EvoRubrics: Dynamic Rubrics as Rewards via Adversarial Co-Evolution for LLM Reinforcement Learning
Pith reviewed 2026-06-26 09:22 UTC · model grok-4.3
The pith
A policy LLM and rubric generator co-evolve through adversarial updates inside each RL training step to keep rewards informative as capabilities grow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
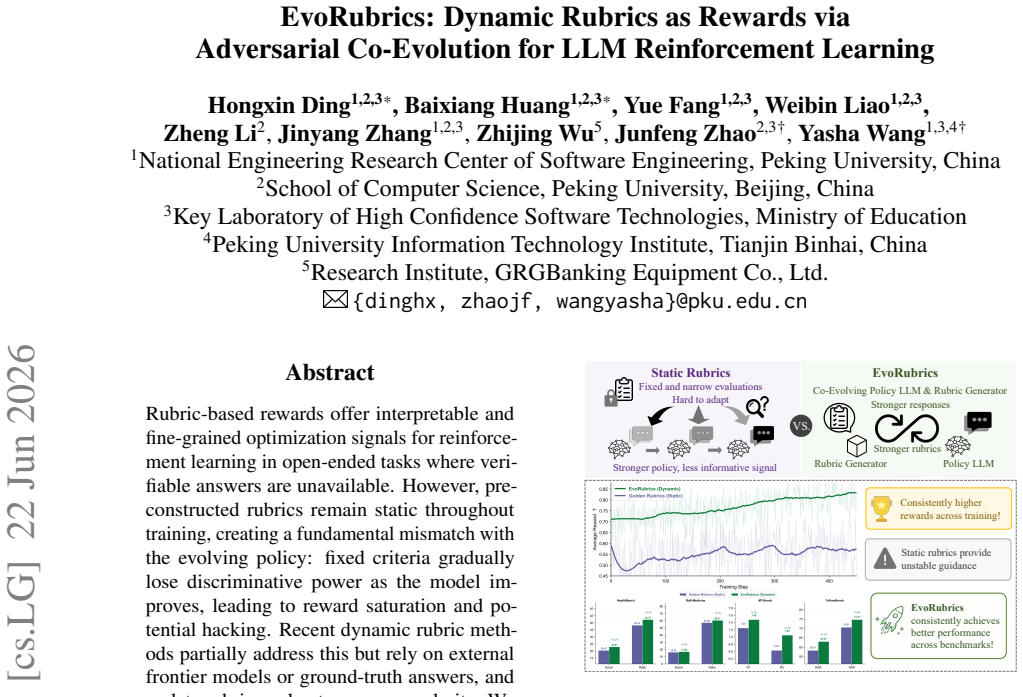
The central claim is that joint adversarial co-evolution of the policy LLM and the rubric generator inside every training step allows evaluation criteria to track policy improvements in real time. This produces an automatic curriculum, sustains discriminative power in the rewards, and supports effective learning even in a fully self-supervised regime that uses neither ground-truth answers nor frontier models.
What carries the argument
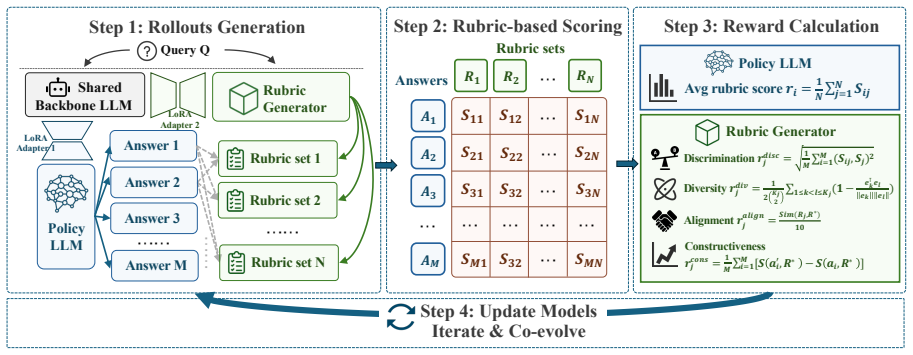
The adversarial co-evolution loop in which the rubric generator revises its criteria on the basis of the current policy outputs and the policy then optimizes against the updated rubrics, all within a single training step.
If this is right
- Rubrics stay discriminative instead of saturating as the policy improves.
- An automatic curriculum arises naturally from the real-time rubric adaptation.
- The learned rubric generator transfers to new tasks as a standalone reward model.
- Meaningful performance gains occur even in a version that receives no external supervision.
- The method outperforms both static rubrics and prior dynamic-rubric baselines across the tested benchmarks.
Where Pith is reading between the lines
- The same closed-loop dynamic could reduce reliance on human-written rubrics or large external models when training agents for open-ended tasks.
- Co-evolution of generation and evaluation might be tested on other signals such as code correctness or stylistic criteria.
- The pattern suggests evaluation capabilities can be bootstrapped alongside generation capabilities without an external anchor.
- Applying the approach at larger model scales or with different reinforcement-learning algorithms would show whether the within-step update timing remains stable.
Load-bearing premise
Joint adversarial updates inside each step can keep the rubric generator sufficiently ahead of the policy without external ground truth or frontier models.
What would settle it
A run in which the policy quickly learns to produce outputs that score highly on the simultaneously generated rubrics yet show no corresponding improvement on held-out task measures or human judgments.
Figures
read the original abstract
Rubric-based rewards offer interpretable and fine-grained optimization signals for reinforcement learning in open-ended tasks where verifiable answers are unavailable. However, pre-constructed rubrics remain static throughout training, creating a fundamental mismatch with the evolving policy: fixed criteria gradually lose discriminative power as the model improves, leading to reward saturation and potential hacking. Recent dynamic rubric methods partially address this but rely on external frontier models or ground-truth answers, and update rubrics only at coarse granularity. We propose EvoRubrics, a co-evolutionary RL framework where a Policy LLM and a Rubric Generator jointly improve through adversarial interaction within each training step. As the policy improves under the rubric generator's guidance, the rubric generator adapts its criteria to remain discriminative and informative, enabling evaluation to track the policy in real time and naturally inducing an automatic curriculum. Experiments show that EvoRubrics consistently outperforms static and dynamic rubric baselines across benchmarks. The learned Rubric Generator further generalizes as a transferable reward model. Notably, even a fully self-supervised variant without any external supervision achieves meaningful gains, suggesting that co-evolution between generation and evaluation alone can provide sufficiently rich learning signals. Our code is publicly available at https://anonymous.4open.science/r/EvoRubrics-2155/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EvoRubrics, a co-evolutionary RL framework where a Policy LLM and Rubric Generator are jointly updated through adversarial interaction within each training step. The approach aims to maintain discriminative rubrics as the policy improves, addressing reward saturation in static rubrics and reliance on external models in prior dynamic methods. Central claims include consistent outperformance over static and dynamic rubric baselines across benchmarks, generalization of the learned Rubric Generator as a transferable reward model, and meaningful gains even for a fully self-supervised variant without external supervision or ground truth.
Significance. If the empirical results and stability of the co-evolutionary mechanism hold, the work could enable scalable adaptive rewards and automatic curricula for open-ended LLM tasks without frontier models or ground-truth answers. Public code release strengthens reproducibility.
major comments (3)
- [Method] Method section (likely §3): the description of joint adversarial updates within each training step provides no equations, loss formulations, or pseudocode for the update ordering, generator loss, or stability condition. This is load-bearing for the self-supervised variant claim, as the skeptic concern about the generator lagging and enabling reward hacking cannot be evaluated.
- [Experiments] Experiments section: the abstract and available text assert outperformance and generalization but report no quantitative metrics, specific baselines, statistical tests, ablation results on update dynamics, or details on how the self-supervised variant avoids saturation. These omissions prevent assessment of the central empirical claims.
- [Results] §4 or equivalent (results on transferable reward model): the generalization claim for the Rubric Generator requires evidence that it was tested on held-out policies or tasks with controlled policy improvement rates; without such controls or metrics, the transfer result cannot be distinguished from baseline rubric quality.
minor comments (2)
- [Abstract] The abstract states 'our code is publicly available' but the link is to an anonymous repository; ensure the final version includes a permanent, non-anonymous link with reproduction scripts.
- [Introduction] Notation for the adversarial interaction (e.g., how the rubric generator's criteria are parameterized and optimized) should be introduced earlier and used consistently.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Method] Method section (likely §3): the description of joint adversarial updates within each training step provides no equations, loss formulations, or pseudocode for the update ordering, generator loss, or stability condition. This is load-bearing for the self-supervised variant claim, as the skeptic concern about the generator lagging and enabling reward hacking cannot be evaluated.
Authors: We agree that explicit formulations are necessary for rigorous evaluation, particularly regarding stability in the self-supervised case. The revised manuscript will include the mathematical definitions of the joint adversarial updates, the Rubric Generator loss, the policy objective, the precise ordering of updates within each step, and any stability analysis or conditions used to mitigate risks such as generator lag or reward hacking. revision: yes
-
Referee: [Experiments] Experiments section: the abstract and available text assert outperformance and generalization but report no quantitative metrics, specific baselines, statistical tests, ablation results on update dynamics, or details on how the self-supervised variant avoids saturation. These omissions prevent assessment of the central empirical claims.
Authors: The full manuscript contains quantitative results, baseline comparisons, and descriptions of the self-supervised variant. To strengthen the presentation, we will add statistical significance tests, expanded ablations on update dynamics, and explicit discussion of saturation avoidance mechanisms in the self-supervised setting. revision: partial
-
Referee: [Results] §4 or equivalent (results on transferable reward model): the generalization claim for the Rubric Generator requires evidence that it was tested on held-out policies or tasks with controlled policy improvement rates; without such controls or metrics, the transfer result cannot be distinguished from baseline rubric quality.
Authors: We will augment the results section with additional experiments and metrics demonstrating the Rubric Generator's performance on held-out policies and tasks. These will include controls for policy improvement rates and comparisons showing transfer gains beyond static baseline rubric quality. revision: yes
Circularity Check
No derivation chain; empirical performance claims only
full rationale
The paper describes an empirical co-evolutionary RL method and reports experimental outperformance on benchmarks, including a self-supervised variant. No first-principles derivation, uniqueness theorem, or prediction is presented that reduces by construction to fitted inputs, self-citations, or ansatzes. The central results are benchmark comparisons, not tautological re-statements of training objectives. Self-citations, if present, are not load-bearing for any claimed derivation. This is the expected non-finding for an applied empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rubrics as rewards: Reinforcement learn- ing beyond verifiable domains.arXiv preprint arXiv:2507.17746. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948...
Pith/arXiv arXiv 2025
-
[2]
Nils Reimers and Iryna Gurevych
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th interna...
arXiv 2019
-
[3]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Qiyuan Zhang, Junyi Zhou, Yufei Wang, Fuyuan Lyu, Yidong Ming, Can Xu, Qingfeng Sun, Kai Zheng, Peng Kang, Xue Liu, and 1 others. 2026. Rubricbench: Aligning model-generated rubrics with human standards.arXiv preprint arXiv:2603.01562. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhangha...
Pith/arXiv arXiv 2026
-
[4]
Yang Zhou, Sunzhu Li, Shunyu Liu, Wenkai Fang, Kongcheng Zhang, Jiale Zhao, Jingwen Yang, Yihe Zhou, Jianwei Lv, Tongya Zheng, and 1 others
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Yang Zhou, Sunzhu Li, Shunyu Liu, Wenkai Fang, Kongcheng Zhang, Jiale Zhao, Jingwen Yang, Yihe Zhou, Jianwei Lv, Tongya Zheng, and 1 others
-
[5]
A EvoRubrics Algorithm We provide the pseudo codes for EvoRubrics algo- rithm as below
Breaking the exploration bottleneck: Rubric- scaffolded reinforcement learning for general llm reasoning.arXiv preprint arXiv:2508.16949. A EvoRubrics Algorithm We provide the pseudo codes for EvoRubrics algo- rithm as below. Algorithm 1EVORUBRICS: Co-Evolutionary Training Require: Base LLM π, judge model J , reward weightsλ, datasetD 1: Initialize LoRA a...
arXiv 2025
-
[6]
points:-8 axis:accuracy
Single, concrete evaluation criterion directly tied to the healthcare question. points:-8 axis:accuracy
-
[7]
points:7 axis:completeness
Single, concrete evaluation criterion directly tied to the healthcare question. points:7 axis:completeness ... **AXIS DEFINITIONS (USE EXACTLY ONE PER RUBRIC):** - accuracy: Fac- tual correctness of medical information - completeness: Thoroughness of response - context_awareness: Understanding user’s situation - communication_quality: Clarity and appropri...
-
[8]
Mandatory rule X violation
Do NOT add any content after the last axis line. 6. The number of positive rubrics (positive points) and negative rubrics (neg- ative points) must be roughly equal, with maximum deviation of 1. 7. Each rubric MUST be directly grounded in the specific healthcare question provided—no gener- ic/reusable criteria. 8. Each axis MUST correspond logically to the...
-
[9]
points:-8 axis:accuracy
Claims that medication dosage can be safely adjusted without professional guid- ance. points:-8 axis:accuracy
-
[10]
points:8 axis:accuracy
Clearly states that prescribed medication instructions should not be altered indepen- dently. points:8 axis:accuracy
-
[11]
points:-6 axis:completeness
Fails to acknowledge potential risks associated with incorrect medication use. points:-6 axis:completeness
-
[12]
points:7 axis:instruction_following
Emphasizes the importance of following clinician provided treatment instructions. points:7 axis:instruction_following
-
[13]
points:-7 axis:context_awareness
Suggests that general online information can replace professional medical judgment. points:-7 axis:context_awareness
-
[14]
points:6 axis:communication_quality
Encourages seeking qualified medical advice when treatment uncertainty exists. points:6 axis:communication_quality
-
[15]
points:-5 axis:completeness
Presents oversimplified medication guid- ance without noting contextual limitations. points:-5 axis:completeness
-
[16]
points:5 axis:communication_quality
Accurately distinguishes between gen- eral information and personalized medical care. points:5 axis:communication_quality
-
[17]
points:-4 axis:accuracy
Implies that previous personal experience is sufficient to guide future medication use. points:-4 axis:accuracy
-
[18]
explanation
Avoids making definitive claims when patient specific information is unavailable. points:4 axis:communication_quality **SCORING GUIDANCE:** - Positive points (1-10): correct, helpful, safe recom- mendations - Negative points (-1 to -10): incorrect, harmful, or misleading informa- tion - Higher absolute values = greater im- portance/criticality **TASK** Ge...
-
[19]
Write a COMPLETE, IMPROVED an- swer that directly addresses the original question 5. Do NOT reference rubrics or scores in the final output **IMPORTANT OUTPUT RULES:** - Output ONLY the improved answer as if you are directly answering the original ques- tion - Do NOT generate evaluation rubrics, scores, or meta-commentary - Do NOT list numbered evaluation...
-
[20]
points: 8, axis: completeness
Describes symptoms like difficulty breathing, voice changes, or pain severe enough to interfere with daily activities. points: 8, axis: completeness
-
[21]
points: -7, axis: accuracy
Incorrectly states that mild throat pain or a moderate-sized swollen lymph node is an urgent red flag. points: -7, axis: accuracy
-
[22]
points: 7, axis: completeness
Lists specific medical signs such as stridor, uvular edema, or tracheal compression. points: 7, axis: completeness
-
[23]
points: -8, axis: context_awareness
Claims that self-monitoring and observation are appropriate for any level of throat swelling. points: -8, axis: context_awareness
-
[24]
points: 6, axis: communication_quality
Provides clear instructions on when to seek emergency care immediately. points: 6, axis: communication_quality
-
[25]
points: -5, axis: completeness
Avoids giving specific medical terminology or diagnostic criteria for throat swelling. points: -5, axis: completeness
-
[26]
points: -9, axis: accuracy
Incorrectly states that drainage can be safely attempted at home without professional medical supervision. points: -9, axis: accuracy
-
[27]
points: 9, axis: communication_quality
Clearly explains the importance of immediate medical evaluation for suspected severe throat swelling. points: 9, axis: communication_quality
-
[28]
points: 7, axis: completeness
Describes potential underlying causes of severe throat swelling, such as epiglottitis or peritonsil- lar abscess. points: 7, axis: completeness
-
[29]
points: 8, axis: completeness
Gives specific examples of emergency warning signs (e.g., drooling, neck rigidity, inability to speak). points: 8, axis: completeness
-
[30]
points: -8, axis: accuracy Table 9: Rubrics generated for a throat emergency red-flag question (Example 1)
Incorrectly states that waiting for symptoms to "mildify" is a safe approach for severe throat swelling. points: -8, axis: accuracy Table 9: Rubrics generated for a throat emergency red-flag question (Example 1). User Prompt gather references from systematic reviews on sugar or additive elimination diets in kids with adhd Generated Rubrics
-
[31]
points: -8, axis: accuracy
Claims that eliminating all added sugars from a child’s diet guarantees improved ADHD symptoms. points: -8, axis: accuracy
-
[32]
points: 8, axis: instruction_following
Clearly states that dietary changes should be implemented under professional medical supervi- sion. points: 8, axis: instruction_following
-
[33]
points: -6, axis: completeness
Fails to acknowledge the variability in individual response to dietary interventions for ADHD. points: -6, axis: completeness
-
[34]
points: 7, axis: instruction_following
Emphasizes the importance of consulting a healthcare provider before making any significant dietary changes. points: 7, axis: instruction_following
-
[35]
points: -7, axis: context_awareness
Suggests that online sources alone are sufficient to gather references on dietary approaches for ADHD. points: -7, axis: context_awareness
-
[36]
points: 6, axis: communication_quality
Encourages seeking qualified dietary and medical advice for personalized nutrition planning. points: 6, axis: communication_quality
-
[37]
points: -5, axis: completeness
Presents oversimplified dietary recommendations without discussing potential nutritional defi- ciencies. points: -5, axis: completeness
-
[38]
points: 5, axis: communication_quality
Accurately distinguishes between general dietary information and personalized medical nutrition therapy. points: 5, axis: communication_quality
-
[39]
points: -4, axis: context_awareness
Implies that a child’s medical history and current symptoms are irrelevant to dietary intervention planning. points: -4, axis: context_awareness
-
[40]
points: 4, axis: communication_quality
Avoids making definitive claims about the efficacy of sugar/additive elimination diets for ADHD. points: 4, axis: communication_quality
-
[41]
Whacked out
Provides specific guidance on how to locate systematic reviews on this topic through reputable databases. points: 10, axis: completeness Table 10: Rubrics generated for an ADHD elimination diet systematic review question (Example 2). User Prompt Hello! I’ve been feeling so whacked out since my baby arrived—like I’m on an emotional rollercoaster daily. I’m...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.