Evaluating LLMs' Effectiveness on Real-World Consumer Device Repair Questions
Pith reviewed 2026-06-28 10:04 UTC · model grok-4.3
The pith
LLMs can assist with device repairs but remain unreliable for high-risk tasks like phone fixes without safeguards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
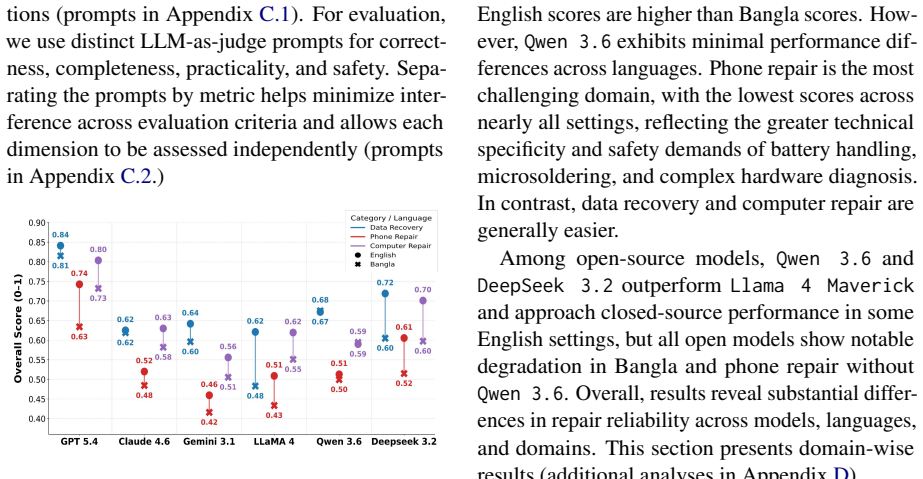
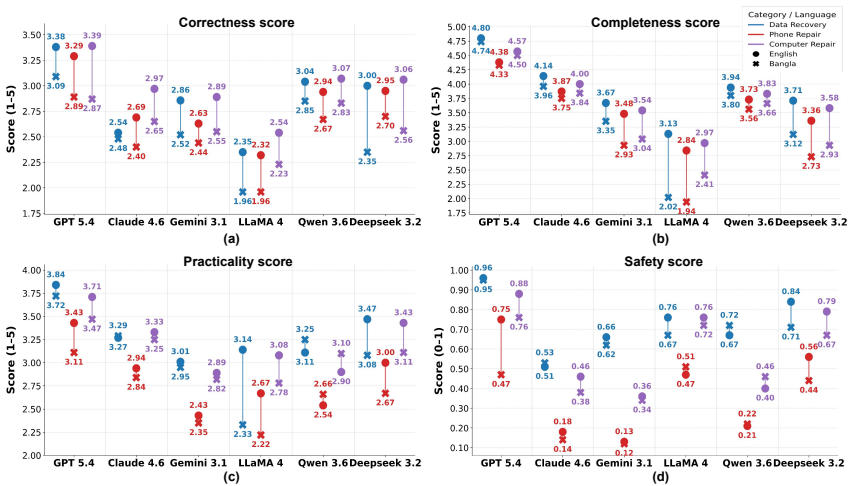
The paper establishes that while LLMs can provide useful repair assistance, they remain unreliable for high-risk real-world repair tasks without rigorous evaluation and explicit safety safeguards. Phone repair is the most difficult and safety-sensitive domain, and all models make substantial errors in board-level diagnosis, repair prioritization, and safe recovery procedures. Across domains and models, Bangla responses consistently perform worse than English responses, with GPT-5.4 performing best overall.
What carries the argument
The benchmark dataset of 991 Reddit questions paired with technician-written reference solutions, evaluated on four repair-specific criteria: correctness, completeness, practicality, and safety.
If this is right
- Phone repair demands more careful model evaluation than computer or data recovery tasks.
- Explicit safety safeguards must be added to LLMs before deployment in repair scenarios.
- English-language performance exceeds Bangla, indicating a need for better multilingual repair training.
- Current models require improvements in hardware-specific diagnostics and recovery procedures.
- Real-world Reddit-sourced questions expose model weaknesses not apparent in standard benchmarks.
Where Pith is reading between the lines
- Adding image or video inputs to the benchmark could better test visual diagnostic capabilities.
- Error patterns identified could inform the creation of targeted safety filters for repair advice.
- Long-term, this benchmark might guide development of specialized repair-assistant models.
- Community feedback from actual repairs could iteratively improve the reference solutions and evaluations.
Load-bearing premise
The 991 Reddit questions paired with technician solutions are representative of real-world consumer device repair challenges, and the four criteria adequately capture the risks of incorrect advice.
What would settle it
Conducting real-world tests where individuals follow LLM repair advice on actual devices and track rates of successful repairs, device damage, or safety incidents versus following the technician references.
Figures

read the original abstract
Consumer device repair is an important but underexplored testbed for large language models (LLMs). Repair tasks require reasoning over incomplete problem descriptions, hardware-specific diagnostics, actionable troubleshooting, and safety-critical decisions, where incorrect advice can cause device damage, battery hazards, or permanent data loss. We introduce a benchmark of 991 real-world repair questions from Reddit spanning phone repair, computer repair, and data recovery, each paired with technician-written reference solutions, and provide Bangla translations to evaluate cross-lingual performance. We evaluate six state-of-the-art LLMs in English and Bangla using four repair-specific criteria: correctness, completeness, practicality, and safety. Our results show that while LLMs can provide useful repair assistance, they remain unreliable for high-risk real-world repair tasks without rigorous evaluation and explicit safety safeguards. Phone repair is the most difficult and safety-sensitive domain, and all models make substantial errors in board-level diagnosis, repair prioritization, and safe recovery procedures. Across domains and models, Bangla responses consistently perform worse than English responses. Among the evaluated models, GPT-5.4 performs best overall.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a benchmark of 991 real-world repair questions sourced from Reddit, spanning phone repair, computer repair, and data recovery, each paired with technician-written reference solutions. It also provides Bangla translations for cross-lingual evaluation. Six state-of-the-art LLMs are evaluated using four criteria: correctness, completeness, practicality, and safety. The results indicate that LLMs can offer useful assistance but are unreliable for high-risk tasks without safeguards, with phone repair being the most difficult and safety-sensitive domain, all models erring in board-level diagnosis and safe procedures, Bangla responses underperforming English ones, and GPT-5.4 performing best.
Significance. If the central findings hold, this work offers a valuable real-world testbed for LLM capabilities in safety-critical consumer support tasks. The use of technician references and multi-criteria evaluation grounded in practical risks provides concrete evidence of current limitations, which could influence the design of domain-specific LLM applications and safety protocols. The cross-lingual component adds to its utility in diverse settings.
major comments (2)
- [§3 (Benchmark Construction)] §3 (Benchmark Construction): The 991 Reddit questions are presented as representative of real-world challenges, but the manuscript provides no comparison of topic distribution, difficulty, or safety exposure to external corpora such as iFixit, manufacturer service logs, or technician surveys. This is load-bearing for the domain-specific claims that phone repair is the hardest domain and that observed error rates in board-level diagnosis reflect true high-risk distributions.
- [§4 (Evaluation Protocol)] §4 (Evaluation Protocol): Details on the scoring process for the four criteria, inter-rater reliability, and validation of the technician-written reference solutions are insufficient. This weakens the evidential support for the unreliability conclusion, as the soundness assessment notes only moderate backing without these elements.
minor comments (2)
- [Results] Ensure tables or figures reporting per-model and per-domain scores include statistical significance tests or confidence intervals to support cross-domain comparisons.
- [Experimental Setup] Clarify the exact model versions and prompting strategies used, as these details affect reproducibility of the English vs. Bangla performance gap.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and have revised the manuscript accordingly to strengthen the evidential basis for our claims.
read point-by-point responses
-
Referee: [§3 (Benchmark Construction)] §3 (Benchmark Construction): The 991 Reddit questions are presented as representative of real-world challenges, but the manuscript provides no comparison of topic distribution, difficulty, or safety exposure to external corpora such as iFixit, manufacturer service logs, or technician surveys. This is load-bearing for the domain-specific claims that phone repair is the hardest domain and that observed error rates in board-level diagnosis reflect true high-risk distributions.
Authors: We acknowledge that external validation against corpora such as iFixit would further support generalizability. Obtaining structured, comparable data from manufacturer logs or technician surveys proved infeasible due to proprietary restrictions and differing categorization schemes. In the revision we have added a new paragraph in §3.2 describing our subreddit sampling strategy (r/phonerepair, r/computerrepair, r/datarecovery) with post counts and temporal distribution, plus a qualitative mapping of the top 20 issue types to publicly available iFixit repair guides. We also inserted an explicit limitations subsection noting that our domain-difficulty rankings are conditioned on the Reddit distribution and may not fully generalize to other sources. These changes are marked in the revised manuscript. revision: partial
-
Referee: [§4 (Evaluation Protocol)] §4 (Evaluation Protocol): Details on the scoring process for the four criteria, inter-rater reliability, and validation of the technician-written reference solutions are insufficient. This weakens the evidential support for the unreliability conclusion, as the soundness assessment notes only moderate backing without these elements.
Authors: We agree that additional protocol details are warranted. The revised §4 now includes: (i) the complete four-criterion rubric with scoring anchors and two worked examples per criterion; (ii) inter-rater statistics—two certified technicians independently scored a random 100-response subset, yielding Cohen’s κ = 0.72 (substantial agreement) on the composite score; and (iii) reference-solution validation steps, including initial drafting by one technician followed by independent review and consensus resolution by a second technician for all 991 items, with 12 % requiring minor clarification. These details, together with the updated Appendix C containing the rubric and agreement table, directly address the concern. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation against external data
full rationale
The paper is a straightforward empirical evaluation of LLMs on a fixed set of 991 Reddit-sourced repair questions paired with independently written technician references. It defines four evaluation criteria (correctness, completeness, practicality, safety) explicitly and reports model performance against those external references. No derivations, fitted parameters, ansatzes, or predictions are present; the central claims rest on direct comparison to the collected data rather than any self-referential construction or self-citation chain. The representativeness concern raised by the skeptic is a validity issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Technician-written solutions accurately represent correct and safe repair procedures for the collected questions.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
The techqa dataset , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[9]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Papers , pages=
Technical question answering across tasks and domains , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Papers , pages=
2021
-
[10]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
DoQA-accessing domain-specific FAQs via conversational QA , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
-
[11]
Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) , year=
PhotoshopQuiA: A corpus of non-factoid questions and answers for why-question answering , author=. Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) , year=
2018
-
[12]
and metadata, metadata, metadata , author=
Preferred answer selection in stack overflow: Better text representations... and metadata, metadata, metadata , author=. Proceedings of the 2018 EMNLP workshop w-NUT: The 4th workshop on noisy user-generated text , pages=
2018
-
[13]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
Empower large language model to perform better on industrial domain-specific question answering , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2023
-
[14]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Question Answering in Climate Adaptation for Agriculture: Model Development and Evaluation with Expert Feedback , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[15]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
CasiMedicos-arg: A medical question answering dataset annotated with explanatory argumentative structures , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[16]
Available at SSRN 4450320 , year=
An Exploratory Analysis of Community-Based Question-Answering Platforms and Gpt-3-Driven Generative Ai: Is it the End of Online Community-Based Learning? , author=. Available at SSRN 4450320 , year=
-
[17]
2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE) , pages=
Large language models for software engineering: Survey and open problems , author=. 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE) , pages=. 2023 , organization=
2023
-
[18]
Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=
Is stack overflow obsolete? an empirical study of the characteristics of chatgpt answers to stack overflow questions , author=. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=
2024
-
[19]
Proceedings of the ACM on Software Engineering , volume=
Chatdbg: Augmenting debugging with large language models , author=. Proceedings of the ACM on Software Engineering , volume=. 2025 , publisher=
2025
-
[20]
Advances in Neural Information Processing Systems , volume=
Stackeval: Benchmarking llms in coding assistance , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Debugbench: Evaluating debugging capability of large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[22]
2024 ieee international conference on prognostics and health management (icphm) , pages=
Generating troubleshooting trees for industrial equipment using large language models (llm) , author=. 2024 ieee international conference on prognostics and health management (icphm) , pages=. 2024 , organization=
2024
-
[23]
2025 International Joint Conference on Neural Networks (IJCNN) , pages=
TechSupportEval: An Automated Evaluation Framework for Technical Support Question Answering , author=. 2025 International Joint Conference on Neural Networks (IJCNN) , pages=. 2025 , organization=
2025
-
[24]
1987 , publisher=
Plans and situated actions: The problem of human-machine communication , author=. 1987 , publisher=
1987
-
[25]
2016 , publisher=
Talking about machines: An ethnography of a modern job , author=. 2016 , publisher=
2016
-
[26]
2007 , publisher=
Human-machine reconfigurations: Plans and situated actions , author=. 2007 , publisher=
2007
-
[27]
Proceedings of the SIGCHI conference on human factors in computing systems , pages=
Breakdown, obsolescence and reuse: HCI and the art of repair , author=. Proceedings of the SIGCHI conference on human factors in computing systems , pages=
-
[28]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
Data Repair , author=. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
2026
-
[29]
Proceedings of the Seventh International Conference on Information and Communication Technologies and Development , pages=
Learning to fix: knowledge, collaboration and mobile phone repair in Dhaka, Bangladesh , author=. Proceedings of the Seventh International Conference on Information and Communication Technologies and Development , pages=
-
[30]
Proceedings of the 2011 iConference , pages=
Things fall apart: maintenance, repair, and technology for education initiatives in rural Namibia , author=. Proceedings of the 2011 iConference , pages=
2011
-
[31]
Proceedings of the ACM 2012 conference on Computer Supported Cooperative Work , pages=
Repair worlds: maintenance, repair, and ICT for development in rural Namibia , author=. Proceedings of the ACM 2012 conference on Computer Supported Cooperative Work , pages=
2012
-
[32]
Proceedings of the seventh international conference on information and communication technologies and development , pages=
Exploring mobile phone and social media use in a Nairobi slum: a case for alternative approaches to design in ICTD , author=. Proceedings of the seventh international conference on information and communication technologies and development , pages=
-
[33]
2019 , publisher=
Apprenticeship in critical ethnographic practice , author=. 2019 , publisher=
2019
-
[34]
1991 , publisher=
Situated learning: Legitimate peripheral participation , author=. 1991 , publisher=
1991
-
[35]
Knowledge in organisations , pages=
The tacit dimension , author=. Knowledge in organisations , pages=. 2009 , publisher=
2009
-
[36]
Inventive infrastructures: an exploration of mobile phone'repair'cultures in Kampala, Uganda , author=
-
[37]
Privacy as contextual integrity , author=. Wash. L. Rev. , volume=. 2004 , publisher=
2004
-
[38]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
Realtoxicityprompts: Evaluating neural toxic degeneration in language models , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
2020
-
[39]
Proceedings of the 2022 CHI conference on human factors in computing systems , pages=
Are deepfakes concerning? analyzing conversations of deepfakes on reddit and exploring societal implications , author=. Proceedings of the 2022 CHI conference on human factors in computing systems , pages=
2022
-
[40]
Papers presented at the May 9-11, 1961, western joint IRE-AIEE-ACM computer conference , pages=
Baseball: an automatic question-answerer , author=. Papers presented at the May 9-11, 1961, western joint IRE-AIEE-ACM computer conference , pages=
1961
-
[41]
Proceedings of the June 4-8, 1973, national computer conference and exposition , pages=
Progress in natural language understanding: an application to lunar geology , author=. Proceedings of the June 4-8, 1973, national computer conference and exposition , pages=
1973
-
[42]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
2023
-
[43]
Proceedings of the fourth ACM international conference on AI in finance , pages=
Large language models in finance: A survey , author=. Proceedings of the fourth ACM international conference on AI in finance , pages=
-
[44]
Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
AI for education (AI4EDU): Advancing personalized education with LLM and adaptive learning , author=. Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[45]
Communications Earth & Environment , volume=
ChatClimate: Grounding conversational AI in climate science , author=. Communications Earth & Environment , volume=. 2023 , publisher=
2023
-
[46]
Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
On the dangers of stochastic parrots: Can language models be too big?�� , author=. Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
2021
-
[48]
Knowledgeable or educated guess? revisiting language models as knowledge bases , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[49]
Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems , pages=
Social inequality and HCI: The view from political economy , author=. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems , pages=
2016
-
[50]
Digital Technology and Sustainability: Embracing the Paradox , year=
Developing a political economy perspective for sustainable HCI , author=. Digital Technology and Sustainability: Embracing the Paradox , year=
-
[51]
Information, Communication & Society , volume=
The data subject and the myth of the ‘black box’data communication and critical data literacy as a resistant practice to platform exploitation , author=. Information, Communication & Society , volume=. 2024 , publisher=
2024
-
[52]
Syed Ishtiaque Ahmed, Steven J Jackson, and Md Rashidujjaman Rifat. 2015. Learning to fix: knowledge, collaboration and mobile phone repair in dhaka, bangladesh. In Proceedings of the Seventh International Conference on Information and Communication Technologies and Development, pages 1--10
2015
-
[53]
Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the dangers of stochastic parrots: Can language models be too big?. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610--623
2021
-
[54]
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, and 1 others. 2021. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258
Pith/arXiv arXiv 2021
-
[55]
Jon Ander Campos, Arantxa Otegi, Aitor Soroa, Jan Milan Deriu, Mark Cieliebak, and Eneko Agirre. 2020. Doqa-accessing domain-specific faqs via conversational qa. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7302--7314
2020
-
[56]
Boxi Cao, Hongyu Lin, Xianpei Han, Le Sun, Lingyong Yan, Meng Liao, Tong Xue, and Jin Xu. 2021. Knowledgeable or educated guess? revisiting language models as knowledge bases. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long...
2021
-
[57]
Vittorio Castelli, Rishav Chakravarti, Saswati Dana, Anthony Ferritto, Radu Florian, Martin Franz, Dinesh Garg, Dinesh Khandelwal, J Scott McCarley, Michael McCawley, and 1 others. 2020. The techqa dataset. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 1269--1278
2020
-
[58]
Bohan Chen, Yongqian Sun, Yuhe Liu, Longlong Xu, Zhe Xie, Changhua Pei, Jing Han, Fan Ni, Xuhui Cai, Ce Yang, and 1 others. 2025. Techsupporteval: An automated evaluation framework for technical support question answering. In 2025 International Joint Conference on Neural Networks (IJCNN), pages 1--8. IEEE
2025
-
[59]
Andrei Dulceanu, Thang Le Dinh, Walter Chang, Trung Bui, Doo Soon Kim, Manh Chien Vu, and Seokhwan Kim. 2018. Photoshopquia: A corpus of non-factoid questions and answers for why-question answering. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018)
2018
-
[60]
Hamid Ekbia and Bonnie Nardi. 2016. Social inequality and hci: The view from political economy. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, pages 4997--5002
2016
-
[61]
Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M Zhang. 2023. Large language models for software engineering: Survey and open problems. In 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE), pages 31--53. IEEE
2023
-
[62]
Dilrukshi Gamage, Piyush Ghasiya, Vamshi Bonagiri, Mark E Whiting, and Kazutoshi Sasahara. 2022. Are deepfakes concerning? analyzing conversations of deepfakes on reddit and exploring societal implications. In Proceedings of the 2022 CHI conference on human factors in computing systems, pages 1--19
2022
-
[63]
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. 2020. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. In Findings of the association for computational linguistics: EMNLP 2020, pages 3356--3369
2020
-
[64]
Bert F Green Jr, Alice K Wolf, Carol Chomsky, and Kenneth Laughery. 1961. Baseball: an automatic question-answerer. In Papers presented at the May 9-11, 1961, western joint IRE-AIEE-ACM computer conference, pages 219--224
1961
-
[65]
Mohammed Mehedi Hasan, Mahady Hasan, and Jannat Un Nayeem. 2023. An exploratory analysis of community-based question-answering platforms and gpt-3-driven generative ai: Is it the end of online community-based learning? Available at SSRN 4450320
2023
-
[66]
Lara Houston. 2013. Inventive infrastructures: an exploration of mobile phone'repair'cultures in kampala, uganda
2013
-
[67]
Steven J Jackson and Laewoo Kang. 2014. Breakdown, obsolescence and reuse: Hci and the art of repair. In Proceedings of the SIGCHI conference on human factors in computing systems, pages 449--458
2014
-
[68]
Steven J Jackson, Alex Pompe, and Gabriel Krieshok. 2011. Things fall apart: maintenance, repair, and technology for education initiatives in rural namibia. In Proceedings of the 2011 iConference, pages 83--90
2011
-
[69]
Steven J Jackson, Alex Pompe, and Gabriel Krieshok. 2012. Repair worlds: maintenance, repair, and ict for development in rural namibia. In Proceedings of the ACM 2012 conference on Computer Supported Cooperative Work, pages 107--116
2012
-
[70]
Samia Kabir, David N Udo-Imeh, Bonan Kou, and Tianyi Zhang. 2024. Is stack overflow obsolete? an empirical study of the characteristics of chatgpt answers to stack overflow questions. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1--17
2024
-
[71]
Jean Lave. 2019. Apprenticeship in critical ethnographic practice. University of Chicago Press
2019
-
[72]
Jean Lave and Etienne Wenger. 1991. Situated learning: Legitimate peripheral participation. Cambridge university press
1991
-
[73]
Kyla H Levin, Nicolas Van Kempen, Emery D Berger, and Stephen N Freund. 2025. Chatdbg: Augmenting debugging with large language models. Proceedings of the ACM on Software Engineering, 2(FSE):1892--1913
2025
-
[74]
Yinheng Li, Shaofei Wang, Han Ding, and Hang Chen. 2023. Large language models in finance: A survey. In Proceedings of the fourth ACM international conference on AI in finance, pages 374--382
2023
-
[75]
Bonnie Nardi and Hamid Ekbia. 2017. Developing a political economy perspective for sustainable hci. Digital Technology and Sustainability: Embracing the Paradox
2017
-
[76]
Dennis Nguyen and Bjorn Beijnon. 2024. The data subject and the myth of the ‘black box’data communication and critical data literacy as a resistant practice to platform exploitation. Information, Communication & Society, 27(2):333--349
2024
-
[77]
Vincent Nguyen, Sarvnaz Karimi, Willow Hallgren, and Mahesh Prakash. 2025. Question answering in climate adaptation for agriculture: Model development and evaluation with expert feedback. In Findings of the Association for Computational Linguistics: ACL 2025, pages 7045--7075
2025
-
[78]
Helen Nissenbaum. 2004. Privacy as contextual integrity. Wash. L. Rev., 79:119
2004
-
[79]
Julian E Orr. 2016. Talking about machines: An ethnography of a modern job. Cornell University Press
2016
-
[80]
Michael Polanyi. 2009. The tacit dimension. In Knowledge in organisations, pages 135--146. Routledge
2009
-
[81]
ATM Mizanur Rahman, Syed Ishtiaque Ahmed, and Sharifa Sultana. 2026. Data repair. In Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems, pages 1--15
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.