Toward Calibrated Mixture-of-Experts Under Distribution Shift
Pith reviewed 2026-06-26 17:20 UTC · model grok-4.3
The pith
Expert calibration ensures overall calibration for hard-routed mixture-of-experts models under a broad class of distribution shifts, but not for soft-routed models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Expert calibration is sufficient to ensure calibration of the overall model under a broad class of distribution shifts in hard-routed models, but is insufficient for calibrating soft-routed models. To address this, an adversarial reweighting that penalizes calibration errors of the routed aggregate under distribution shift improves the accuracy-calibration tradeoff both on average and on difficult subsets of the data, across model classes, prediction tasks, and distribution shifts.
What carries the argument
Adversarial reweighting that penalizes calibration errors of the routed aggregate under distribution shift, together with the sufficiency result for expert calibration in hard routing.
If this is right
- Hard-routed models achieve end-to-end calibration simply by calibrating each expert in isolation when shifts fall in the covered class.
- Soft-routed models require the additional adversarial penalty on the combined output to restore calibration under shifts.
- The reweighting procedure produces better accuracy-calibration tradeoffs on difficult data subsets without harming average performance.
- The approach applies uniformly across different model classes, tasks, and families of distribution shifts.
Where Pith is reading between the lines
- Designers facing strong distribution shift may prefer hard routing over soft routing when expert calibration is already available.
- The method could be extended by incorporating explicit shift detection to switch between expert-only calibration and the full adversarial penalty.
- Similar reweighting penalties might apply to other ensemble methods where routing or gating interacts with calibration.
Load-bearing premise
The distribution shifts encountered in practice must belong to the broad class for which expert calibration alone suffices in hard-routed models.
What would settle it
A controlled test in which experts are calibrated yet the hard-routed aggregate becomes miscalibrated on a shift outside the broad class, or the adversarial reweighting fails to improve calibration on a shift inside the class.
Figures
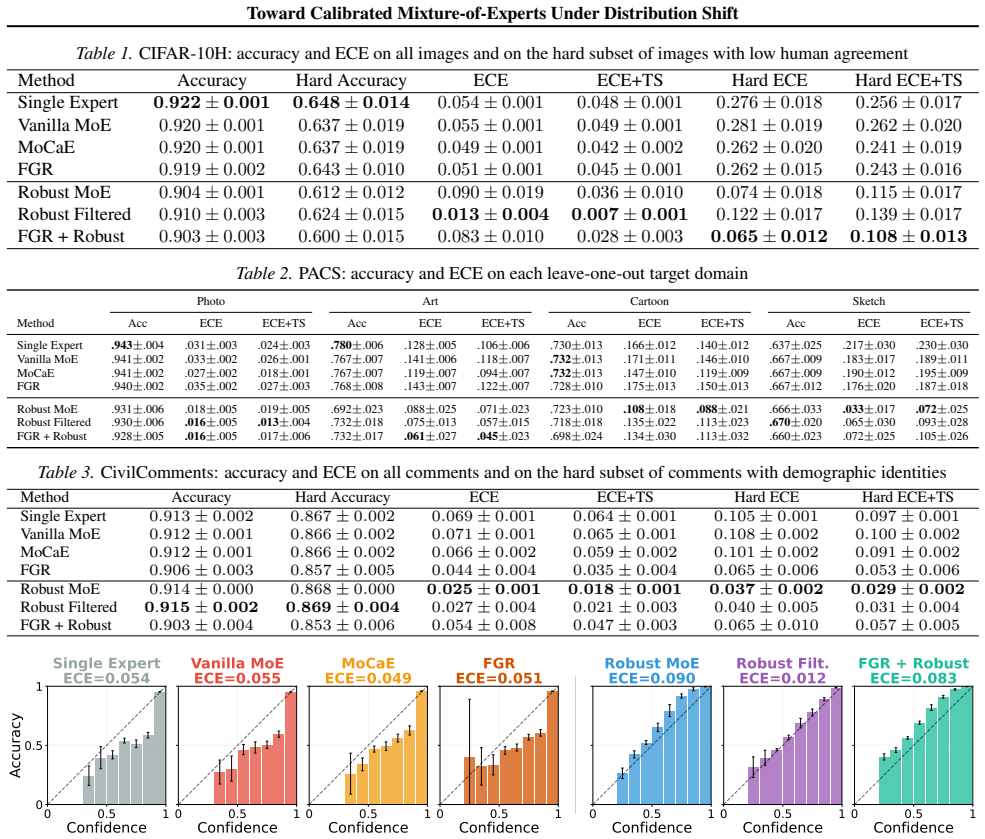
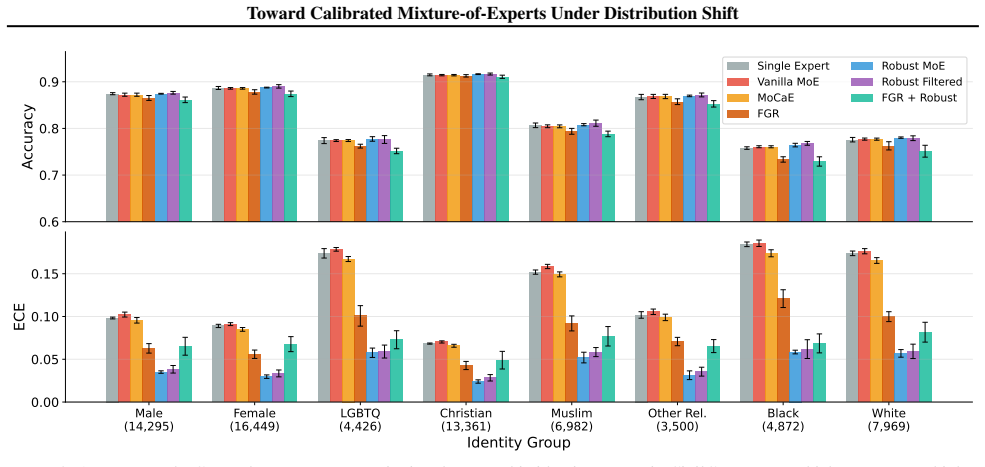
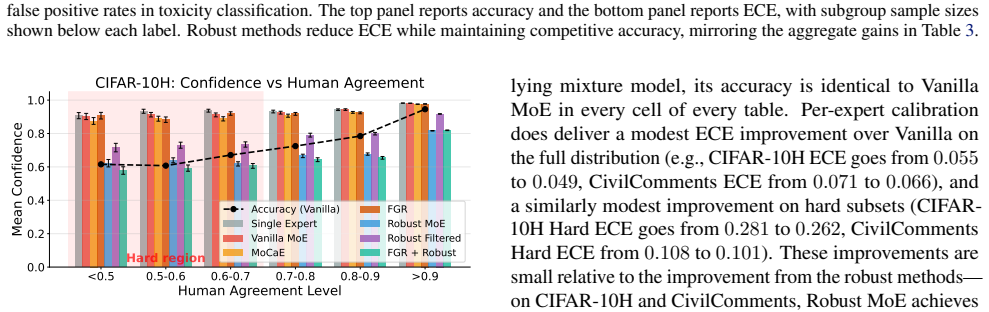
read the original abstract
Calibration aligns a model's predictive uncertainty with the frequencies of its empirical outcomes and is important for understanding and trusting reported probabilities. Recent work shows that enforcing calibration at the level of individual predictors can improve ensemble accuracy and calibration, with mixture-of-experts (MoE) models showing strong empirical improvements in particular; however, the conditions under which calibration helps MoE are not well understood. In this work, we study how MoE models behave under distribution shift, focusing on how routing mechanisms interact with expert-level calibration. We show that expert calibration is sufficient to ensure calibration of the overall model under a broad class of distribution shifts in hard-routed models, but is insufficient for calibrating soft-routed models. To address this, we propose an adversarial reweighting that penalizes calibration errors of the routed aggregate under distribution shift, and we demonstrate that it improves the accuracy-calibration tradeoff both on average and on difficult subsets of the data, across model classes, prediction tasks, and distribution shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that expert calibration ensures calibration of the overall model under a broad class of distribution shifts for hard-routed MoE models, but is insufficient for soft-routed models. It proposes an adversarial reweighting penalty on calibration errors of the routed aggregate under distribution shift and reports that this improves the accuracy-calibration tradeoff both on average and on difficult subsets, across model classes, tasks, and shifts.
Significance. If the sufficiency result is established with an explicit characterization of the shift class and the adversarial method is shown to be effective without introducing new failure modes, the work would clarify when expert-level calibration transfers to MoE aggregates and offer a practical tool for uncertainty estimation under shift.
major comments (2)
- [Abstract] Abstract: the central sufficiency claim for hard-routed models is load-bearing, yet the 'broad class' of distribution shifts is never characterized (no assumptions on invariance of expert conditionals P(y|x,expert), routing-label independence, or covariate vs. label shift). Without this, it is impossible to determine whether the class includes realistic shifts that would break the reduction to per-expert calibration on the target distribution.
- [Theoretical results section] Theoretical results section (presumed location of the main theorem): the claim reduces to the selected expert being calibrated on the shifted distribution for hard routing. The manuscript must state the exact conditions under which this holds and supply either a proof sketch or a counterexample showing when expert calibration fails to imply aggregate calibration.
minor comments (1)
- [Abstract] Abstract: the phrase 'across model classes, prediction tasks, and distribution shifts' is used without naming the concrete benchmarks or shift types; adding one sentence listing them would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The feedback highlights important areas where the theoretical claims require greater precision and explicit characterization. We address each major comment below and will revise the manuscript to strengthen the presentation of the sufficiency result and its conditions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central sufficiency claim for hard-routed models is load-bearing, yet the 'broad class' of distribution shifts is never characterized (no assumptions on invariance of expert conditionals P(y|x,expert), routing-label independence, or covariate vs. label shift). Without this, it is impossible to determine whether the class includes realistic shifts that would break the reduction to per-expert calibration on the target distribution.
Authors: We agree that the abstract's reference to a 'broad class' of shifts requires an explicit characterization to make the sufficiency claim rigorous. In the revision we will define the class by stating the necessary assumptions, including invariance of the expert conditionals P(y|x, expert) and routing-label independence, and we will discuss coverage of covariate versus label shift. This will clarify the scope and allow readers to assess applicability to realistic shifts. revision: yes
-
Referee: [Theoretical results section] Theoretical results section (presumed location of the main theorem): the claim reduces to the selected expert being calibrated on the shifted distribution for hard routing. The manuscript must state the exact conditions under which this holds and supply either a proof sketch or a counterexample showing when expert calibration fails to imply aggregate calibration.
Authors: The core reduction for hard routing is indeed that aggregate calibration follows from per-expert calibration on the target distribution when the routing decision is independent of the label. We will revise the theoretical results section to state these conditions explicitly and include a concise proof sketch. We will also add a counterexample demonstrating failure cases, for instance when the shift introduces label-dependent routing that violates the independence assumption. revision: yes
Circularity Check
No circularity; derivation is self-contained
full rationale
The paper states a sufficiency result (expert calibration implies aggregate calibration for hard-routed MoE under a broad class of shifts) as a mathematical claim, then introduces an independent adversarial reweighting penalty for the soft-routed case. No equation reduces a prediction to a fitted parameter by construction, no self-citation is load-bearing for the central implication, and no ansatz or renaming is smuggled in. The derivation chain stands on its own stated assumptions without circular reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Distribution shifts belong to a broad class for which expert calibration suffices in hard-routed MoE models
Reference graph
Works this paper leans on
-
[1]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[2]
International conference on machine learning , pages=
Glam: Efficient scaling of language models with mixture-of-experts , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[3]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Advancing Expert Specialization for Better MoE , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[4]
Forty-second International Conference on Machine Learning , year=
Joint MoE Scaling Laws: Mixture of Experts Can Be Memory Efficient , author=. Forty-second International Conference on Machine Learning , year=
-
[5]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models , author=. arXiv preprint arXiv:2401.06066 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
2021 , url=
Dmitry Lepikhin and HyoukJoong Lee and Yuanzhong Xu and Dehao Chen and Orhan Firat and Yanping Huang and Maxim Krikun and Noam Shazeer and Zhifeng Chen , booktitle=. 2021 , url=
2021
-
[7]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Journal of the American statistical Association , volume=
The well-calibrated Bayesian , author=. Journal of the American statistical Association , volume=. 1982 , publisher=
1982
-
[9]
Journal of Machine Learning Research , volume=
Metrics of calibration for probabilistic predictions , author=. Journal of Machine Learning Research , volume=
-
[10]
arXiv preprint arXiv:2309.12236 , year=
Smooth ECE: Principled reliability diagrams via kernel smoothing , author=. arXiv preprint arXiv:2309.12236 , year=
-
[11]
, author=
Measuring calibration in deep learning. , author=. CVPR workshops , volume=
-
[12]
Journal of the American statistical Association , volume=
Strictly proper scoring rules, prediction, and estimation , author=. Journal of the American statistical Association , volume=. 2007 , publisher=
2007
-
[13]
Monthly weather review , volume=
Verification of forecasts expressed in terms of probability , author=. Monthly weather review , volume=. 1950 , publisher=
1950
-
[14]
Journal of Applied Meteorology and Climatology , volume=
A new vector partition of the probability score , author=. Journal of Applied Meteorology and Climatology , volume=
-
[15]
Inherent Trade-Offs in the Fair Determination of Risk Scores
Inherent trade-offs in the fair determination of risk scores , author=. arXiv preprint arXiv:1609.05807 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Neural computation , volume=
Adaptive mixtures of local experts , author=. Neural computation , volume=. 1991 , publisher=
1991
-
[17]
Transactions on Machine Learning Research , issn=
MoCaE: Mixture of Calibrated Experts Significantly Improves Object Detection , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[18]
arXiv preprint arXiv:2505.18586 , year=
Guiding the Experts: Semantic Priors for Efficient and Focused MoE Routing , author=. arXiv preprint arXiv:2505.18586 , year=
-
[19]
arXiv preprint arXiv:2310.09762 , year=
Diversifying the mixture-of-experts representation for language models with orthogonal optimizer , author=. arXiv preprint arXiv:2310.09762 , year=
-
[20]
Advances in Neural Information Processing Systems , volume=
On the representation collapse of sparse mixture of experts , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
arXiv preprint arXiv:2112.14397 , year=
Evomoe: An evolutional mixture-of-experts training framework via dense-to-sparse gate , author=. arXiv preprint arXiv:2112.14397 , year=
-
[22]
Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society , pages=
Multiaccuracy: Black-box post-processing for fairness in classification , author=. Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society , pages=
2019
-
[23]
International Conference on Machine Learning , pages=
Multicalibration: Calibration for the (computationally-identifiable) masses , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[24]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[25]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Human uncertainty makes classification more robust , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[26]
Advances in Neural Information Processing Systems , volume=
Meta-dmoe: Adapting to domain shift by meta-distillation from mixture-of-experts , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
IEEE Transactions on Artificial Intelligence , year=
Mixture-of-Experts for Open Set Domain Adaptation: A Dual-Space Detection Approach , author=. IEEE Transactions on Artificial Intelligence , year=
-
[28]
Proceedings of the 31st ACM International Conference on Multimedia , pages=
Mixture-of-experts learner for single long-tailed domain generalization , author=. Proceedings of the 31st ACM International Conference on Multimedia , pages=
-
[29]
Advances in Neural Information Processing Systems , volume=
GraphMETRO: Mitigating Complex Graph Distribution Shifts via Mixture of Aligned Experts , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
1957 , institution=
A min-max solution of an inventory problem , author=. 1957 , institution=
1957
-
[31]
Operations research , volume=
Distributionally robust optimization under moment uncertainty with application to data-driven problems , author=. Operations research , volume=. 2010 , publisher=
2010
-
[32]
Journal of risk , volume=
Optimization of conditional value-at-risk , author=. Journal of risk , volume=
-
[33]
Proceedings of the IEEE international conference on computer vision , pages=
Focal loss for dense object detection , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[34]
Advances in neural information processing systems , volume=
Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection , author=. Advances in neural information processing systems , volume=
-
[35]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Varifocalnet: An iou-aware dense object detector , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Class-balanced loss based on effective number of samples , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[37]
Advances in neural information processing systems , volume=
Calibrating deep neural networks using focal loss , author=. Advances in neural information processing systems , volume=
-
[38]
arXiv preprint arXiv:2408.11598 , year=
Improving calibration by relating focal loss, temperature scaling, and properness , author=. arXiv preprint arXiv:2408.11598 , year=
-
[39]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Uncertainty Weighted Gradients for Model Calibration , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[40]
Advances in neural information processing systems , volume=
Large-scale methods for distributionally robust optimization , author=. Advances in neural information processing systems , volume=
-
[41]
New England Journal of Medicine , volume=
The clinician and dataset shift in artificial intelligence , author=. New England Journal of Medicine , volume=. 2021 , publisher=
2021
-
[42]
Journal of Causal Inference , volume=
A unifying causal framework for analyzing dataset shift-stable learning algorithms , author=. Journal of Causal Inference , volume=. 2022 , publisher=
2022
-
[43]
Political analysis , volume=
Entropy balancing for causal effects: A multivariate reweighting method to produce balanced samples in observational studies , author=. Political analysis , volume=. 2012 , publisher=
2012
-
[44]
Journal of Machine Learning Research , volume=
On tilted losses in machine learning: Theory and applications , author=. Journal of Machine Learning Research , volume=
-
[45]
Target-Agnostic Calibration under Distribution Shift with Frequency-Aware Gradient Rectification
Gradient Rectification for Robust Calibration under Distribution Shift , author=. arXiv preprint arXiv:2508.19830 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Advances in Neural Information Processing Systems , volume=
Soft calibration objectives for neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
arXiv preprint arXiv:2412.14711 , year=
Remoe: Fully differentiable mixture-of-experts with relu routing , author=. arXiv preprint arXiv:2412.14711 , year=
-
[48]
Transactions on Machine Learning Research , issn=
Where are we with calibration under dataset shift in image classification? , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[49]
Proceedings of the IEEE international conference on computer vision , pages=
Deeper, broader and artier domain generalization , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[50]
International conference on machine learning , pages=
Wilds: A benchmark of in-the-wild distribution shifts , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[51]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. arXiv preprint arXiv:1910.01108 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.