Online Agent-as-a-Judge: Situation-Generating Evaluation for Interactive Agents
Pith reviewed 2026-06-27 19:43 UTC · model grok-4.3
The pith
An in-world evaluator agent interacts with a target agent to generate situations that test 32 social criteria, raising coverage and human agreement over passive observation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
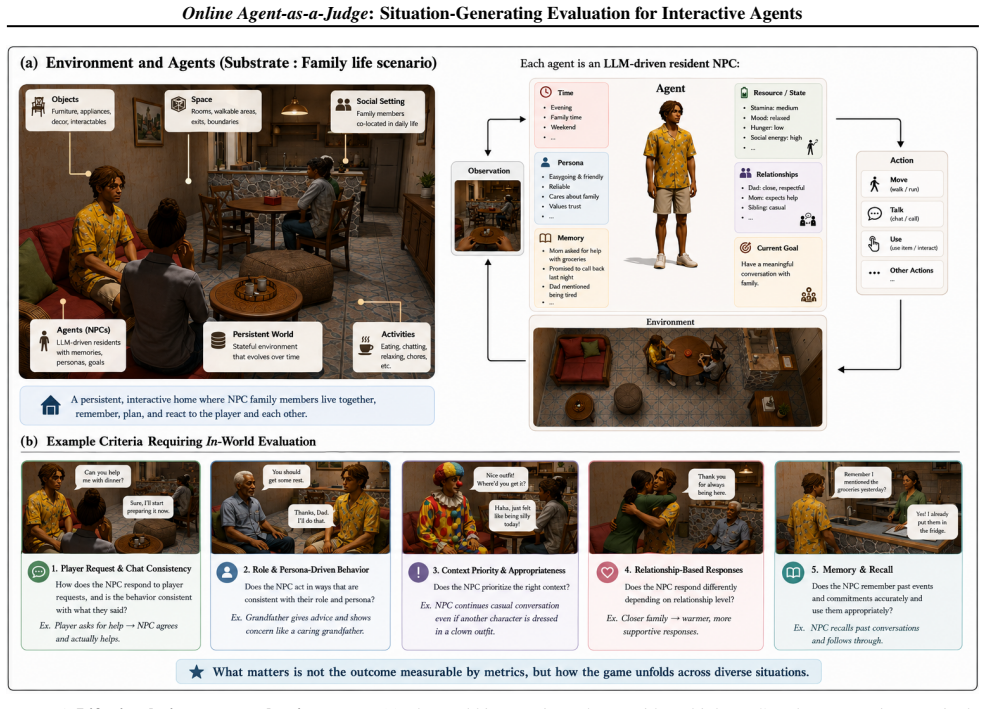
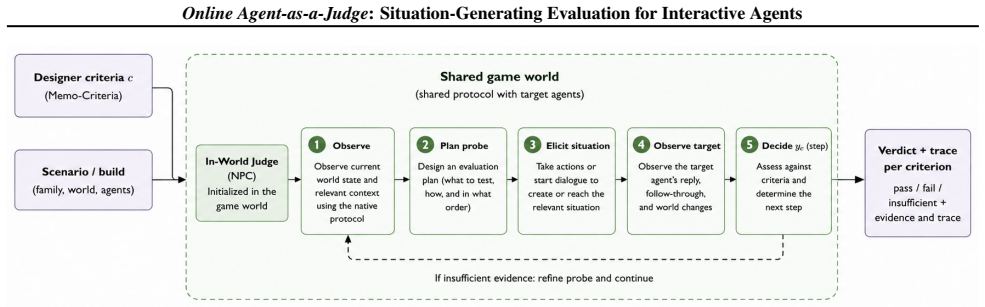
Online Agent-as-a-Judge deploys an in-world evaluator agent that interacts with the target agent through the environment's native dialogue and action protocol, actively eliciting situations relevant to the evaluation criteria. The resulting trajectories provide evidence for assessing both immediate responses and subsequent behavior. In a life-simulation environment with 32 designer-authored social criteria, this approach improves criteria coverage and agreement with human labels, yielding more reliable evidence-grounded evaluations of behaviors that passive methods can leave unobserved.
What carries the argument
An in-world evaluator agent that shares the environment and uses native interaction protocols to generate criterion-relevant situations on the fly.
If this is right
- Evaluations can now test social capabilities that only surface under specific conditions rather than waiting for them to occur by chance.
- Trajectories contain explicit evidence of both the elicited situation and the agent's subsequent actions.
- Agreement with human labels rises because the generated situations are tied directly to the criteria being scored.
- The same framework can be applied to any environment that supplies a shared dialogue and action protocol.
Where Pith is reading between the lines
- If the evaluator's prompts or persona are varied across runs, the method could surface different subsets of behaviors for the same target agent.
- The approach may reduce the number of environment rollouts needed to reach stable coverage compared with purely random or scripted situation generation.
- Extending the evaluator to multiple simultaneous criteria in one interaction could further increase efficiency, though that remains outside the reported experiments.
Load-bearing premise
The evaluator agent can create situations relevant to the criteria without introducing its own systematic biases or changing the target agent's observable behavior through the interaction protocol.
What would settle it
A controlled comparison in which the same target agents are evaluated once with the interactive judge and once with passive scoring, followed by human raters scoring both sets of trajectories for the same 32 criteria; if coverage or human agreement does not increase, the central claim fails.
Figures
read the original abstract
Evaluating LLM-powered interactive social agents is challenging because socially relevant behaviors depend not only on isolated outputs, but also on prior interactions, social roles, and downstream actions. Existing methods typically allow a target agent to act freely in an environment and then score the resulting trajectory. However, this passive setup can miss capabilities that only become observable under specific social circumstances; for example, conflict handling may remain untested if no disagreement arises. We propose Online Agent-as-a-Judge, a situation-generating evaluation framework for interactive social agents. Online Agent-as-a-Judge deploys an in-world evaluator agent that interacts with the target agent through the environment's native dialogue and action protocol, actively eliciting situations relevant to the evaluation criteria. The resulting trajectories provide evidence for assessing both immediate responses and subsequent behavior. In a life-simulation environment with $32$ designer-authored social criteria, Online Agent-as-a-Judge improves criteria coverage and agreement with human labels, yielding more reliable evidence-grounded evaluations of behaviors that passive methods can leave unobserved.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Online Agent-as-a-Judge, a situation-generating evaluation framework for LLM-powered interactive social agents. An in-world evaluator agent interacts with the target agent via the environment's native dialogue and action protocol in a life-simulation setting to actively elicit situations relevant to 32 designer-authored social criteria. The resulting trajectories are claimed to improve criteria coverage and agreement with human labels relative to passive trajectory scoring, yielding more reliable evidence-grounded assessments of behaviors that passive methods can leave unobserved.
Significance. If the reported gains in coverage and human agreement prove robust, the work would be significant for the evaluation of interactive agents, as it directly targets the limitation that passive observation can miss context-dependent social behaviors. The core idea of deploying an in-world evaluator to generate relevant situations is a creative contribution that could influence benchmark design for social capabilities in LLMs.
major comments (2)
- [Abstract] Abstract: the central claim that Online Agent-as-a-Judge yields more reliable evaluations rests on the assumption that the evaluator generates relevant situations without introducing systematic biases or altering target-agent behavior via the shared interaction protocol, yet the abstract (and available description) provides no prompt template, neutrality constraint, or control experiment addressing this.
- [Abstract] Abstract: improvements in criteria coverage and human agreement are asserted without any reported experimental controls, statistical significance tests, details on how the 32 criteria were selected or scored, or comparison to a clearly specified passive baseline, making it impossible to assess whether the gains are load-bearing or artifactual.
minor comments (1)
- [Abstract] Abstract: the phrase 'evidence-grounded evaluations' is used without defining what constitutes evidence or how it is distinguished from the passive baseline.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on our work. We address each major comment point by point below, clarifying the manuscript content and indicating where revisions will be made to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Online Agent-as-a-Judge yields more reliable evaluations rests on the assumption that the evaluator generates relevant situations without introducing systematic biases or altering target-agent behavior via the shared interaction protocol, yet the abstract (and available description) provides no prompt template, neutrality constraint, or control experiment addressing this.
Authors: The abstract is intentionally concise. The full manuscript details the evaluator prompt templates in the appendix and incorporates explicit neutrality constraints (e.g., instructions to avoid leading questions or favoring particular outcomes) to minimize bias and behavior alteration. Control experiments comparing active situation generation against passive trajectories are reported in Section 5. We will revise the abstract to briefly reference these safeguards and controls for completeness. revision: yes
-
Referee: [Abstract] Abstract: improvements in criteria coverage and human agreement are asserted without any reported experimental controls, statistical significance tests, details on how the 32 criteria were selected or scored, or comparison to a clearly specified passive baseline, making it impossible to assess whether the gains are load-bearing or artifactual.
Authors: Section 3 describes the 32 designer-authored criteria and their selection process; Section 4 details the scoring protocol and human label collection; the passive baseline is explicitly the standard free-interaction trajectory scoring without the in-world evaluator. Experimental controls are included via direct comparisons in the results. However, statistical significance tests on the reported gains were not performed. We agree this strengthens the claims and will add appropriate tests (e.g., paired t-tests or bootstrap) in the revision, along with a more explicit baseline description in the abstract. revision: partial
Circularity Check
No circularity: methodological proposal with no equations, fits, or self-referential derivations
full rationale
The paper describes a new evaluation framework (Online Agent-as-a-Judge) that deploys an in-world evaluator to generate situations for 32 criteria. No equations, parameters, or quantitative derivations appear in the provided text. Claims of improved coverage and human agreement are presented as empirical outcomes to be measured externally, not as quantities defined or fitted from the method itself. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The derivation chain is therefore self-contained against external benchmarks and does not reduce any result to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The life-simulation environment supports native dialogue and action protocols that allow the evaluator agent to interact without special interfaces.
invented entities (1)
-
Online Agent-as-a-Judge evaluator agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
How to Correctly Report LLM-as-a-Judge Evaluations
URL https://openreview.net/forum ?id=AUaW6DS9si. inZOI Studio. inZOI. Video game, Early Access, 2025. URLhttps://playinzoi.com/. Larooij, M. and T¨ornberg, P. Validation is the central chal- lenge for generative social simulation: a critical review of LLMs in agent-based modeling.Artificial Intelligence Review, 59(1), 2025. doi: 10.1007/s10462-025-11412-6...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s10462-025-11412-6 2025
-
[2]
URL https://aclanthology.org/2023. emnlp-main.153/. L`u, X. H., Kazemnejad, A., Meade, N., Patel, A., Shin, D., Zambrano, A., Sta ´nczak, K., Shaw, P., Pal, C. J., and Reddy, S. AgentRewardBench: Evaluating automatic evaluations of web agent trajectories.arXiv preprint arXiv:2504.08942, 2025. Mao, L., Ren, J., Zhou, K., Chen, J., Ma, Z., and Qin, L. Deliv...
arXiv 2023
-
[3]
URL https: //doi.org/10.1145/3526113.3545616
doi: 10.1145/3526113.3545616. URL https: //doi.org/10.1145/3526113.3545616. Park, J. S., O’Brien, J., Cai, C. J., Morris, M. R., Liang, P., and Bernstein, M. S. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pp. 1–22. ACM, 2023. doi: 10.1145/3586 183.360...
-
[4]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
URL https://doi.org/10.48550/arX iv.2404.07972. Yu, P., Shen, D., Meng, S., Lee, J., Yin, W., Cui, A. Y ., Xu, Z., Zhu, Y ., Shi, X., Li, M., and Smola, A. RPGBENCH: Evaluating large language models as role-playing game engines.arXiv preprint arXiv:2502.00595, 2025. Zhang, A. L., Griffiths, T. L., Narasimhan, K. R., and Press, O. VideoGameBench: Can visio...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arx 2025
-
[5]
Zhou, S., Xu, F
URL https://openreview.net/forum ?id=drdrFhKYjP. Zhou, S., Xu, F. F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y ., Fried, D., Alon, U., and Neubig, G. WebArena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations, volume 2024, pp. 15585– 15606, 2024a. URL https://proce...
2024
-
[6]
I don’t know
Conversation / Relationship C1. Relationship-aware conversation.Form: General Behavioral. Coverage: Trace-visible.Does the character adjust register and content to the listener’s age, role, and relationship?Positive:different distance and politeness toward parent, child, sibling, grandparent.Negative:same register for everyone, or coldly formal toward clo...
-
[7]
can I go out?
Family Role / Persona Consistency C6. Family-role consistency.Form: General Behavioral. Coverage: Trace-visible.Does the character express family role and persona consistently across turns? C7. Advice, permission, and guidance.Form: Everyday. Coverage: Mixed.When younger family members ask for advice or permission, is the response role-appropriate: warm, ...
-
[8]
Following up on recent concerns.Form: General Behavioral
Memory / Continuity C13. Following up on recent concerns.Form: General Behavioral. Coverage: Mixed.Does the character later refer back to plans, feelings, or concerns shared earlier? C14. Non-hallucinated continuity.Form: General Be- havioral. Coverage: Trace-visible.Does memory use stay grounded in actually observed events? C15. Repair after conflict.For...
-
[9]
can you grab me a coffee?
Household Coordination C16. Coordinating daily plans.Form: Everyday. Cover- age: Mixed.Does the character coordinate meals, outings, rest, study, and chores with other family members? C17. Respecting shared household context.Form: Gen- eral Behavioral. Coverage: Trace-visible.Does the char- acter act in a way consistent with shared space and family routin...
-
[10]
Everyday emotional responsiveness.Form: Gen- eral Behavioral
Emotional / Social Support C22. Everyday emotional responsiveness.Form: Gen- eral Behavioral. Coverage: Trace-visible.Does the charac- ter respond to small everyday emotions, such as tiredness, boredom, hunger, or loneliness, appropriately for the rela- tionship? C23. Responding to strong distress.Form: Exceptional. Coverage: Judge-elicited.When a family ...
-
[11]
Goal-consistent action choice.Form: General Be- havioral
Agency / Goal Alignment C26. Goal-consistent action choice.Form: General Be- havioral. Coverage: Trace-visible.Are character goals, interests, and current desires reflected in action choices? C27. Plausible refusal and compromise.Form: Ev- eryday. Coverage: Mixed.Does the character refuse or compromise in a grounded way, instead of always agreeing?
-
[12]
Joining simple family play.Form: Everyday
Play / Lightweight Social Interaction C28. Joining simple family play.Form: Everyday. Cov- erage: Judge-elicited.When invited to a simple game or joke, does the character understand the rules and join the mood? C29. Handling unfair play.Form: Exceptional. Cov- erage: Judge-elicited.When a family member cheats or shows excessive competitiveness in play, do...
-
[13]
what would you do
Conflict / Norm Violation C30. Believable family conflict handling.Form: Gen- eral Behavioral. Coverage: Mixed.Does the character handle disagreement via softening, negotiation, avoidance, apology, or escalation in role-appropriate ways? C31. Handling mild daily disagreement.Form: Ev- eryday. Coverage: Mixed.Are small daily disagreements handled in a soci...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.