Single-Channel EEG-Based Cognitive Load Assessment in Online Learning: A Hybrid Deep Learning Approach
Pith reviewed 2026-07-03 17:20 UTC · model grok-4.3
The pith
A hybrid CNN-LSTM-Attention model on single-channel EEG data reaches 78.5 percent accuracy distinguishing easy from difficult online learning videos within subjects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
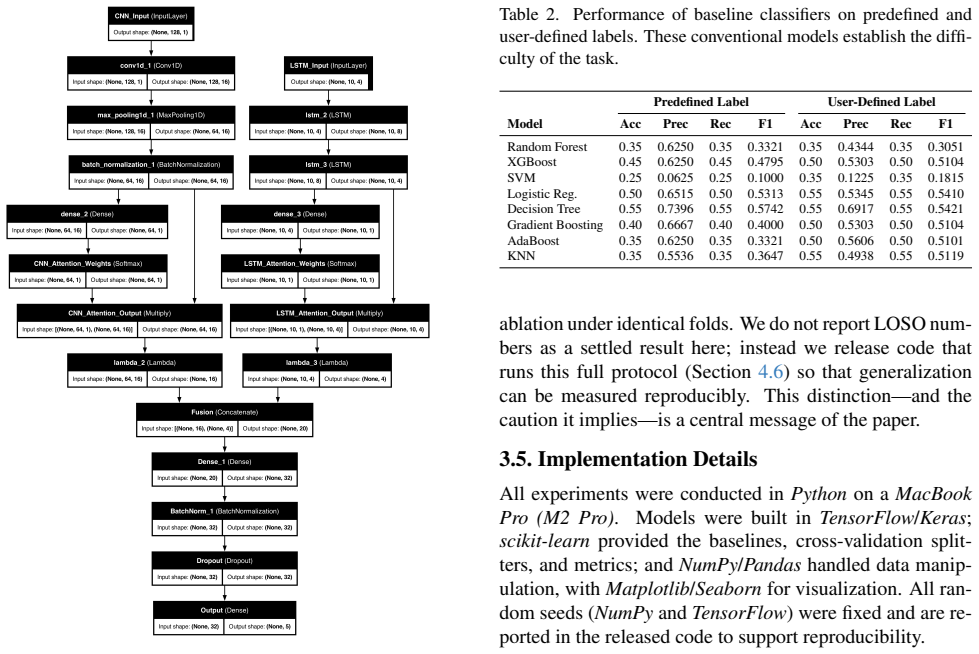
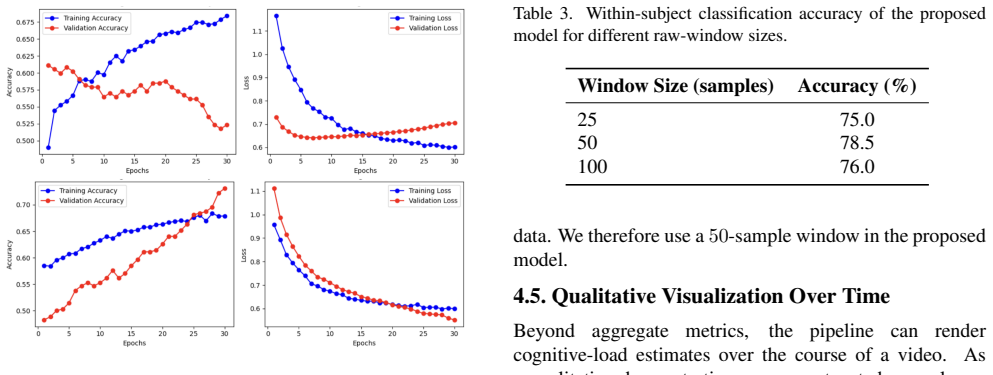
A hybrid CNN+LSTM+Attention architecture that ingests both the raw EEG waveform and its band-power features can separate low from high cognitive load states induced by easy versus difficult video segments, attaining up to 78.5 percent accuracy in within-subject evaluation after dropout and L2 regularization stabilize training.
What carries the argument
The hybrid CNN+LSTM+Attention model that fuses raw waveform input with band-power features.
If this is right
- Instructors could locate difficult segments in video lessons by overlaying model outputs on the timeline.
- Consumer-grade single-channel headsets become viable for remote cognitive-load monitoring without laboratory equipment.
- Regularization closes the train-validation gap on small EEG datasets and keeps accuracy stable near 68-73 percent.
- An open reproducible pipeline allows direct comparison of future models under subject-independent protocols.
Where Pith is reading between the lines
- Larger multi-subject datasets or transfer-learning techniques will be needed before subject-independent accuracy approaches the reported within-subject numbers.
- The same architecture could be tested on other single-channel biosignals such as forehead ECG or ear-worn sensors for cognitive monitoring.
- Integration with existing video platforms would let the heatmap tool run automatically during live sessions.
Load-bearing premise
Performance measured when the same learners contribute data to both training and test sets will hold when entirely new learners are tested.
What would settle it
Running the released pipeline in a subject-independent split on the same nine-subject dataset yields accuracy no higher than the 55 percent baseline of conventional classifiers.
Figures

read the original abstract
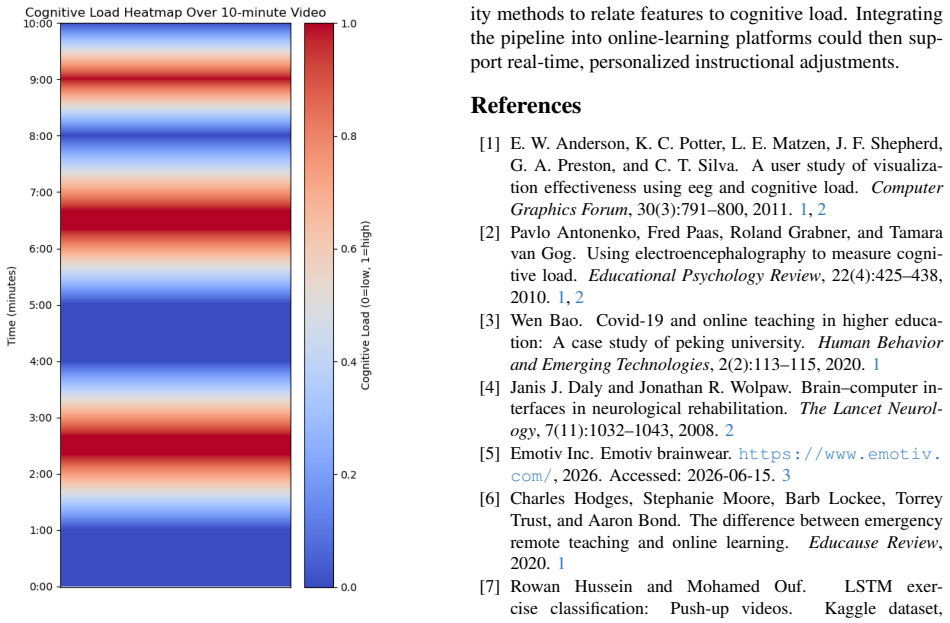
Monitoring cognitive load during online learning could help instructors identify content that learners find difficult, but remote settings remove the visual cues that support this judgement in a classroom. We study whether a single-channel, consumer-grade EEG device (the NeuroSky MindWave Mobile 2) can distinguish easy from difficult educational-video content, using the publicly available dataset of Wang et al. [24] (ten learners, one excluded for excessive noise, leaving nine). We implement a hybrid CNN+LSTM+Attention model that combines the raw waveform with band-power features. In a within-subject setting, the model reaches up to 78.5% accuracy, compared with 55% for conventional feature-based classifiers; regularization (dropout and L2) closes the large gap between training and validation accuracy that we observe without it, keeping validation accuracy stable at roughly 68-73%. We are deliberately cautious about these numbers: with only nine subjects, within-subject evaluation is optimistic, and we argue that subject-independent evaluation -- in which no learner appears in both training and test data -- should be the standard for this task. To that end we release a reproducible evaluation pipeline. We frame the work as a feasibility study rather than a deployable system, and pair it with an open, notebook-based tool that records EEG, runs inference, and visualizes estimated cognitive load as a heatmap over the video timeline to help educators locate potentially challenging segments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates a hybrid CNN+LSTM+Attention model on single-channel EEG (NeuroSky MindWave) from the Wang et al. public dataset (9 subjects after exclusion) to classify easy vs. difficult educational video content as a proxy for cognitive load. In within-subject splits the model reaches 78.5% accuracy versus 55% for conventional feature-based classifiers; dropout and L2 regularization stabilize validation accuracy at 68-73%. The authors explicitly caution that within-subject evaluation is optimistic, argue that subject-independent evaluation should be the standard, release a reproducible pipeline, and provide an open notebook tool for EEG recording, inference, and timeline heatmaps. The work is framed as a feasibility study rather than a deployable system.
Significance. If the reported performance holds under more stringent protocols, the study demonstrates the practical potential of low-cost single-channel EEG for remote cognitive-load monitoring in online education and supplies reusable code and visualization tools that lower the barrier for follow-on work. The explicit discussion of evaluation limitations and the call for subject-independent standards are positive contributions to methodological practice in the field.
major comments (2)
- [Abstract / Results] Abstract and results (implicitly the within-subject tables/figures): the headline comparison of 78.5% vs. 55% is obtained exclusively under within-subject partitioning. Because the paper itself states that this regime allows exploitation of subject-specific signatures and that subject-independent evaluation is the proper standard, the central performance claim for distinguishing content difficulty does not yet support the feasibility argument for real-world deployment across unseen learners.
- [Methods / Experiments] Dataset and evaluation description: with n=9 and within-subject splits, the reported accuracy numbers are consistent with the experiments but the small sample and optimistic partitioning constitute the primary limitation on the strength of any generalization claim; the manuscript correctly flags this but the quantitative results and baseline comparison remain tied to the weaker protocol.
minor comments (1)
- [Discussion] The reproducible pipeline is a clear strength; consider adding a short subject-independent baseline result (even if lower) using the released code so readers can immediately see the gap.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and the recommendation for minor revision. The two major comments both concern the well-known limitations of within-subject evaluation on a small cohort; the manuscript already foregrounds these limitations and frames the work accordingly. We respond point by point below.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results (implicitly the within-subject tables/figures): the headline comparison of 78.5% vs. 55% is obtained exclusively under within-subject partitioning. Because the paper itself states that this regime allows exploitation of subject-specific signatures and that subject-independent evaluation is the proper standard, the central performance claim for distinguishing content difficulty does not yet support the feasibility argument for real-world deployment across unseen learners.
Authors: We agree that within-subject results are optimistic and do not license claims of generalization to unseen subjects. The manuscript explicitly states this limitation, argues that subject-independent evaluation should become the standard, and repeatedly describes the study as a feasibility demonstration rather than a deployable system. The 78.5 % figure is therefore presented only with these caveats; the released pipeline is intended precisely to enable the more stringent protocols the referee correctly identifies as necessary. revision: no
-
Referee: [Methods / Experiments] Dataset and evaluation description: with n=9 and within-subject splits, the reported accuracy numbers are consistent with the experiments but the small sample and optimistic partitioning constitute the primary limitation on the strength of any generalization claim; the manuscript correctly flags this but the quantitative results and baseline comparison remain tied to the weaker protocol.
Authors: We concur that n=9 and within-subject partitioning are the primary constraints on generalization. This is why the paper flags the issue in the abstract, methods, and discussion, advocates for subject-independent evaluation as the appropriate standard, and supplies a reproducible pipeline to support such evaluations. The quantitative results are reported together with these qualifications; no stronger generalization claim is advanced. revision: no
Circularity Check
No circularity; standard supervised ML on external public data with explicit caveats on evaluation
full rationale
The paper trains a hybrid CNN+LSTM+Attention model on the public Wang et al. EEG dataset and reports within-subject accuracy via ordinary supervised learning and held-out splits. No derivation chain, equations, or fitted-parameter predictions are present. The authors themselves flag within-subject results as optimistic and recommend subject-independent evaluation, releasing a pipeline for it. No self-citation load-bearing steps, self-definitional constructs, or renamings of known results occur. This is a standard empirical feasibility study whose central numbers do not reduce to their inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- DL hyperparameters (learning rate, dropout rate, layer sizes, regularization strength)
axioms (2)
- domain assumption Single-channel consumer EEG contains usable information about cognitive load during video viewing
- domain assumption The labels in the Wang et al. dataset correctly reflect easy vs difficult content for each subject
Reference graph
Works this paper leans on
-
[1]
E. W. Anderson, K. C. Potter, L. E. Matzen, J. F. Shepherd, G. A. Preston, and C. T. Silva. A user study of visualiza- tion effectiveness using eeg and cognitive load.Computer Graphics Forum, 30(3):791–800, 2011. 1, 2
2011
-
[2]
Using electroencephalography to measure cogni- tive load.Educational Psychology Review, 22(4):425–438,
Pavlo Antonenko, Fred Paas, Roland Grabner, and Tamara van Gog. Using electroencephalography to measure cogni- tive load.Educational Psychology Review, 22(4):425–438,
-
[3]
Covid-19 and online teaching in higher educa- tion: A case study of peking university.Human Behavior and Emerging Technologies, 2(2):113–115, 2020
Wen Bao. Covid-19 and online teaching in higher educa- tion: A case study of peking university.Human Behavior and Emerging Technologies, 2(2):113–115, 2020. 1
2020
-
[4]
Daly and Jonathan R
Janis J. Daly and Jonathan R. Wolpaw. Brain–computer in- terfaces in neurological rehabilitation.The Lancet Neurol- ogy, 7(11):1032–1043, 2008. 2
2008
-
[5]
Emotiv brainwear.https://www.emotiv
Emotiv Inc. Emotiv brainwear.https://www.emotiv. com/, 2026. Accessed: 2026-06-15. 3
2026
-
[6]
The difference between emergency remote teaching and online learning.Educause Review,
Charles Hodges, Stephanie Moore, Barb Lockee, Torrey Trust, and Aaron Bond. The difference between emergency remote teaching and online learning.Educause Review,
-
[7]
LSTM exer- cise classification: Push-up videos
Rowan Hussein and Mohamed Ouf. LSTM exer- cise classification: Push-up videos. Kaggle dataset, 2022.https : / / www . kaggle . com / datasets / mohamadashrafsalama/pushup/data. 3, 4
2022
-
[8]
Muse: The brain sensing headband.https: //choosemuse.com/, 2026
InteraXon Inc. Muse: The brain sensing headband.https: //choosemuse.com/, 2026. Accessed: 2026-06-15. 3
2026
-
[9]
Deep learning in medical diagnostics.Nature Biomedical Engineering, 4: 389–399, 2020
Jakob Nikolas Kather, Johannes Krisam, et al. Deep learning in medical diagnostics.Nature Biomedical Engineering, 4: 389–399, 2020. 2
2020
-
[10]
Automatic fea- ture extraction and fusion recognition of motor imagery eeg using multilevel multiscale cnn.Medical & Biological Engi- neering & Computing, 59:2037–2050, 2021
Ming-ai Li, Jian-fu Han, and Jin-fu Yang. Automatic fea- ture extraction and fusion recognition of motor imagery eeg using multilevel multiscale cnn.Medical & Biological Engi- neering & Computing, 59:2037–2050, 2021. 2, 3
2037
-
[11]
A review of classification al- gorithms for eeg-based brain–computer interfaces.Journal of Neural Engineering, 4(2):R1–R13, 2007
Fabien Lotte, Marco Congedo, Anatole L ´ecuyer, Fr ´ed´eric Lamarche, and Bruno Arnaldi. A review of classification al- gorithms for eeg-based brain–computer interfaces.Journal of Neural Engineering, 4(2):R1–R13, 2007. 2
2007
-
[12]
Wgan domain adaptation for eeg-based emotion recog- nition
Yun Luo, Si-Yang Zhang, Wei-Long Zheng, and Bao-Liang Lu. Wgan domain adaptation for eeg-based emotion recog- nition. InInternational Conference on Neural Information Processing (ICONIP), pages 275–286. Springer, 2018. 3
2018
-
[13]
M. A. Marshall, Mohamed A. Ouf, A. Elkhateeb, Amr Soli- man, M. S. Rahaman, and S. Mobarak. A review of recon- figurable intelligent surfaces and their application to machine learning-assisted underwater communications. Technical re- port, Fisheries and Marine Institute, Memorial University of Newfoundland, 2024. 3
2024
-
[14]
fnirs-based brain– computer interfaces: A review.Frontiers in Human Neu- roscience, 9:3, 2015
Noman Naseer and Keum-Shik Hong. fnirs-based brain– computer interfaces: A review.Frontiers in Human Neu- roscience, 9:3, 2015. 2, 3
2015
-
[15]
NeuroSky MindWave mobile 2.https: //neurosky.com/, 2026
NeuroSky Inc. NeuroSky MindWave mobile 2.https: //neurosky.com/, 2026. Accessed: 2026-06-15. 2, 3 7
2026
-
[16]
Same Project, Different Start: How Contribution Events Shape Activity and Retention in Open Source
Mohamed Ouf and Mariam Guizani. Same project, different start: How contribution events shape activity and retention in open source.arXiv preprint arXiv:2604.22120, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Reverse engineering user stories from code using large lan- guage models
Mohamed Ouf, Hao Li, Ming Zhang, and Mariam Guizani. Reverse engineering user stories from code using large lan- guage models. In2025 IEEE International Conference on Collaborative Advances in Software and Computing. IEEE, 2025
2025
-
[18]
Mohamed Ouf, Aya Mohamed, and Mariam Guizani. Do good, stay longer? temporal patterns and predictors of newcomer-to-core transitions in conventional OSS and OSS4SG.arXiv preprint arXiv:2601.23142, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
An empirical analysis of commu- nity and coding patterns in OSS4SG vs
Mohamed Ouf, Shayan Noei, Zana Van Iterson, Mariam Guizani, and Ying Zou. An empirical analysis of commu- nity and coding patterns in OSS4SG vs. conventional OSS. arXiv preprint arXiv:2601.03430, 2026. 3
-
[20]
Mohamed A. Ouf, R. M. Amin, M. M. Sabry, A. H. Ali, Y . A. Hamdan, and Sherine N. Saleh. VISION-PF: A com- puter vision approach to injury prevention in physical fitness. In2024 International Telecommunications Conference (ITC- Egypt), pages 1–6. IEEE, 2024. 3
2024
-
[21]
Machine learning for predicting epileptic seizures using eeg signals: A review.IEEE Reviews in Biomedical Engineering, 14:139–155, 2021
Khansa Rasheed, Adnan Qayyum, Junaid Qadir, Shobi Sivathamboo, Patrick Kwan, Levin Kuhlmann, Terence O’Brien, and Adeel Razi. Machine learning for predicting epileptic seizures using eeg signals: A review.IEEE Reviews in Biomedical Engineering, 14:139–155, 2021. 2, 3
2021
-
[22]
A deep learning-based comparative study to track mental depres- sion from eeg data.Neuroscience Informatics, 2(4):100039,
Avik Sarkar, Ankita Singh, and Rakhi Chakraborty. A deep learning-based comparative study to track mental depres- sion from eeg data.Neuroscience Informatics, 2(4):100039,
-
[23]
Amr Soliman, M. A. Marshall, M. S. Rahaman, Mohamed A. Ouf, and A. El-Sayed. A bibliometric review of research publications on digital twin predictive maintenance systems in the maritime industry. Technical report, Fisheries and Ma- rine Institute, Memorial University of Newfoundland, 2024. 3
2024
-
[24]
Using eeg to improve massive open online courses feedback interaction
Haohan Wang, Yiwei Li, Xiaobo Hu, Yucong Yang, Zhu Meng, and Kai-min Chang. Using eeg to improve massive open online courses feedback interaction. InAIED 2013 Workshops Proceedings, 2013. 1, 3
2013
-
[25]
Characteriz- ing working memory load using eeg delta activity
Pega Zarjam, Julien Epps, and Fang Chen. Characteriz- ing working memory load using eeg delta activity. In19th European Signal Processing Conference (EUSIPCO), pages 1554–1558. IEEE, 2011. 2
2011
-
[26]
Classifica- tion of hand movements from eeg using a deep attention- based lstm network.IEEE Sensors Journal, 20(6):3113– 3121, 2020
Guangyi Zhang, Vandad Davoodnia, Alireza Sepas- Moghaddam, Yaoxue Zhang, and Ali Etemad. Classifica- tion of hand movements from eeg using a deep attention- based lstm network.IEEE Sensors Journal, 20(6):3113– 3121, 2020. 2, 4 8
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.