Never Seen Before: Benchmarking Genuine Zero-Shot Composed Image Retrieval with Consistent Video-Sourced Datasets
Pith reviewed 2026-06-27 22:42 UTC · model grok-4.3
The pith
Existing ZS-CIR benchmarks inflate model performance by pairing unrelated images and reusing data that models have already seen.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
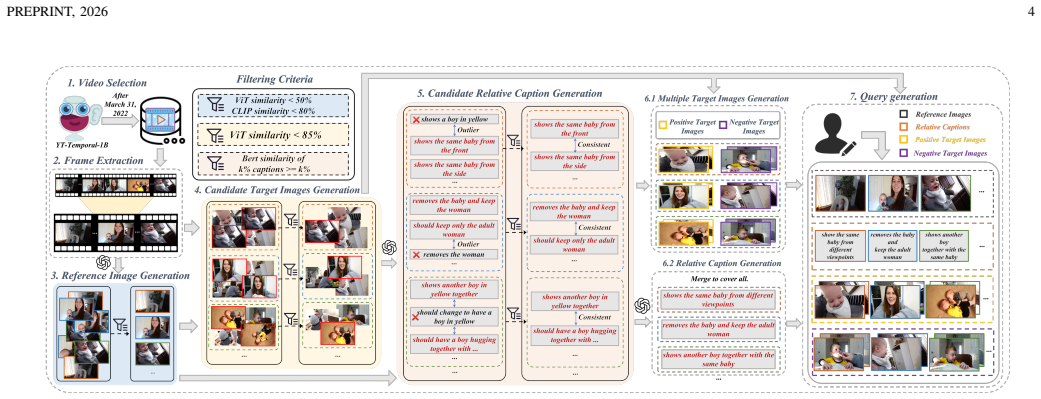
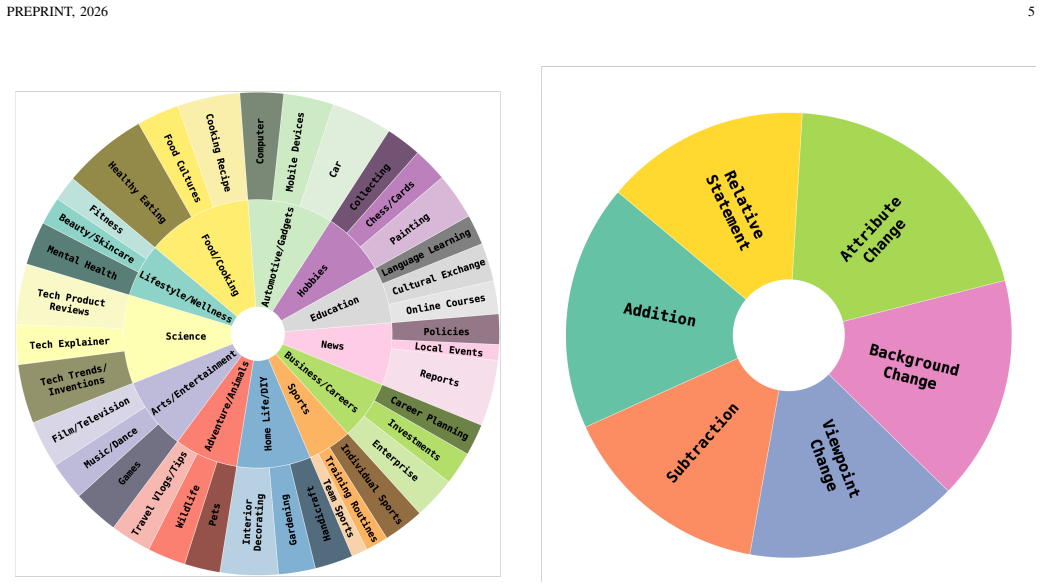
ZeroSight supplies reference-target pairs drawn from single videos published after March 2022, paired with LLM-generated relative captions, together with an evaluation protocol that ranks multiple positives and negatives; under this protocol, existing composed image retrieval methods exhibit substantially lower performance than reported on earlier datasets.
What carries the argument
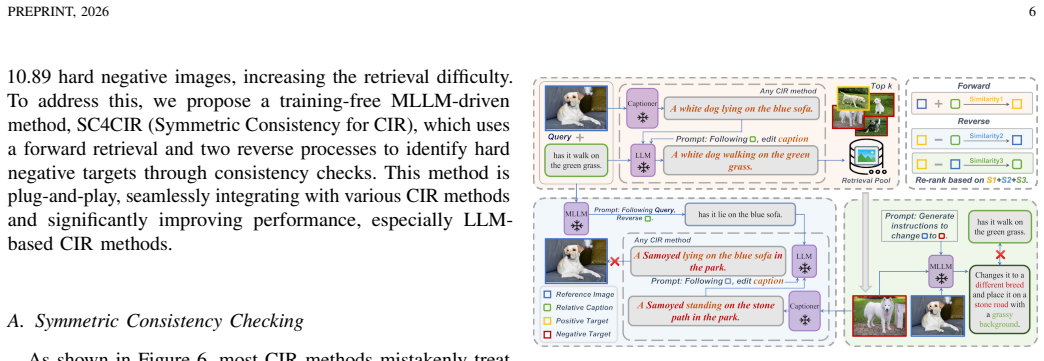
The ZeroSight data pipeline that produces visually and semantically consistent reference-target pairs from frames of one video, combined with the SC4CIR method that applies three symmetric consistency checks inside an MLLM to surface hard negative targets.
If this is right
- Any CIR method claiming strong zero-shot ability must now be re-evaluated on video-sourced pairs that lie outside known pre-training corpora.
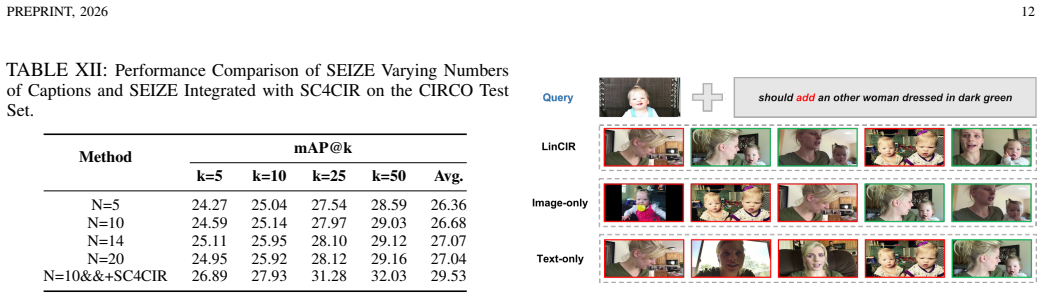
- Plugging SC4CIR into an existing retrieval pipeline raises performance by identifying hard negatives without additional training.
- Evaluation protocols that ignore multiple positive and negative targets overstate true retrieval quality.
- Data construction pipelines that enforce single-video consistency can replace noisy web-sourced pairs in future benchmarks.
Where Pith is reading between the lines
- The same video-frame consistency idea could be applied to other multimodal tasks that need paired examples without manual annotation.
- As new foundation models are released, the March 2022 cutoff will need periodic updates to maintain a true zero-shot regime.
- If single-video pairs prove too easy or too hard, the benchmark could be extended by sampling frames from different but thematically related videos.
Load-bearing premise
Frames taken from a single video automatically form reference-target pairs that are consistent enough to serve as reliable ground truth.
What would settle it
Running the same 27 methods on ZeroSight and observing whether their mean recall or rank metrics fall by a large margin compared with their scores on prior ZS-CIR test sets.
Figures



read the original abstract
Zero-Shot Composed Image Retrieval (ZS-CIR) aims to retrieve a target image based on a query composed of a reference image and a relative caption without training samples. Existing ZS-CIR datasets often suffer from complete irrelevance between reference and target images due to noisy image sources, and do not achieve a true zero-shot scenario as they use public image datasets that models like CLIP have been trained on. To tackle these challenges, we introduce ZeroSight, a novel benchmark for ZS-CIR. It includes a dataset with consistent reference-target pairs sourced from videos, a data construction pipeline, and evaluation methods that consider the ranking of multiple positive and negative target images. We ensure visually and semantically consistent reference-target pairs by extracting frames from a single video and generating relative captions using LLM-assisted methods. To ensure a true zero-shot scenario, we use video data published after March 31, 2022, ensuring it was not included in CLIP's pre-training data. Additionally, we propose a training-free MLLM-driven method, SC4CIR (Symmetric Consistency for CIR), which can effectively identify hard negative targets through 3 symmetric consistency checks. This method is plug-and-play, seamlessly integrating with various CIR methods and significantly improving performance. Our experimental results from 27 methods reveal that current ZS-CIR datasets and evaluation metrics result in inflated retrieval performance, exaggerating the capabilities of CIR methods. Our benchmark and models can be accessed at https://github.com/sotayang/ZeroSight.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing ZS-CIR datasets suffer from irrelevant reference-target pairs and training-data overlap with models like CLIP, leading to inflated performance. It introduces the ZeroSight benchmark consisting of visually and semantically consistent reference-target pairs extracted from single videos published after March 31, 2022 (to ensure zero-shot), LLM-assisted relative captions, and multi-positive/negative ranking evaluation. It also proposes the training-free SC4CIR method that applies three symmetric consistency checks via MLLMs to identify hard negatives and improve existing CIR methods. Experiments across 27 methods are said to confirm the inflation in prior benchmarks.
Significance. If the zero-shot guarantee and pair consistency hold, ZeroSight would offer a stricter, more realistic benchmark for ZS-CIR that could better expose limitations of current methods and metrics. The plug-and-play SC4CIR approach provides a practical, training-free improvement that integrates with existing pipelines.
major comments (3)
- [dataset construction pipeline] Dataset construction (video sourcing and zero-shot claim): the guarantee that post-March 31, 2022 videos lie entirely outside CLIP's pre-training corpus rests only on upload timestamps; this does not rule out archival footage, re-uploads, or earlier web-circulated images, undermining the central 'genuine zero-shot' property required for the inflation claim.
- [experimental results] Experimental results (27-method evaluation): the claim that prior ZS-CIR datasets and metrics inflate performance is presented without quantitative tables, error bars, per-method breakdowns, or ablation details on the new benchmark, making the evidence for the central claim uninspectable and unverifiable.
- [data construction pipeline] Pair consistency validation: while same-video frame extraction ensures visual proximity, the paper provides no quantitative measure (e.g., CLIP similarity distributions or human validation scores) confirming that the LLM-generated relative captions produce semantically consistent reference-target pairs at the level needed to serve as reliable ground truth.
minor comments (2)
- [abstract and experiments] The abstract states results across 27 methods but the main text should include at least one summary table of retrieval metrics (e.g., R@K) on ZeroSight versus prior datasets to support the inflation claim.
- [SC4CIR method] Notation for the three symmetric consistency checks in SC4CIR could be formalized with equations rather than prose description to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening our claims on the zero-shot property, experimental transparency, and pair consistency. We address each major comment below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [dataset construction pipeline] Dataset construction (video sourcing and zero-shot claim): the guarantee that post-March 31, 2022 videos lie entirely outside CLIP's pre-training corpus rests only on upload timestamps; this does not rule out archival footage, re-uploads, or earlier web-circulated images, undermining the central 'genuine zero-shot' property required for the inflation claim.
Authors: We agree that upload timestamps alone cannot provide an absolute guarantee against archival footage, re-uploads, or earlier circulation. Our selection prioritized videos uploaded after the cutoff from sources likely to contain original recent content (e.g., new events or user-generated material), which substantially lowers overlap risk relative to static public datasets. In revision we will add: (i) explicit details on selection heuristics, (ii) results of reverse-image-search spot checks on a sampled subset to detect pre-2022 matches, and (iii) a dedicated limitations paragraph acknowledging that exhaustive verification remains impractical. These steps mitigate but do not eliminate the concern. revision: partial
-
Referee: [experimental results] Experimental results (27-method evaluation): the claim that prior ZS-CIR datasets and metrics inflate performance is presented without quantitative tables, error bars, per-method breakdowns, or ablation details on the new benchmark, making the evidence for the central claim uninspectable and unverifiable.
Authors: The referee is correct that the initial submission did not make the supporting numbers sufficiently accessible. The full manuscript reports results across 27 methods, yet we will expand the experimental section in revision to include: full per-method tables comparing ZeroSight against prior benchmarks, standard-error bars from repeated evaluations where stochasticity exists, and ablations isolating the contribution of multi-positive ranking and SC4CIR. This will render the inflation claim directly verifiable. revision: yes
-
Referee: [data construction pipeline] Pair consistency validation: while same-video frame extraction ensures visual proximity, the paper provides no quantitative measure (e.g., CLIP similarity distributions or human validation scores) confirming that the LLM-generated relative captions produce semantically consistent reference-target pairs at the level needed to serve as reliable ground truth.
Authors: We concur that quantitative validation is necessary to establish the benchmark's reliability. In the revised manuscript we will add: (i) CLIP similarity distributions comparing reference-target pairs against random and cross-video controls, and (ii) a human validation study on a statistically meaningful random sample, reporting inter-annotator agreement and consistency scores. These metrics will directly support the claim that the extracted pairs constitute reliable ground truth. revision: yes
Circularity Check
No significant circularity; benchmark built from external sources
full rationale
The paper constructs ZeroSight from post-March 2022 videos and off-the-shelf MLLMs for relative captions, then evaluates 27 existing methods on it. No equations, fitted parameters, or self-citations reduce the reported performance inflation claim to quantities defined inside the paper itself. The date-based zero-shot guarantee is an external assumption (not a self-referential derivation), and the central experimental result compares against independent prior methods and datasets.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Frames from a single video yield visually and semantically consistent reference-target pairs suitable for ground-truth construction.
- domain assumption Video data published after March 31, 2022 was absent from CLIP pre-training corpora.
Forward citations
Cited by 1 Pith paper
-
LiveStarPro: Proactive Streaming Video Understanding with Hierarchical Memory for Long-Horizon Streams
LiveStarPro uses SVeD for response timing via perplexity, SCAM for incremental alignment, and TSHM for event-chain memory to achieve 28.9% better semantic correctness and 1.58x speedup on long video streams.
Reference graph
Works this paper leans on
-
[1]
Heterogeneous feature fusion and cross-modal alignment for composed image retrieval,
G. Zhang, S. Wei, H. Pang, and Y . Zhao, “Heterogeneous feature fusion and cross-modal alignment for composed image retrieval,” inProceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 5353–5362
2021
-
[2]
Effective conditioned and composed image retrieval combining clip-based features,
A. Baldrati, M. Bertini, T. Uricchio, and A. Del Bimbo, “Effective conditioned and composed image retrieval combining clip-based features,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 21 466–21 474
2022
-
[3]
Target-guided composed image retrieval,
H. Wen, X. Zhang, X. Song, Y . Wei, and L. Nie, “Target-guided composed image retrieval,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 915–923
2023
-
[4]
Self-training boosted multi-factor matching network for composed image retrieval,
H. Wen, X. Song, J. Yin, J. Wu, W. Guan, and L. Nie, “Self-training boosted multi-factor matching network for composed image retrieval,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 5, pp. 3665–3678, 2023. PREPRINT, 2026 15
2023
-
[5]
Pic2word: Mapping pictures to words for zero-shot composed image retrieval,
K. Saito, K. Sohn, X. Zhang, C.-L. Li, C.-Y . Lee, K. Saenko, and T. Pfister, “Pic2word: Mapping pictures to words for zero-shot composed image retrieval,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 305–19 314
2023
-
[6]
Zero- shot composed image retrieval with textual inversion,
A. Baldrati, L. Agnolucci, M. Bertini, and A. Del Bimbo, “Zero- shot composed image retrieval with textual inversion,”arXiv preprint arXiv:2303.15247, 2023
arXiv 2023
-
[7]
Y . Tang, J. Yu, K. Gai, Z. Jiamin, G. Xiong, Y . Hu, and Q. Wu, “Context- i2w: Mapping images to context-dependent words for accurate zero-shot composed image retrieval,”arXiv preprint arXiv:2309.16137, 2023
arXiv 2023
-
[8]
Image retrieval on real-life images with pre-trained vision-and-language models,
Z. Liu, C. Rodriguez-Opazo, D. Teney, and S. Gould, “Image retrieval on real-life images with pre-trained vision-and-language models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 2125–2134
2021
-
[9]
Genecis: A benchmark for general con- ditional image similarity,
S. Vaze, N. Carion, and I. Misra, “Genecis: A benchmark for general con- ditional image similarity,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6862–6872
2023
-
[10]
Fashion iq: A new dataset towards retrieving images by natural language feedback,
H. Wu, Y . Gao, X. Guo, Z. Al-Halah, S. Rennie, K. Grauman, and R. Feris, “Fashion iq: A new dataset towards retrieving images by natural language feedback,” inProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, 2021, pp. 11 307–11 317
2021
-
[11]
Data roaming and quality assessment for composed image retrieval,
M. Levy, R. Ben-Ari, N. Darshan, and D. Lischinski, “Data roaming and quality assessment for composed image retrieval,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 4, pp. 2991–2999, Mar. 2024. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/28081
2024
-
[12]
Dual compositional learning in interactive image retrieval,
J. Kim, Y . Yu, H. Kim, and G. Kim, “Dual compositional learning in interactive image retrieval,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 2, 2021, pp. 1771–1779
2021
-
[13]
Visual compositional learning for human-object interaction detection,
Z. Hou, X. Peng, Y . Qiao, and D. Tao, “Visual compositional learning for human-object interaction detection,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XV 16. Springer, 2020, pp. 584–600
2020
-
[14]
Leveraging large vision-language model as user intent-aware encoder for composed image retrieval,
Z. Sun, D. Jing, G. Yang, N. Fei, and Z. Lu, “Leveraging large vision-language model as user intent-aware encoder for composed image retrieval,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 7, 2025, pp. 7149–7157
2025
-
[15]
Ccin: Compositional conflict identification and neutralization for composed image retrieval
L. Tian, J. Zhao, Z. Hu, Z. Yang, H. Li, L. Jin, Z. Wang, and X. Li, “Ccin: Compositional conflict identification and neutralization for composed image retrieval.”
-
[16]
Covr: Learning composed video retrieval from web video captions,
L. Ventura, A. Yang, C. Schmid, and G. Varol, “Covr: Learning composed video retrieval from web video captions,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 6, 2024, pp. 5270–5279
2024
-
[17]
Bi-directional training for composed image retrieval via text prompt learning,
Z. Liu, W. Sun, Y . Hong, D. Teney, and S. Gould, “Bi-directional training for composed image retrieval via text prompt learning,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 5753–5762
2024
-
[18]
Sentence-level prompts benefit composed image retrieval,
X. Xu, Y . Liu, S. Khan, F. Khan, W. Zuo, R. S. M. Goh, C.-M. Feng et al., “Sentence-level prompts benefit composed image retrieval,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[19]
Dynamic bit-wise semantic transformer hashing for multi-modal retrieval,
W. Tan, F. Li, L. Zhu, W. Guan, J. Li, Z. Cheng, and H. T. Shen, “Dynamic bit-wise semantic transformer hashing for multi-modal retrieval,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[20]
Fashion retrieval via graph reasoning networks on a similarity pyramid,
Y . Gao, Z. Kuang, G. Li, P. Luo, Y . Chen, L. Lin, and W. Zhang, “Fashion retrieval via graph reasoning networks on a similarity pyramid,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 6, pp. 7019–7034, 2020
2020
-
[21]
Multilin- gual text-to-image person retrieval via bidirectional relation reasoning and aligning,
M. Cao, X. Zhou, D. Jiang, B. Du, M. Ye, and M. Zhang, “Multilin- gual text-to-image person retrieval via bidirectional relation reasoning and aligning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[22]
A corpus of natural language for visual reasoning,
A. Suhr, M. Lewis, J. Yeh, and Y . Artzi, “A corpus of natural language for visual reasoning,” inProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 2017, pp. 217–223
2017
-
[23]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer, 2014, pp. 740–755
2014
-
[24]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
2009
-
[25]
“this is my unicorn, fluffy
N. Cohen, R. Gal, E. A. Meirom, G. Chechik, and Y . Atzmon, ““this is my unicorn, fluffy”: Personalizing frozen vision-language representations,” in European Conference on Computer Vision. Springer, 2022, pp. 558–577
2022
-
[26]
Language-only efficient training of zero-shot composed image retrieval,
G. Gu, S. Chun, W. Kim, Y . Kang, and S. Yun, “Language-only efficient training of zero-shot composed image retrieval,”arXiv preprint arXiv:2312.01998, 2023
arXiv 2023
-
[27]
Vision-by- language for training-free compositional image retrieval,
S. Karthik, K. Roth, M. Mancini, and Z. Akata, “Vision-by- language for training-free compositional image retrieval,”arXiv preprint arXiv:2310.09291, 2023
arXiv 2023
-
[28]
Ldre: Llm-based divergent reasoning and ensemble for zero-shot composed image retrieval,
Z. Yang, D. Xue, S. Qian, W. Dong, and C. Xu, “Ldre: Llm-based divergent reasoning and ensemble for zero-shot composed image retrieval,” inProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, pp. 80–90
2024
-
[29]
Semantic editing increment benefits zero-shot composed image retrieval,
Z. Yang, S. Qian, D. Xue, J. Wu, F. Yang, W. Dong, and C. Xu, “Semantic editing increment benefits zero-shot composed image retrieval,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 1245–1254
2024
-
[30]
Mllm-i2w: Harnessing multimodal large language model for zero-shot composed image retrieval,
T. Bao, C. Liu, D. Xu, Z. Zheng, and T. Xu, “Mllm-i2w: Harnessing multimodal large language model for zero-shot composed image retrieval,” inProceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 1839–1849
2025
-
[31]
Generative zero-shot composed image retrieval
L. Wang, W. Ao, V . N. Boddeti, and S.-N. Lim, “Generative zero-shot composed image retrieval.”
-
[32]
Active supervised cross- modal retrieval,
H. Zhang, Y . Yang, F. Qi, S. Qian, and C. Xu, “Active supervised cross- modal retrieval,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[33]
Prvr: Partially relevant video retrieval,
X. Chen, D. Liu, X. Yang, X. Li, J. Dong, M. Wang, and X. Wang, “Prvr: Partially relevant video retrieval,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[34]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[35]
Laion- 5b: An open large-scale dataset for training next generation image-text models,
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsmanet al., “Laion- 5b: An open large-scale dataset for training next generation image-text models,”Advances in Neural Information Processing Systems, vol. 35, pp. 25 278–25 294, 2022
2022
-
[36]
Datacomp: In search of the next generation of multimodal datasets,
S. Y . Gadre, G. Ilharco, A. Fang, J. Hayase, G. Smyrnis, T. Nguyen, R. Marten, M. Wortsman, D. Ghosh, J. Zhanget al., “Datacomp: In search of the next generation of multimodal datasets,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[37]
Wit: Wikipedia-based image text dataset for multimodal multilingual machine learning,
K. Srinivasan, K. Raman, J. Chen, M. Bendersky, and M. Najork, “Wit: Wikipedia-based image text dataset for multimodal multilingual machine learning,” inProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval, 2021, pp. 2443– 2449
2021
-
[38]
Pali: A jointly-scaled multilingual language-image model,
X. Chen, X. Wang, S. Changpinyo, A. Piergiovanni, P. Padlewski, D. Salz, S. Goodman, A. Grycner, B. Mustafa, L. Beyeret al., “Pali: A jointly-scaled multilingual language-image model,”arXiv preprint arXiv:2209.06794, 2022
Pith/arXiv arXiv 2022
-
[39]
A. Fang, A. M. Jose, A. Jain, L. Schmidt, A. Toshev, and V . Shankar, “Data filtering networks,”arXiv preprint arXiv:2309.17425, 2023
arXiv 2023
-
[40]
Composing text and image for image retrieval-an empirical odyssey,
N. V o, L. Jiang, C. Sun, K. Murphy, L.-J. Li, L. Fei-Fei, and J. Hays, “Composing text and image for image retrieval-an empirical odyssey,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 6439–6448
2019
-
[41]
Image search with text feedback by visiolinguistic attention learning,
Y . Chen, S. Gong, and L. Bazzani, “Image search with text feedback by visiolinguistic attention learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3001–3011
2020
-
[42]
Image search with text feedback by deep hierarchical attention mutual information maximization,
C. Gu, J. Bu, Z. Zhang, Z. Yu, D. Ma, and W. Wang, “Image search with text feedback by deep hierarchical attention mutual information maximization,” inProceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 4600–4609
2021
-
[43]
Cosmo: Content-style modulation for image retrieval with text feedback,
S. Lee, D. Kim, and B. Han, “Cosmo: Content-style modulation for image retrieval with text feedback,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 802–812
2021
-
[44]
Zero-shot composed text-image retrieval,
Y . Liu, J. Yao, Y . Zhang, Y . Wang, and W. Xie, “Zero-shot composed text-image retrieval,”arXiv preprint arXiv:2306.07272, 2023
arXiv 2023
-
[45]
isearle: Improving textual inversion for zero-shot composed image retrieval,
L. Agnolucci, A. Baldrati, A. Del Bimbo, and M. Bertini, “isearle: Improving textual inversion for zero-shot composed image retrieval,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[46]
Towards codebook-free deep probabilistic quantization for image retrieval,
M. Wang, W. Zhou, X. Yao, Q. Tian, and H. Li, “Towards codebook-free deep probabilistic quantization for image retrieval,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 1, pp. 626–640, 2023
2023
-
[47]
Mixture of subspaces image representation and compact coding for large-scale image retrieval,
T. Takahashi and T. Kurita, “Mixture of subspaces image representation and compact coding for large-scale image retrieval,”IEEE transactions on PREPRINT, 2026 16 pattern analysis and machine intelligence, vol. 37, no. 7, pp. 1469–1479, 2014
2026
-
[48]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,”arXiv preprint arXiv:1810.04805, 2018
Pith/arXiv arXiv 2018
-
[49]
Uniter: Universal image-text representation learning,
Y .-C. Chen, L. Li, L. Yu, A. El Kholy, F. Ahmed, Z. Gan, Y . Cheng, and J. Liu, “Uniter: Universal image-text representation learning,” in European conference on computer vision. Springer, 2020, pp. 104–120
2020
-
[50]
Visualbert: A simple and performant baseline for vision and language,
L. H. Li, M. Yatskar, D. Yin, C.-J. Hsieh, and K.-W. Chang, “Visualbert: A simple and performant baseline for vision and language,”arXiv preprint arXiv:1908.03557, 2019
Pith/arXiv arXiv 1908
-
[51]
Oscar: Object-semantics aligned pre-training for vision-language tasks,
X. Li, X. Yin, C. Li, P. Zhang, X. Hu, L. Zhang, L. Wang, H. Hu, L. Dong, F. Weiet al., “Oscar: Object-semantics aligned pre-training for vision-language tasks,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX
2020
-
[52]
Springer, 2020, pp. 121–137
2020
-
[53]
Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,
J. Lu, D. Batra, D. Parikh, and S. Lee, “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[54]
Lxmert: Learning cross-modality encoder representations from transformers,
H. Tan and M. Bansal, “Lxmert: Learning cross-modality encoder representations from transformers,”arXiv preprint arXiv:1908.07490, 2019
arXiv 1908
-
[55]
Optimization of rank losses for image retrieval,
E. Ramzi, N. Audebert, C. Rambour, A. Araujo, X. Bitot, and N. Thome, “Optimization of rank losses for image retrieval,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[56]
Attack as defense: Proactive adversarial multi-modal learning to evade retrieval,
F. Li, T. Wang, L. Zhu, J. Li, and H. T. Shen, “Attack as defense: Proactive adversarial multi-modal learning to evade retrieval,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[57]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[58]
Conditioned and composed image retrieval combining and partially fine-tuning clip-based features,
A. Baldrati, M. Bertini, T. Uricchio, and A. Del Bimbo, “Conditioned and composed image retrieval combining and partially fine-tuning clip-based features,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4959–4968
2022
-
[59]
Fame-vil: Multi-tasking vision-language model for heterogeneous fashion tasks,
X. Han, X. Zhu, L. Yu, L. Zhang, Y .-Z. Song, and T. Xiang, “Fame-vil: Multi-tasking vision-language model for heterogeneous fashion tasks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2669–2680
2023
-
[60]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[61]
Llama: Open and efficient foundation language models,
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[62]
Svbench: A benchmark with temporal multi-turn dialogues for streaming video understanding,
Z. Yang, Y . Hu, Z. Du, D. Xue, S. Qian, J. Wu, F. Yang, W. Dong, and C. Xu, “Svbench: A benchmark with temporal multi-turn dialogues for streaming video understanding,” inThe Thirteenth International Conference on Learning Representations
-
[63]
Livestar: Live streaming assistant for real-world online video understanding,
Z. Yang, K. Zhang, Y . Hu, B. Wang, S. Qian, B. Wen, F. Yang, T. Gao, W. Dong, and C. Xu, “Livestar: Live streaming assistant for real-world online video understanding,”Advances in Neural Information Processing Systems, vol. 38, pp. 31 266–31 304, 2026
2026
-
[64]
Querystream: Advancing streaming video understanding with query-aware pruning and proactive response,
K. Zhang, Z. Yang, B. Wang, S. Qian, and C. Xu, “Querystream: Advancing streaming video understanding with query-aware pruning and proactive response,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[65]
Gemini: a family of highly capable multimodal models,
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gemini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[66]
Reason-before-retrieve: One-stage reflective chain- of-thoughts for training-free zero-shot composed image retrieval,
Y . Tang, J. Zhang, X. Qin, J. Yu, G. Gou, G. Xiong, Q. Lin, S. Rajmohan, D. Zhang, and Q. Wu, “Reason-before-retrieve: One-stage reflective chain- of-thoughts for training-free zero-shot composed image retrieval,” in Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 14 400–14 410
2025
-
[67]
Merlot reserve: Neural script knowledge through vision and language and sound,
R. Zellers, J. Lu, X. Lu, Y . Yu, Y . Zhao, M. Salehi, A. Kusupati, J. Hessel, A. Farhadi, and Y . Choi, “Merlot reserve: Neural script knowledge through vision and language and sound,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 375–16 387
2022
-
[68]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[69]
Vision-by-language for training-free compositional image retrieval,
S. Karthik, K. Roth, M. Mancini, and Z. Akata, “Vision-by-language for training-free compositional image retrieval,”International Conference on Learning Representations (ICLR), 2024
2024
-
[70]
"this is my unicorn, fluffy
N. Cohen, R. Gal, E. A. Meirom, G. Chechik, and Y . Atzmon, “"this is my unicorn, fluffy": Personalizing frozen vision-language representations,” inEuropean Conference on Computer Vision (ECCV), 2022
2022
-
[71]
isearle: Improving textual inversion for zero-shot composed image retrieval,
L. Agnolucci, A. Baldrati, M. Bertini, and A. Del Bimbo, “isearle: Improving textual inversion for zero-shot composed image retrieval,” arXiv preprint arXiv:2405.02951, 2024
arXiv 2024
-
[72]
Language-only training of zero-shot composed image retrieval,
G. Gu, S. Chun, W. Kim, , Y . Kang, and S. Yun, “Language-only training of zero-shot composed image retrieval,” inConference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[73]
Artemis: Attention-based retrieval with text-explicit matching and implicit similar- ity,
G. Delmas, R. S. de Rezende, G. Csurka, and D. Larlus, “Artemis: Attention-based retrieval with text-explicit matching and implicit similar- ity,”arXiv preprint arXiv:2203.08101, 2022
arXiv 2022
-
[74]
Amc: Adaptive multi-expert collaborative network for text-guided image retrieval,
H. Zhu, Y . Wei, Y . Zhao, C. Zhang, and S. Huang, “Amc: Adaptive multi-expert collaborative network for text-guided image retrieval,” ACM Transactions on Multimedia Computing, Communications and Applications, 2023
2023
-
[75]
Modality- agnostic attention fusion for visual search with text feedback,
E. Dodds, J. Culpepper, S. Herdade, Y . Zhang, and K. Boakye, “Modality- agnostic attention fusion for visual search with text feedback,”arXiv preprint arXiv:2007.00145, 2020
arXiv 2007
-
[76]
Dynamic weighted combiner for mixed-modal image retrieval,
F. Huang, L. Zhang, X. Fu, and S. Song, “Dynamic weighted combiner for mixed-modal image retrieval,” inAssociation for the Advance of Artificial Intelligence (AAAI), 2024
2024
-
[77]
Composed image retrieval using contrastive learning and task-oriented clip-based features,
A. Baldrati, M. Bertini, T. Uricchio, and A. D. Bimbo, “Composed image retrieval using contrastive learning and task-oriented clip-based features,”ACM Transactions on Multimedia Computing, Communications and Applications
-
[78]
Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.