Fine-Tuning Over Architectural Complexity: Broad-Coverage PII Detection on PIIBench with DeBERTa
Pith reviewed 2026-06-29 21:24 UTC · model grok-4.3
The pith
Direct DeBERTa fine-tuning on multi-source PII data outperforms source-conditioned and curriculum models for 82 entity types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
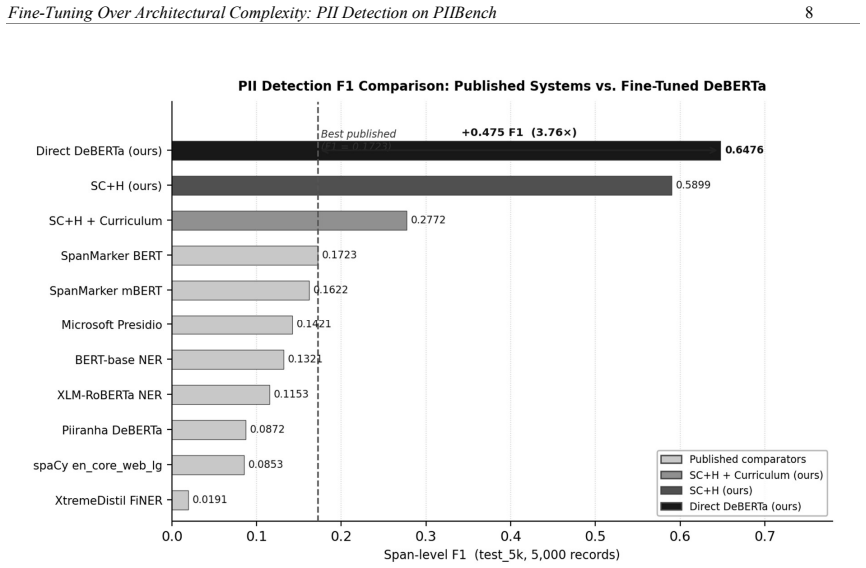
On the corrected multi-source PIIBench, direct token-classification fine-tuning of DeBERTa reaches F1 0.6455 on the full 100,002-record held-out split, exceeding 0.5894 for the source-conditioned hierarchical model and lower scores for the curriculum extension; the same direct model also surpasses all eight published comparators on the reproducible 5,000-record subset and wins 54 of 82 fine entity types plus every coarse group.
What carries the argument
Direct token classification fine-tuning of DeBERTa with weighted cross-entropy loss on the corrected multi-source PIIBench dataset.
If this is right
- Direct fine-tuning wins on 54 of 82 fine entity types and all ten coarse groups by support-weighted entity F1.
- The source-conditioned hierarchical model retains localized advantages on only 28 types.
- The three-phase curriculum extension produces markedly lower F1 than either direct or hierarchical training.
- All three DeBERTa variants exceed the strongest published comparator (F1 0.1723) on the 5k test split.
- Diverse task-specific training data plus a simple weighted objective drive the observed gains more than added architectural or curriculum complexity.
Where Pith is reading between the lines
- For other sequence-labeling tasks that cross heterogeneous sources, allocating effort to data collection and cleaning may yield larger returns than further architectural elaboration.
- The pattern suggests that dataset preparation steps can dominate reported performance differences in information-extraction benchmarks.
- Repeating the comparison at larger model scales or on additional languages would test whether the same data-over-complexity ordering persists.
Load-bearing premise
The corrections applied to the ten source datasets produce accurate unbiased labels for all 82 entity types and the held-out splits represent performance on unseen heterogeneous text.
What would settle it
A new held-out collection drawn from additional heterogeneous sources on which the source-conditioned hierarchical model records a higher overall F1 than direct fine-tuning would falsify the superiority claim.
Figures
read the original abstract
Personally identifiable information (PII) detection systems are frequently trained within narrow source or domain boundaries, limiting coverage when deployed on heterogeneous text. We study model fine-tuning on a corrected multi-source PIIBench preparation spanning 82 retained entity types across ten source datasets. We evaluate three DeBERTa-based approaches: direct token classification fine-tuning, a source-conditioned hierarchical model (SC+H), and a three-phase curriculum extension (SC+H+Curr). Against eight published comparator systems on a reproducible 5,000-record held-out subset (test_5k), direct fine-tuned DeBERTa achieves F1 0.6476, while SC+H and the curriculum variant achieve 0.5899 and 0.2772 respectively; the strongest published comparator reaches only 0.1723. Because validation initially favoured SC+H, we perform a final streamed evaluation on the complete 100,002-record held-out split. Direct fine-tuning remains superior, achieving F1 0.6455 versus 0.5894 for SC+H. Entity-level analysis shows that direct fine tuning wins 54 of 82 fine entity types and all ten coarse groups by support-weighted entity F1, while SC+H retains localised advantages on 28 types. The results indicate that diverse task-specific training data and a simple weighted cross-entropy objective contribute more to broad-coverage PII detection than the tested architectural and curriculum complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that direct fine-tuning of DeBERTa on a corrected multi-source PIIBench dataset spanning 82 entity types from ten sources achieves higher F1 for broad-coverage PII detection (0.6476 on the reproducible test_5k held-out subset and 0.6455 on the full 100k held-out split) than a source-conditioned hierarchical model (SC+H: 0.5899/0.5894) or its curriculum extension (0.2772), outperforming eight published comparators; entity-level analysis shows direct fine-tuning wins on 54/82 fine types and all 10 coarse groups by support-weighted F1, leading to the conclusion that diverse task-specific data and weighted cross-entropy contribute more than the tested architectural and curriculum complexity.
Significance. If the data corrections prove accurate and the held-out splits representative, the result would indicate that for heterogeneous PII detection, simple fine-tuning on diverse data can outperform added model complexity, with potential implications for efficient deployment of privacy tools in NLP. The reproducible 5k subset and streamed 100k evaluation provide a concrete empirical basis for the comparison.
major comments (3)
- [Abstract] Abstract: the central claim attributes performance superiority to 'diverse task-specific training data' after corrections to PIIBench, yet supplies no description of the correction rules, validation against original annotations, inter-annotator metrics, or checks for systematic bias/leakage between train and held-out sets; without this, the entity-level wins (54/82 fine types) and the data-vs-complexity conclusion cannot be confidently separated from possible label artifacts favoring direct token classification.
- [Abstract] Abstract and Results: the reported F1 gaps (e.g., 0.6476 vs. 0.5899 on test_5k) are presented without statistical significance testing, confidence intervals, or error analysis, which is load-bearing because the initial validation favored SC+H while the final streamed evaluation favors direct fine-tuning; this leaves open whether the observed differences are robust across the heterogeneous sources.
- [Abstract] Abstract: hyperparameter selection, class-weight computation for the weighted cross-entropy, and training protocol details for the three DeBERTa variants are omitted, undermining assessment of whether the simple objective's contribution is truly isolated from tuning choices that could have been applied equally to SC+H.
minor comments (2)
- [Abstract] The phrase 'streamed evaluation' on the 100k set is introduced without definition or reference to the streaming procedure.
- [Abstract] Support-weighted entity F1 is mentioned for the 54/82 wins but the exact weighting formula and per-entity support counts are not tabulated.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim attributes performance superiority to 'diverse task-specific training data' after corrections to PIIBench, yet supplies no description of the correction rules, validation against original annotations, inter-annotator metrics, or checks for systematic bias/leakage between train and held-out sets; without this, the entity-level wins (54/82 fine types) and the data-vs-complexity conclusion cannot be confidently separated from possible label artifacts favoring direct token classification.
Authors: We agree that the abstract does not contain these details and that they are needed to support the central claim. The full manuscript (Section 3) describes the multi-source preparation of PIIBench and the corrections performed (label standardization across the ten sources and removal of inconsistent annotations). To address the concern, we will expand Section 3 with an explicit list of correction rules, any available validation steps against original annotations, checks for train/held-out leakage, and a discussion of possible label artifacts. This revision will allow readers to evaluate whether the entity-level results can be attributed to data rather than artifacts. revision: yes
-
Referee: [Abstract] Abstract and Results: the reported F1 gaps (e.g., 0.6476 vs. 0.5899 on test_5k) are presented without statistical significance testing, confidence intervals, or error analysis, which is load-bearing because the initial validation favored SC+H while the final streamed evaluation favors direct fine-tuning; this leaves open whether the observed differences are robust across the heterogeneous sources.
Authors: We acknowledge the absence of statistical testing and error analysis. The manuscript already notes that validation initially favored SC+H and therefore reports the streamed 100k evaluation to test robustness. In revision we will add bootstrap confidence intervals around all reported F1 scores, paired significance tests between models, and a short error analysis section that breaks down performance by source and coarse entity group. These additions will directly address whether the observed gaps are robust. revision: yes
-
Referee: [Abstract] Abstract: hyperparameter selection, class-weight computation for the weighted cross-entropy, and training protocol details for the three DeBERTa variants are omitted, undermining assessment of whether the simple objective's contribution is truly isolated from tuning choices that could have been applied equally to SC+H.
Authors: We agree that these implementation details are required for reproducibility and to isolate the effect of the objective. The experimental section of the manuscript provides high-level training information, but we will add a dedicated appendix that reports the hyperparameter search grid, the exact procedure used to compute class weights (inverse frequency with additive smoothing), optimizer settings, learning-rate schedule, epoch count, and early-stopping criteria for direct fine-tuning, SC+H, and SC+H+Curr. This will enable readers to judge whether the same tuning effort could have been applied to the more complex models. revision: yes
Circularity Check
No circularity: pure empirical comparison on held-out data
full rationale
The paper reports direct fine-tuning results for DeBERTa models on a corrected multi-source PIIBench dataset, with F1 scores on reproducible held-out splits (test_5k and 100k) and entity-level comparisons against published baselines. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear; claims rest on standard train/eval metrics without any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- class weights for weighted cross-entropy
axioms (1)
- domain assumption The corrected multi-source PIIBench supplies accurate ground-truth labels for 82 entity types from ten datasets.
Reference graph
Works this paper leans on
-
[1]
ai4privacy. (2023). PII Masking 400K / 300K. HuggingFace Hub. Custom academic licence. Bengio, Y., Louradour, J., Collobert, R., and Weston, J. (2009). Curriculum learning. Proceedings of ICML, 41–48. Ding, N., et al. (2021). Few-NERD: A few-shot named entity recognition dataset. ACL-IJCNLP
2023
-
[2]
Gretel.ai. (2023). Synthetic PII Finance Multilingual Dataset. HuggingFace Hub: gretelai/synthetic_pii_finance_multilingual. He, P., Gao, J., and Chen, W. (2023). DeBERTaV3: Improving DeBERTa using ELECTRA-style pre-training with gradient-disentangled embedding sharing. ICLR
2023
-
[3]
PIIBench: A Unified Multi-Source Benchmark Corpus for Personally Identifiable Information Detection
Honnibal, M. and Montani, I. (2017). spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing. Isotonic. (2023). PII Masking 200K. HuggingFace Hub: Isotonic/pii-masking-200k. Apache 2.0 Licence. Jha, P. (2026). PIIBench: A unified multi-source benchmark corpus for personally identifiable informat...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
and Cohen, N
McCloskey, M. and Cohen, N. J. (1989). Catastrophic interference in connectionist networks: The sequential learning problem. Psychology of Learning and Motivation, 24:109–165. Microsoft. (2023). Presidio — Data Protection SDK. https://github.com/microsoft/presidio. NVIDIA. (2023). Nemotron-PII: A synthetic dataset for PII detection. HuggingFace Hub: nvidi...
1989
-
[5]
Sang, E. F. and De Meulder, F. (2003). Introduction to the CoNLL-2003 shared task: Language- independent named entity recognition. CoNLL
2003
-
[6]
and Navigli, R
Tedeschi, S. and Navigli, R. (2022). MultiNERD: A multilingual, multi-genre and fine-grained dataset for named entity recognition. NAACL Findings
2022
-
[7]
Weischedel, R. et al. (2013). OntoNotes Release 5.0. LDC Catalog No.: LDC2013T19. Wolf, T., et al. (2020). Transformers: State-of-the-art natural language processing. EMNLP 2020 System Demonstrations. Fine-Tuning Over Architectural Complexity: PII Detection on PIIBench 13 Appendix A: Complete Fine-Entity Full-Test Comparison All 82 retained fine entity ty...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.