Surrogate Fidelity: When Can Open LLMs Explain Closed Ones?
Pith reviewed 2026-07-01 06:13 UTC · model grok-4.3
The pith
Open and closed language models that agree on answers often disagree on the reasons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
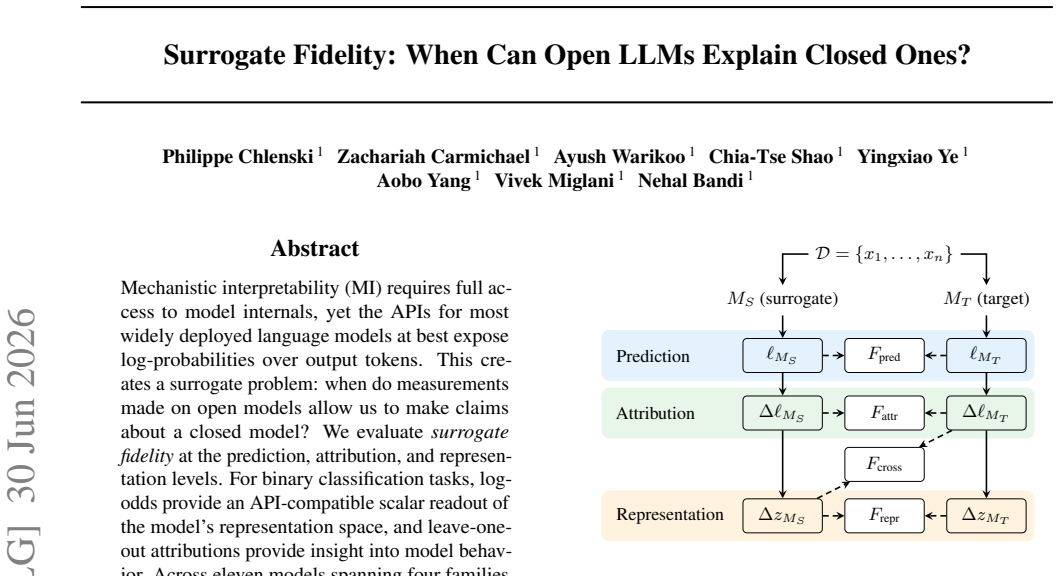
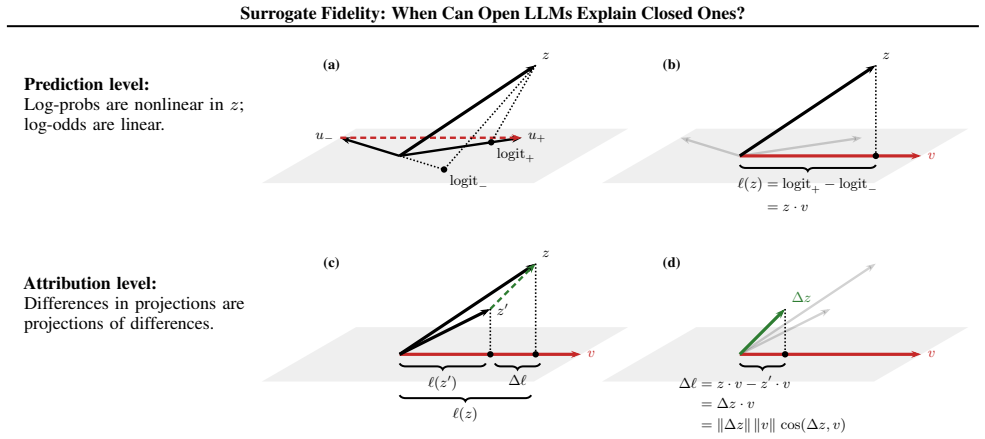
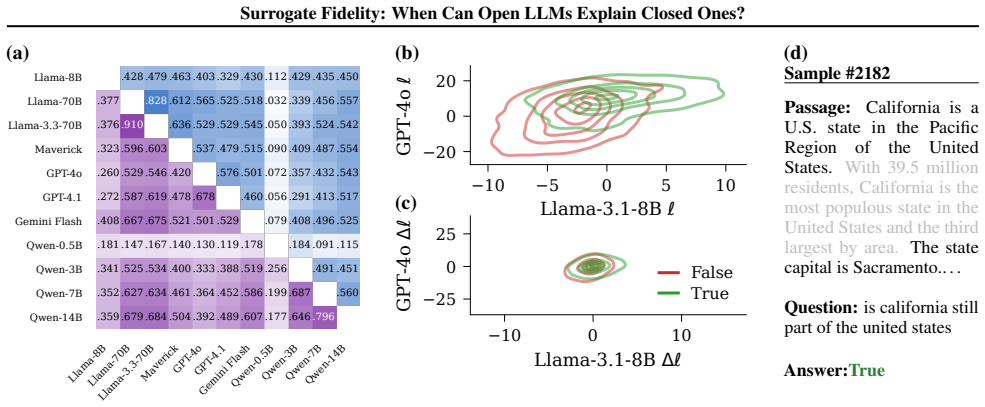
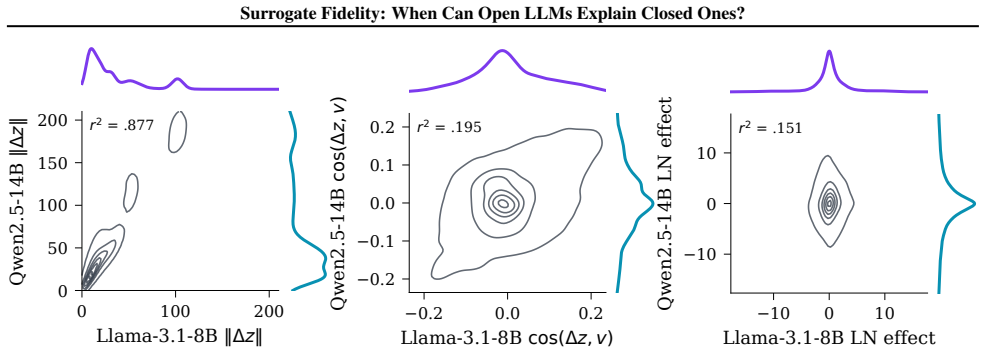
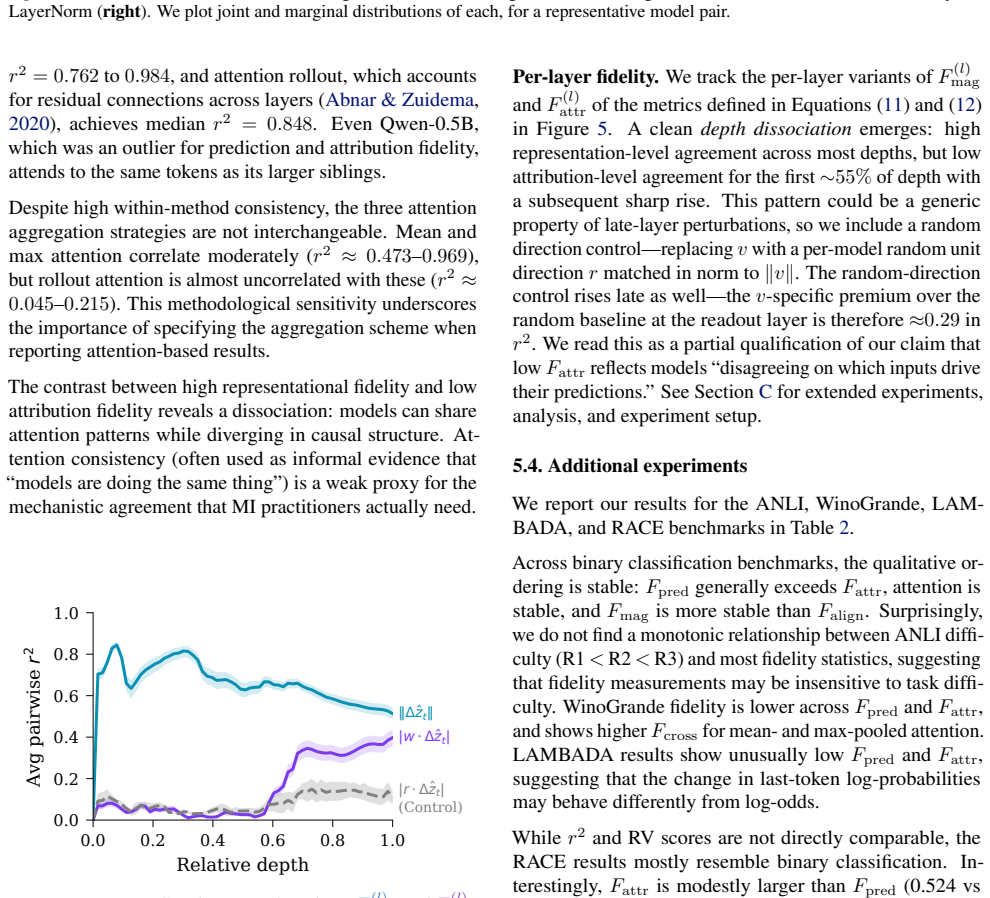
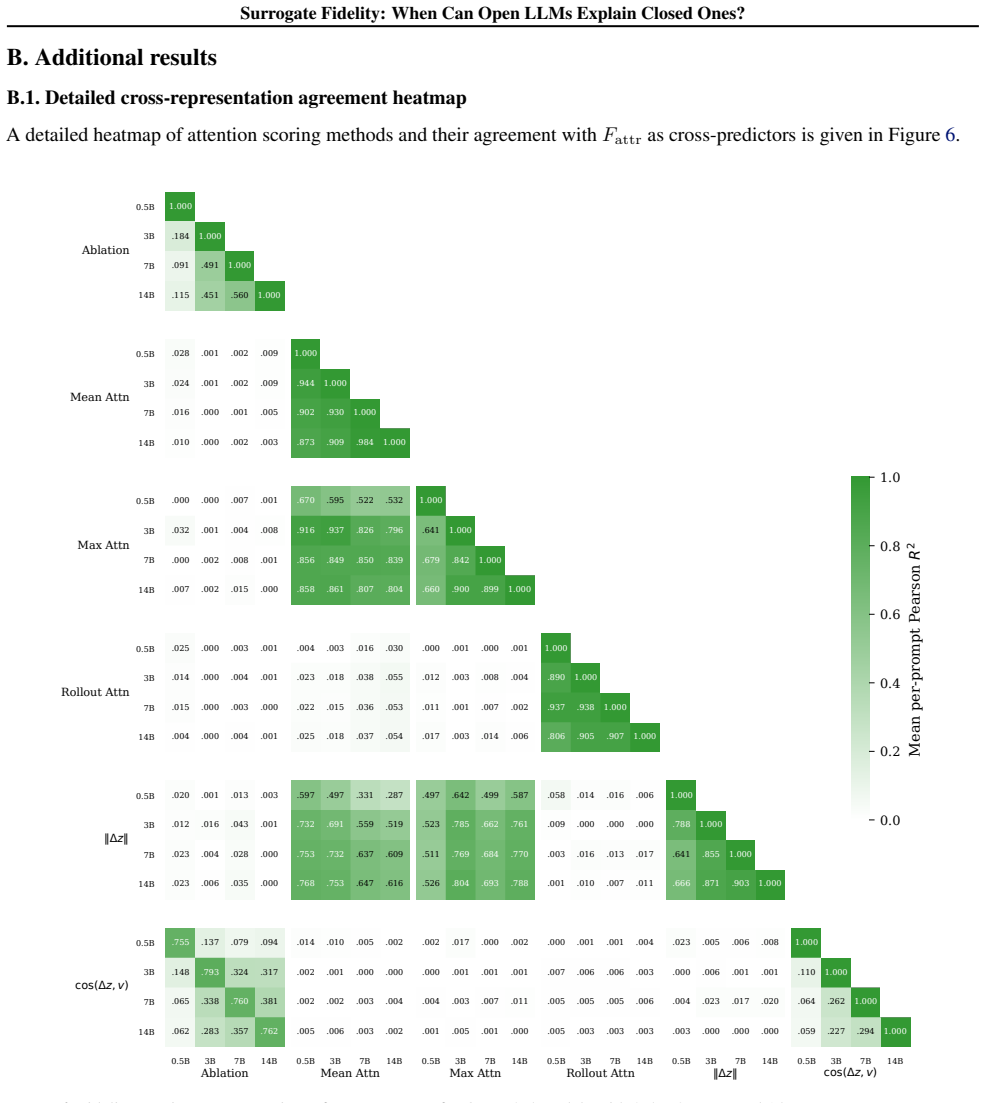
Across eleven models spanning four families, prediction fidelity substantially overstates attribution fidelity: models that agree on what the answer is often disagree on why. Log-odds provide an API-compatible scalar readout of representation space, and leave-one-out attributions give insight into behavior on open models. White-box signals such as attention patterns remain stable across models yet only weakly predict the causal attributions that black-box input ablations capture by design. Mechanistic insight does not automatically transfer to closed targets, and prediction-level agreement alone is insufficient to warrant such transfer.
What carries the argument
Surrogate fidelity at the attribution level, measured by comparing leave-one-out attributions computed on open models against input-ablation effects measured on closed models.
If this is right
- Prediction agreement between open and closed models is not sufficient evidence that their internal reasoning aligns.
- White-box signals such as attention patterns are highly stable across models but only weakly tied to causal attributions.
- Black-box input ablations capture causal attributions more directly than stable white-box signals.
- Mechanistic interpretability methods developed on open models cannot be assumed to explain closed models.
Where Pith is reading between the lines
- Attribution methods that operate entirely through black-box APIs may be needed when surrogates prove unreliable.
- The observed gap between prediction and attribution fidelity may appear in non-classification tasks if similar comparison protocols are applied.
- Auditing or explaining proprietary models may require new black-box techniques rather than reliance on open proxies.
Load-bearing premise
Leave-one-out attributions on open models and input-ablation effects on closed models are comparable quantities that can be used to judge attribution fidelity.
What would settle it
An experiment that finds high agreement between leave-one-out attributions on an open model and input-ablation effects on a matched closed model across the same set of inputs and tasks.
Figures
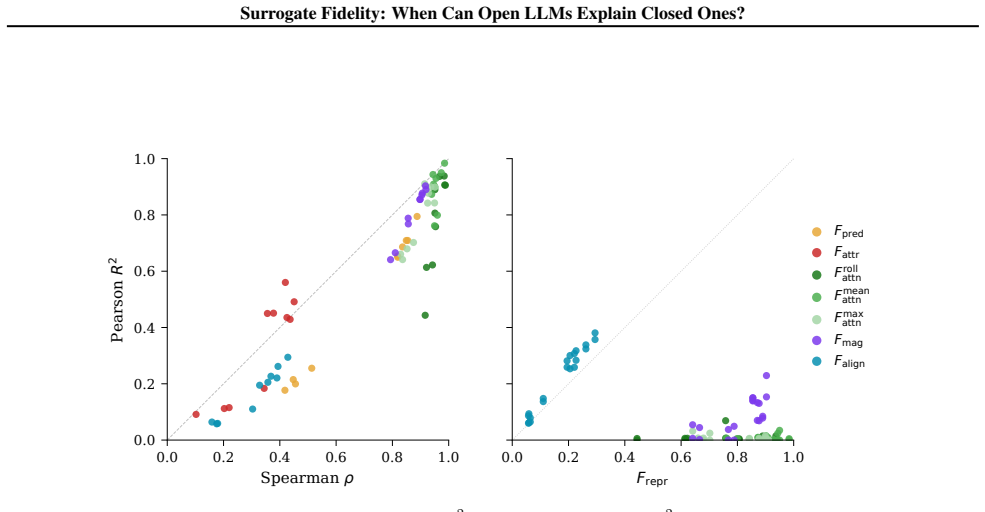
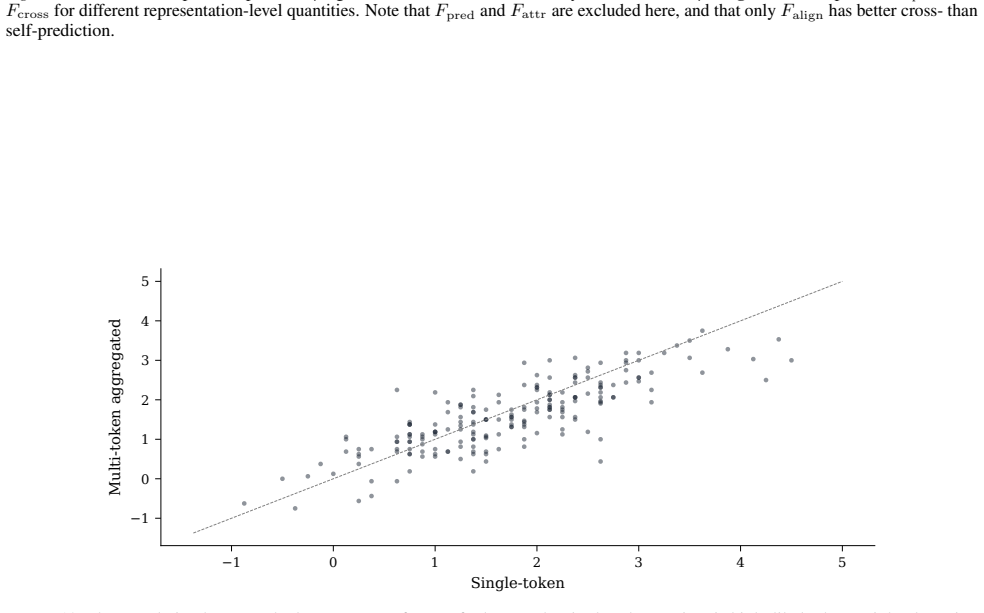
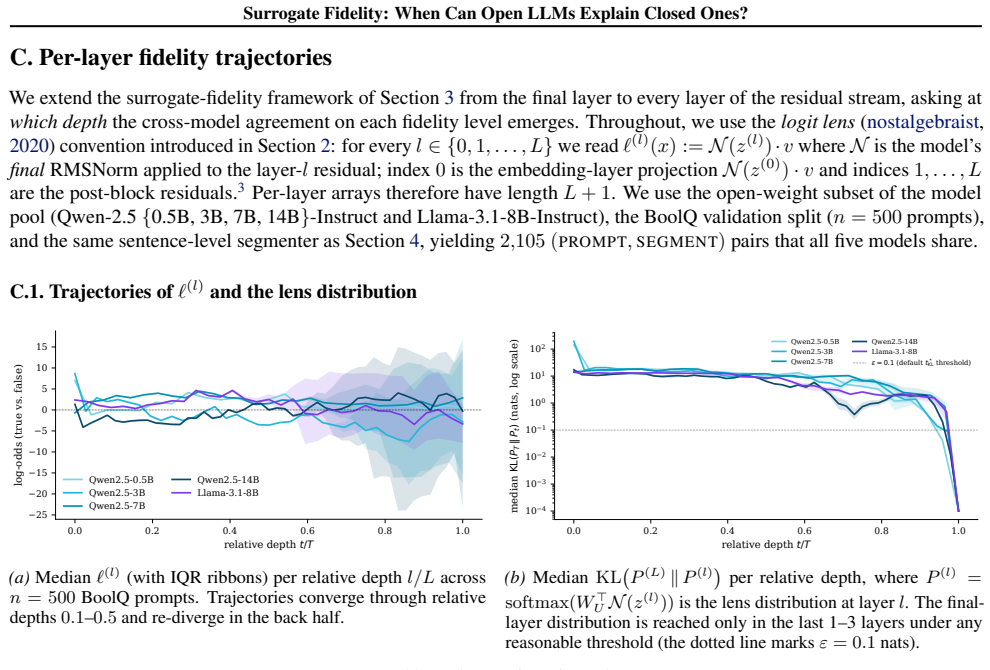
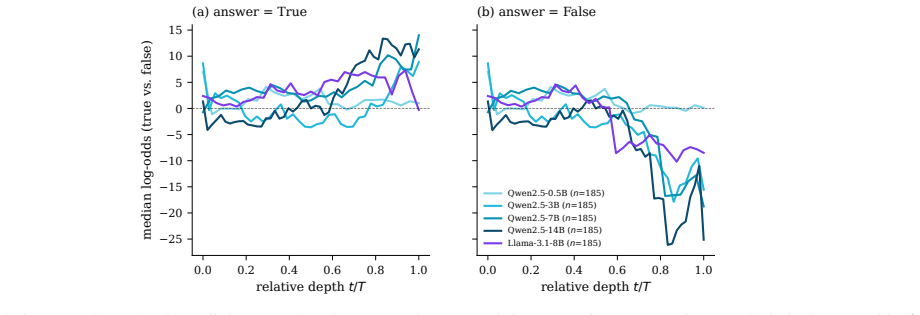
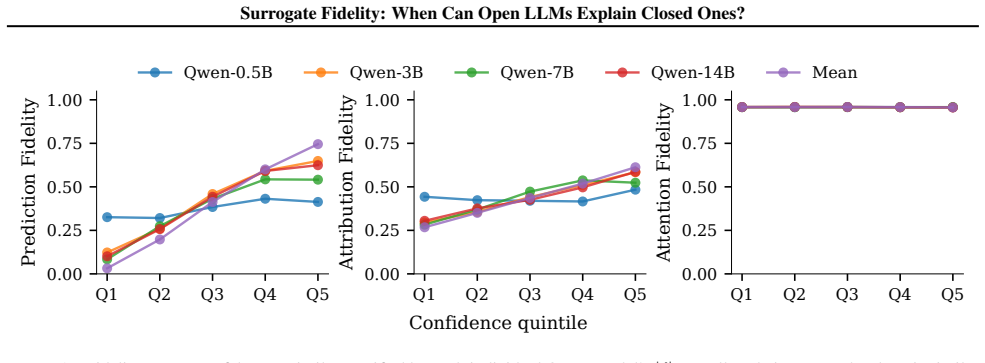
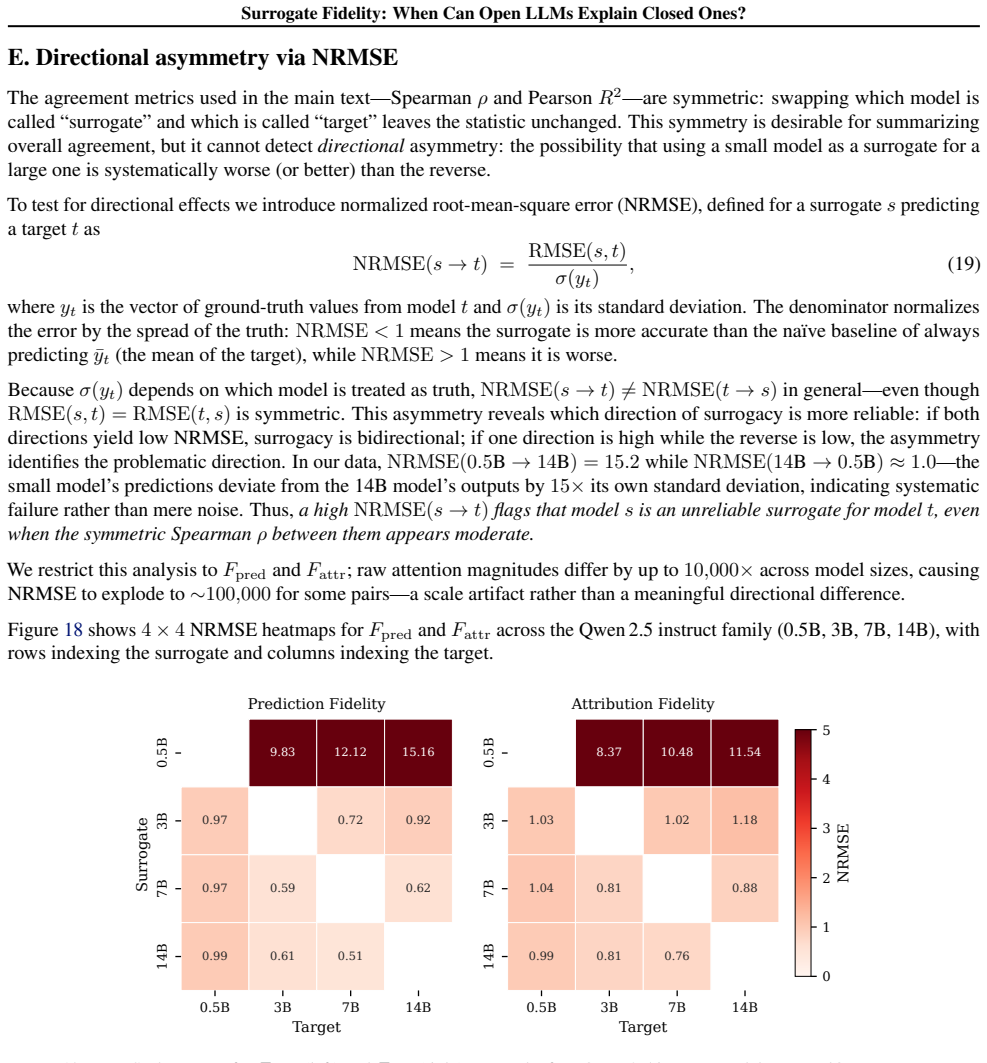
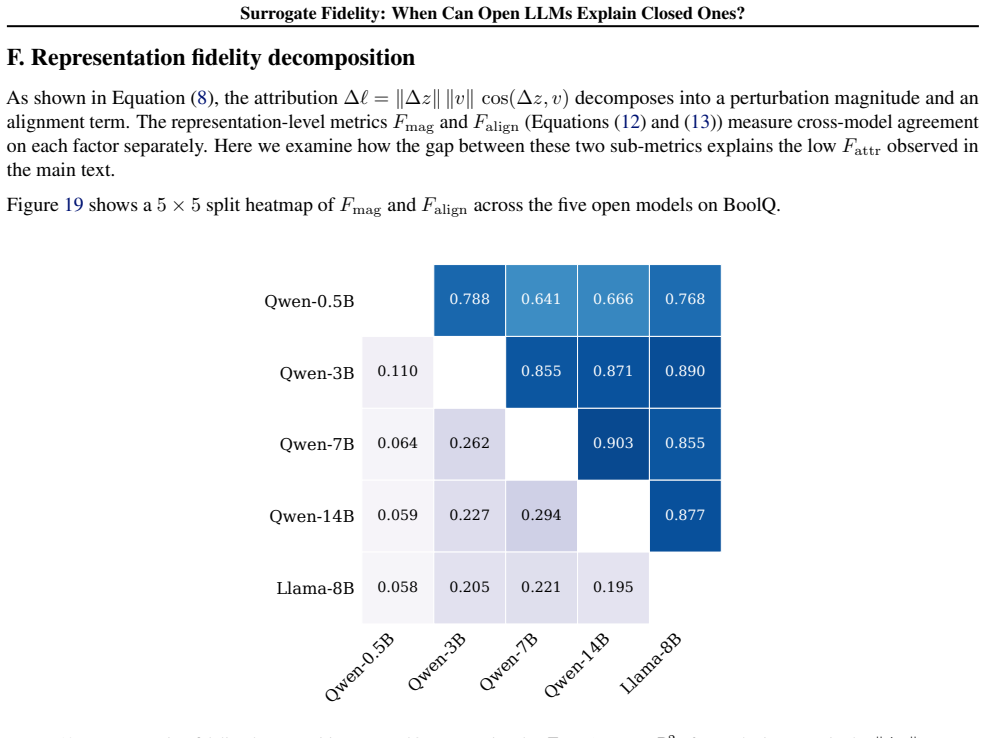
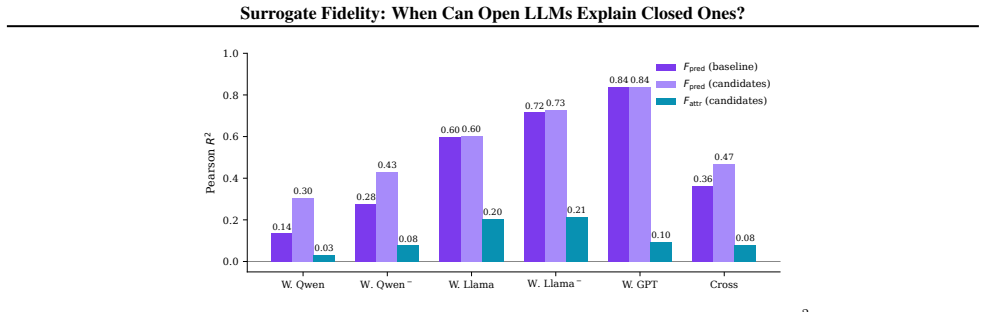

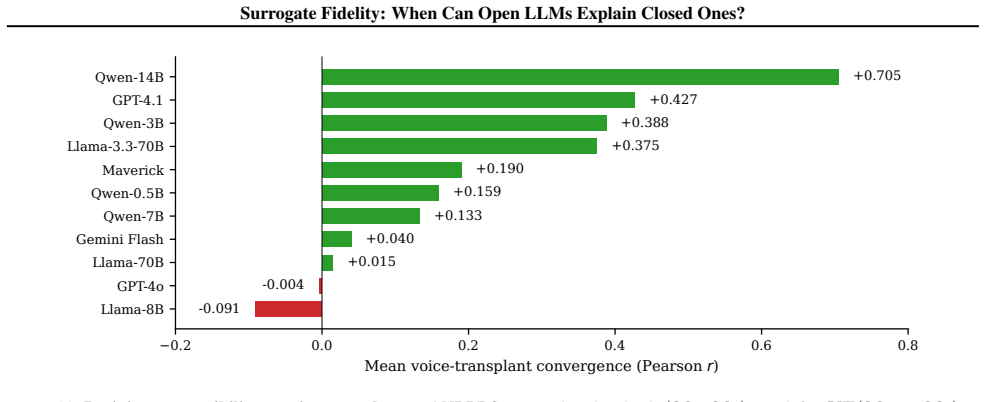
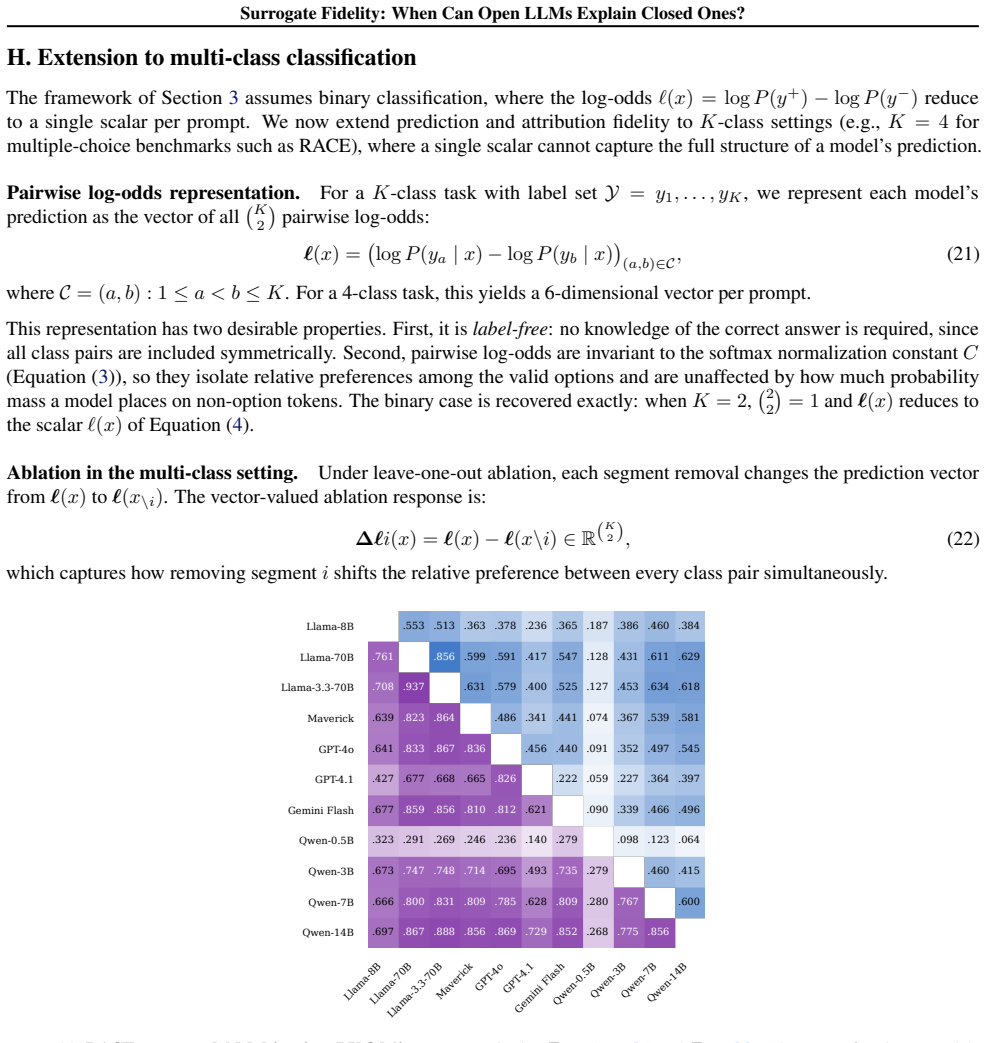

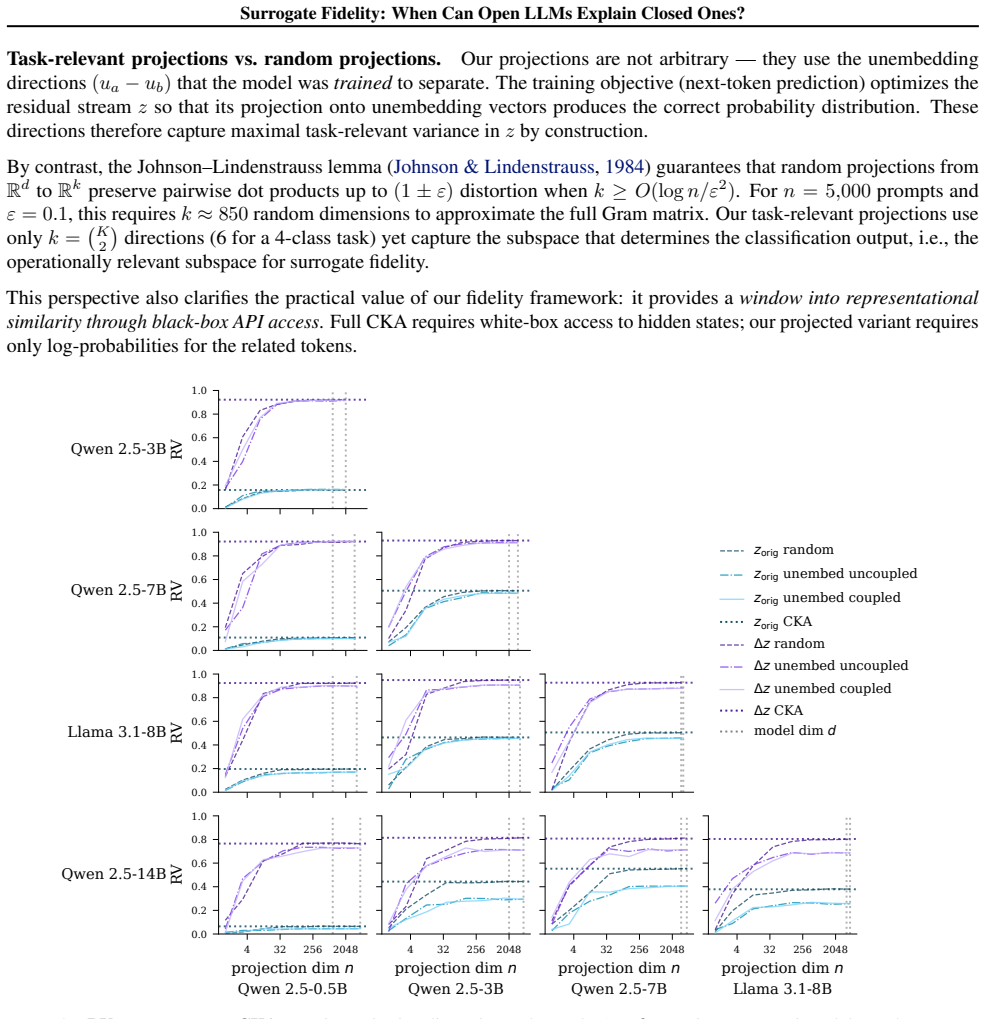
read the original abstract
Mechanistic interpretability (MI) requires full access to model internals, yet the APIs for most widely deployed language models at best expose log-probabilities over output tokens. This creates a surrogate problem: when do measurements made on open models allow us to make claims about a closed model? We evaluate surrogate fidelity at the prediction, attribution, and representation levels. For binary classification tasks, log-odds provide an API-compatible scalar readout of the model's representation space, and leave-one-out attributions provide insight into model behavior. Across eleven models spanning four families (Llama, Qwen, GPT, and Gemini), we find that prediction fidelity substantially overstates attribution fidelity: models that agree on what the answer is often disagree on why. We document an access-validity inversion: white-box signals like attention patterns and perturbation magnitudes are highly stable across models but only weakly predictive of causal attributions, which black-box input ablations capture by design. Mechanistic insight does not automatically transfer to closed targets, and prediction-level agreement is insufficient to warrant such transfer. Code and results are available at https://github.com/facebookresearch/surrogate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for binary classification tasks, prediction-level agreement between open and closed LLMs substantially overstates attribution-level agreement: across eleven models from four families, models that agree on answers often disagree on attributions. It introduces surrogate fidelity evaluation at prediction, attribution, and representation levels, documents an access-validity inversion (stable white-box signals like attention are weakly predictive of causal attributions captured by black-box ablations), and concludes that mechanistic insights do not transfer automatically from open to closed models.
Significance. If the attribution gap is shown to be robust to the choice of attribution method, the result would usefully caution the interpretability community against assuming that open-model explanations apply to closed targets. The public release of code and results at the cited GitHub repository is a clear strength that supports reproducibility and follow-up work.
major comments (2)
- [Methods] Methods (attribution and ablation procedures): leave-one-out attributions computed via full forward passes on open models are treated as directly comparable to black-box input-ablation effects on closed models when quantifying attribution fidelity, yet the manuscript provides no cross-method calibration experiment on any model where both techniques can be run. Because the two procedures differ in their handling of token interactions, position sensitivity, and normalization, the reported gap between prediction and attribution fidelity could be inflated by this mismatch rather than reflecting genuine differences in internal reasoning.
- [Results] Results (access-validity inversion): the observation that white-box signals are stable across models but only weakly predictive of causal attributions is presented as supporting evidence, but it is not used to test or bound the potential discrepancy between LOO and ablation quantities on the same model; without such a test the central claim that prediction fidelity overstates attribution fidelity remains vulnerable to methodological artifact.
minor comments (2)
- [Methods] The manuscript does not report the precise data exclusion rules, tokenization details, or statistical tests used to establish the 'consistent patterns' across the eleven models; these details are needed to assess whether post-hoc choices affect the attribution-fidelity gap.
- [Figures/Tables] Figure captions and table legends should explicitly state the exact perturbation used for each attribution method (e.g., token deletion vs. masking) so readers can evaluate comparability without returning to the main text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each major point below, indicating where revisions will be made to strengthen the work.
read point-by-point responses
-
Referee: [Methods] Methods (attribution and ablation procedures): leave-one-out attributions computed via full forward passes on open models are treated as directly comparable to black-box input-ablation effects on closed models when quantifying attribution fidelity, yet the manuscript provides no cross-method calibration experiment on any model where both techniques can be run. Because the two procedures differ in their handling of token interactions, position sensitivity, and normalization, the reported gap between prediction and attribution fidelity could be inflated by this mismatch rather than reflecting genuine differences in internal reasoning.
Authors: We agree that the absence of a direct cross-method calibration on models permitting both leave-one-out and ablation leaves open the possibility that some portion of the observed attribution gap arises from procedural differences rather than model-internal differences. In the revised manuscript we will add a calibration experiment on open models (where both methods are feasible) to quantify the method-induced discrepancy in attribution scores and to bound its contribution to the reported prediction-versus-attribution fidelity gap. revision: yes
-
Referee: [Results] Results (access-validity inversion): the observation that white-box signals are stable across models but only weakly predictive of causal attributions is presented as supporting evidence, but it is not used to test or bound the potential discrepancy between LOO and ablation quantities on the same model; without such a test the central claim that prediction fidelity overstates attribution fidelity remains vulnerable to methodological artifact.
Authors: The access-validity inversion already demonstrates that highly stable white-box signals (attention, perturbation magnitudes) are only weakly aligned with the causal effects recovered by black-box ablations. This pattern is consistent with the claim that attribution differences reflect genuine differences in causal reasoning rather than being driven primarily by the choice of attribution procedure. We will revise the relevant section to make this linkage explicit and to note how the inversion results provide an indirect bound on the methodological artifact. revision: partial
Circularity Check
No circularity in empirical comparison
full rationale
The paper conducts an empirical study measuring prediction fidelity, attribution fidelity, and representation fidelity by directly comparing outputs and attributions across open and closed models on binary classification tasks. Leave-one-out attributions and input ablations are applied as experimental procedures without any fitted parameters being redefined as predictions, without self-citation load-bearing on core claims, and without any self-definitional equations or ansatzes. The reported findings (prediction fidelity overstating attribution fidelity, access-validity inversion) are presented as outcomes of these measurements rather than derivations that reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2009 , publisher=
Causality , author=. 2009 , publisher=
2009
-
[2]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Quantifying attention flow in transformers , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[3]
Boolq: Exploring the surprising difficulty of natural yes/no questions , author=. Proceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers) , pages=
2019
-
[4]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Adversarial NLI: A new benchmark for natural language understanding , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[5]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[6]
, author=
Tests for comparing elements of a correlation matrix. , author=. Psychological bulletin , volume=. 1980 , publisher=
1980
-
[7]
Attention is not explanation , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
-
[8]
Attention is not not explanation , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[9]
2023 , howpublished =
Language models can explain neurons in language models , author=. 2023 , howpublished =
2023
-
[10]
2024 , journal=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , journal=
2024
-
[11]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (volume 1: long papers) , pages=
Is attention explanation? an introduction to the debate , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (volume 1: long papers) , pages=
-
[12]
Distill , volume=
Zoom in: An introduction to circuits , author=. Distill , volume=
-
[13]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[14]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small , author=. arXiv preprint arXiv:2211.00593 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Advances in Neural Information Processing Systems , volume=
Towards automated circuit discovery for mechanistic interpretability , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Localizing Model Behavior with Path Patching
Localizing model behavior with path patching , author=. arXiv preprint arXiv:2304.05969 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Transformer Circuits Thread , volume=
Towards monosemanticity: Decomposing language models with dictionary learning , author=. Transformer Circuits Thread , volume=
-
[18]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Is attention interpretable? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[20]
Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP , pages=
The elephant in the interpretability room: Why use attention as explanation when we have saliency methods? , author=. Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP , pages=
-
[21]
European conference on computer vision , pages=
Visualizing and understanding convolutional networks , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[22]
Why should i trust you?
" Why should i trust you?" Explaining the predictions of any classifier , author=. Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining , pages=
-
[23]
Advances in neural information processing systems , volume=
A unified approach to interpreting model predictions , author=. Advances in neural information processing systems , volume=
-
[24]
Advances in neural information processing systems , volume=
Causal abstractions of neural networks , author=. Advances in neural information processing systems , volume=
-
[25]
Advances in neural information processing systems , volume=
Investigating gender bias in language models using causal mediation analysis , author=. Advances in neural information processing systems , volume=
-
[26]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[27]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[28]
Advances in neural information processing systems , volume=
Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability , author=. Advances in neural information processing systems , volume=
-
[29]
Frontiers in systems neuroscience , volume=
Representational similarity analysis-connecting the branches of systems neuroscience , author=. Frontiers in systems neuroscience , volume=. 2008 , publisher=
2008
-
[30]
The Platonic Representation Hypothesis
The platonic representation hypothesis , author=. arXiv preprint arXiv:2405.07987 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Holistic Evaluation of Language Models
Holistic evaluation of language models , author=. arXiv preprint arXiv:2211.09110 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[33]
Science , volume=
Rethink reporting of evaluation results in AI , author=. Science , volume=. 2023 , publisher=
2023
-
[34]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Steering Language Models With Activation Engineering
Steering language models with activation engineering , author=. arXiv preprint arXiv:2308.10248 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Steering llama 2 via contrastive activation addition , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[37]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Computational Linguistics , volume=
Probing classifiers: Promises, shortcomings, and advances , author=. Computational Linguistics , volume=
-
[39]
A structural probe for finding syntax in word representations , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
-
[40]
arXiv preprint arXiv:2409.14507 , year=
A is for absorption: Studying feature splitting and absorption in sparse autoencoders , author=. arXiv preprint arXiv:2409.14507 , year=
-
[41]
arXiv preprint arXiv:2502.04878 , year=
Sparse autoencoders do not find canonical units of analysis , author=. arXiv preprint arXiv:2502.04878 , year=
-
[42]
Proceedings of the 3rd Workshop for Natural Language Processing Open Source Software (NLP-OSS 2023) , pages=
Using captum to explain generative language models , author=. Proceedings of the 3rd Workshop for Natural Language Processing Open Source Software (NLP-OSS 2023) , pages=
2023
-
[43]
Advances in Neural Information Processing Systems , volume=
Transcoders find interpretable llm feature circuits , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
arXiv preprint arXiv:2009.07896 , year=
Captum: A unified and generic model interpretability library for pytorch , author=. arXiv preprint arXiv:2009.07896 , year=
-
[45]
Transformer Circuits Thread , pages=
Sparse crosscoders for cross-layer features and model diffing , author=. Transformer Circuits Thread , pages=
-
[46]
Ameisen, Emmanuel and Lindsey, Jack and Pearce, Adam and Gurnee, Wes and Turner, Nicholas L. and Chen, Brian and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[47]
Nauta, Meike and Trienes, Jan and Pathak, Shreyasi and Nguyen, Elisa and Peters, Michelle and Schmitt, Yasmin and Schlötterer, Jörg and van Keulen, Maurice and Seifert, Christin , year=. From Anecdotal Evidence to Quantitative Evaluation Methods: A Systematic Review on Evaluating Explainable AI , volume=. ACM Computing Surveys , publisher=. doi:10.1145/35...
-
[48]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
Transformers: State-of-the-art natural language processing , author=. Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
2020
-
[50]
2016 , eprint=
The LAMBADA dataset: Word prediction requiring a broad discourse context , author=. 2016 , eprint=
2016
-
[51]
2020 , url =
nostalgebraist , title =. 2020 , url =
2020
-
[52]
2025 , eprint=
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. 2025 , eprint=
2025
-
[53]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
arXiv preprint arXiv:2403.06634 , year=
Stealing part of a production language model , author=. arXiv preprint arXiv:2403.06634 , year=
-
[57]
arXiv preprint arXiv:2211.12312 , year=
Interpreting neural networks through the polytope lens , author=. arXiv preprint arXiv:2211.12312 , year=
-
[58]
2023 , journal=
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. 2023 , journal=
2023
-
[59]
International conference on machine learning , pages=
Understanding black-box predictions via influence functions , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[60]
Advances in Neural Information Processing Systems , volume=
Contextcite: Attributing model generation to context , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
2026 , eprint=
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning , author=. 2026 , eprint=
2026
-
[62]
2025 , eprint=
Multi-Level Explanations for Generative Language Models , author=. 2025 , eprint=
2025
-
[63]
2025 , eprint=
Explaining Large Language Models with gSMILE , author=. 2025 , eprint=
2025
-
[64]
2025 , eprint=
AttriBoT: A Bag of Tricks for Efficiently Approximating Leave-One-Out Context Attribution , author=. 2025 , eprint=
2025
-
[65]
2026 , eprint=
Predicting LLM Reasoning Performance with Small Proxy Model , author=. 2026 , eprint=
2026
-
[66]
2024 , eprint=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. 2024 , eprint=
2024
-
[67]
Journal of the Royal Statistical Society Series C: Applied Statistics , volume=
A unifying tool for linear multivariate statistical methods: the RV-coefficient , author=. Journal of the Royal Statistical Society Series C: Applied Statistics , volume=. 1976 , publisher=
1976
-
[68]
RACE : Large-scale R e A ding Comprehension Dataset From Examinations
Lai, Guokun and Xie, Qizhe and Liu, Hanxiao and Yang, Yiming and Hovy, Eduard. RACE : Large-scale R e A ding Comprehension Dataset From Examinations. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017. doi:10.18653/v1/D17-1082
-
[69]
Contemporary mathematics , year=
Extensions of Lipschitz mappings into Hilbert space , author=. Contemporary mathematics , year=
-
[70]
2026 , eprint=
Brittlebench: Quantifying LLM robustness via prompt sensitivity , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.