Evaluating Vision-Language Models as a Zero-Shot Learning Alternative to You Only Look Once and Optical Character Recognition for Nigerian License Plate Recognition
Pith reviewed 2026-07-03 16:07 UTC · model grok-4.3
The pith
Gemini 2.0 Flash Exp and Qwen2.5-VL-7B-Instruct outperform other vision-language models on Nigerian license plate recognition in zero-shot tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
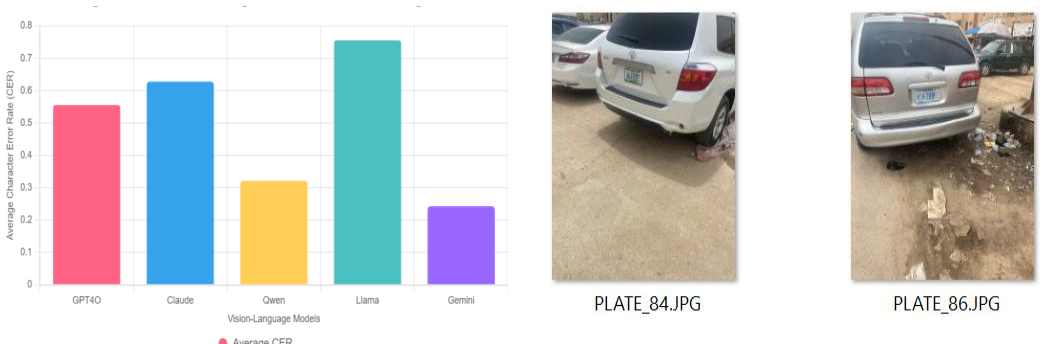
Using a curated dataset of 88 challenging real-world Nigerian license plate images, Gemini 2.0 Flash Exp and Qwen2.5-VL-7B-Instruct significantly outperform GPT-4o, Claude 4 Sonnet, and Llama 3.2 Vision 90b in both accuracy and robustness as measured by character error rate, supporting the use of vision-language models as a unified zero-shot solution for license plate recognition.
What carries the argument
Zero-shot prompting of vision-language models evaluated on an 88-image Nigerian license plate dataset with character error rate as the performance metric.
If this is right
- VLMs can function as a single-stage alternative that lowers resource demands compared to multi-stage pipelines.
- Zero-shot operation removes the requirement for large annotated datasets specific to Nigerian plates.
- The top models maintain accuracy in unstructured environments where traditional systems degrade.
- The results cast doubt on some performance claims issued by the model providers.
Where Pith is reading between the lines
- The same models could be tested on license plates from neighboring countries to check whether the advantage holds across similar regional formats.
- Post-processing the VLM text outputs with simple string rules might further reduce error rates for production use.
- Collecting a larger test set of several thousand images would allow statistical comparison of robustness across lighting, angle, and plate wear conditions.
Load-bearing premise
The 88 curated images capture the full range of real-world Nigerian license plate conditions and the VLM results indicate a genuine practical advantage over YOLO plus OCR without a direct comparison on the same data.
What would settle it
Running a standard YOLO detection plus OCR pipeline on the identical 88 images and comparing its character error rate directly against the rates reported for Gemini and Qwen.
Figures



read the original abstract
License Plate Recognition (LPR) systems are critical tools in traffic monitoring, security enforcement, and urban mobility management. Traditional LPR systems often rely on a multi-stage pipeline involving object detection using You Only Look Once (YOLO) and Optical Character Recognition (OCR), which suffer from limitations such as high resource demands, poor performance in unstructured environments, and the need for large annotated datasets. This study explores the potential of Vision-Language Models (VLMs) as a unified, zeroshot learning solution for Nigerian license plate recognition. Using a curated dataset of 88 challenging real-world images collected in Nigeria, we evaluate five selected VLMs: Gemini 2.0 Flash Exp (Google DeepMind), Qwen2.5-VL-7B-Instruct (Alibaba), GPT-4o (OpenAI), Claude 4 Sonnet (Anthropic), and Llama 3.2 Vision 90b (Meta). Results based on Character Error Rate (CER) reveal that Gemini and Qwen significantly outperform other models in both accuracy and robustness, on the challenging image scenarios. This work highlights the practical advantages of VLMs over YOLO+OCR, questions the claims by model providers, and compares the performances of the VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates five vision-language models (Gemini 2.0 Flash Exp, Qwen2.5-VL-7B-Instruct, GPT-4o, Claude 4 Sonnet, Llama 3.2 Vision 90b) as zero-shot solutions for Nigerian license plate recognition on a curated set of 88 real-world images, using Character Error Rate (CER) to identify Gemini and Qwen as superior, while asserting that VLMs provide practical advantages over traditional YOLO+OCR pipelines without large annotated datasets or high resource demands.
Significance. If the central empirical claims are strengthened with direct baselines, the work could usefully document VLM performance on a regionally specific LPR task with challenging images. The evaluation of multiple frontier VLMs and focus on Nigerian plates are positive aspects; however, the absence of any side-by-side YOLO+OCR measurement on the same data leaves the asserted practical superiority untested.
major comments (3)
- [Abstract and Results section] Abstract and Results section: the claim that VLMs offer 'practical advantages over YOLO+OCR' (including lower resource demands and better performance in unstructured environments) is unsupported because no YOLO detector or OCR pipeline is run on the identical 88 images; only intra-VLM CER values are reported.
- [Dataset description] Dataset description (likely §3): the 88-image set is described as 'challenging real-world' but no quantitative statistics (e.g., distribution of lighting, angles, occlusion, or plate format variants) or diversity metrics are provided to support representativeness claims.
- [Results section] Results section: CER comparisons among the five VLMs lack error bars, confidence intervals, or statistical significance tests, so the statement that Gemini and Qwen 'significantly outperform' the others cannot be assessed for robustness.
minor comments (2)
- [Abstract] The abstract states 'questions the claims by model providers' but the manuscript does not identify or test any specific provider claims.
- [Methods] Prompting strategy and exact VLM inference parameters (temperature, max tokens, etc.) are not detailed, limiting reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating planned revisions where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract and Results section] Abstract and Results section: the claim that VLMs offer 'practical advantages over YOLO+OCR' (including lower resource demands and better performance in unstructured environments) is unsupported because no YOLO detector or OCR pipeline is run on the identical 88 images; only intra-VLM CER values are reported.
Authors: We agree that a direct comparison on the same 88 images would be required to empirically support claims of practical superiority in performance or resource demands. The manuscript's statements on advantages derive from the zero-shot methodology, which avoids annotated training data required by YOLO+OCR pipelines. We will revise the abstract and results to present these as potential advantages of the zero-shot approach rather than demonstrated outcomes, and add a limitations paragraph noting the absence of a baseline YOLO+OCR run on this dataset. revision: yes
-
Referee: [Dataset description] Dataset description (likely §3): the 88-image set is described as 'challenging real-world' but no quantitative statistics (e.g., distribution of lighting, angles, occlusion, or plate format variants) or diversity metrics are provided to support representativeness claims.
Authors: We accept the point that quantitative characterization is missing. In revision we will add statistics on the 88 images, including counts or percentages for lighting conditions, viewing angles, occlusion levels, and Nigerian plate format variants, to substantiate the challenging real-world description. revision: yes
-
Referee: [Results section] Results section: CER comparisons among the five VLMs lack error bars, confidence intervals, or statistical significance tests, so the statement that Gemini and Qwen 'significantly outperform' the others cannot be assessed for robustness.
Authors: We acknowledge that without error bars or significance tests the robustness of the outperformance cannot be quantified. The reported CER values come from single evaluations per model. We will revise the results to remove unsubstantiated use of 'significantly' and include an explicit discussion of this limitation; bootstrap confidence intervals will be considered if they can be computed without additional model calls. revision: partial
Circularity Check
No circularity: purely empirical VLM evaluation on fixed dataset
full rationale
The paper reports Character Error Rate measurements of five VLMs on a fixed set of 88 curated images. No derivations, equations, fitted parameters, or theoretical claims appear in the provided text. The comparison to YOLO+OCR is asserted but not executed on the same data; this is an evidentiary gap, not a circular reduction of any result to its own inputs. No self-citations, ansatzes, or uniqueness theorems are invoked. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Character Error Rate is an appropriate and sufficient metric for license plate recognition performance.
Reference graph
Works this paper leans on
-
[1]
Automatic license plate recognition,
S.-L. Chang, L. S. Chen, Y. C. Chung, and S. W. Chen, “Automatic license plate recognition,” IEEE Trans. Intell. Transp. Syst., vol. 5, no. 1, pp. 42–53, Mar. 2004
2004
-
[2]
Learning-based approach for license plate recognition,
K. K. Kim, K. I. Kim, J. B. Kim, and H. J. Kim, “Learning-based approach for license plate recognition,” in Proc. Neural Networks for Signal Processing X, IEEE Signal Processing Society Workshop , Sydney, Australia, Dec. 2000, vol. 2, pp. 614–623
2000
-
[3]
Application -oriented license plate recognition,
G. S. Hsu, J. C. Chen, and Y. Z. Chung, “Application -oriented license plate recognition,” IEEE Trans. Veh. Technol. , vol. 62, no. 2, pp. 552 – 561, Feb. 2012
2012
-
[4]
Enhancing automated vehicle identification by integrating YOLO v8 and OCR techniques for high -precision license plate detection and recognition,
H. Moussaoui, N. E. Akkad, M. Benslimane, W. El-Shafai, A. Baihan, C. Hewage, and R. S. Rathore, “Enhancing automated vehicle identification by integrating YOLO v8 and OCR techniques for high -precision license plate detection and recognition,” Sci. Rep., vol. 14, no. 1, p. 14389, 2024
2024
-
[5]
Vehicle number plate detection and recognition using YOLO- v3 and OCR method,
R. Shashidhar, A. S. Manjunath, R. S. Kumar, M. Roopa, and S. B. Puneeth, “Vehicle number plate detection and recognition using YOLO- v3 and OCR method,” in Proc. IEEE Int. Conf. Mobile Networks and Wireless Commun. (ICMNWC), Dec. 2021, pp. 1–5
2021
-
[6]
Multi-task YOLO for vehicle colour recognition and automatic license plate recognition,
Y. L. Khor, Y. J. Wong, M. L. Tham, Y. C. Chang, B. H. Kwan, and K. C. Khor, “Multi-task YOLO for vehicle colour recognition and automatic license plate recognition,” in Proc. IEEE Int. Conf. Evolving and Adaptive Intelligent Syst. (EAIS), May 2024, pp. 1–7
2024
-
[7]
Disentangled generation network for enlarged license plate recognition and a unified dataset,
C. Li, X. Yang, G. Wang, A. Zheng, C. Tan, and J. Tang, “Disentangled generation network for enlarged license plate recognition and a unified dataset,” Computer Vision and Image Understanding , vol. 238, p. 103880, Jan. 2024
2024
-
[8]
Automatic number plate detection and recognition using YOLO world,
V. Agarwal and G. Bansal, “Automatic number plate detection and recognition using YOLO world,” Comput. Electr. Eng. , vol. 120, p. 109646, 2024
2024
-
[9]
Vision-language models for vision tasks: A survey,
J. Zhang, J. Huang, S. Jin, and S. Lu, “Vision-language models for vision tasks: A survey,” IEEE Trans. Pattern Anal. Mach. Intell., 2024
2024
-
[10]
RegionGPT: Towards region understanding vision language model,
Q. Guo et al., “RegionGPT: Towards region understanding vision language model,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 13796–13806
2024
-
[11]
Learning to prompt for vision- language models,
K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Learning to prompt for vision- language models,” Int. J. Comput. Vis. , vol. 130, no. 9, pp. 2337 –2348, 2022
2022
-
[12]
Ocean -OCR: Towards general OCR application via a vision-language model,
S. Chen et al., “Ocean -OCR: Towards general OCR application via a vision-language model,” arXiv preprint, arXiv:2501.15558, 2025
-
[13]
Patch n’pack: Navit, a vision transformer for any aspect ratio and resolution,
M. Dehghani et al., “Patch n’pack: Navit, a vision transformer for any aspect ratio and resolution,” Adv. Neural Inf. Process. Syst. , vol. 36, pp. 2252–2274, 2023
2023
-
[14]
J. Ye et al., “Ureader: Universal OCR -free visually -situated language understanding with multimodal large language model,” arXiv preprint, arXiv:2310.05126, 2023
-
[15]
Unlocking multimedia capabilities of gigantic pretrained language models,
B. Li, “Unlocking multimedia capabilities of gigantic pretrained language models,” in Proc. 1st Workshop on Large Generative Models Meet Multimodal Applications, Nov. 2023, pp. 3–4
2023
-
[16]
Automatic license plate recognition (ALPR): A state -of-the-art review,
S. Du, M. Ibrahim, M. Shehata, and W. Badawy, “Automatic license plate recognition (ALPR): A state -of-the-art review,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 23, no. 2, pp. 311 –325, Feb. 2013
2013
-
[17]
Advancing vehicle plate recognition: Multitasking visual language models with VehiclePaliGemma,
N. AlDahoul, M. J. Tan, R. R. Tera, H. A. Karim, C. H. Lim, M. K. Mishra, and Y. Zaki, “Advancing vehicle plate recognition: Multitasking visual language models with VehiclePaliGemma,” arXiv preprint arXiv:2412.14197, Dec. 14, 2024
-
[18]
Gemini 2.0: A new AI model for the agentic era,
Google DeepMind, “Gemini 2.0: A new AI model for the agentic era,” Google Blog , Dec. 2024. [Online]. Available: https://blog.google/technology/google-deepmind/google-gemini-ai- update-december-2024/
2024
-
[19]
Qwen Team, Alibaba Cloud, “Qwen2.5 -VL technical report,” arXiv preprint arXiv:2502.13923, 2025. [Online]. Available: https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Gemini 2.0 model updates: 2.0 Flash, Flash-Lite, Pro Experimental,
Google DeepMind, “Gemini 2.0 model updates: 2.0 Flash, Flash-Lite, Pro Experimental,” Google Blog , Feb. 2025. [Online]. Available: https://blog.google/technology/google-deepmind/gemini-model-updates- february-2025/
2025
-
[21]
Llama 3.2: Revolutionizing edge AI and vision with open, customizable models,
Meta AI, “Llama 3.2: Revolutionizing edge AI and vision with open, customizable models,” Meta AI Blog , Sept. 2024. [Online]. Available: https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile- devices/
2024
-
[22]
Holistic recognition of low -quality license plates by CNN using track annotated data,
J. Špaňhel, J. Sochor, R. Juránek, A. Herout, L. Maršík, and P. Zemčík, “Holistic recognition of low -quality license plates by CNN using track annotated data,” in Proc. 14th IEEE Int. Conf. on Advanced Video and Signal Based Surveillance (AVSS), Aug. 29–Sep. 1, 2017, pp. 1–6
2017
-
[23]
A training -free framework for video license plate tracking and recognition with only one -shot,
H. Ding, Q. Wang, J. Gao, and Q. Li, “A training -free framework for video license plate tracking and recognition with only one -shot,” arXiv preprint arXiv:2408.05729, Aug. 11, 2024
-
[24]
Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL!,
Qwen Team, “Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL!,” Qwen Blog,
-
[25]
Available: https://qwenlm.github.io/blog/qwen2.5-vl/
[Online]. Available: https://qwenlm.github.io/blog/qwen2.5-vl/
-
[26]
Beyond OCR+ VQA: Towards end -to-end reading and reasoning for robust and accurate TextVQA,
G. Zeng, Y. Zhang, Y. Zhou, X. Yang, N. Jiang, G. Zhao, W. Wang, and X.-C. Yin, “Beyond OCR+ VQA: Towards end -to-end reading and reasoning for robust and accurate TextVQA,” Pattern Recognition, vol. 138, p. 109337, Jun. 2023
2023
-
[27]
The ultimate guide to VLM evaluation metrics, datasets, and benchmarks,
LearnOpenCV, “The ultimate guide to VLM evaluation metrics, datasets, and benchmarks,” LearnOpenCV, 2025. [Online]. Available: https://learnopencv.com/vlm-evaluation-metrics/
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.