Skill Weaving: Efficient LLM Improvement via Modular Skillpacks
Pith reviewed 2026-05-22 05:51 UTC · model grok-4.3
The pith
SkillWeave partitions LLM capabilities into lightweight domain-specific modules that compress for fast multi-task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
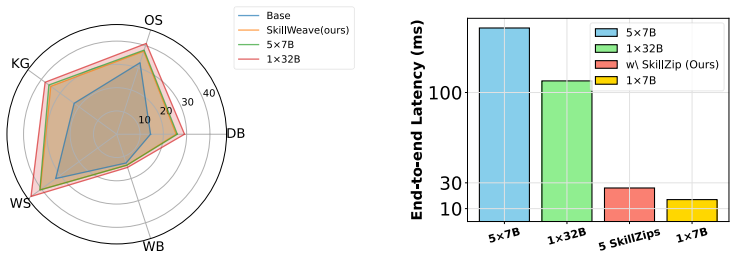
SkillWeave partitions the full capabilities of a general-purpose model into skillpacks -- lightweight, domain-specific delta modules -- that reorganize and refine the model's internal knowledge. SkillZip then compresses these skillpacks into a compact, inference-ready format. On multi-task and agentic benchmarks, this produces a 9B model that outperforms baselines and surpasses a 32B monolithic LLM while delivering up to 4x speedup under fixed memory budgets.
What carries the argument
Skillpacks as lightweight domain-specific delta modules that capture specialized knowledge, paired with SkillZip compression to keep them compact and fast at inference time.
If this is right
- Models can maintain or improve multi-domain results without growing in size or memory use.
- Specialized behavior becomes available even when inference must stay low-latency.
- A 9B model reaches performance levels previously seen only in much larger single models.
- The same modular structure works for both standard multi-task tests and agent-style tasks.
Where Pith is reading between the lines
- If modules can be swapped in and out, users could build custom versions for narrow use cases without full retraining.
- This approach might reduce reliance on training ever-larger base models by reusing and refining existing ones.
- Further tests on real applications such as code generation or decision support would show whether compression affects fine details.
Load-bearing premise
That a model's overall abilities can be split into separate domain modules and then compressed without hidden losses when the modules are combined again.
What would settle it
A direct comparison showing that the compressed skillpack version drops accuracy on a mixed-domain task relative to the original large model.
Figures




read the original abstract
Large language models increasingly require specialization across diverse domains, yet existing approaches struggle to balance multi-domain capacities with strict memory and inference constraints. In this work, we introduce SkillWeave, a modular improvement framework that enables LLMs to specialize under fixed memory budgets. SkillWeave partitions full capabilities of a general-purpose model into skillpacks -- lightweight, domain-specific delta modules -- that reorganize and refine the model's internal knowledge. For efficient deployment, SkillWeave integrates SkillZip to compress skillpacks into compact and inference-ready format, enabling strong multi-domain performance with low-latency execution. On multi-task and agentic benchmarks, a 9B SkillWeave model outperforms several baselines and even surpasses a 32B monolithic LLM, while achieving up to 4x speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkillWeave, a modular framework that partitions the capabilities of a general-purpose LLM into lightweight domain-specific delta modules called skillpacks. These are compressed via SkillZip to enable strong multi-domain performance under fixed memory budgets. The central claim is that a 9B SkillWeave model outperforms several baselines and even a 32B monolithic LLM on multi-task and agentic benchmarks while achieving up to 4x speedup.
Significance. If the results hold after verification, this would be a notable contribution to efficient LLM specialization and deployment. The skillpack partitioning plus compression approach could allow high multi-domain capability without scaling model size or memory, with practical value for resource-constrained settings. The work introduces the novel concepts of skillpacks and SkillZip as concrete mechanisms for modular improvement.
major comments (2)
- [§4 (Experiments)] §4 (Experiments): The headline result that the 9B SkillWeave model surpasses a 32B monolithic LLM rests on the fidelity of SkillZip compression across multiple active skillpacks, yet no ablation is presented comparing compressed versus uncompressed skillpack performance on the same tasks. This omission is load-bearing because even modest per-skill loss could compound and invalidate the fixed-memory comparison.
- [§3.2 (SkillZip)] §3.2 (SkillZip): The compression procedure is described only at a high level with no specification of the algorithm (quantization bit-width, pruning criteria, or distillation objective), no reported compression ratios, and no fidelity metrics (e.g., per-skillpack accuracy retention). These details are required to evaluate whether the 9B-vs-32B outperformance holds under the claimed memory constraints.
minor comments (2)
- [Abstract] Abstract: The claim that skillpacks 'reorganize and refine the model's internal knowledge' is vague; a brief mechanistic description of how the delta modules achieve this would improve precision.
- [Related Work] Related Work: Additional citations to prior parameter-efficient fine-tuning and modular adaptation literature would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and indicate how we plan to revise the paper to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments): The headline result that the 9B SkillWeave model surpasses a 32B monolithic LLM rests on the fidelity of SkillZip compression across multiple active skillpacks, yet no ablation is presented comparing compressed versus uncompressed skillpack performance on the same tasks. This omission is load-bearing because even modest per-skill loss could compound and invalidate the fixed-memory comparison.
Authors: We agree that an ablation study directly comparing compressed versus uncompressed skillpack performance is important for validating the fixed-memory claims. In the revised manuscript we will add this ablation to §4, reporting performance on the multi-task and agentic benchmarks for the 9B model both with and without SkillZip compression. This will quantify any per-skill degradation and confirm whether the reported outperformance over the 32B baseline holds under the stated memory constraints. revision: yes
-
Referee: [§3.2 (SkillZip)] §3.2 (SkillZip): The compression procedure is described only at a high level with no specification of the algorithm (quantization bit-width, pruning criteria, or distillation objective), no reported compression ratios, and no fidelity metrics (e.g., per-skillpack accuracy retention). These details are required to evaluate whether the 9B-vs-32B outperformance holds under the claimed memory constraints.
Authors: We acknowledge that §3.2 currently provides only a high-level description of SkillZip. In the revision we will expand this section with the concrete algorithmic details, including the quantization bit-width, pruning criteria, and distillation objective. We will also report the achieved compression ratios and fidelity metrics such as per-skillpack accuracy retention on held-out validation tasks. These additions will allow readers to assess the memory constraints and performance trade-offs more precisely. revision: yes
Circularity Check
No significant circularity; claims anchored to external benchmarks
full rationale
The paper proposes SkillWeave as a modular partitioning of LLM capabilities into domain-specific skillpacks followed by SkillZip compression. Performance is asserted via results on multi-task and agentic benchmarks rather than any self-referential metric or fitted quantity. No equations, self-citations, or uniqueness theorems are supplied in the available text that would reduce the central claims to definitional tautologies or input fits. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
invented entities (2)
-
skillpacks
no independent evidence
-
SkillZip
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SkillZip applies full-quantization to delta compression, quantizing both the delta weights and their corresponding activation inputs... double smoothing strategy... channel-wise smoothing... truncated singular value decomposition (SVD)... rank-wise smoothing
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we compute a shared component through model-merging: ∆shared = Merge([∆1, …, ∆k])... subtract it from each delta
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. Llm.int8(): 8-bit ma- trix multiplication for transformers at scale.CoRR, abs/2208.07339. Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zong- han Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, W...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Self-training meets consistency: Improving llms’ reasoning with consistency-driven rationale evaluation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Asso- ciation for Computational Linguistics: Human Lan- guage Technologies (Volume 1: Long Papers). Junlin Li, Guodong Du, Jing Li, Sim Kuan Goh, Wenya Wang, Yequan Wang...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Simo Ryu, Seunghyun Seo, and Jaejun Yoo
Direct preference optimization: Your lan- guage model is secretly a reward model.Advances in Neural Information Processing Systems, 36:53728– 53741. Simo Ryu, Seunghyun Seo, and Jaejun Yoo. 2023. Efficient storage of fine-tuned models via low- rank approximation of weight residuals.CoRR, abs/2305.18425. Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, N...
-
[4]
Fusechat-3.0: Preference optimization meets heterogeneous model fusion.arXiv preprint arXiv:2503.04222. Ziyi Yang, Fanqi Wan, Longguang Zhong, Tianyuan Shi, and Xiaojun Quan. 2024b. Weighted-reward preference optimization for implicit model fusion. arXiv preprint arXiv:2412.03187. Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. 2023. Language mode...
-
[5]
mention the key- word ‘AI’ at least 3 times
We design diverse prompting formats with ex- plicit instruction constraints (e.g., “mention the key- word ‘AI’ at least 3 times”), and verify completions against corresponding structural rules—covering aspects such as keyword frequency, maximum length, repetition, banned tokens, format, para- graph structure, language tone and so on. 2) For loosely define...
work page 1979
-
[6]
Channel-wise Smoothing.We compute a domain-specific channel scaling vector ⃗ s∈ RCi based on the average absolute activation magnitude per channel: ⃗ si =f(mean(|X :,i|)), where f(·) is a monotonic mapping tuned for aggressive smoothing. We rescale: X←X· diag(s−1), W←diag(s)·W thus transferring channel-wise quantization difficulty from X to W . Unlike Smo...
work page 2023
-
[7]
Rank-wise Smoothing.we apply trun- cated singular value decomposition (SVD) to the smoothed weight matrix Wsmooth: Wsmooth ≈ URΣRV T R , A=U RΣ1/2 R , B= Σ 1/2 R V T R . And then apply a second-stage rank-wise smoothing: a appropriate orthogonal rotation matrix Q to dis- perses the energy evenly across dimensions:Arot = AQ, B rot =Q T B. The optimal Q sho...
work page 2024
-
[8]
Input X is first smoothed using precomputed s−1, and quantized to INT8/INT4 ˆXsmooth
-
[9]
The output is intermediate result in INT32 format
We then load the quantized matrix , and per- form the first INT8 GEMM: ˆXsmooth · ˆAsmooth → INT32. The output is intermediate result in INT32 format
-
[10]
Rather than dequantizing the INT32 result, we aggressively truncate it to INT8—thereby pre- serving throughput and maintaining compatibility with the next GEMM. This truncated INT8 matrix is then used as input to a second matrix multipli- cation with ˆBsmooth, again using Tensor Core ac- celeration: INT8· ˆBsmooth →INT32 . While, this second multiplicatio...
-
[11]
All scaling vectors and quantization param- eters are precomputed to minimize runtime over- head
-
[12]
To avoid latency from separate dequantization kernels, we fuse the dequantization step into the GEMM computation (Wang et al., 2024b), utilizing fast-dequantization strategies (Kim et al., 2022). This two-stage smoothing and hardware-aware execution pipeline forms the core of SkillZip, en- abling low-latency, high-accuracy inference across diverse domains...
work page 2022
-
[13]
Oracle Domain Labels.For fair compari- son with prior work, the main table assumes known domain labels, which is standard for multi-domain evaluation
-
[14]
Math” skillpack yields higher-quality output than routing to the “Dialogue
Learned Router.To approximate realistic scenarios where domain labels may be un- known, we additionally train a domain clas- sifier that predicts the skillpack to activate at inference time. Training the Routing ModelWe adopt Qwen2.5-0.5B as a lightweight routing model and attach a linear classification head. The model is fine-tuned for sequence classific...
-
[15]
There are 1000 milliseconds in 1 second.200 milliseconds / 1000 milliseconds/second = 0.2 seconds
First, let's convert the time from milliseconds to seconds. There are 1000 milliseconds in 1 second.200 milliseconds / 1000 milliseconds/second = 0.2 seconds
-
[16]
Next, we use the formula: number of samples = sampling rate * time. Given the sampling rate of 48 kHz and 0.2 seconds of sound, number of samples = 48,000 samples/second * 0.2 second = 9600 So you now have 9600 amplitude measurements from the extracted 200 milliseconds of sound. The answer is 9600. Generation: (with Dialogue SKillpack) Generation: (with M...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.