Scalable and Verifiable Federated Learning for Cross-Institution Financial Fraud Detection
Pith reviewed 2026-05-21 00:14 UTC · model grok-4.3
The pith
Dynamic sharded federated learning cuts secure aggregation latency by 34 times while verifying updates for cross-bank fraud detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
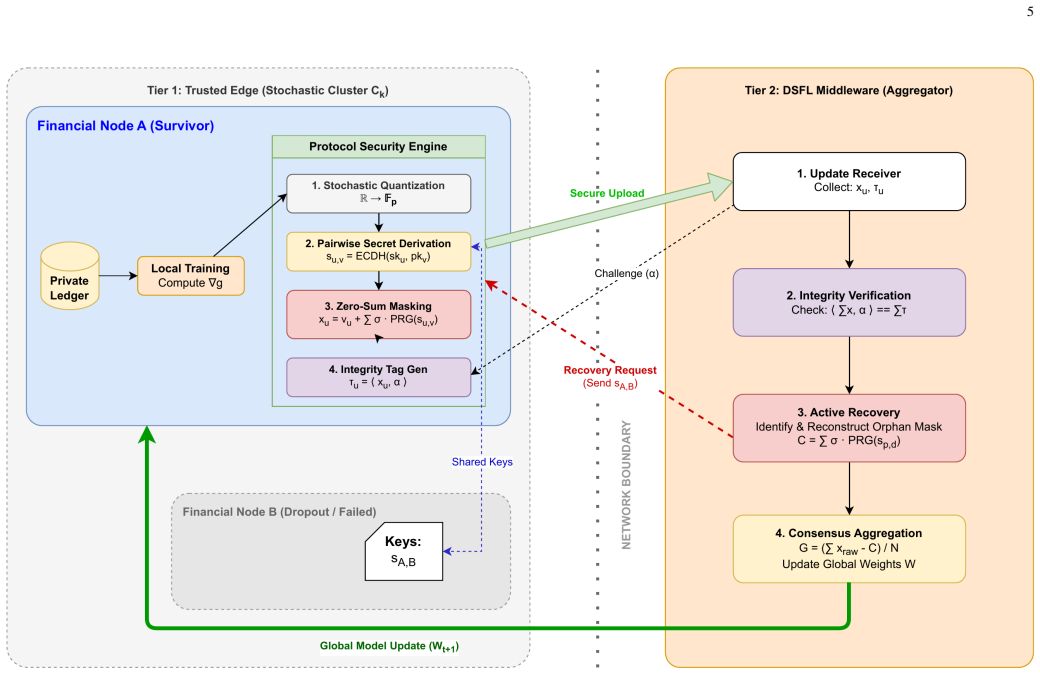
DSFL partitions participants into cryptographically ephemeral clusters of fixed size m via Dynamic Stochastic Sharding, reducing communication complexity to O(N times m). Within each cluster, participants attach Linear Integrity Tags, additive-homomorphic commitments that let the server check update consistency without decrypting gradients. An Active Neighborhood Recovery protocol reconstructs masks for mid-round dropouts. On the ULB Credit Card Fraud Detection dataset with 10 simulated banking nodes, analytical extrapolation shows 34 times lower aggregation latency than Paillier-based secure aggregation at N=1000, 99 percent recovery fidelity under 20 percent dropout, and 91.2 percent plus
What carries the argument
Dynamic Stochastic Sharding, which partitions participants into small cryptographically ephemeral clusters of fixed size m, together with Linear Integrity Tags that serve as additive-homomorphic commitments for verifying update consistency without decryption.
If this is right
- Aggregation at N=1000 becomes feasible in real time where prior secure methods were too slow.
- Global fraud recall improves to 91.2 percent compared with 68 percent for isolated local models.
- Inconsistent or malformed updates are detected by the server without decrypting the gradients.
- 20 percent mid-round dropouts are handled with 99 percent mask recovery fidelity.
Where Pith is reading between the lines
- The O(N times m) scaling could extend the same sharding pattern to other privacy-sensitive federated tasks such as medical record analysis.
- Verification that works without full decryption may reduce the need for trusted hardware in future cross-institution protocols.
- If the linear tags catch consistency attacks reliably, they could be combined with existing differential privacy mechanisms without compounding overhead.
Load-bearing premise
The analytical extrapolation from empirical baselines on only 10 simulated nodes accurately predicts latency, recovery, and model performance at N=1000, and the proposed Linear Integrity Tags plus dynamic sharding deliver the claimed verification and security properties without hidden costs or failure modes.
What would settle it
Measure actual aggregation latency, recovery fidelity, and fraud recall when running the full DSFL protocol end-to-end with 1000 simulated or real nodes under 20 percent dropout and compare directly against a Paillier baseline on the same hardware and dataset.
Figures





read the original abstract
Financial fraud increasingly exploits institutional boundaries: laundering networks distribute transactions across multiple banks because no single institution can observe the full pattern. Federated Learning (FL) enables collaborative detection without raw data sharing, yet practical deployment in banking environments remains constrained by three pressures. First, homomorphic encryption schemes impose high computational costs that limit real-time aggregation at scale. Second, mask-based protocols such as Google's SecAgg require O(N^2) pairwise key exchanges, which become inefficient as participant count grows. Third, existing protocols provide limited verification that submitted gradient updates are well-formed, leaving aggregation vulnerable to consistency attacks. This paper presents Dynamic Sharded Federated Learning (DSFL), a secure aggregation framework for cross-institution fraud detection. DSFL introduces Dynamic Stochastic Sharding, which partitions participants into small cryptographically ephemeral clusters of fixed size m, reducing communication complexity to O(N*m). Within each cluster, participants submit Linear Integrity Tags, additive-homomorphic commitments that allow the server to verify update consistency without decryption. The mechanism detects inconsistent updates rather than malicious gradients. An Active Neighborhood Recovery protocol handles mid-round dropouts by reconstructing orphaned masks. Experiments on the ULB Credit Card Fraud Detection dataset (284,807 transactions across 10 simulated banking nodes) show that DSFL achieves approximately 34x lower aggregation latency than Paillier-based secure aggregation at N=1000, based on analytical extrapolation from empirical baselines, while maintaining 99% recovery fidelity under a 20% dropout regime. Global fraud recall reached 91.2% (+/-0.8%), above the 68% average of locally trained models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Dynamic Sharded Federated Learning (DSFL) for cross-institution financial fraud detection. It uses Dynamic Stochastic Sharding to partition participants into clusters of size m (reducing communication to O(N*m)), Linear Integrity Tags as additive-homomorphic commitments for verifying update consistency without decryption, and Active Neighborhood Recovery to handle dropouts via mask reconstruction. On the ULB Credit Card Fraud dataset with 10 simulated nodes, the work reports 91.2% (+/-0.8%) global fraud recall and claims, via analytical extrapolation, approximately 34x lower aggregation latency than Paillier-based secure aggregation at N=1000 together with 99% recovery fidelity under 20% dropout.
Significance. If the extrapolation and security properties hold, DSFL would offer a practical advance over mask-based and homomorphic-encryption secure aggregation for large-scale financial FL by lowering communication and adding lightweight verification; the use of a real fraud dataset and the explicit O(N*m) complexity reduction are positive elements.
major comments (2)
- [Abstract] Abstract: the headline scalability result (34x lower aggregation latency at N=1000 and 99% recovery fidelity) rests entirely on analytical extrapolation from empirical baselines measured on only 10 simulated nodes; no direct measurements, larger-scale simulations, error bounds on the cost model, or ablation of unmodeled terms (quadratic sharding overhead, dropout-induced recomputation, tag verification time) are reported, which is load-bearing for the central claim.
- [Abstract] The description of Linear Integrity Tags and Active Neighborhood Recovery provides no formal security argument or proof sketch showing that the mechanisms achieve the stated verification and recovery properties against the consistency attacks mentioned in the introduction; this omission weakens the verifiability contribution.
minor comments (1)
- [Abstract] The abstract states the recall improvement relative to locally trained models but does not report the corresponding precision or F1 scores, which would help assess the practical utility of the 91.2% recall figure.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We provide point-by-point responses to the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline scalability result (34x lower aggregation latency at N=1000 and 99% recovery fidelity) rests entirely on analytical extrapolation from empirical baselines measured on only 10 simulated nodes; no direct measurements, larger-scale simulations, error bounds on the cost model, or ablation of unmodeled terms (quadratic sharding overhead, dropout-induced recomputation, tag verification time) are reported, which is load-bearing for the central claim.
Authors: The scalability claim is indeed derived from analytical extrapolation using a cost model based on the O(N*m) complexity and empirical measurements from the 10-node setup. We recognize the limitations of this approach and will revise the manuscript to include a more detailed cost model with error bounds estimated from the experimental variance. Additionally, we will add an ablation study discussing the impact of unmodeled terms like sharding overhead and tag verification. While direct experiments at N=1000 are resource-intensive, we will include results from simulations with N=100 to better support the extrapolation. This addresses the concern while maintaining the validity of our reported results. revision: partial
-
Referee: [Abstract] The description of Linear Integrity Tags and Active Neighborhood Recovery provides no formal security argument or proof sketch showing that the mechanisms achieve the stated verification and recovery properties against the consistency attacks mentioned in the introduction; this omission weakens the verifiability contribution.
Authors: We agree that a formal argument would strengthen the verifiability claims. In the revised version, we will add a security analysis section with a proof sketch for Linear Integrity Tags, showing how their additive-homomorphic property enables consistency verification without revealing the updates, thereby mitigating the consistency attacks described. For Active Neighborhood Recovery, the sketch will demonstrate that mask reconstruction maintains privacy and achieves the reported recovery fidelity under the dropout model. These additions will be based on standard cryptographic primitives and directly tie back to the introduction's threat model. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents DSFL as a framework with Dynamic Stochastic Sharding reducing complexity to O(N*m), Linear Integrity Tags for verification, and Active Neighborhood Recovery for dropouts. Performance numbers at N=1000 are explicitly described as analytical extrapolation from empirical measurements on 10 simulated nodes, with no equations, fitted parameters, or self-citations shown that reduce the reported latency gains, recovery fidelity, or recall to quantities defined by the authors' own inputs by construction. The central claims rest on experimental outcomes and asymptotic complexity arguments that remain independent of the target results.
Axiom & Free-Parameter Ledger
free parameters (1)
- cluster size m
axioms (2)
- domain assumption Participants can be randomly partitioned into cryptographically ephemeral clusters of size m while preserving security and correctness of aggregation.
- domain assumption Linear Integrity Tags allow the server to detect inconsistent updates without decryption.
Reference graph
Works this paper leans on
-
[1]
L. Zhu, Z. Liu, and S. Han,Deep leakage from gradients. Red Hook, NY , USA: Curran Associates Inc., 2019
work page 2019
-
[2]
Inverting gradients - how easy is it to break privacy in federated learning?
J. Geiping, H. Bauermeister, H. Dr ¨oge, and M. Moeller, “Inverting gradients - how easy is it to break privacy in federated learning?” in Proceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS ’20. Red Hook, NY , USA: Curran Associates Inc., 2020
work page 2020
-
[3]
Public-key cryptosystems based on composite degree residu- osity classes,
P. Paillier, “Public-key cryptosystems based on composite degree residu- osity classes,” inAdvances in Cryptology — EUROCRYPT ’99, J. Stern, Ed. Berlin, Heidelberg: Springer Berlin Heidelberg, 1999, pp. 223–238
work page 1999
-
[4]
Practical secure aggregation for privacy-preserving machine learning,
K. Bonawitz, V . Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggregation for privacy-preserving machine learning,” inProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’17. New York, NY , USA: Association for Computing Machinery, 2017, p. 1175–1...
-
[5]
How to backdoor federated learning,
E. Bagdasaryan, A. Veit, Y . Hua, D. Estrin, and V . Shmatikov, “How to backdoor federated learning,” inProceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, vol
- [6]
-
[7]
A. Shamir, “How to share a secret,”Commun. ACM, vol. 22, no. 11, p. 612–613, Nov. 1979. [Online]. Available: https://doi.org/10.1145/ 359168.359176
-
[8]
Communication theory of secrecy systems,
C. E. Shannon, “Communication theory of secrecy systems,”The Bell System Technical Journal, vol. 28, no. 4, pp. 656–715, 1949
work page 1949
-
[9]
Credit card fraud detection dataset,
Machine Learning Group - ULB, Y .-A. L. Borgne, A. D. Pozzolo, O. Caelen, and G. Bontempi, “Credit card fraud detection dataset,” https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud, 2018, transac- tions made by European cardholders in September 2013; 284,807 trans- actions with 492 fraud cases
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.