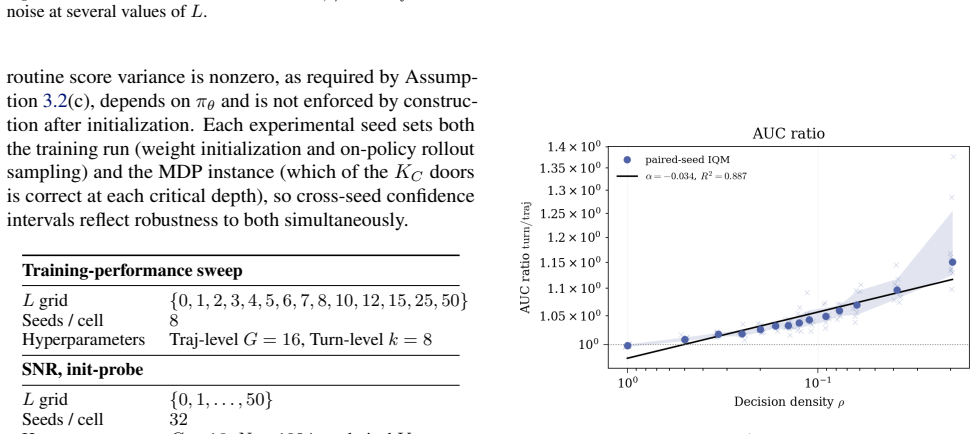
Multi-turn agents interleave consequential decisions with routine execution where some actions change the downstream return distribution while others are necessary but reward-equivalent. The cost of trajectory-level credit assignment is governed by decision density rho, the fraction of turns whose actions affect the return. When decision density is low, routine turns create signal dilution by adding gradient variance to trajectory-level estimators such as GRPO without adding expected signal. Under explicit assumptions, the resulting turn-level to trajectory-level signal-to-noise ratio scales as rho to the power of negative one-half, provided critic error remains controlled. The same analysis
What carries the argument
Decision density rho, the fraction of turns whose actions affect the return distribution, which determines the degree of signal dilution in trajectory-level estimators.
If this is right
- At low decision density, trajectory-level methods suffer from signal dilution due to added variance from routine turns.
- At high decision density, trajectory-level methods can remain competitive without requiring a value critic.
- The signal-to-noise ratio between turn-level and trajectory-level estimators scales as rho to the power of negative one-half when critic error is controlled.
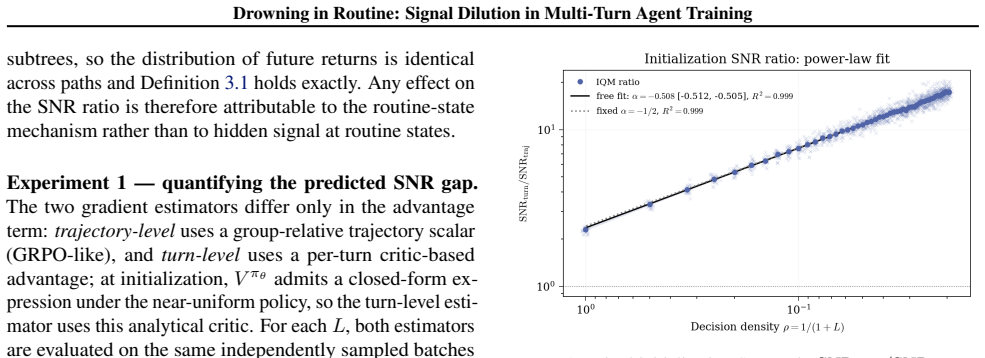
- In environments where decision density is tunable, the predicted scaling relation is observed with R squared equal to 0.999.
Where Pith is reading between the lines
- Environments or agent designs that increase the fraction of impactful turns could reduce reliance on separate critics during training.
- The dilution analysis may extend to other sequential tasks with sparse impactful actions, such as long-horizon planning with many maintenance steps.
- Hybrid estimators could monitor estimated decision density to decide dynamically between trajectory-level and turn-level updates.
Load-bearing premise
Routine turns are reward-equivalent and critic error remains controlled throughout the derivation.
What would settle it
An experiment that varies decision density in a new environment and measures the turn-to-trajectory signal-to-noise ratio, finding that it fails to follow the inverse square root scaling.
Figures
read the original abstract
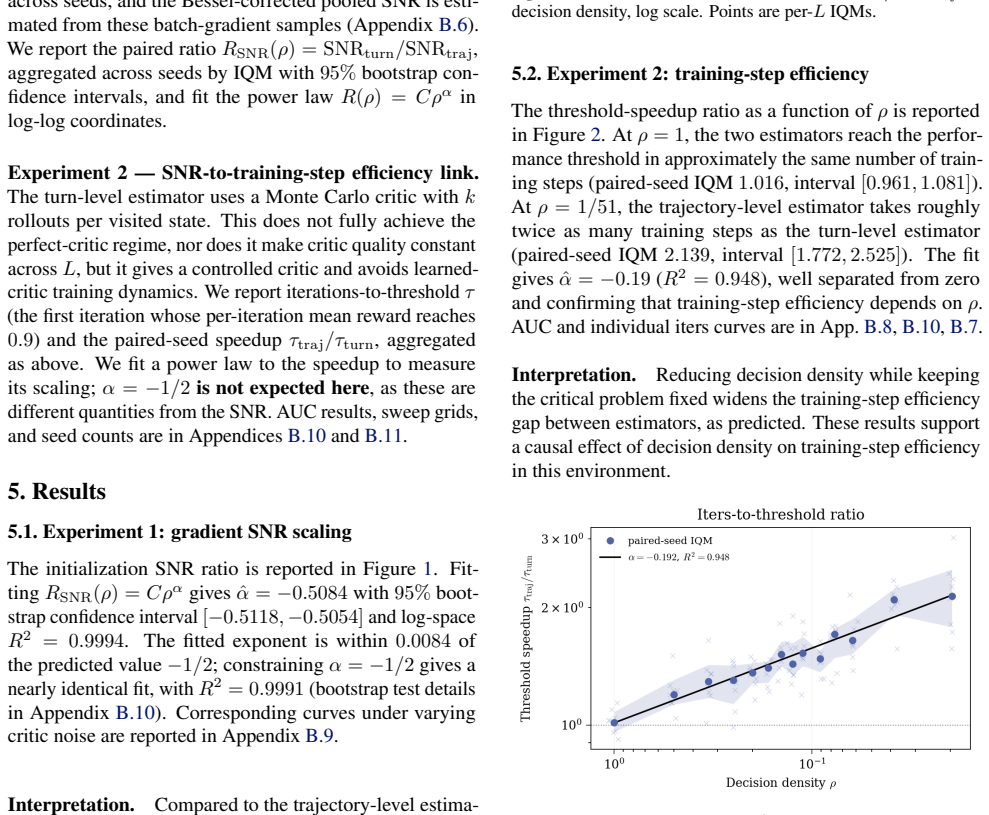
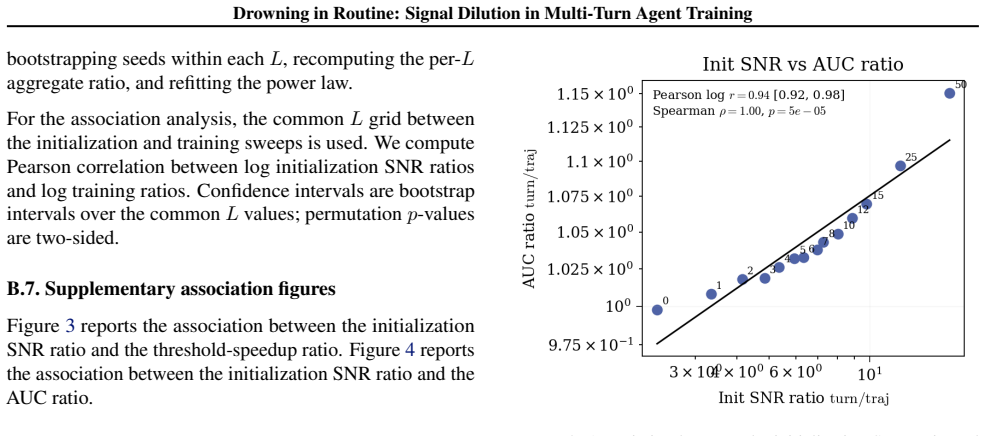
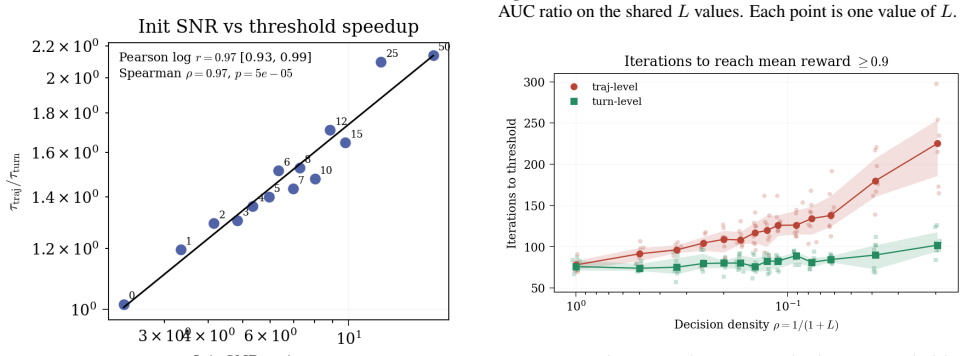
Multi-turn agents interleave consequential decisions with routine execution: some actions change the downstream return distribution, while others are necessary but reward-equivalent. The cost of trajectory-level credit assignment, often attributed to long horizons, is in fact governed by decision density $\rho$: the fraction of turns whose actions affect the return. When decision density is low, routine turns create signal dilution: they add gradient variance to trajectory-level estimators such as GRPO without adding expected signal. Under explicit assumptions, the resulting turn-level to trajectory-level signal-to-noise ratio scales as $\rho^{-1/2}$, provided critic error remains controlled. The same analysis identifies the complementary regime: at high decision density, trajectory-level methods can remain competitive while avoiding the cost of a critic. In a controlled environment where $\rho$ is exactly tunable, the predicted scaling is recovered with $R^2 = 0.999$, and the training-step gap widens significantly as $\rho \to 0$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that in multi-turn agents, the cost of trajectory-level credit assignment is governed by decision density ρ (fraction of turns whose actions affect the return distribution), rather than horizon length alone. Routine turns that are reward-equivalent create signal dilution in estimators such as GRPO by adding gradient variance without expected signal. Under explicit assumptions on the environment, reward-equivalent routine turns, and controlled critic error, the turn-level to trajectory-level signal-to-noise ratio scales as ρ^{-1/2}. The analysis also identifies the complementary high-ρ regime where trajectory-level methods remain competitive. In a controlled environment with exactly tunable ρ, the predicted scaling is recovered with R² = 0.999, and the training-step gap widens as ρ → 0.
Significance. If the central scaling holds, the work supplies a precise, parameter-free characterization of signal dilution in multi-turn RL and clarifies when trajectory-level methods suffice versus when a critic is required. The explicit-assumption derivation combined with near-perfect empirical recovery (R² = 0.999) in a tunable-ρ setting constitutes a falsifiable prediction that could guide algorithm design; the absence of free parameters and the independent empirical grounding are particular strengths.
major comments (2)
- [Abstract] The central derivation of the ρ^{-1/2} scaling is presented as holding under explicit assumptions on reward-equivalent routine turns and controlled critic error, yet the abstract (and the provided material) does not supply the full derivation, the precise statement of those assumptions, or the intermediate steps; without these, the claim cannot be independently verified even though the empirical recovery is reported.
- The experimental section is described only at the level of 'a controlled environment where ρ is exactly tunable' with R² = 0.999; the manuscript must include the precise definition of the tunable environment, the implementation of ρ, the number of runs, and the exact estimator (GRPO or otherwise) used, as these details are load-bearing for assessing whether the empirical result independently confirms the scaling rather than being an artifact of the construction.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] The central derivation of the ρ^{-1/2} scaling is presented as holding under explicit assumptions on reward-equivalent routine turns and controlled critic error, yet the abstract (and the provided material) does not supply the full derivation, the precise statement of those assumptions, or the intermediate steps; without these, the claim cannot be independently verified even though the empirical recovery is reported.
Authors: The full derivation with explicit assumptions and intermediate steps appears in Section 3. To improve verifiability from the abstract, we will revise the abstract to state the key assumptions concisely and reference Section 3 for the complete derivation. revision: yes
-
Referee: [—] The experimental section is described only at the level of 'a controlled environment where ρ is exactly tunable' with R² = 0.999; the manuscript must include the precise definition of the tunable environment, the implementation of ρ, the number of runs, and the exact estimator (GRPO or otherwise) used, as these details are load-bearing for assessing whether the empirical result independently confirms the scaling rather than being an artifact of the construction.
Authors: We agree these details are required for independent assessment. The revised manuscript will expand the experimental section with the precise definition of the tunable environment, the implementation of ρ, the number of runs, and confirmation that GRPO was the estimator employed. revision: yes
Circularity Check
No significant circularity; derivation self-contained with independent empirical grounding
full rationale
The paper states the ρ^{-1/2} SNR scaling under explicit assumptions on reward-equivalent routine turns and controlled critic error. It then reports empirical recovery of the exact scaling (R²=0.999) in a controlled environment where ρ is stated to be exactly tunable. This constitutes independent validation rather than a fitted input renamed as prediction or a self-definitional reduction. No self-citation chains, uniqueness theorems, or ansatzes smuggled via prior work are referenced in the provided material as load-bearing. The central claim retains independent content from the derivation-plus-validation structure.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Routine turns are necessary but reward-equivalent and do not affect the return distribution
- domain assumption Critic error remains controlled
invented entities (1)
-
decision density ρ
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S., Courville, A
Agarwal, R., Schwarzer, M., Castro, P. S., Courville, A. C., and Bellemare, M. G. Deep reinforcement learning at the edge of the statistical precipice. Advances in Neural Information Processing Systems, 34, 2021
2021
-
[2]
Back to basics: Revisiting REINFORCE -style optimization for learning from human feedback in LLM s
Ahmadian, A., Cremer, C., Gall \'e , M., Fadaee, M., Kreutzer, J., Pietquin, O., \"U st \"u n, A., and Hooker, S. Back to basics: Revisiting REINFORCE -style optimization for learning from human feedback in LLM s. ACL, 2024
2024
-
[3]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Cui, G., Zhang, Y., Chen, J., et al. The entropy mechanism of reinforcement learning for reasoning language models. arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
and Tibshirani, R
Efron, B. and Tibshirani, R. J. An Introduction to the Bootstrap. Chapman and Hall, 1993
1993
-
[5]
Group-in-Group Policy Optimization for LLM Agent Training
Feng, L., et al. Group-in-Group Policy Optimization for LLM Agent Training. arXiv preprint arXiv:2505.10978, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
L., and Baxter, J
Greensmith, E., Bartlett, P. L., and Baxter, J. Variance reduction techniques for gradient estimates in reinforcement learning. Journal of Machine Learning Research, 5:1471--1530, 2004
2004
-
[7]
V., Jeon, M., Vu, K., Lai, V., and Yang, E
Le, T.-L. V., Jeon, M., Vu, K., Lai, V., and Yang, E. No prompt left behind: Exploiting zero-variance prompts in LLM reinforcement learning via entropy-guided advantage shaping. ICLR, 2026
2026
-
[8]
P., Li, L., and Li, Y
Li, J., Zhou, P., Meng, R., Vadera, M. P., Li, L., and Li, Y. Turn- PPO : Turn-level advantage estimation with PPO for improved multi-turn RL in agentic LLM s. Findings of the Association for Computational Linguistics: EACL 2026, pp. 6227--6243, 2026
2026
-
[9]
Understanding why neural networks generalize well through GSNR of parameters
Liu, J., Bai, Y., Jiang, G., Chen, T., and Wang, H. Understanding why neural networks generalize well through GSNR of parameters. ICLR, 2020
2020
-
[10]
and Hutter, F
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. ICLR, 2019
2019
-
[11]
Steps toward artificial intelligence
Minsky, M. Steps toward artificial intelligence. Proceedings of the IRE, 49(1):8--30, 1961
1961
-
[12]
Training language models to follow instructions with human feedback
Ouyang, L., Wu, J., Jiang, X., et al. Training language models to follow instructions with human feedback. NeurIPS, 2022
2022
-
[13]
On the difficulty of training recurrent neural networks
Pascanu, R., Mikolov, T., and Bengio, Y. On the difficulty of training recurrent neural networks. ICML, 2013
2013
-
[14]
D., and Finn, C
Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., and Finn, C. Direct preference optimization: Your language model is secretly a reward model. NeurIPS, 2023
2023
-
[15]
and Tedrake, R
Roberts, J. and Tedrake, R. Signal-to-noise ratio analysis of policy gradient algorithms. Advances in Neural Information Processing Systems, 21, 2008
2008
-
[16]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
Schulman, J., Moritz, P., Levine, S., Jordan, M., and Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
F., Lee, S., and Har, D
Seo, M., Vecchietti, L. F., Lee, S., and Har, D. Rewards prediction-based credit assignment for reinforcement learning with sparse binary rewards. IEEE Access, 7:118776--118791, 2019
2019
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
S., McAllester, D
Sutton, R. S., McAllester, D. A., Singh, S. P., and Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Advances in Neural Information Processing Systems, 12:1057--1063, 2000
2000
-
[21]
Sutton, R. S. and Barto, A. G. Reinforcement Learning: An Introduction. MIT Press, second edition, 2018
2018
-
[22]
Attention is all you need
Vaswani, A., Shazeer, N., Parmar, N., et al. Attention is all you need. Advances in Neural Information Processing Systems, 30, 2017
2017
-
[23]
Wei, Q., Zeng, S., Li, C., et al. Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Reward Design. arXiv preprint arXiv:2505.11821, 2025
-
[24]
Williams, R. J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8:229--256, 1992
1992
-
[25]
E., Wettig, A., Lieret, K., Yao, S., Narasimhan, K., and Press, O
Yang, J., Jimenez, C. E., Wettig, A., Lieret, K., Yao, S., Narasimhan, K., and Press, O. SWE -agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Processing Systems, 37, 2024
2024
-
[26]
F., Zhu, H., et al
Zhou, S., Xu, F. F., Zhu, H., et al. WebArena : A realistic web environment for building autonomous agents. ICLR, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.