CapRiCorn-1K: A Comprehensive Benchmark for Video Captioning and Subject Referential Consistency Across Temporal Scales
Pith reviewed 2026-06-26 12:07 UTC · model grok-4.3
The pith
The CapRiCorn-1K benchmark shows current video captioning models lose accuracy and subject reference consistency as videos grow longer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
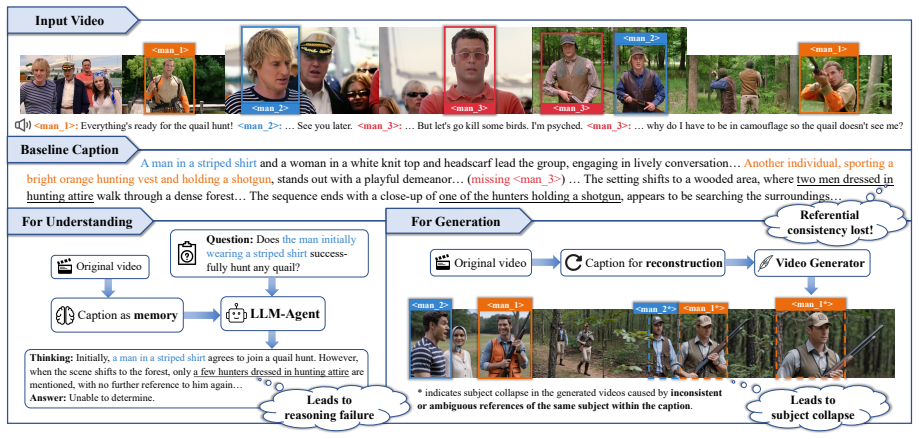
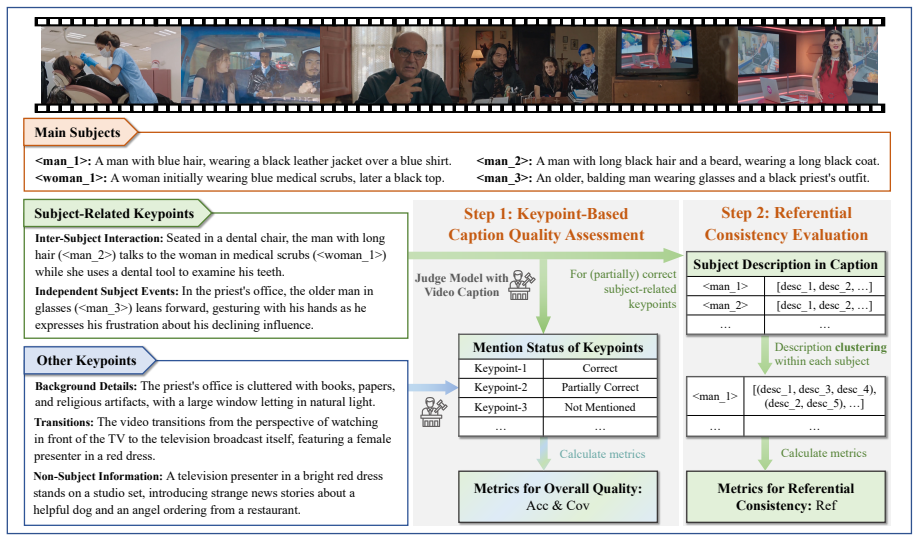
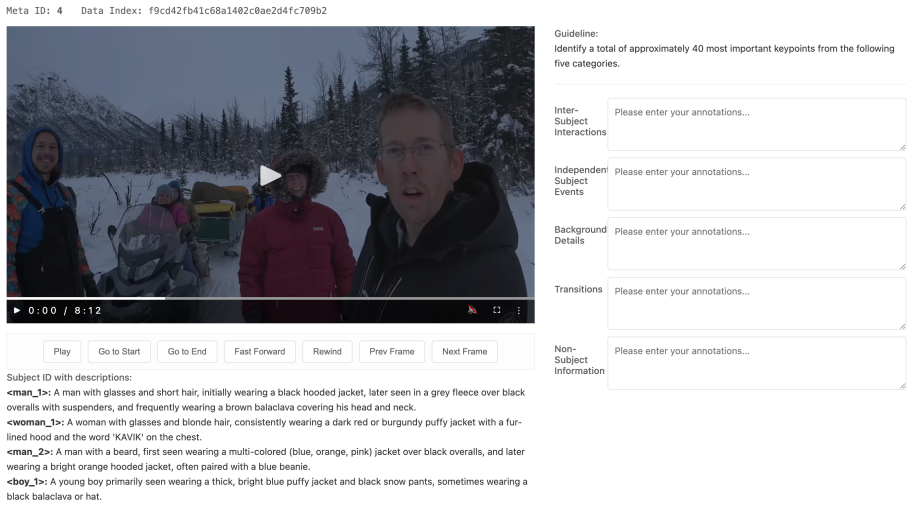
CapRiCorn-1K is a benchmark for video captioning quality and subject referential consistency across long temporal horizons and diverse domains. It shows that current models struggle to generate accurate and comprehensive captions while maintaining consistent subject references, with both quality and consistency declining as video duration increases. The benchmark works in audiovisual and visual-only modes, and its metrics correlate strongly with performance on downstream tasks that use the captions.
What carries the argument
CapRiCorn-1K benchmark, which measures caption accuracy, comprehensiveness, and subject referential consistency across temporal scales.
If this is right
- Models require advances in temporal handling to keep subject references stable in longer videos.
- The benchmark metrics can serve as predictors for caption usefulness in other tasks.
- Support for both audiovisual and visual-only inputs allows targeted testing of different input types.
- Observed drops with longer durations indicate limits in current approaches to tracking subjects over time.
Where Pith is reading between the lines
- Model training could shift toward including more long-form videos to address the length-related declines.
- Emphasis on referential consistency may lead to new architectures focused on entity tracking in video narratives.
- The benchmark could be applied to test whether gains in consistency directly improve tasks like video summarization.
Load-bearing premise
The videos, annotations, and metrics selected for CapRiCorn-1K give an objective measure of caption quality and consistency that applies beyond the benchmark itself.
What would settle it
Finding a captioning model that scores high on CapRiCorn-1K yet shows no improvement or even worse results on downstream tasks when its captions are used would challenge the benchmark's value.
Figures








read the original abstract
Accurate and comprehensive video captions with consistent subject references are critical for downstream understanding and generation tasks. However, few existing benchmarks can objectively and comprehensively evaluate these properties across diverse durations and scenarios, thereby hindering the advancement of video captioning models. To bridge this gap, we propose CapRiCorn-1K, a comprehensive benchmark designed to evaluate both video captioning quality and subject referential consistency across long temporal horizons and diverse video domains. To accommodate varied evaluation needs, our benchmark supports both audiovisual and visual-only settings. Extensive experiments on CapRiCorn-1K reveal that current models generally struggle to generate accurate and comprehensive captions while maintaining consistent subject references. Moreover, as video duration increases, both the overall caption quality and subject referential consistency decline. Notably, our evaluation metrics exhibit strong correlations with the performance of downstream understanding and generation tasks conditioned on the generated captions, further validating their effectiveness. The project is available at https://github.com/xlchen0205/CapRiCorn-1K .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CapRiCorn-1K, a benchmark for video captioning that evaluates both overall caption quality (accuracy and comprehensiveness) and subject referential consistency across temporal scales and diverse domains. It supports audiovisual and visual-only settings. Experiments on the benchmark show that current models struggle with these properties, that performance declines as video duration increases, and that the proposed evaluation metrics correlate strongly with downstream understanding and generation task performance.
Significance. A benchmark explicitly targeting subject referential consistency over long temporal horizons addresses a recognized gap in video captioning evaluation. If the dataset curation, metric definitions, and reported correlations are robust and reproducible, the work could provide a useful standardized testbed for model development in this area. The public GitHub release supports reproducibility.
minor comments (3)
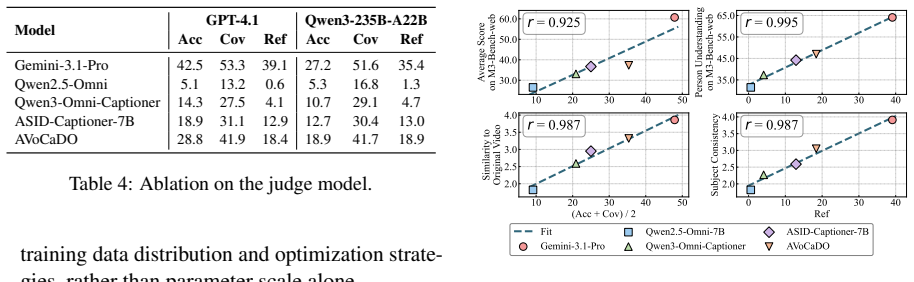
- [Abstract / Experiments] The abstract states that the metrics 'exhibit strong correlations' with downstream tasks; the main text should include the exact correlation coefficients, p-values, and the number of models/tasks used to support this claim (e.g., in the experiments or results section).
- [Methods / Evaluation Metrics] Clarify the precise definition and computation of 'subject referential consistency' (e.g., how coreference chains are identified and scored across frames) in the methods or evaluation-metrics subsection.
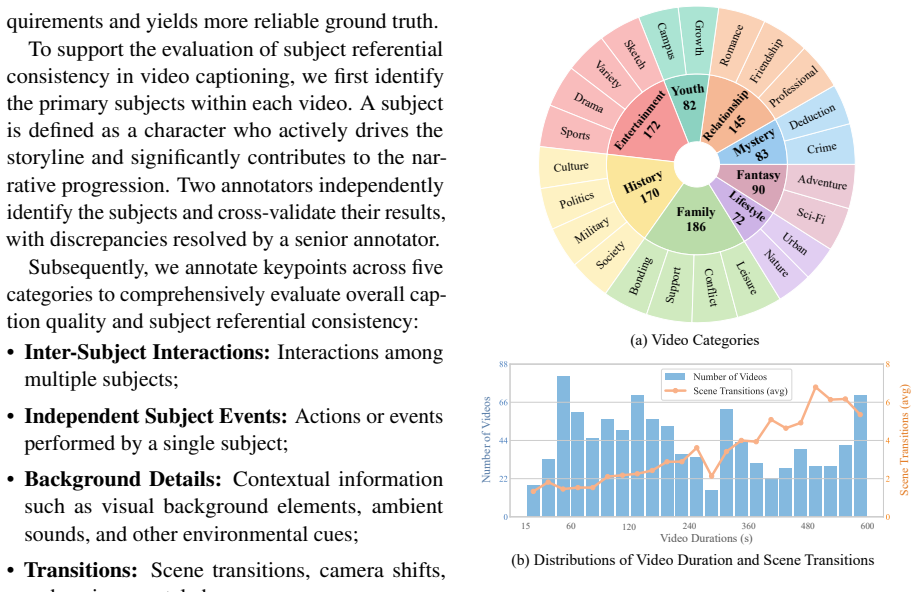
- [Dataset Construction] Provide more detail on video selection criteria, duration binning, and domain coverage to allow readers to assess potential selection bias.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of CapRiCorn-1K and the recommendation of minor revision. The referee summary accurately captures the benchmark's focus on caption quality, subject referential consistency, and correlations with downstream tasks. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
This is a benchmark paper whose central claims consist of empirical observations (model performance struggles, duration-dependent decline, metric-downstream correlations) obtained by running existing captioning models on the newly introduced CapRiCorn-1K dataset and metrics. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the supplied text. The benchmark design, annotations, and metrics are presented as independent contributions rather than quantities derived from the evaluated models themselves. The paper is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jacob Benesty, Jingdong Chen, Yiteng Huang, and Is- rael Cohen
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Jacob Benesty, Jingdong Chen, Yiteng Huang, and Is- rael Cohen. 2009. Pearson correlation coefficient. InNoise reduction in speech processing, pages 1–4. Springer. Wenhao Chai, Enxin Song, Yilun Du, Chenlin Meng, Vashisht Madhavan, Omer Bar-Tal, Jenq-Neng Hwang, Saining Xie, and Christopher D Manning
Pith/arXiv arXiv 2009
-
[2]
Auroracap: Efficient, performant video de- tailed captioning and a new benchmark.arXiv preprint arXiv:2410.03051. Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, and 1 others. 2024. Sharegpt4video: Improving video understanding and generation with better captions.Advances in Neural Info...
arXiv 2024
-
[3]
Fine-grained captioning of long videos through scene graph consolidation.arXiv preprint arXiv:2502.16427. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long con...
arXiv 2025
-
[4]
Shiyu Hu, Xuchen Li, Xuzhao Li, Jing Zhang, Yipei Wang, Xin Zhao, and Kang Hao Cheong
Toward long form audio-visual video under- standing.ACM Transactions on Multimedia Comput- ing, Communications and Applications, 20(9):1–26. Shiyu Hu, Xuchen Li, Xuzhao Li, Jing Zhang, Yipei Wang, Xin Zhao, and Kang Hao Cheong
-
[5]
Fiova: A multi-annotator benchmark for human-aligned video captioning.arXiv preprint arXiv:2410.15270. Daili Hua, Xizhi Wang, Bohan Zeng, Xinyi Huang, Hao Liang, Junbo Niu, Xinlong Chen, Quanqing Xu, and Wentao Zhang. 2026. Vabench: A comprehensive benchmark for audio-video generation. InProceed- ings of the IEEE/CVF Conference on Computer Vi- sion and Pa...
arXiv 2026
-
[6]
Video recap: Recursive captioning of hour- long videos. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 18198–18208. Yunheng Li, Hengrui Zhang, Meng-Hao Guo, Wenzhao Gao, Shaoyong Jia, Shaohui Jiao, Qibin Hou, and Ming-Ming Cheng. 2026. Towards universal video mllms with attribute-structured and quality-verifie...
arXiv 2026
-
[7]
Junfu Pu, Yuxin Chen, Teng Wang, and Ying Shan
X-instructblip: A framework for aligning x-modal instruction-aware representations to llms and emergent cross-modal reasoning.arXiv preprint arXiv:2311.18799. Junfu Pu, Yuxin Chen, Teng Wang, and Ying Shan
-
[8]
Omniscript: Towards audio-visual script gen- eration for long-form cinematic video.arXiv preprint arXiv:2604.11102. Qwen Team. 2026a. Qwen3.6-27B: Flagship-level cod- ing in a 27B dense model. Qwen Team. 2026b. Qwen3.6-35B-A3B: Agentic cod- ing power, now open to all. William M Rand. 1971. Objective criteria for the evalu- ation of clustering methods.Jour...
Pith/arXiv arXiv 1971
-
[9]
In Proceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 4246–4255
Audio-visual llm for video understanding. In Proceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 4246–4255. Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Yux- uan Wang, and Chao Zhang. 2024. video-salmonn: Speech-enhanced audio-visual large language mod- els.arXiv preprint arXiv:2406.1...
arXiv 2024
-
[10]
Changli Tang, Tianyi Wang, Fengyun Rao, Jing Lyu, and Chao Zhang
video-salmonn 2: Caption-enhanced audio- visual large language models.arXiv preprint arXiv:2506.15220. Changli Tang, Tianyi Wang, Fengyun Rao, Jing Lyu, and Chao Zhang. 2026. D-orca: Dialogue-centric op- timization for robust audio-visual captioning.arXiv preprint arXiv:2602.07960. Meituan LongCat Team, Bairui Wang, Bin Xiao, Bo Zhang, Bolin Rong, Borun C...
arXiv 2026
-
[11]
Longcat-flash-omni technical report.arXiv preprint arXiv:2511.00279. Qwen Team. 2026a. Qwen3.5: Accelerating productiv- ity with native multimodal agents. Tencent Hunyuan Team. 2026b. Script-a-video: Deep structured audio-visual captions via factorized streams and relational grounding.arXiv preprint arXiv:2604.11244. Jiawei Wang, Liping Yuan, Yuchen Zhang...
arXiv 2024
-
[12]
Omnivinci: Enhancing architecture and data for omni-modal understanding llm.arXiv preprint arXiv:2510.15870. Qilang Ye, Zitong Yu, Rui Shao, Xinyu Xie, Philip Torr, and Xiaochun Cao. 2024. Cat: Enhancing multi- modal large language model to answer questions in dynamic audio-visual scenarios. InEuropean Confer- ence on Computer Vision, pages 146–164. Sprin...
arXiv 2024
-
[13]
They share sufficiently specific matching **appearance attributes**, without considering actions
-
[14]
In this case, attribute differences must be ignored, and **all descriptions with the same subject name must always be grouped into a single cluster**
They contain the same subject name. In this case, attribute differences must be ignored, and **all descriptions with the same subject name must always be grouped into a single cluster**
-
[15]
a girl” should be treated as distinct subjects, because the only feature
Based on the video caption, it can be reasonably and clearly inferred that the descriptions refer to the same subject. Guidelines: - Note that identical descriptions do not necessarily refer to the same subject. - For example, multiple generic references such as “a girl” should be treated as distinct subjects, because the only feature "girl" is too vague ...
-
[16]
Be sure to include as much of the audio information as possible, and ensure that your descriptions of the audio and video are closely aligned
Provide a comprehensive description of all the content in the video, leaving out no details. Be sure to include as much of the audio information as possible, and ensure that your descriptions of the audio and video are closely aligned. Ensure coherence in the description of the same subject throughout
-
[17]
Include as much information from the audio as possible, and ensure that the descriptions of both audio and video are well- coordinated
Thoroughly describe everything in the video, capturing every detail. Include as much information from the audio as possible, and ensure that the descriptions of both audio and video are well- coordinated. Ensure coherence in the description of the same subject throughout
-
[18]
As you describe, you should also describe as much of the information in the audio as possible, and pay attention to the synchronization between the audio and video descriptions
Please describe all the information in the video without sparing every detail in it. As you describe, you should also describe as much of the information in the audio as possible, and pay attention to the synchronization between the audio and video descriptions. Ensure coherence in the description of the same subject throughout
-
[19]
Also, incorporate as much information from the audio as you can, and ensure that your descriptions of the audio and video are in sync
Offer a detailed description of the video, making sure to include every detail. Also, incorporate as much information from the audio as you can, and ensure that your descriptions of the audio and video are in sync. Ensure coherence in the description of the same subject throughout
-
[20]
Additionally, include as much of the audio content as you can, and make sure your descriptions of the audio and video are synchronized
Describe every aspect of the video in full detail, covering all the information it contains. Additionally, include as much of the audio content as you can, and make sure your descriptions of the audio and video are synchronized. Ensure coherence in the description of the same subject throughout
-
[21]
As you describe, ensure that you also cover as much information from the audio as possible, and be mindful of the synchronization between the audio and video as you do so
Please provide a thorough description of all the content in the video, including every detail. As you describe, ensure that you also cover as much information from the audio as possible, and be mindful of the synchronization between the audio and video as you do so. Ensure coherence in the description of the same subject throughout
-
[22]
While doing so, also include as much information from the audio as possible, ensuring that the descriptions of audio and video are well-synchronized
Give a detailed account of everything in the video, capturing all the specifics. While doing so, also include as much information from the audio as possible, ensuring that the descriptions of audio and video are well-synchronized. Ensure coherence in the description of the same subject throughout. Figure 13: List of prompts used to evaluate the audiovisua...
-
[23]
Describe the subjects, actions, scenes, objects, camera changes, and temporal progression as clearly as possible
Provide a comprehensive description of all visible content in the video, leaving out no important visual details. Describe the subjects, actions, scenes, objects, camera changes, and temporal progression as clearly as possible. Ensure coherence in the description of the same subject throughout
-
[24]
Include detailed information about the people or subjects, their appearances, actions, interactions, background, scene transitions, and changes over time
Thoroughly describe everything that can be observed in the video. Include detailed information about the people or subjects, their appearances, actions, interactions, background, scene transitions, and changes over time. Ensure coherence in the description of the same subject throughout
-
[25]
Focus on the subjects, their actions, spatial relationships, environment, objects, scene changes, and the overall temporal sequence of events
Please describe all visual information in the video in detail. Focus on the subjects, their actions, spatial relationships, environment, objects, scene changes, and the overall temporal sequence of events. Ensure coherence in the description of the same subject throughout
-
[26]
Ensure coherence in the description of the same subject throughout
Offer a detailed visual description of the video, making sure to cover important subjects, actions, interactions, background details, object appearances, camera movements, and scene transitions. Ensure coherence in the description of the same subject throughout
-
[27]
Pay attention to the identities and appearances of recurring subjects, their actions, interactions, locations, and how the scene evolves over time
Describe every visible aspect of the video in full detail. Pay attention to the identities and appearances of recurring subjects, their actions, interactions, locations, and how the scene evolves over time. Ensure coherence in the description of the same subject throughout
-
[28]
Describe what happens from beginning to end, and maintain consistent references to the same subjects throughout the description
Please provide a thorough visual description of the video, including all important details. Describe what happens from beginning to end, and maintain consistent references to the same subjects throughout the description. Ensure coherence in the description of the same subject throughout
-
[29]
Ensure that recurring subjects are described coherently and consistently
Give a detailed account of the visual content in the video, capturing the subjects, objects, actions, backgrounds, scene transitions, and temporal order of events. Ensure that recurring subjects are described coherently and consistently. Ensure coherence in the description of the same subject throughout. Figure 14: List of prompts used to evaluate the vis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.