Simulated Customers Never Walk Away: Decision Fidelity of LLM User Simulators Measured Against Real Purchase Outcomes
Pith reviewed 2026-06-27 01:36 UTC · model grok-4.3
The pith
LLM customer simulators match real buyers but push non-buyers toward purchase.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
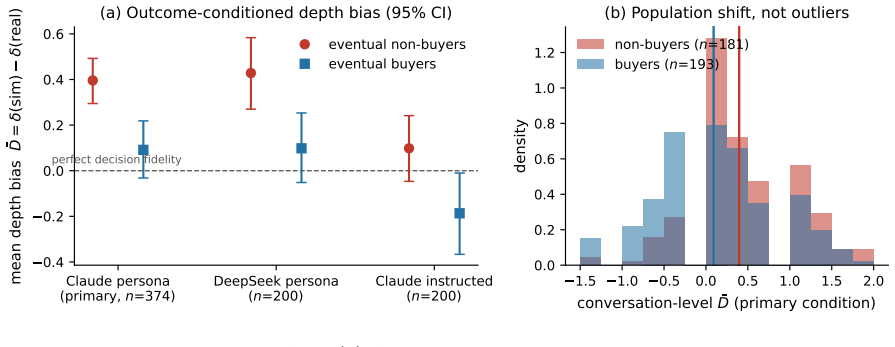
Simulators exhibit a disengagement deficit: they reproduce the decision states of eventual buyers with near-zero bias but inflate those of eventual non-buyers toward the purchase frame by a depth bias of +0.40, halving resistance from 25.1 percent to 13.5 percent and nearly doubling deliberation from 21.9 percent to 40.1 percent while producing no purchases. The deficit replicates across model families and is not removed by prompting the simulator that it may disengage.
What carries the argument
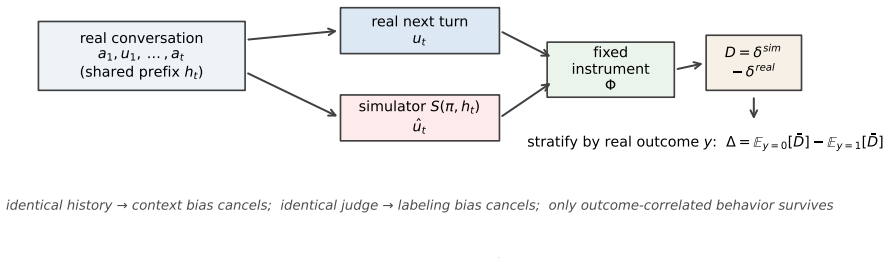
The teacher-forced probe protocol that holds conversation context and measurement instrument fixed while comparing simulated decision states to verified real purchase outcomes.
If this is right
- Benchmarks of sales or persuasion agents will overstate funnel progress on the subset of customers who would actually walk away.
- Training loops that rely on these simulators will reinforce the same over-engagement pattern.
- Simple prompting fixes that allow disengagement reduce marginal bias but leave the outcome-conditioned contrast largely intact.
- The deficit appears consistently across multiple model families, suggesting it is not an isolated implementation flaw.
Where Pith is reading between the lines
- The same bias may appear in any simulation setting where real users can quit, such as customer support or negotiation dialogues.
- Explicitly modeling decaying motivation rather than relying on role instructions could reduce the deficit.
- Agents trained or evaluated on current simulators may under-deliver when deployed against real users who retain the option to disengage.
Load-bearing premise
The fixed-context probe protocol and the set of 2,790 sampled real conversations capture the simulators' own decision dynamics without introducing selection effects or measurement artifacts.
What would settle it
Re-running the identical teacher-forced probes on a new collection of real sales conversations from a different product category or customer segment and finding that the depth bias for non-buyers is no longer near 0.40.
Figures
read the original abstract
LLM-as-user-simulation has become core infrastructure for conversational AI: agent benchmarks (tau-bench), training pipelines, and a growing body of fidelity studies all rely on LLMs role-playing the human side of dialogue. Existing frameworks measure communicative fidelity -- whether simulators talk like humans -- against ground truth from paid participants role-playing assigned goals. We argue this has a structural blind spot: when the goal is assigned, the user's willingness is exogenous, so no framework can test whether simulators make decisions like real users whose motivation is endogenous, latent, and decaying. We introduce decision fidelity -- whether a simulated population reproduces the decision-state dynamics of real users facing real, consequential choices -- and measure it on a unique testbed: 2,790 production conversations between an LLM sales agent and real customers, including 793 with verified payment outcomes. Using a teacher-forced probe protocol that holds context and instrument fixed, we find a systematic, outcome-correlated failure we call the disengagement deficit: simulators reproduce eventual buyers almost exactly (depth bias +0.09) but inflate eventual non-buyers toward the purchase frame (depth bias +0.40; d=0.38, p<0.001), halving expressed resistance (25.1% to 13.5%) and nearly doubling deliberation (21.9% to 40.1%) while fabricating no purchases. The deficit replicates across model families (DeepSeek: d=0.41, p=0.002) and resists the obvious fix: instructing the simulator that it may disengage cuts marginal bias five-fold but barely moves the outcome-conditioned contrast (d=0.34, p=0.008). Real non-buyers say "not now" and stop; simulated non-buyers ask about price. Evaluating or training sales and persuasion agents against such simulators overstates funnel progress exactly where it matters most -- the customers who walk away.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'decision fidelity' as a measure for LLM user simulators, arguing that existing communicative fidelity tests cannot capture endogenous decision dynamics because they assign goals exogenously. Using 2,790 real production sales conversations (793 with verified payment outcomes) and a teacher-forced probe protocol that holds context and instrument fixed, the authors report a systematic 'disengagement deficit': simulators reproduce eventual buyers closely (depth bias +0.09) but inflate eventual non-buyers toward purchase (depth bias +0.40; d=0.38, p<0.001), halving expressed resistance and nearly doubling deliberation while fabricating no purchases. The deficit replicates across model families and persists after an explicit disengagement instruction.
Significance. If the result holds, it identifies a load-bearing limitation in LLM simulators for sales-agent benchmarks, training pipelines, and persuasion studies: they systematically overstate funnel progress precisely for the customers who walk away. The empirical grounding in verified real-world outcomes, statistical contrasts, and cross-model replication constitutes a concrete advance over prior fidelity work that relies on paid role-players with assigned goals.
major comments (2)
- [Methods / probe protocol] §4 (teacher-forced probe protocol): the central contrast depends on the assumption that fixing context and instrument isolates endogenous decision-state dynamics. The skeptic concern that this protocol may itself suppress natural termination in simulators (real non-buyers stop after resistance; simulators continue) is not fully dispelled by the disengagement-instruction ablation, which reduces marginal bias but leaves the outcome-conditioned d=0.34 contrast intact. A direct comparison of probe vs. free-generation trajectories on the same real contexts would test whether the measured deficit is protocol-dependent.
- [Data and sampling] §3.2 (sampling of 793 verified-payment subset from 2,790 conversations): selection into the verified non-buyer sample could skew toward higher-engagement cases, inflating the apparent deficit. The paper should report engagement statistics (turns, resistance rate) for the full 2,790 vs. the verified subset to rule out selection effects as a contributor to the +0.40 depth bias.
minor comments (2)
- [Results] The depth-bias metric definition and its exact formula should be stated explicitly in the main text (not only supplementary) to permit independent replication of the reported effect sizes.
- [Results] Table or figure presenting the resistance/deliberation percentages (25.1% vs 13.5%; 21.9% vs 40.1%) should include per-model breakdowns to show consistency with the aggregate d=0.38 result.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and constructive suggestions. We respond to each major comment below.
read point-by-point responses
-
Referee: [Methods / probe protocol] §4 (teacher-forced probe protocol): the central contrast depends on the assumption that fixing context and instrument isolates endogenous decision-state dynamics. The skeptic concern that this protocol may itself suppress natural termination in simulators (real non-buyers stop after resistance; simulators continue) is not fully dispelled by the disengagement-instruction ablation, which reduces marginal bias but leaves the outcome-conditioned d=0.34 contrast intact. A direct comparison of probe vs. free-generation trajectories on the same real contexts would test whether the measured deficit is protocol-dependent.
Authors: The disengagement-instruction ablation was included specifically to test whether the probe protocol suppresses termination. Even with explicit permission to disengage, the outcome-conditioned contrast remains significant (d=0.34). This supports that the deficit reflects endogenous decision dynamics rather than protocol artifact. A free-generation comparison would introduce uncontrolled variation in context and instrument, weakening the controlled contrast central to the design. We have added discussion of this limitation in the revised manuscript. revision: partial
-
Referee: [Data and sampling] §3.2 (sampling of 793 verified-payment subset from 2,790 conversations): selection into the verified non-buyer sample could skew toward higher-engagement cases, inflating the apparent deficit. The paper should report engagement statistics (turns, resistance rate) for the full 2,790 vs. the verified subset to rule out selection effects as a contributor to the +0.40 depth bias.
Authors: We agree that selection effects warrant explicit checking. In the revised manuscript we will report engagement statistics (average turns and resistance rates) for the full 2,790 conversations versus the 793 verified subset. revision: yes
Circularity Check
No significant circularity: central contrast uses external real purchase outcomes
full rationale
The paper's core claim compares LLM simulator behavior to verified real customer outcomes from 2,790 production conversations (793 with payment verification). No load-bearing step reduces to a fitted parameter, self-citation chain, or definitional equivalence; the disengagement deficit is quantified directly against independent ground truth rather than derived from the simulators themselves. The teacher-forced protocol is an experimental design choice, not a self-referential derivation. This is a standard empirical measurement against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Assumptions underlying two-sample t-tests and Cohen's d effect sizes (sufficient sample size and approximate normality for the reported p and d values)
Reference graph
Works this paper leans on
-
[1]
ResPer: Computationally modelling resisting strategies in persuasive conversations
Ritam Dutt, Sayan Sinha, Rishabh Joshi, Surya Shekhar Chakraborty, Meredith Riggs, Xinru Yan, Haogang Bao, and Carolyn Penstein Rosé. ResPer: Computationally modelling resisting strategies in persuasive conversations. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 78–
-
[2]
doi: 10.18653/v1/2021.eacl-main.7
Association for Computational Linguistics, apr 2021. doi: 10.18653/v1/2021.eacl-main.7. URLhttps://aclanthology.org/2021.eacl-main.7
-
[3]
Using imperfect surrogates for downstream inference: Design-based supervised learning for social science applications of large language models.NeurIPS, 2023
Naoki Egami, Musashi Hinck, Brandon M Stewart, and Hanying Wei. Using imperfect surrogates for downstream inference: Design-based supervised learning for social science applications of large language models.NeurIPS, 2023
2023
-
[4]
A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594, 2024
Jiawei Gu et al. A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594, 2024. 13
Pith/arXiv arXiv 2024
-
[5]
User willingness-aware sales talk dataset
Asahi Hentona, Jun Baba, Shiki Sato, and Reina Akama. User willingness-aware sales talk dataset. InProceedings of COLING 2025, 2025. arXiv:2412.19490
arXiv 2025
-
[6]
Jessica Hullman, David Broska, Huaman Sun, and Aaron Shaw. This human study did not involve human subjects: Validating LLM simulations as behavioral evidence.arXiv preprint arXiv:2602.15785, 2026
arXiv 2026
-
[7]
A user simulator for task-completion dialogues.arXiv preprint arXiv:1612.05688, 2016
Xiujun Li, Zachary C Lipton, Bhuwan Dhingra, Lihong Li, Jianfeng Gao, and Yun-Nung Chen. A user simulator for task-completion dialogues.arXiv preprint arXiv:1612.05688, 2016
Pith/arXiv arXiv 2016
-
[8]
Learning when to quit in sales conversa- tions.arXiv preprint arXiv:2511.01181, 2025
Emaad Manzoor, Eva Ascarza, and Oded Netzer. Learning when to quit in sales conversa- tions.arXiv preprint arXiv:2511.01181, 2025
arXiv 2025
-
[9]
Ofer Meshi, Krisztian Balog, Sally Goldman, Avi Caciularu, Guy Tennenholtz, Jihwan Jeong, Amir Globerson, and Craig Boutilier. ConvApparel: A benchmark dataset and validation framework for user simulators in conversational recommenders.arXiv preprint arXiv:2602.16938, 2026. Google
arXiv 2026
-
[10]
M Nandakishor. Salesrlagent: A reinforcement learning approach for real-time sales conversion prediction and optimization.arXiv preprint arXiv:2503.23303, 2025
arXiv 2025
-
[11]
How much does persuasion strategy matter? LLM-annotated evidence from charitable donation dialogues
Tatiana Petrova, Stanislav Sokol, and Radu State. How much does persuasion strategy matter? LLM-annotated evidence from charitable donation dialogues. 2026
2026
-
[12]
Agenda- based user simulation for bootstrapping a POMDP dialogue system
Jost Schatzmann, Blaise Thomson, Karl Weilhammer, Hui Ye, and Steve Young. Agenda- based user simulation for bootstrapping a POMDP dialogue system. InNAACL-HLT, 2007
2007
-
[13]
Ferdinand M. Schessl. The autocorrelation blind spot: Why 42% of turn-level findings in LLM conversation analysis may be spurious.arXiv preprint arXiv:2604.14414, 2026
Pith/arXiv arXiv 2026
-
[14]
Preethi Seshadri, Samuel Cahyawijaya, Ayomide Odumakinde, Sameer Singh, and Seraphina Goldfarb-Tarrant. Lost in simulation: LLM-simulated users are unreliable proxies for human users in agentic evaluations.arXiv preprint arXiv:2601.17087, 2026
arXiv 2026
-
[15]
Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548, 2023
Mrinank Sharma, Meg Tong, Tomasz Korbak, et al. Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548, 2023
Pith/arXiv arXiv 2023
-
[16]
Evaluating alignment of behavioral dispositions in LLMs.arXiv preprint arXiv:2602.11328,
Amir Taubenfeld, Zorik Gekhman, Lior Nezry, Omri Feldman, Natalie Harris, Shashir Reddy, Romina Stella, Ariel Goldstein, Marian Croak, Yossi Matias, and Amir Feder. Evaluating alignment of behavioral dispositions in LLMs.arXiv preprint arXiv:2602.11328,
-
[17]
Persuasion for good: Towards a personalized persuasive dialogue system for social good
Xuewei Wang, Weiyan Shi, Richard Kim, Yoojung Oh, Sijia Yang, Jingwen Zhang, and Zhou Yu. Persuasion for good: Towards a personalized persuasive dialogue system for social good. InACL, 2019
2019
-
[18]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024
Pith/arXiv arXiv 2024
-
[19]
Qingyu Zhang, Chunlei Xin, Xuanang Chen, Yaojie Lu, Hongyu Lin, Xianpei Han, Le Sun, Qing Ye, Qianlong Xie, and Xingxing Wang. Ai-salesman: Towards reliable large language model driven telemarketing.arXiv preprint arXiv:2511.12133, 2025. 14
arXiv 2025
-
[20]
Judging llm-as-a-judge with mt-bench and chatbot arena.NeurIPS, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.NeurIPS, 2023
2023
-
[21]
Mind the Sim2Real gap in user simulation for agentic tasks.arXiv preprint arXiv:2603.11245, 2026
Xuhui Zhou, Weiwei Sun, Qianou Ma, Yiqing Xie, Jiarui Liu, Weihua Du, Sean Welleck, Yiming Yang, Graham Neubig, Sherry Tongshuang Wu, and Maarten Sap. Mind the Sim2Real gap in user simulation for agentic tasks.arXiv preprint arXiv:2603.11245, 2026
arXiv 2026
-
[22]
Ming Zhu, Juntao Tan, Rithesh Murthy, Jielin Qiu, Liangwei Yang, Wenting Zhao, Silvio Savarese, Shelby Heinecke, and Huan Wang. RealUserSim: Bridging the reality gap in agent benchmarking via grounded user simulation.arXiv preprint arXiv:2605.20204, 2026. 15 A Decision-State Instrument Prompt (Φ) The instrument is an LLM perceiver that maps a user turn, i...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.