The Concept Allocation Zone: Tracking How Concepts Form Across Transformer Depth
Pith reviewed 2026-06-30 12:36 UTC · model grok-4.3
The pith
Concept formation in transformers occurs gradually across depth regions called Concept Allocation Zones rather than at single layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
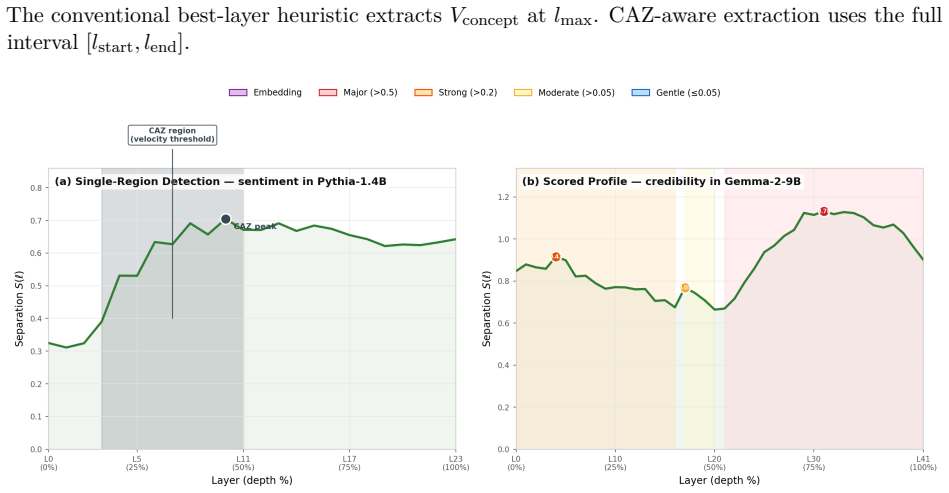
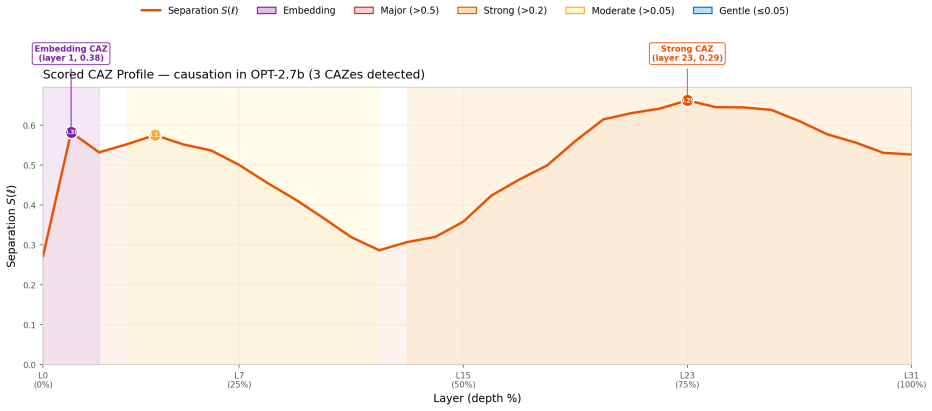
Concept formation is depth-extended: a CAZ is the depth interval within which a concept becomes measurably separable, the region allocated to its geometric expression. The zone is formalized with three layer-wise metrics (Separation, Concept Coherence, Concept Velocity) and principled boundary detection. A single concept typically participates in multiple CAZes; multiple concepts may share one. The separation curve S(l) is frequently multimodal, and a scored detector identifies gentle CAZes that prove causally active in 93-100 percent of ablation cases.
What carries the argument
The Concept Allocation Zone (CAZ), the depth region within which the model organizes its geometry to make a concept separable, identified via the three metrics and scored detector.
If this is right
- A single concept typically participates in multiple CAZes while multiple concepts may share one.
- The separation curve S(l) is frequently multimodal rather than unimodal.
- Gentle CAZes remain causally active in 93-100 percent of cases under ablation despite being invisible to peak detection.
- Cross-architecture alignment of concept formation is depth-matched rather than monolithic under leave-one-concept-out validation.
Where Pith is reading between the lines
- Interpretability work that currently hunts for a single best layer could be extended to search for intervals instead.
- Targeted interventions such as activation patching might need to address entire zones to reliably alter concept expression.
- The depth-matched pattern across architectures suggests it may be possible to predict allocation locations in new models from a small set of reference runs.
Load-bearing premise
The three layer-wise metrics and the scored detector correctly identify causally relevant allocation regions without post-hoc tuning or reliance on peak-only detection.
What would settle it
An experiment that shows ablating the detected CAZ interval changes concept-related model behavior no more than ablating random non-CAZ layers of equal width, or that every concept exhibits a single sharp peak with no extended separable interval.
Figures
read the original abstract
Concept formation in transformer language models is depth-extended, not a single-layer event: concepts emerge gradually across a contiguous region of the residual stream. Mechanistic interpretability methods identify the single layer of peak class separation -- the "best layer" -- capturing a snapshot rather than the process itself. We introduce the Concept Allocation Zone (CAZ): the depth interval within which a concept becomes measurably separable, the region allocated to its geometric expression. We formalize the CAZ through three layer-wise metrics (Separation, Concept Coherence, Concept Velocity) and derive principled boundary detection without manual layer sweeps. A CAZ is not a concept: it is the depth region within which the model organizes its geometry to make a concept separable. A single concept typically participates in multiple CAZes; multiple concepts may share one. Empirical validation across 34 models from 8 architectural families and 7 concepts reveals that the separation curve S(l) is frequently multimodal. A scored detector uncovers "gentle CAZes" -- subtle allocation regions invisible to standard peak detection but causally active in 93-100% of cases under ablation (16 of 34 models; 26 in the companion validation paper). The framework generates seven testable predictions; four yield clear verdicts (two not supported, one partially supported, one supported), one had its precondition invalidated by the data, and two are underpowered -- with cross-architecture alignment confirmed as depth-matched rather than monolithic under leave-one-concept-out cross-validation. Reference implementation: rosetta_tools v1.3.1 (doi:10.5281/zenodo.20361433).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that concept formation in transformer language models occurs across contiguous depth regions of the residual stream rather than at single peak layers. It introduces the Concept Allocation Zone (CAZ) as the interval where a concept becomes measurably separable, formalized via three layer-wise metrics (Separation S(l), Concept Coherence, Concept Velocity) with a scored detector for boundary detection. Empirical results across 34 models from 8 families and 7 concepts show frequently multimodal S(l) curves; the detector identifies 'gentle CAZes' that are causally active under ablation in 93-100% of cases (16 of 34 models), and the framework yields seven testable predictions with mixed support (four clear verdicts, one invalidated precondition, two underpowered), confirming depth-matched cross-architecture alignment.
Significance. If the metrics and detector faithfully locate causally relevant allocation regions, the work would shift mechanistic interpretability from snapshot 'best layer' analysis toward process-level tracking of geometric organization across depth. Strengths include the broad empirical scope (34 models, 8 families), the reference implementation (rosetta_tools v1.3.1), and the balanced reporting of prediction outcomes. The approach could inform architecture comparisons and ablation design if the central methodological assumptions hold.
major comments (3)
- [Abstract / boundary detection] Abstract and methods (boundary detection): The claim that the scored detector provides 'principled' boundary detection 'without manual layer sweeps' and uncovers gentle CAZes requires an explicit, independent definition of the scoring rule, thresholds on Separation/Coherence/Velocity, and how these are set without reference to the same multimodal S(l) curves used to declare multimodality; otherwise the boundary definition risks circularity with the separation data.
- [Results / ablation] Results (ablation validation): The report of 93-100% causal activity for gentle CAZes under ablation (16 of 34 models) is load-bearing for the claim that these regions are 'causally active' rather than artifacts; the manuscript must specify the exact ablation procedure (e.g., whether interventions act on the contiguous CAZ geometry versus individual layers), the 16-model subset selection criteria, and any exclusion rules, as the current description leaves the causal link unverifiable.
- [Framework / predictions] Framework and predictions: The seven testable predictions are evaluated on the same 34 models used to define CAZ boundaries via the three metrics; the manuscript should demonstrate that the predictions (particularly those on multimodality and cross-architecture alignment) are derived independently of the S(l), coherence, and velocity quantities, or clarify how leave-one-concept-out cross-validation avoids fitting to the same separation curves.
minor comments (2)
- [Abstract] The abstract states empirical validation and ablation results but provides no equations for the three metrics or the detector scoring function; the full text should include these definitions early (e.g., as Eq. 1-3) to allow readers to assess the metrics without the companion paper.
- [Results] The mention of '26 in the companion validation paper' for ablation cases should include a clear citation or pointer so the current manuscript stands alone for the 93-100% claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and proposed revisions to improve verifiability and independence of the claims.
read point-by-point responses
-
Referee: [Abstract / boundary detection] Abstract and methods (boundary detection): The claim that the scored detector provides 'principled' boundary detection 'without manual layer sweeps' and uncovers gentle CAZes requires an explicit, independent definition of the scoring rule, thresholds on Separation/Coherence/Velocity, and how these are set without reference to the same multimodal S(l) curves used to declare multimodality; otherwise the boundary definition risks circularity with the separation data.
Authors: We agree that an explicit, independent definition is required to eliminate any risk of circularity. The scoring rule is a fixed composite function of the three normalized metrics with thresholds derived from statistical properties on synthetic null distributions (not from the empirical multimodal curves of the 34 models). We will add the complete mathematical definition, pseudocode, and threshold-setting procedure to the methods section in the revision. revision: yes
-
Referee: [Results / ablation] Results (ablation validation): The report of 93-100% causal activity for gentle CAZes under ablation (16 of 34 models) is load-bearing for the claim that these regions are 'causally active' rather than artifacts; the manuscript must specify the exact ablation procedure (e.g., whether interventions act on the contiguous CAZ geometry versus individual layers), the 16-model subset selection criteria, and any exclusion rules, as the current description leaves the causal link unverifiable.
Authors: We accept that the current description is insufficient for full verifiability. The ablation intervenes on the contiguous CAZ interval by masking the relevant dimensions across all layers in the zone (not single layers). The 16-model subset comprises all models in which the scored detector identified at least one gentle CAZ; exclusion rules (e.g., models lacking sufficient concept-labeled data for stable metric estimation) will be stated explicitly. We will insert a dedicated subsection detailing the procedure, selection criteria, and exclusion rules. revision: yes
-
Referee: [Framework / predictions] Framework and predictions: The seven testable predictions are evaluated on the same 34 models used to define CAZ boundaries via the three metrics; the manuscript should demonstrate that the predictions (particularly those on multimodality and cross-architecture alignment) are derived independently of the S(l), coherence, and velocity quantities, or clarify how leave-one-concept-out cross-validation avoids fitting to the same separation curves.
Authors: The cross-architecture alignment prediction was tested via leave-one-concept-out cross-validation: CAZ boundaries for each held-out concept are computed exclusively from the other six concepts, and alignment is assessed on the held-out concept. This decouples the test from the specific separation curves of the evaluated concept. The multimodality prediction was pre-specified before data collection and is evaluated by direct observation of curve shape frequency. We will add an explicit subsection on prediction pre-specification and the LOOCV procedure to demonstrate independence. revision: partial
Circularity Check
No circularity: CAZ boundaries and predictions are derived from explicit metrics and tested independently
full rationale
The paper defines the CAZ via three layer-wise metrics (Separation, Concept Coherence, Concept Velocity) and states it derives principled boundary detection from them, then generates seven testable predictions that are evaluated on the data. Several predictions are reported as not supported or underpowered, which is incompatible with reduction by construction. Leave-one-concept-out cross-validation is used for the alignment claim. No equations, self-citations, or fitted parameters are shown in the provided text that would make any central result equivalent to its inputs. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
• Arditi, A., Obeso, O., Syed, A., Paleka, D., Panickssery, N., Gurnee, W., & Nanda, N. (2024). Refusal in language models is mediated by a single direction.arXiv preprint arXiv:2406.11717. https://arxiv.org/abs/2406.11717 • Alain, G., & Bengio, Y. (2017). Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644. ht...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
https://www.alignmentforum.org/posts/JvZhhzycHu2Yd57RN/causal-scrubbing-a-method- for-rigorously-testing • Cunningham, H., Ewart, A., Riggs, L., Huben, R., & Sharkey, L. (2023). Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600. https://arxiv.org/abs/2309.08600 23 • Elhage, N., Nanda, N., Olsson, C.,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the- logit-lens •Henry, J. (2026). rosetta_tools (v1.3.1). Zenodo. https://doi.org/10.5281/zenodo.20361433 • Henry, J.(2026). RosettaActivations: Pre-extractedtransformerresidualstreamactivationsfor 33 language models across 17 concepts. HuggingFace. https://huggingface.co/datasets/james- ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.5281/zenodo.20361433 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.