One More Time: Revisiting Neural Quantum States from a Reinforcement Learning Perspective
Pith reviewed 2026-07-03 16:34 UTC · model grok-4.3
The pith
Viewing energy minimization for neural quantum states as a policy gradient problem yields a trust-region optimizer that scales to billion-parameter models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Variational energy minimization for autoregressive neural quantum states is equivalent to an advantage policy-gradient problem over the Born distribution; a trust-region update that clips amplitude probability ratios and phase increments produces a stable optimizer that preserves the variational upper bound on energy while scaling to models with over a billion parameters.
What carries the argument
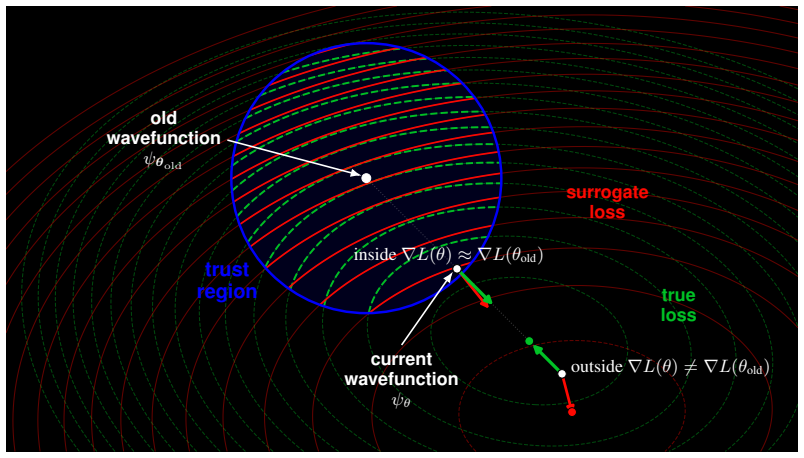
Proximal Wavefunction Optimization (PWO), a trust-region algorithm that clips probability-ratio changes in the amplitude channel and phase increments in the phase channel.
If this is right
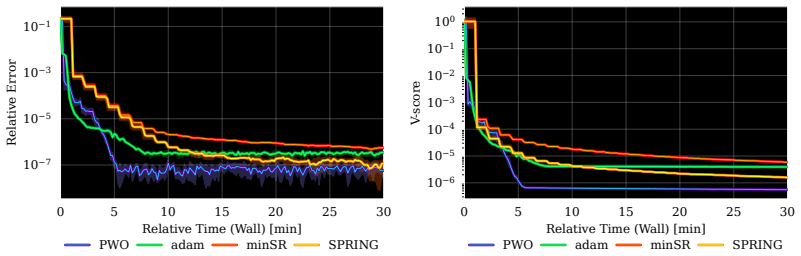
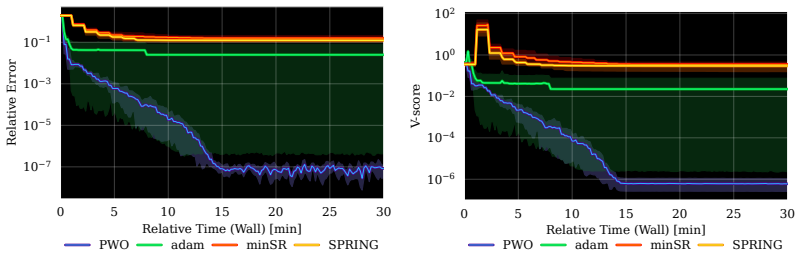
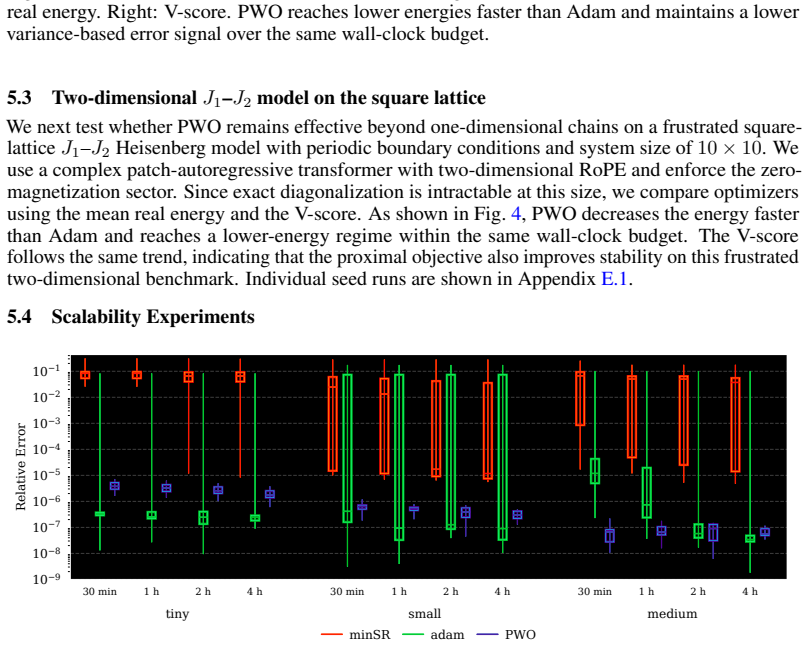
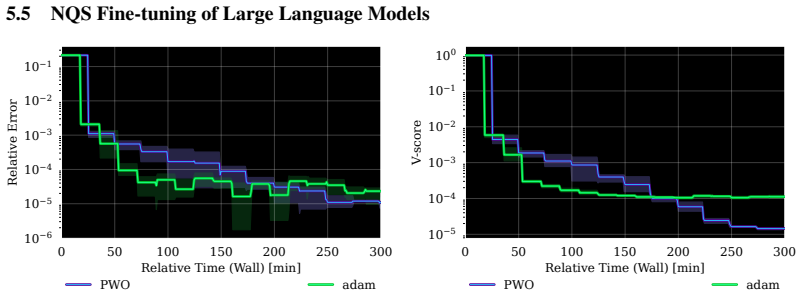
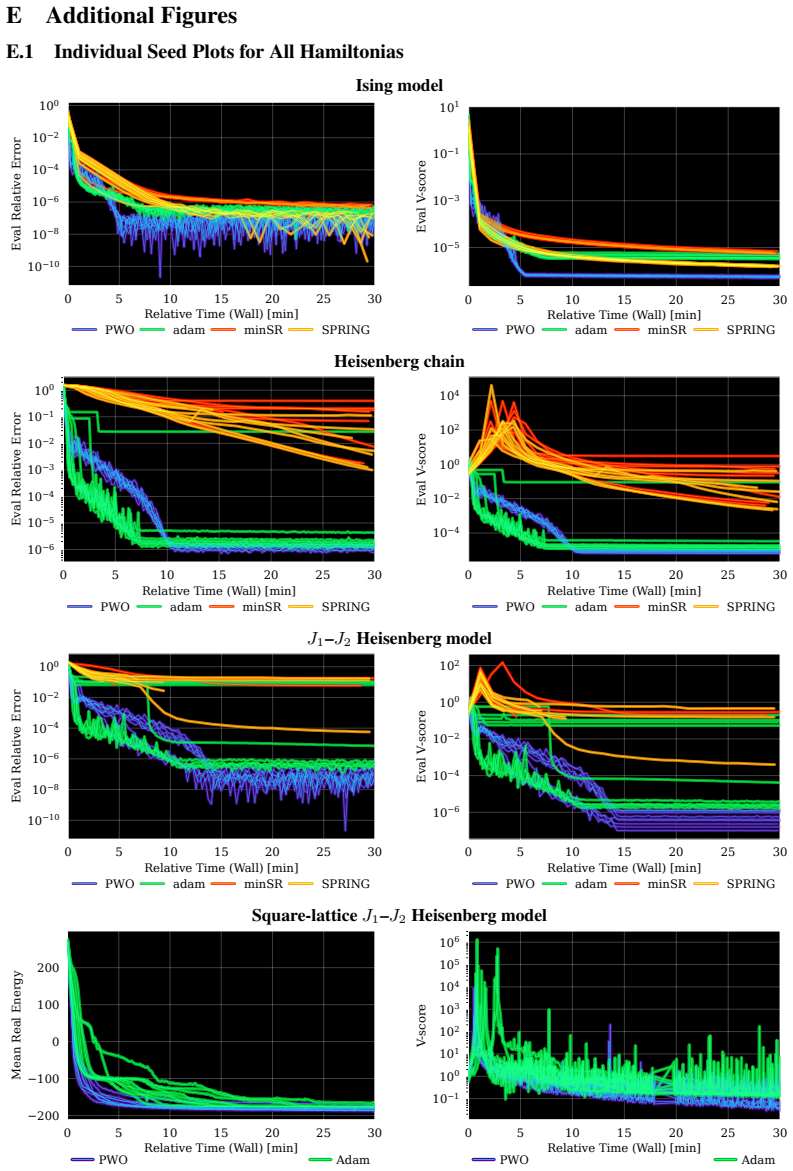
- PWO improves stability and wall-clock convergence over Adam, minSR, and SPRING on Ising and J1-J2 spin systems.
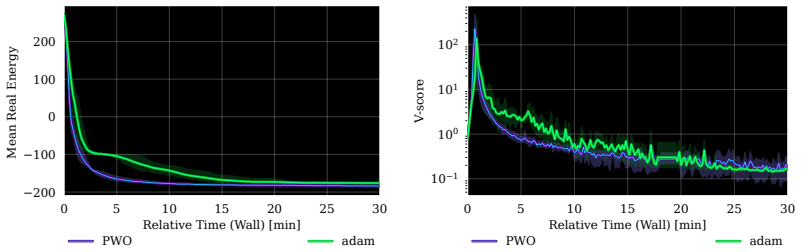
- The algorithm enables optimization of neural quantum states at a scale exceeding one billion parameters.
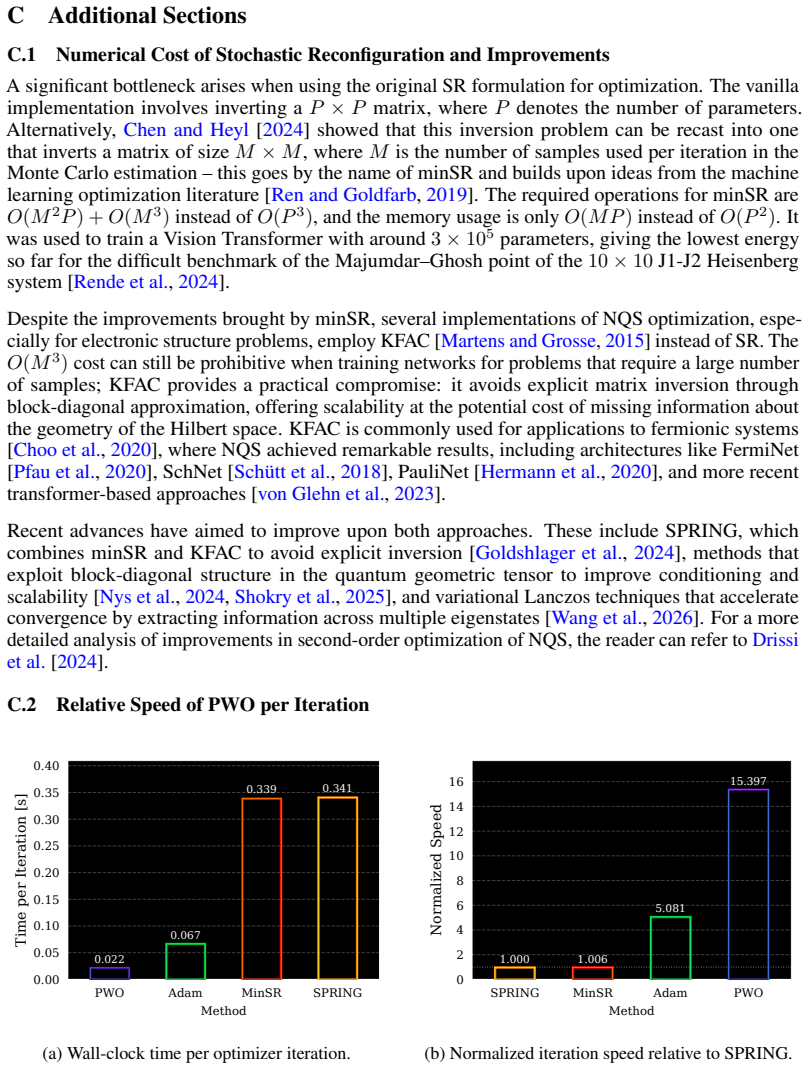
- Sample reuse across multiple updates reduces wall-clock cost while maintaining theoretical guarantees.
- Clipping in separate amplitude and phase channels combines first-order scalability with trust-region safety.
Where Pith is reading between the lines
- If the policy-gradient equivalence holds, analogous trust-region clipping could be applied to other variational Monte Carlo methods that admit exact sampling.
- The demonstrated scaling suggests that autoregressive architectures could be tested on higher-dimensional or frustrated quantum systems previously inaccessible to NQS.
- The separation of amplitude and phase clipping channels may generalize to wavefunction ansatzes where the phase is represented separately from the modulus.
Load-bearing premise
That reframing variational energy minimization as an advantage policy-gradient problem produces a trust-region update that preserves the variational energy bound without introducing uncontrolled bias from the clipping operations.
What would settle it
An experiment in which PWO either fails to improve stability or convergence speed over Adam on the same large-scale Ising instances, or in which the 1.5-billion-parameter model training produces an energy estimate that violates the variational upper bound by more than sampling noise.
Figures
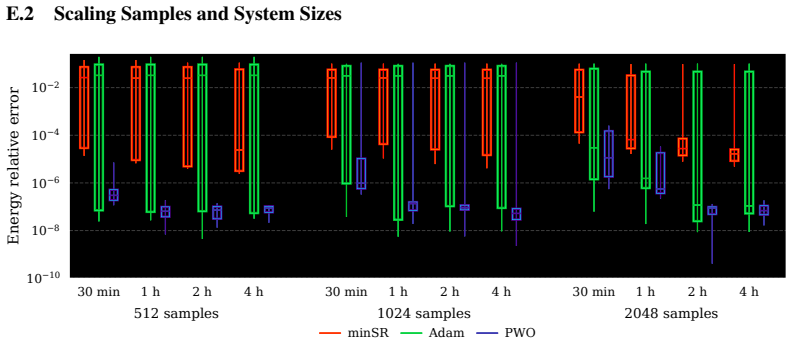
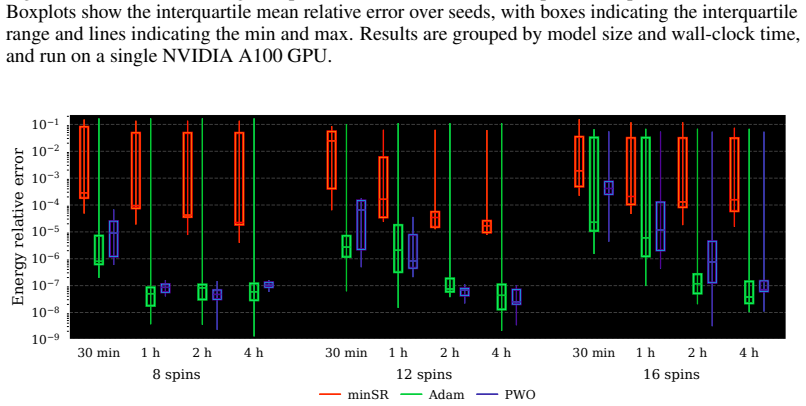
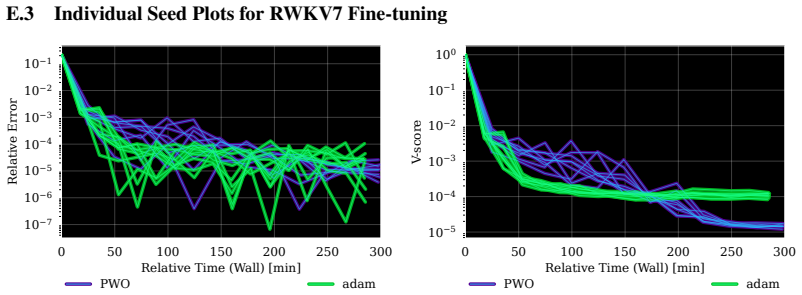
read the original abstract
Neural quantum states (NQS) provide a flexible and scalable framework for approximating quantum many-body wavefunctions. Among NQS parameterizations, autoregressive models are especially attractive because they enable exact, independent sampling from the Born distribution, avoiding the autocorrelation and mixing issues of Markov chain methods. Yet their optimization remains comparatively underexplored: Adam is a scalable method but ignores function space geometry, while stochastic reconfiguration is principled but costly and numerically fragile in large models. To address this gap, we show that variational energy minimization can be viewed as an advantage policy-gradient problem over the Born distribution, motivating trust-region optimization for NQS training. We introduce Proximal Wavefunction Optimization (PWO), a principled trust-region algorithm that clips probability-ratio changes in the amplitude channel and phase increments in the phase channel. PWO avoids explicit matrix inversion, reuses samples across multiple updates, and combines the scalability of first-order optimization with theoretical guarantees. Across Ising and frustrated $J_1$-$J_2$ one- and two-dimensional spin systems, PWO improves stability and wall-clock convergence over Adam, minSR, and SPRING. Finally, we fine-tune a $1.5$B-parameter RWKV-7 model, demonstrating NQS optimization at a scale over three orders of magnitude beyond prior work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reframes variational energy minimization for neural quantum states (NQS) as an advantage policy-gradient problem over the Born distribution and introduces Proximal Wavefunction Optimization (PWO), a trust-region algorithm that applies separate clipping to probability ratios in the amplitude channel and to phase increments. It claims that PWO improves stability and wall-clock convergence over Adam, minSR, and SPRING on Ising and frustrated J1-J2 models in 1D and 2D while enabling optimization of a 1.5B-parameter RWKV-7 model, three orders of magnitude beyond prior NQS work, and states that the method combines first-order scalability with theoretical guarantees.
Significance. If the dual-channel clipping can be shown to preserve the variational upper bound on energy with controlled or vanishing bias, the approach would meaningfully advance scalable, geometry-aware optimization for autoregressive NQS at large parameter counts. The reported scaling to 1.5B parameters and sample reuse across updates would constitute a concrete practical advance if the theoretical grounding holds.
major comments (2)
- [Abstract] Abstract and method description: the claim that PWO supplies 'theoretical guarantees' while using PPO-style clipping on separate amplitude and phase channels is load-bearing for the central contribution, yet no derivation, bias bound, or limit argument is supplied showing that the clipped updates keep the energy estimator above the true ground-state energy or that any introduced bias vanishes.
- [Method (PWO definition)] The weakest assumption identified in the stress test is not addressed: standard PPO clipping is known to bias policy gradients; the manuscript must demonstrate (via an explicit inequality or expectation argument) that the amplitude-ratio clipping plus independent phase clipping does not inject uncontrolled estimator error that violates the variational principle.
minor comments (1)
- [Abstract] The abstract supplies no quantitative results, error bars, hyperparameter values for clipping or sample reuse, or description of the baselines, making the performance claims impossible to assess from the provided text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments both concern the strength of the theoretical claims around PWO's clipping procedure. We address them directly below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the claim that PWO supplies 'theoretical guarantees' while using PPO-style clipping on separate amplitude and phase channels is load-bearing for the central contribution, yet no derivation, bias bound, or limit argument is supplied showing that the clipped updates keep the energy estimator above the true ground-state energy or that any introduced bias vanishes.
Authors: The referee is correct that the manuscript does not contain an explicit derivation or bias bound for the dual-channel clipping. The phrase 'theoretical guarantees' in the abstract and introduction is intended to refer to the fact that PWO inherits the trust-region structure of PPO, which limits policy deviation and reuses samples. However, because amplitude and phase are clipped independently, we do not supply a proof that the variational upper bound on energy is preserved or that bias vanishes. In the revised manuscript we will qualify or remove this phrasing and replace it with a statement that PWO is a practical trust-region method whose bias properties are left for future analysis, consistent with the empirical focus of the work. revision: yes
-
Referee: [Method (PWO definition)] The weakest assumption identified in the stress test is not addressed: standard PPO clipping is known to bias policy gradients; the manuscript must demonstrate (via an explicit inequality or expectation argument) that the amplitude-ratio clipping plus independent phase clipping does not inject uncontrolled estimator error that violates the variational principle.
Authors: No such explicit inequality or expectation argument appears in the current manuscript. We acknowledge that standard PPO clipping introduces bias and that the separate phase clipping adds an additional degree of freedom whose effect on the energy estimator has not been bounded. The paper therefore cannot claim that the variational principle is strictly preserved. In revision we will add a short paragraph in the method section noting this limitation and stating that the algorithm is motivated by PPO but treated as a heuristic whose bias is controlled empirically through the reported stability results. revision: yes
- Deriving a rigorous inequality or expectation argument showing that the dual-channel clipping preserves the variational upper bound without uncontrolled bias.
Circularity Check
No circularity: RL reframing is motivational framing, not a self-referential reduction
full rationale
The paper presents viewing energy minimization as an advantage policy-gradient problem over the Born distribution as a way to motivate the introduction of PWO with trust-region clipping on amplitude and phase channels. No equations, fitted parameters, or self-citations are shown to reduce the claimed stability gains, wall-clock improvements, or scaling results to inputs by construction. The central claims rest on empirical comparisons across Ising and J1-J2 systems plus a large-scale RWKV-7 demonstration, which are independent of the framing. No self-definitional, fitted-input-called-prediction, or load-bearing self-citation patterns appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi:10.4324/9780203769560 , address =
Social Dilemmas: Theoretical Issues and Research Findings , year =. doi:10.4324/9780203769560 , address =
-
[2]
Dawid, Anna and Arnold, Julian and Requena, Borja and Gresch, Alexander and Płodzień, Marcin and Donatella, Kaelan and Nicoli, Kim A. and Stornati, Paolo and Koch, Rouven and Büttner, Miriam and Okuła, Robert and Muñoz-Gil, Gorka and Vargas-Hernández, Rodrigo A. and Cervera-Lierta, Alba and Carrasquilla, Juan and Dunjko, Vedran and Gabrié, Marylou and Hue...
-
[3]
Kearns and Satinder Singh , editor =
Michael J. Kearns and Satinder Singh , editor =. Bias--Variance Error Bounds for Temporal Difference Updates , booktitle =. 2000 , url =
2000
-
[4]
, title =
Nash, John F. , title =. Proceedings of the National Academy of Sciences of the United States of America , volume =. 1950 , doi =
1950
-
[5]
The Annals of Mathematical Statistics , year =
Herbert Robbins and Sutton Monro , title =. The Annals of Mathematical Statistics , year =
-
[6]
Stochastic Games , volume =
Shapley, Lloyd , journal =. Stochastic Games , volume =
-
[7]
Journal of Law and Economics , volume=
The Problem of Social Cost , author=. Journal of Law and Economics , volume=. 1960 , publisher=
1960
-
[8]
Watkins, Christopher J. C. H. and Dayan, Peter , biburl =. Q-learning , url =. Machine Learning , keywords =. doi:10.1007/BF00992698 , interhash =
-
[9]
Simple statistical gradient-following algorithms for connectionist reinforcement learning , volume =
Williams, Ronald , journal =. Simple statistical gradient-following algorithms for connectionist reinforcement learning , volume =
-
[10]
Oxford Economic Papers , year =
Barrett, Scott , title =. Oxford Economic Papers , year =
-
[11]
1996 , journal=
Multiagent reinforcement learning in the Iterated Prisoner's Dilemma , author=. 1996 , journal=
1996
-
[12]
Does voluntary participation undermine the Coase Theorem? , journal =. 2000 , issn =. doi:https://doi.org/10.1016/S0047-2727(99)00089-4 , url =
-
[13]
Proceedings of the National Academy of Sciences , volume=
Iterated Prisoner’s Dilemma contains strategies that dominate any evolutionary opponent , author=. Proceedings of the National Academy of Sciences , volume=. 2012 , publisher=
2012
-
[14]
Solving the quantum many-body problem with artificial neural networks , volume=
Carleo, Giuseppe and Troyer, Matthias , year=. Solving the quantum many-body problem with artificial neural networks , volume=. Science , publisher=. doi:10.1126/science.aag2302 , number=
-
[15]
Social Science Research Network , year =
AI for Global Climate Cooperation: Modeling Global Climate Negotiations, Agreements, and Long-Term Cooperation in RICE-N , author =. Social Science Research Network , year =. doi:10.48550/arXiv.2208.07004 , bibSource =
-
[16]
Machine Intelligence Research , year=
An Empirical Study on Google Research Football Multi-agent Reinforcement Learning , author=. Machine Intelligence Research , year=. doi:10.1007/s11633-023-1426-8 , url=
-
[17]
Empowering deep neural quantum states through efficient optimization , volume=
Chen, Ao and Heyl, Markus , year=. Empowering deep neural quantum states through efficient optimization , volume=. Nature Physics , publisher=. doi:10.1038/s41567-024-02566-1 , number=
-
[18]
2013 , eprint=
Playing Atari with Deep Reinforcement Learning , author=. 2013 , eprint=
2013
-
[19]
2017 , eprint=
Trust Region Policy Optimization , author=. 2017 , eprint=
2017
-
[20]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[21]
2017 , eprint=
Adam: A Method for Stochastic Optimization , author=. 2017 , eprint=
2017
-
[22]
2017 , journal =
Deal or No Deal? End-to-End Learning for Negotiation Dialogues , author =. 2017 , journal =
2017
-
[23]
2018 , eprint=
Maintaining cooperation in complex social dilemmas using deep reinforcement learning , author=. 2018 , eprint=
2018
-
[24]
2018 , eprint=
Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments , author=. 2018 , eprint=
2018
-
[25]
2018 , eprint=
Emergent Communication through Negotiation , author=. 2018 , eprint=
2018
-
[26]
2018 , eprint=
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures , author=. 2018 , eprint=
2018
-
[27]
Learning with Opponent-Learning Awareness
Learning with Opponent-Learning Awareness , author=. arXiv , primaryClass=:1709.04326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
2018 , eprint=
DiCE: The Infinitely Differentiable Monte-Carlo Estimator , author=. 2018 , eprint=
2018
-
[29]
2018 , eprint=
High-Dimensional Continuous Control Using Generalized Advantage Estimation , author=. 2018 , eprint=
2018
-
[30]
Radford, Alec and Narasimhan, Karthik and Salimans, Tim and Sutskever, Ilya , biburl =
-
[31]
2019 , eprint=
Stabilizing Transformers for Reinforcement Learning , author=. 2019 , eprint=
2019
-
[32]
2019 , eprint=
V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete and Continuous Control , author=. 2019 , eprint=
2019
-
[33]
2020 , eprint=
Denoising Diffusion Probabilistic Models , author=. 2020 , eprint=
2020
-
[34]
2021 , eprint=
The AI Economist: Optimal Economic Policy Design via Two-level Deep Reinforcement Learning , author=. 2021 , eprint=
2021
-
[35]
2021 , eprint=
Stable Opponent Shaping in Differentiable Games , author=. 2021 , eprint=
2021
-
[36]
2022 , eprint=
COLA: Consistent Learning with Opponent-Learning Awareness , author=. 2022 , eprint=
2022
-
[37]
2022 , eprint=
Proximal Learning With Opponent-Learning Awareness , author=. 2022 , eprint=
2022
-
[38]
2022 , eprint=
Model-Free Opponent Shaping , author=. 2022 , eprint=
2022
-
[39]
2022 , eprint=
A Generalist Agent , author=. 2022 , eprint=
2022
-
[40]
2023 , eprint=
Melting Pot 2.0 , author=. 2023 , eprint=
2023
-
[41]
2023 , eprint=
Deep Reinforcement Learning for Active High Frequency Trading , author=. 2023 , eprint=
2023
-
[42]
2023 , eprint=
Meta-Value Learning: a General Framework for Learning with Learning Awareness , author=. 2023 , eprint=
2023
-
[43]
2023 , eprint=
Q-learners Can Provably Collude in the Iterated Prisoner's Dilemma , author=. 2023 , eprint=
2023
-
[44]
2024 , eprint=
From Architectures to Applications: A Review of Neural Quantum States , author=. 2024 , eprint=
2024
-
[45]
2024 , eprint=
Best Response Shaping , author=. 2024 , eprint=
2024
-
[46]
2024 , eprint=
LOQA: Learning with Opponent Q-Learning Awareness , author=. 2024 , eprint=
2024
-
[47]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[48]
2024 , eprint=
Dissecting Deep RL with High Update Ratios: Combatting Value Overestimation and Divergence , author=. 2024 , eprint=
2024
-
[49]
2024 , eprint=
Scaling Opponent Shaping to High Dimensional Games , author=. 2024 , eprint=
2024
-
[50]
2025 , eprint=
Advantage Alignment Algorithms , author=. 2025 , eprint=
2025
-
[51]
2025 , eprint=
InvestESG: A multi-agent reinforcement learning benchmark for studying climate investment as a social dilemma , author=. 2025 , eprint=
2025
-
[52]
2025 , eprint=
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks , author=. 2025 , eprint=
2025
-
[53]
1944 , address =
John von Neumann and Oskar Morgenstern , title =. 1944 , address =
1944
-
[54]
1965 , publisher=
Prisoner's Dilemma: A Study in Conflict and Cooperation , author=. 1965 , publisher=
1965
-
[55]
Axelrod, Robert , biburl =
-
[56]
2007 , publisher =
Algorithmic Game Theory , editor =. 2007 , publisher =
2007
-
[57]
2021 , publisher=
Reinforcement Learning: Theory and Algorithms , author=. 2021 , publisher=
2021
-
[58]
Climate Change 2022: Impacts, Adaptation and Vulnerability , editor =. 2022 , publisher =. doi:10.1017/9781009325844 , url =
-
[59]
AAAI Spring Symposia , year=
Toward Natural Turn-Taking in a Virtual Human Negotiation Agent , author=. AAAI Spring Symposia , year=
-
[60]
Valerio Capraro and Joseph Y. Halpern , editor =. Translucent Players: Explaining Cooperative Behavior in Social Dilemmas , booktitle =. 2015 , url =. doi:10.4204/EPTCS.215.9 , timestamp =
-
[61]
Michael Noukhovitch and Travis LaCroix and Angeliki Lazaridou and Aaron C. Courville , editor =. Emergent Communication under Competition , booktitle =. 2021 , url =. doi:10.5555/3463952.3464066 , timestamp =
-
[62]
Proceedings of the 37th International Conference on Machine Learning , pages =
Vezhnevets, Alexander and Wu, Yuhuai and Eckstein, Maria and Leblond, R. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[63]
Proceedings of the 31st International Joint Conference on Artificial Intelligence (IJCAI), Demo Track , year=
Carbon Market Simulation with Adaptive Mechanism Design , author=. Proceedings of the 31st International Joint Conference on Artificial Intelligence (IJCAI), Demo Track , year=
-
[64]
and Niranjan, M
Rummery, G. and Niranjan, M. , biburl =
-
[65]
Atanasova, Hristiana and Bernheimer, Liam and Cohen, Guy , journal =. 2023 , title =. doi:10.1038/s41467-023-39244-4 , pmid =
-
[66]
2018 , eprint=
Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates , author=. 2018 , eprint=
2018
-
[67]
2022 , eprint=
Deep Reinforcement Learning at the Edge of the Statistical Precipice , author=. 2022 , eprint=
2022
-
[68]
2022 , eprint=
Neural network quantum state with proximal optimization: a ground-state searching scheme based on variational Monte Carlo , author=. 2022 , eprint=
2022
-
[69]
2026 , eprint=
Parallel Scan Recurrent Neural Quantum States for Scalable Variational Monte Carlo , author=. 2026 , eprint=
2026
-
[70]
Proceedings of the Nineteenth International Conference on Machine Learning , pages =
Kakade, Sham and Langford, John , title =. Proceedings of the Nineteenth International Conference on Machine Learning , pages =. 2002 , isbn =
2002
-
[71]
Deep learning-enhanced variational Monte Carlo method for quantum many-body physics , volume=
Yang, Li and Leng, Zhaoqi and Yu, Guangyuan and Patel, Ankit and Hu, Wen-Jun and Pu, Han , year=. Deep learning-enhanced variational Monte Carlo method for quantum many-body physics , volume=. Physical Review Research , publisher=. doi:10.1103/physrevresearch.2.012039 , number=
-
[72]
Rende, Riccardo and Viteritti, Luciano Loris and Bardone, Lorenzo and Becca, Federico and Goldt, Sebastian , journal =. 2024 , title =. doi:10.1038/s42005-024-01732-4 , eprint =
-
[73]
Nature communications , volume=
Fermionic neural-network states for ab-initio electronic structure , author=. Nature communications , volume=. 2020 , publisher=
2020
-
[74]
Solving many-electron Schr
Han, Jiequn and Zhang, Linfeng and others , journal=. Solving many-electron Schr. 2019 , publisher=
2019
-
[75]
Physical review letters , volume=
Backflow transformations via neural networks for quantum many-body wave functions , author=. Physical review letters , volume=. 2019 , publisher=
2019
-
[76]
Deep-neural-network solution of the electronic Schr
Hermann, Jan and Sch. Deep-neural-network solution of the electronic Schr. Nature Chemistry , volume=. 2020 , publisher=
2020
-
[77]
Ab initio solution of the many-electron Schr
Pfau, David and Spencer, James S and Matthews, Alexander GDG and Foulkes, W Matthew C , journal=. Ab initio solution of the many-electron Schr. 2020 , publisher=
2020
-
[78]
The Eleventh International Conference on Learning Representations , year=
A Self-Attention Ansatz for Ab-initio Quantum Chemistry , author=. The Eleventh International Conference on Learning Representations , year=
-
[79]
International conference on machine learning , pages=
Optimizing neural networks with kronecker-factored approximate curvature , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[80]
The Journal of chemical physics , volume=
Schnet--a deep learning architecture for molecules and materials , author=. The Journal of chemical physics , volume=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.