REVIEW 2 cited by
Current AI coding agents complete at most 39 percent of long-horizon version upgrade tasks drawn from real projects.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-20 16:53 UTC pith:SPIPKLBH
RoadmapBench: Evaluating Long-Horizon Agentic Software Development Across Version Upgrades
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
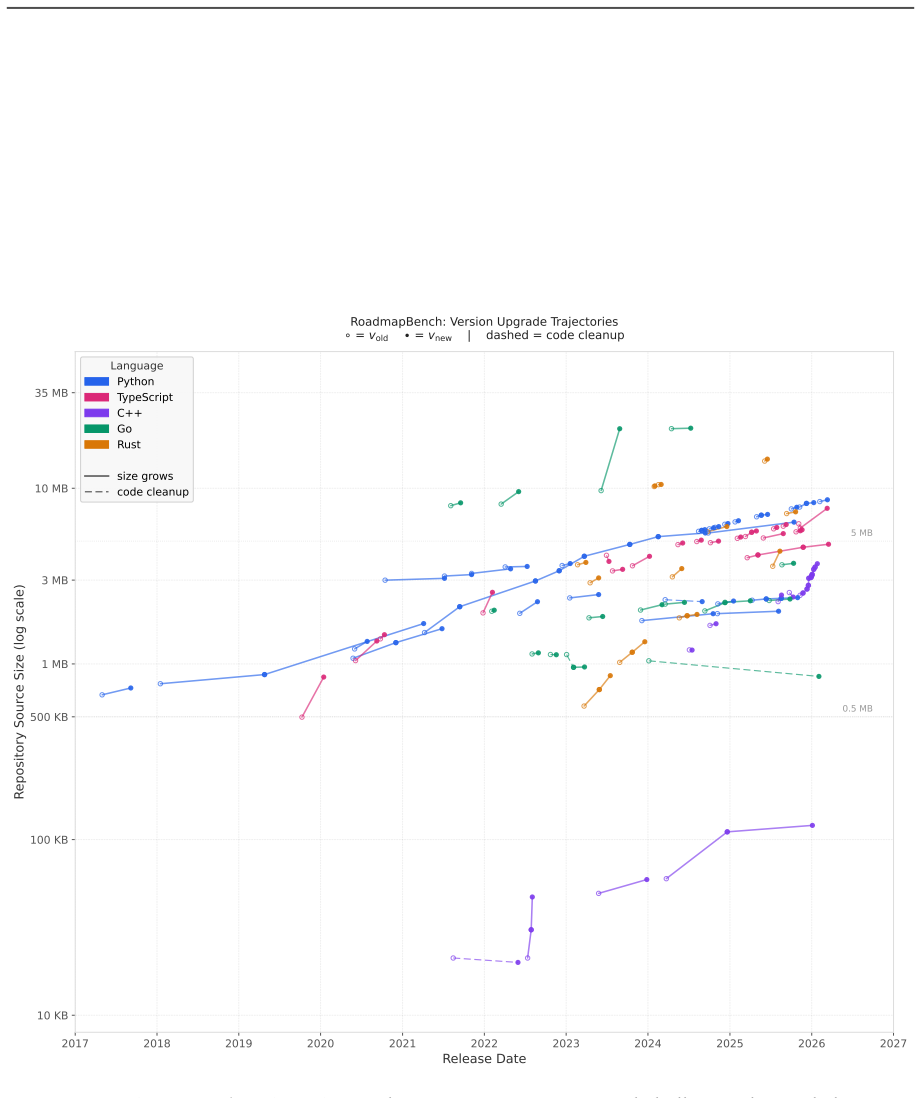
RoadmapBench consists of 115 tasks grounded in real open-source version upgrades; each supplies a source-version code snapshot plus a multi-target roadmap instruction, and requires the agent to produce the functionality present in the target version, with a median of 3,700 lines modified across 51 files. Systematic evaluation of thirteen frontier models shows top success at 39.1 percent and bottom success at 5.2 percent, in clear contrast to performance on existing bug-fix benchmarks.
What carries the argument
RoadmapBench benchmark, a set of 115 tasks each anchored in a real source-version snapshot paired with a multi-target roadmap that specifies the changes introduced in the target version.
Load-bearing premise
The multi-target roadmap instructions supplied with each source snapshot fully specify every code change required for the target version without needing extra unstated context or human clarification.
What would settle it
A future model that reaches success rates above 70 percent on the identical RoadmapBench tasks under the same evaluation rules would directly challenge the claim that long-horizon development remains unsolved.
If this is right
- Existing single-issue bug-fix benchmarks substantially overestimate agent readiness for realistic engineering work.
- Agents must improve coordinated planning across many files and multiple languages to approach professional-level upgrades.
- Success rates vary widely across models, pointing to specific gaps in long-term reasoning rather than uniform limitations.
- Version-upgrade tasks expose the need for evaluation metrics that track partial progress over extended sequences of edits.
Where Pith is reading between the lines
- Training pipelines may need to incorporate full project histories rather than isolated patches to close the observed gap.
- Near-term deployments will likely require human oversight loops for any substantial version migration work.
- Similar roadmap-style benchmarks could be constructed for domains such as database migrations or infrastructure changes to test generality.
- If roadmap clarity proves insufficient, the benchmark results may partly reflect instruction ambiguity rather than pure model capability.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity in empirical benchmark results
full rationale
The paper constructs RoadmapBench from real open-source version upgrades across 17 repositories, supplies multi-target roadmap instructions with source snapshots, and reports success rates from direct execution of 13 external frontier models. The headline percentages (39.1% max, 5.2% min) are measured outcomes on these external tasks rather than quantities fitted to or defined by the benchmark itself. No equations, parameter fits, self-citation chains, or uniqueness theorems appear in the provided text that would reduce the central claim to a tautology or input by construction. The evaluation remains self-contained against external model runs and real repository diffs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Roadmap instructions derived from target versions accurately and completely specify the functionality that must be implemented.
read the original abstract
Coding agents are increasingly deployed in real software development, where a single version iteration requires months of coordinated work across many files. However, most existing benchmarks focus predominantly on single-issue bug fixes from Python repositories, with coarse pass/fail evaluation outcomes, and thus fail to capture long-horizon, multi-target development at real engineering scale. To address this gap, we present RoadmapBench, a benchmark of 115 long-horizon coding tasks grounded in real open-source version upgrades across 17 repositories and 5 programming languages. Each task places the agent on a source-version code snapshot and provides a multi-target roadmap instruction requiring it to implement the functionality introduced in the target version, with a median modification of 3,700 lines across 51 files. We conduct a systematic evaluation on thirteen frontier models and find that even the strongest, Claude-Opus-4.7, resolves only 39.1% of tasks, while the weakest achieves merely 5.2%, in stark contrast to existing bug-fix benchmarks, suggesting that long-horizon software development remains a largely unsolved problem.
Figures














Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Each task places the agent on a source-version code snapshot and provides a multi-target roadmap instruction requiring it to implement the functionality introduced in the target version, with a median modification of 3,700 lines across 51 files.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the per-task weighted reward as st = ∑ wt,k · rt,k / ∑ wt,k
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
EdgeBench: Unveiling Scaling Laws of Learning from Real-World Environments
Across ~38,000 hours on 134 ultra-long real-world tasks, aggregate agent performance follows a log-sigmoid of interaction time, and measured learning speed doubles about every three months.
-
CausalDS: Benchmarking Causal Reasoning in Data-Science Agents
CausalDS generates SCM-grounded scenes with free-form stories and noisy observations to jointly score causal reasoning, coding, uncertainty, and abstention in data-science agents.
Reference graph
Works this paper leans on
-
[1]
Create public subpackage optuna/storages/journal/ containing: __init__.py, _base.py, _file.py, _redis.py,_storage.py
-
[2]
Class renames (importable from optuna.storages.journal): BaseJournalBackend (was BaseJournalLogStorage), BaseJournalSnapshot (was BaseJournalLogSnapshot), JournalFileBackend (was JournalFileStorage), JournalRedisBackend (was JournalRedisStorage), JournalFileSymlinkLock, JournalFileOpenLock,JournalStorage(unchanged)
-
[3]
BaseJournalLogStorage should subclassBaseJournalBackenddecorated with@deprecated_class
Old names remain importable fromoptuna.storages with deprecation warnings. BaseJournalLogStorage should subclassBaseJournalBackenddecorated with@deprecated_class. 4.optuna.storages.journal.__all__ must include: JournalFileBackend, BaseJournalBackend, JournalFileOpenLock,JournalFileSymlinkLock,JournalRedisBackend,JournalStorage. 19 Target 3: Constrained Op...
-
[4]
Helper module optuna/study/_constrained_optimization.py: define constant _CONSTRAINTS_KEY = "constraints". Implement _get_feasible_trials(trials) returning only trials where all constraint values are≤0.0. Trials without a"constraints"key are considered infeasible. 2.best_trial property: if the best trial is infeasible, filter to feasible trials and select...
work page 2025
-
[5]
Specification clarity(Q1–Q3): each target’s goal and constraints are explicitly stated; the instruction is self-contained without referencing the construction process; requirements are defined positively rather than by exclusion
-
[6]
Implementation leakage(Q4): a systematic scan for five leakage types—algorithm/flow steps, internal naming, pseudo-code control flow, bug root-cause disclosure, and refactoring checklists—that reveal howto implement rather thanwhatbehavior is required
-
[7]
Information integrity(Q5–Q7): public API contracts are unambiguous; no test metadata (file names, function names, scoring details) is disclosed; no version numbers or repository names appear
-
[8]
Narrative quality(Q8–Q9): the instruction provides a coherent version narrative with clear prior- ity ordering among targets; individual target sections follow a consistent structure (background, requirements, constraints)
-
[9]
Test conventions(T1–T7): tests use the required directory layout; target weights sum to 1.0; tests are deterministic and environment-independent; tests do not check implementation internals beyond the specified public contract. 21 (a) Optuna v4.2(medium.com/optuna) (b) Kitex v0.12.0(cloudwego.io) (c) Ruff v0.12.0(astral.sh) Figure 13:Examples of high-qual...
-
[10]
Before”: initial validation; “After
Minimality: tests performing only dead-letter matching without behavioral value are flagged for removal. Issues are classified asT-missing,T-ambiguous,T-incorrect, orT-other. Each confirmed issue is repaired by updating the instruction or test, and the oracle patch is re-run to confirm the fail-to-pass guarantee. G.3 Quality Control Protocol G.3.1 Attribu...
-
[11]
Reads the complete test output (test-stdout.txt) containing all subtask results
-
[12]
Reads the task specification (instruction.md) to understand requirements
-
[13]
Optionally inspects the agent’s final code or greps the trajectory for relevant context
-
[14]
Outputs a structured classification for each failed subtask: category, sub-type, root-cause phrase (English, 2–5 words), and rationale (1–3 sentences with technical detail). The task-level approach (one classifier call per task, classifying all failed subtasks together) enables cross-subtask awareness—e.g., recognizing that multiple subtasks fail due to t...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.