DMF: A Deterministic Memory Framework for Conversational AI Agents
Pith reviewed 2026-06-28 10:13 UTC · model grok-4.3
The pith
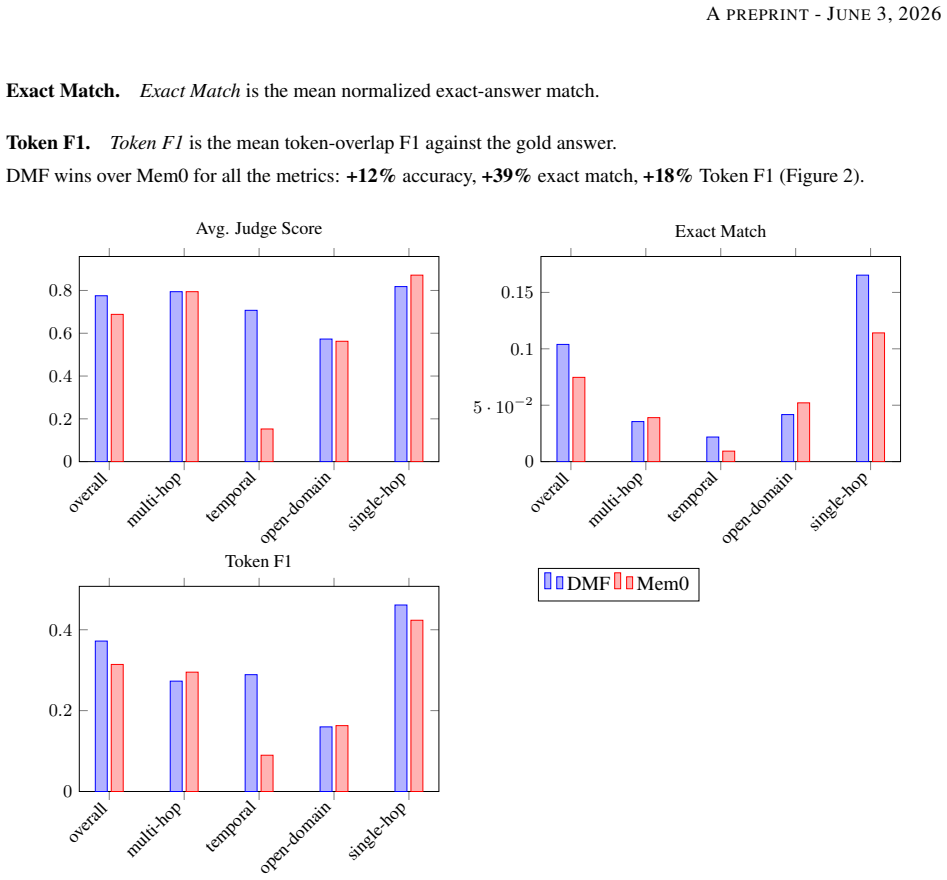
DMF replaces LLM-based memory summarization with a deterministic pipeline of classical signals and a survival score to match accuracy at 5x-242x lower token cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
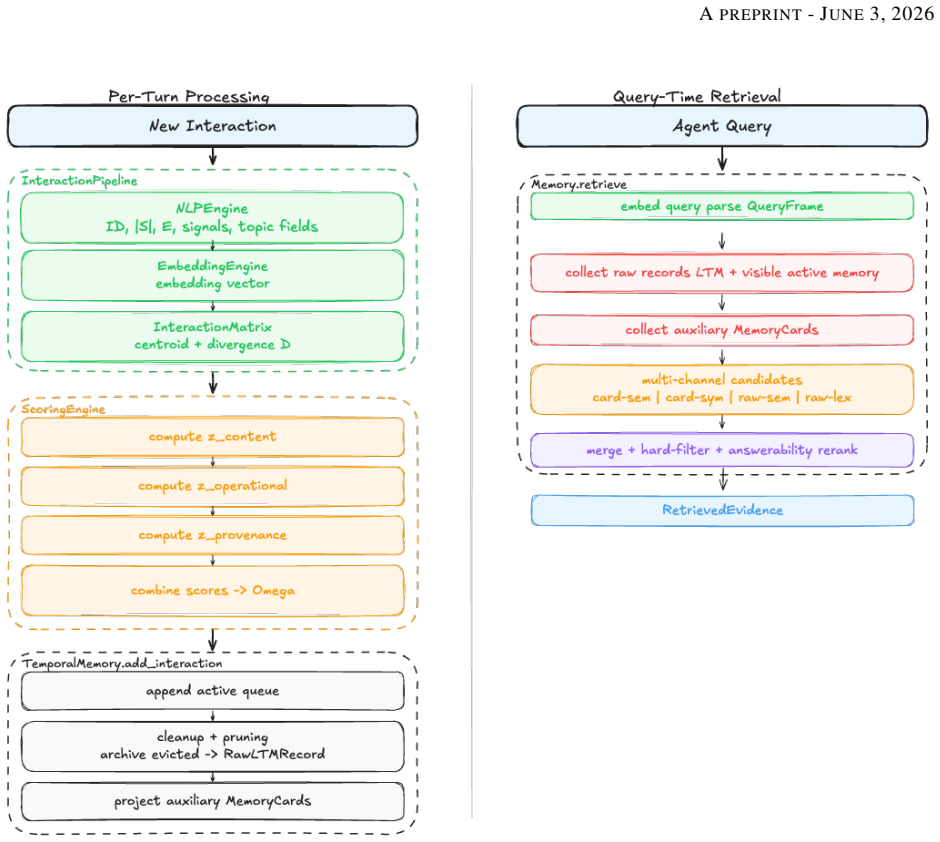
DMF assigns each conversational interaction a Survival Score Ω computed from deterministic content signals, conversational cues, and structured provenance combined through a logistic projection; an interaction-count decay law Ω_eff(Δn) then governs how relevance evolves with newer turns, enabling a fully deterministic recall and pruning pipeline that eliminates LLM calls from memory management while matching accuracy on LoCoMo and LongMemEval benchmarks.
What carries the argument
The Survival Score Ω, formed by logistic projection of deterministic signals and updated by interaction-count decay Ω_eff(Δn).
If this is right
- Memory context preparation requires zero LLM tokens.
- Overall conversation token usage falls by factors between 5 and 242 compared with Mem0.
- Pruning decisions become fully deterministic and traceable to explicit signals rather than opaque model outputs.
- Long interaction horizons remain feasible without escalating generative costs.
- The memory layer can run entirely on CPU without model inference.
- pith_inferences=[
Where Pith is reading between the lines
- The same signal-plus-decay structure could be tested on non-conversational agent memory tasks such as tool-use histories or planning traces.
- If the logistic projection proves stable across domains, hybrid systems might use DMF for routine retention and reserve LLMs only for rare edge-case summarization.
- The interaction-count decay (rather than wall-clock time) suggests the framework could transfer directly to batch or offline agent logs where timing is irregular.
- Keywords from the paper itself plus standard phrases: deterministic memory, conversational AI, survival score, token efficiency, memory pruning, classical NLP, AI agents, semantic relevance.
Load-bearing premise
That deterministic content signals, conversational cues, and structured provenance can be combined through a logistic projection into a Survival Score that reliably tracks semantic relevance without any generative model.
What would settle it
Running the same benchmark conversations with DMF pruning versus LLM summarization and measuring whether accuracy on downstream recall or coherence tasks drops below the LLM baseline by a statistically detectable margin.
Figures
read the original abstract
Conversational AI agents require memory systems that are both scalable and semantically coherent across long interaction horizons. Existing approaches rely predominantly on large language model (LLM)-based summarisation at write time, which introduces non-determinism, escalating token costs, and opacity in pruning decisions. We present the Deterministic Memory Framework (DMF), a CPU-first approach that replaces generative memory compression with a fully deterministic pipeline grounded in classical NLP analysis, vector geometry, and mathematical scoring. DMF assigns each conversational interaction a Survival Score $\Omega$ computed from deterministic content signals, conversational cues, and structured provenance, combined through a logistic projection. An interaction-count decay law, denoted as $\Omega_{\mathrm{eff}}(\Delta n)$, governs how relevance evolves as new turns arrive, where $\Delta n$ is the number of newer interactions rather than wall-clock time, preserving full determinism. We present the mathematical formulation of DMF, its structured recall pipeline, the pruning decision procedure, and the evaluation protocol. Experiments are conducted on a purpose-built benchmark using the LoCoMo and LongMemEval datasets. We compare DMF against Mem0, a popular memory layer for AI agents. DMF achieves comparable accuracy while using zero tokens to prepare the memory context and 5x to 242x fewer tokens over the entire conversation. These results show that it is possible to eliminate LLM calls from the memory-management loop, reducing token costs to nearly zero and enabling deterministic memory systems for conversational AI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
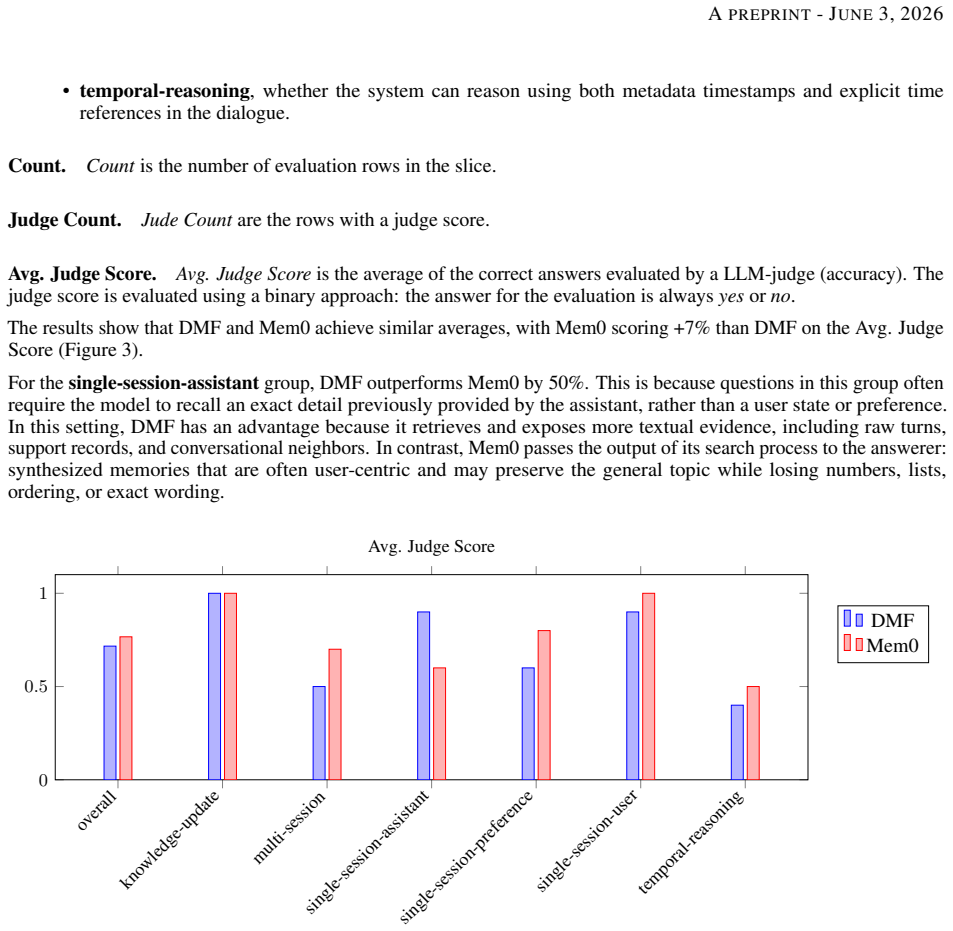
Summary. The manuscript introduces the Deterministic Memory Framework (DMF) as a CPU-first, fully deterministic alternative to LLM-based memory management for conversational agents. DMF computes a Survival Score Ω for each interaction from deterministic content signals, conversational cues, and structured provenance via logistic projection, applies an interaction-count decay law Ω_eff(Δn), and uses the resulting scores for structured recall and pruning. On LoCoMo and LongMemEval benchmarks, DMF is reported to match the accuracy of Mem0 while incurring zero tokens for memory-context preparation and 5×–242× fewer tokens overall.
Significance. If the Survival Score can be shown to track semantic relevance independently of the evaluation benchmarks, DMF would offer a concrete route to scalable, low-cost, and fully reproducible memory systems that eliminate non-determinism and token overhead from the memory loop. The explicit mathematical formulation and emphasis on a reproducible evaluation protocol are strengths that distinguish the work from purely empirical LLM-memory papers.
major comments (3)
- [Mathematical formulation] Mathematical formulation section: the logistic projection that produces Ω is described at a high level, yet the coefficients are free parameters whose values and derivation (first-principles versus fit to benchmark data) are not supplied; without this, the claim that Ω tracks semantic relevance rather than surface cues cannot be evaluated.
- [Evaluation protocol] Evaluation protocol and results sections: the accuracy-parity claim rests on end-to-end benchmark numbers alone; no ablation of the individual signal components, no correlation of Ω with external human relevance labels, and no failure-case analysis are reported, leaving open whether the deterministic pipeline selects memories for semantic reasons or for cue statistics.
- [Results] Token-usage comparison: the headline 5×–242× reduction is load-bearing for the practical contribution, yet the manuscript provides neither per-dataset breakdowns nor explicit accounting of how Mem0’s token counts (including any LLM calls for summarization) were measured across full conversations.
minor comments (1)
- [Abstract] The abstract states that equations and an evaluation protocol are presented, but the provided text supplies neither concrete coefficient values nor error bars; adding these would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments. We address each major comment in turn below.
read point-by-point responses
-
Referee: [Mathematical formulation] Mathematical formulation section: the logistic projection that produces Ω is described at a high level, yet the coefficients are free parameters whose values and derivation (first-principles versus fit to benchmark data) are not supplied; without this, the claim that Ω tracks semantic relevance rather than surface cues cannot be evaluated.
Authors: We agree that the specific coefficients and their derivation were not sufficiently detailed in the original manuscript. In the revised version, we will include the exact values of the coefficients used in the logistic projection and explain their derivation from first-principles analysis of the content signals and conversational cues, without fitting to benchmark data. This will allow readers to evaluate the independence from surface cues. revision: yes
-
Referee: [Evaluation protocol] Evaluation protocol and results sections: the accuracy-parity claim rests on end-to-end benchmark numbers alone; no ablation of the individual signal components, no correlation of Ω with external human relevance labels, and no failure-case analysis are reported, leaving open whether the deterministic pipeline selects memories for semantic reasons or for cue statistics.
Authors: The manuscript emphasizes end-to-end performance on established benchmarks to demonstrate practical utility. However, we acknowledge the value of additional analyses. In revision, we will add ablations on the contribution of individual signal components and include a failure-case analysis. Regarding correlation with human relevance labels, we did not collect such labels in this study as the focus was on deterministic reproducibility; we will discuss this limitation and suggest it as future work. revision: partial
-
Referee: [Results] Token-usage comparison: the headline 5×–242× reduction is load-bearing for the practical contribution, yet the manuscript provides neither per-dataset breakdowns nor explicit accounting of how Mem0’s token counts (including any LLM calls for summarization) were measured across full conversations.
Authors: We will provide per-dataset token usage breakdowns in the revised manuscript. For the Mem0 token counts, they were measured by counting all tokens used in LLM calls for memory operations during the full conversation simulations on the benchmarks, including summarization steps. We will add an explicit section detailing the measurement protocol to ensure reproducibility. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The DMF Survival Score Ω is defined via explicit logistic projection of deterministic signals (content, cues, provenance) and an interaction-count decay Ω_eff(Δn). No equation or section shows these weights or the projection itself being fitted to the LoCoMo/LongMemEval benchmarks used for final accuracy reporting; the formulation is presented as a fixed mathematical construction independent of the evaluation data. End-to-end accuracy comparisons therefore test an externally specified scoring rule rather than a quantity defined by the test outcomes. No self-citation chain, self-definitional loop, or renaming of fitted results appears in the provided derivation steps. The token-reduction claim follows directly from the absence of LLM calls in the memory pipeline, which is independent of the score's semantic fidelity.
Axiom & Free-Parameter Ledger
free parameters (1)
- logistic projection coefficients
axioms (1)
- domain assumption Deterministic content signals, conversational cues, and provenance can be linearly combined and passed through a logistic function to produce a relevance score that tracks human judgment of importance.
Reference graph
Works this paper leans on
-
[1]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana et al. “Evaluating Very Long-Term Conversational Memory of LLM Agents”. In:arXiv preprint arXiv:2402.17753(2024).URL:https://arxiv.org/abs/2402.17753
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Di Wu et al.LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. 2025. arXiv: 2410.10813 [cs.CL].URL:https://arxiv.org/abs/2410.10813
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara et al. “Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory”. In: arXiv preprint arXiv:2504.19413(2025).URL:https://arxiv.org/abs/2504.19413
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Matthew Honnibal et al.spaCy: Industrial-strength Natural Language Processing in Python. Zenodo. 2020.DOI: 10.5281/zenodo.1212303.URL:https://spacy.io
work page doi:10.5281/zenodo.1212303.url:https://spacy.io 2020
-
[5]
V ADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text
Clayton J. Hutto and Eric E. Gilbert. “V ADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text”. In:Proceedings of the 8th International Conference on Weblogs and Social Media (ICWSM). AAAI Press, 2014, pp. 216–225.URL: https://ojs.aaai.org/index.php/ICWSM/article/view/14550
2014
-
[6]
MemGPT: Towards LLMs as Operating Systems
Charles Packer et al. “MemGPT: Towards LLMs as Operating Systems”. In:arXiv preprint arXiv:2310.08560 (2023).URL:https://arxiv.org/abs/2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
A-MEM: Agentic Memory for LLM Agents
Wujiang Li et al. “A-MEM: Agentic Memory for LLM Agents”. In:arXiv preprint arXiv:2502.12110(2025). URL:https://arxiv.org/abs/2502.12110
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Kuang-Huei Lee et al. “ReadAgent: A System for Getting Better LLM Responses to Long Input Documents Using Memory and Retrieval”. In:arXiv preprint arXiv:2402.09727(2024).URL: https://arxiv.org/abs/ 2402.09727
-
[9]
MemoryBank: Enhancing Large Language Models with Long-Term Memory
Wanjun Zhong et al. “MemoryBank: Enhancing Large Language Models with Long-Term Memory”. In:arXiv preprint arXiv:2305.10250(2023).URL:https://arxiv.org/abs/2305.10250
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
English trans- lation:Memory: A Contribution to Experimental Psychology, Teachers College, Columbia University, 1913
Hermann Ebbinghaus.Über das Gedächtnis: Untersuchungen zur experimentellen Psychologie. English trans- lation:Memory: A Contribution to Experimental Psychology, Teachers College, Columbia University, 1913. Leipzig: Duncker & Humblot, 1885
1913
-
[11]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”. In:Advances in Neural Information Processing Systems (NeurIPS). V ol. 33. 2020, pp. 9459–9474.URL: https://arxiv.org/ abs/2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[12]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao et al. “Retrieval-Augmented Generation for Large Language Models: A Survey”. In:arXiv preprint arXiv:2312.10997(2023).URL:https://arxiv.org/abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
https://github.com/langchain- ai/ langmem
LangChain AI.LangMem: Long-Term Memory for LLM Agents. https://github.com/langchain- ai/ langmem. 2024
2024
-
[14]
https://github.com/ langchain-ai/langchain
Harrison Chase.LangChain: Building Applications with LLMs through Composability. https://github.com/ langchain-ai/langchain. 2023
2023
-
[15]
The Atomic Components of Thought
John R. Anderson and Christian Lebiere. “The Atomic Components of Thought”. In:Lawrence Erlbaum Associates(1998). ACT-R cognitive architecture; see also Anderson, J.R. (1983).The Architecture of Cognition. Harvard University Press
1998
-
[16]
https://github
Qdrant Team.FastEmbed: Fast, Accurate, and Lightweight Python Library for Embeddings. https://github. com/qdrant/fastembed. Python library wrapping ONNX-based embedding models for CPU-efficient infer- ence. 2023
2023
-
[17]
https://www.trychroma.com
Chroma Team.ChromaDB: The Open-Source Embedding Database. https://www.trychroma.com. Open- source vector database used as the default LTM backend in DMF. 2023
2023
-
[18]
C-Pack: Packed Resources For General Chinese Embeddings
Shitao Xiao et al. “C-Pack: Packaged Resources To Advance General Chinese Embedding”. In:arXiv preprint arXiv:2309.07597(2023). Source of the BAAI/bge-small-en-v1.5 embedding model family used by DMF. URL:https://arxiv.org/abs/2309.07597
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Aaditya Singh et al.OpenAI GPT-5 System Card. 2026. arXiv: 2601.03267 [cs.CL].URL: https://arxiv. org/abs/2601.03267. 5https://master-data-analytics.it/ 19 APREPRINT- JUNE3, 2026 A Appendix This appendix reports the prompt templates used in the benchmark pipeline to evaluate DMF against Mem0. The templates are shared across frameworks; only the memory con...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Getting 1 out of 2, 2 out of 4, etc
**PARTIAL CREDIT**: If the generated answer includes AT LEAST ONE correct item from the gold answer’s list, mark CORRECT. Getting 1 out of 2, 2 out of 4, etc. is always acceptable. Only mark WRONG if NONE of the gold answer items appear. 20 APREPRINT- JUNE3, 2026
2026
-
[21]
Judge semantic meaning, not exact wording
**PARAPHRASES COUNT**: Same concept in different words is CORRECT. Judge semantic meaning, not exact wording
-
[22]
Never penalize for being more detailed or specific
**EXTRA DETAIL IS FINE**: A longer answer that includes the gold answer’s key facts plus additional information is CORRECT. Never penalize for being more detailed or specific
-
[23]
Durations within 50% are CORRECT
**DATE TOLERANCE**: Dates within 14 days of each other are CORRECT. Durations within 50% are CORRECT. Relative dates that point to the same time window are CORRECT
-
[24]
**ABSTENTION MATCHING**: If the gold answer is an abstention or indicates the information is unavailable, any semantically equivalent refusal to answer is CORRECT
-
[25]
Different wording, phrasing, or level of detail should not result in WRONG if the underlying concept matches
**SEMANTIC OVERLAP**: Judge whether the generated answer addresses the same topic and captures the core idea of the gold answer. Different wording, phrasing, or level of detail should not result in WRONG if the underlying concept matches
-
[26]
**SAME REFERENT**: If the generated answer identifies the same named entity, person, character, place, or concept as the gold answer, mark CORRECT even if it gives a different description or extra detail
-
[27]
reasoning
**FOCUS ON KNOWLEDGE, NOT WORDING**: The goal is to assess whether the system recalled the right fact. Minor differences in specificity, phrasing, or scope should not result in WRONG. Only mark WRONG when the generated answer demonstrates a genuinely different or incorrect understanding. ## ONLY mark WRONG if: - The generated answer contains ZERO correct ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.