MER-R1: Multimodal Emotion Reasoning via Slow-Fast Thinking Synergy
Pith reviewed 2026-06-29 05:04 UTC · model grok-4.3
The pith
MER-R1 uses reinforcement learning to combine fast and slow thinking so explicit reasoning improves multimodal emotion recognition accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
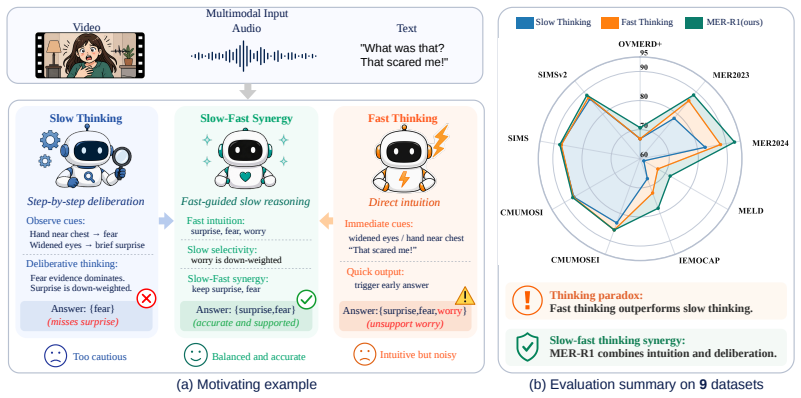
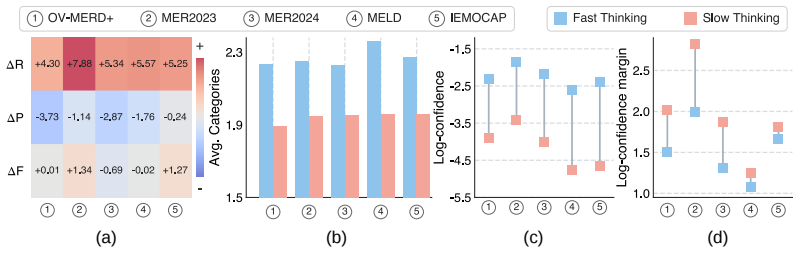
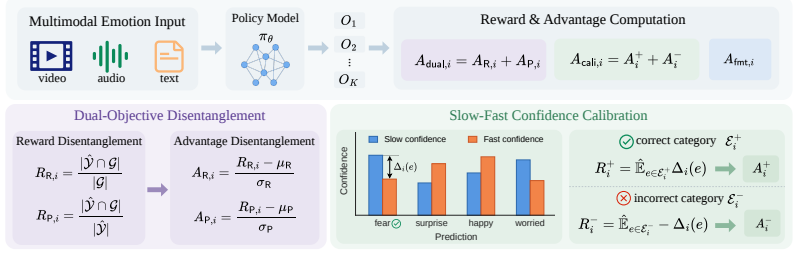
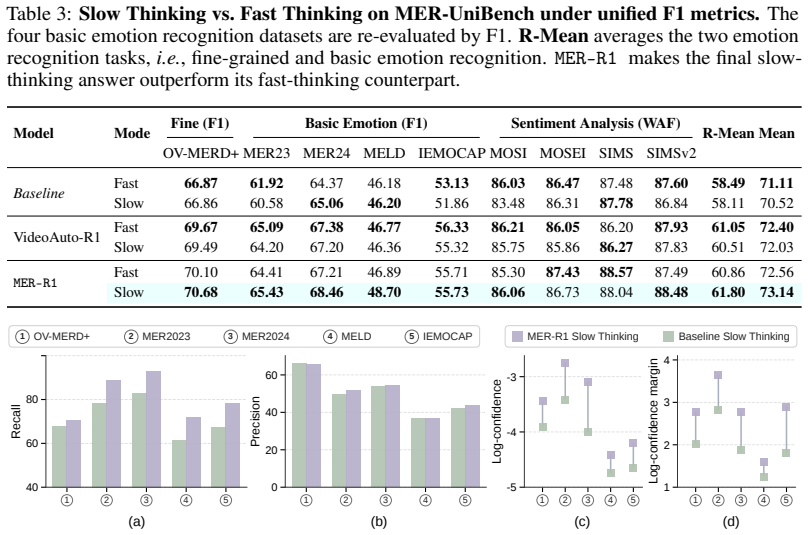
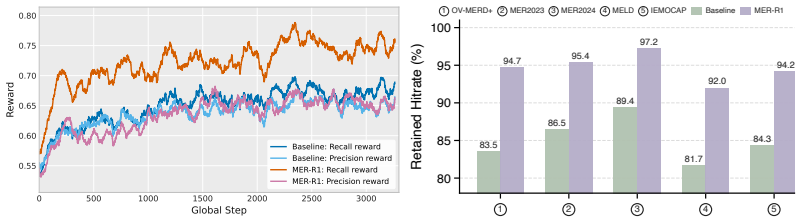
MER-R1 is a reinforcement learning framework that unifies the recall-oriented intuition of fast thinking with the precision-oriented selectivity of slow thinking. It does so through dual-objective disentanglement that treats recall and precision as independent optimization signals and through slow-fast confidence calibration that strengthens correct emotion categories while suppressing incorrect ones. The paper supplies a theoretical argument that this synergy reduces variance-induced interference during optimization.
What carries the argument
Dual-objective disentanglement that separates recall and precision into independent optimization signals, paired with slow-fast confidence calibration that aligns the final slow-thinking answer with fast-thinking intuition.
If this is right
- Recall and precision can be optimized together rather than traded off during training.
- The calibrated slow-thinking output strengthens correct emotions and weakens incorrect ones.
- Reasoning steps contribute directly to higher accuracy on emotion recognition tasks.
- The same slow-fast structure yields state-of-the-art results on both MER-UniBench and MME-Emotion.
Where Pith is reading between the lines
- The same disentanglement technique might be tested on other multimodal tasks that mix intuitive and deliberative reasoning.
- Variance reduction during optimization could be measured directly to check whether it explains the observed gains.
- The framework could be applied to non-emotion domains such as visual question answering to see if the recall-precision separation generalizes.
Load-bearing premise
Separating recall and precision into independent optimization signals allows joint improvement without hidden trade-offs between them.
What would settle it
An experiment in which the dual-objective version on MER-UniBench shows lower recall, lower precision, or higher variance than single-objective fast or slow baselines would falsify the claimed synergy.
Figures


read the original abstract
We find that explicit reasoning does not necessarily translate into better multimodal emotion recognition (MER) accuracy, even though it makes predictions more interpretable. Specifically, for reasoning-based MLLMs, fast thinking by triggering direct answers often outperforms slow thinking after deliberative reasoning. Our empirical analyses show that fast thinking improves recall with broader and more confident predictions, whereas slow thinking favors precision through conservative filtering of incorrect categories. Building on these insights, we propose MER-R1, a reinforcement learning framework that turns slow-fast complementarity into explicit optimization. Dual-objective disentanglement separates recall and precision into two optimization signals, allowing them to be jointly optimized rather than traded off against each other. Slow-fast confidence calibration further aligns the final slow-thinking answer with fast-thinking intuition, strengthening correct emotions while suppressing incorrect ones. In this way, MER-R1 unifies the recall-oriented intuition of fast thinking with the precision-oriented selectivity of slow thinking. We further provide theoretical justification for this synergy, showing that it mitigates variance-induced interference during optimization. Extensive experiments on MER-UniBench and MME-Emotion show that MER-R1 achieves state-of-the-art performance and makes reasoning genuinely benefit emotion recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that explicit reasoning in multimodal emotion recognition (MER) does not always improve accuracy, with fast thinking favoring recall and slow thinking favoring precision; it introduces MER-R1, an RL framework using dual-objective disentanglement to jointly optimize recall/precision signals, slow-fast confidence calibration, and a theoretical argument that this synergy mitigates variance-induced interference during optimization, achieving SOTA results on MER-UniBench and MME-Emotion while making reasoning beneficial for the task.
Significance. If the theoretical justification holds without circularity and the empirical results are robust, the work could advance multimodal reasoning by showing a concrete mechanism to convert complementary thinking modes into joint optimization gains rather than trade-offs, with potential implications for other reasoning-heavy vision-language tasks.
major comments (1)
- [Abstract] Abstract: the central claim rests on 'theoretical justification for this synergy, showing that it mitigates variance-induced interference during optimization' via dual-objective disentanglement, yet no derivation, explicit loss formulation, variance term, or independence assumptions are supplied; without these the argument cannot be checked for non-circularity or whether the claimed separation of recall/precision signals follows from the model rather than being presupposed.
minor comments (1)
- The abstract asserts SOTA performance and that 'reasoning genuinely benefit emotion recognition' but supplies no quantitative deltas, baseline comparisons, or statistical details to allow immediate assessment of effect size.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We agree that the abstract's brevity makes the theoretical claim difficult to verify and will revise it to include a concise outline of the key derivation, loss terms, and assumptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim rests on 'theoretical justification for this synergy, showing that it mitigates variance-induced interference during optimization' via dual-objective disentanglement, yet no derivation, explicit loss formulation, variance term, or independence assumptions are supplied; without these the argument cannot be checked for non-circularity or whether the claimed separation of recall/precision signals follows from the model rather than being presupposed.
Authors: We acknowledge the validity of this observation regarding the abstract. The full manuscript contains the explicit dual-objective loss formulation (Section 3.2), the variance term derivation in Theorem 1, and the independence assumptions in the accompanying proof. These elements demonstrate that the recall/precision separation arises from the disentangled RL objectives rather than being presupposed, and that the synergy reduces variance-induced interference without circularity. To address the referee's concern, we will expand the abstract with a brief summary of these components so the central claim can be evaluated directly from the abstract. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and provided text describe empirical observations on fast vs. slow thinking, introduce dual-objective disentanglement and slow-fast calibration as optimization mechanisms, and assert a theoretical justification for variance mitigation without supplying equations, self-citations, or derivations. No load-bearing step reduces by construction to fitted inputs, self-definitions, or author-overlapping citations; the claimed synergy is presented as following from stated empirical patterns and external experiments on MER-UniBench/MME-Emotion rather than presupposed by the framework itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, et al. Qwen2.5-omni technical report.arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
MIT press, 2000
Rosalind W Picard.Affective computing. MIT press, 2000
2000
-
[5]
Mer 2025: When affective computing meets large language models
Zheng Lian, Rui Liu, Kele Xu, Bin Liu, Xuefei Liu, Yazhou Zhang, Xin Liu, Yong Li, Zebang Cheng, Haolin Zuo, et al. Mer 2025: When affective computing meets large language models. InACM MM, 2025
2025
-
[6]
Yuntao Shou, Tao Meng, Wei Ai, and Keqin Li. Multimodal large language models meet multimodal emotion recognition and reasoning: A survey.arXiv preprint arXiv:2509.24322, 2025
-
[7]
Mer 2023: Multi-label learning, modality robustness, and semi-supervised learning
Zheng Lian, Haiyang Sun, Licai Sun, Kang Chen, Mngyu Xu, Kexin Wang, Ke Xu, Yu He, Ying Li, Jinming Zhao, et al. Mer 2023: Multi-label learning, modality robustness, and semi-supervised learning. InACM MM, 2023
2023
-
[8]
Mer 2024: Semi-supervised learning, noise robustness, and open-vocabulary multimodal emotion recognition
Zheng Lian, Haiyang Sun, Licai Sun, Zhuofan Wen, Siyuan Zhang, Shun Chen, Hao Gu, Jinming Zhao, Ziyang Ma, Xie Chen, et al. Mer 2024: Semi-supervised learning, noise robustness, and open-vocabulary multimodal emotion recognition. InProceedings of the 2nd International Workshop on Multimodal and Responsible Affective Computing, 2024
2024
-
[9]
Meld: A multimodal multi-party dataset for emotion recognition in conversa- tions
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. Meld: A multimodal multi-party dataset for emotion recognition in conversa- tions. InACL, 2019
2019
-
[10]
Iemocap: Interactive emotional dyadic motion capture database.Language resources and evaluation, 42(4):335–359, 2008
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N Chang, Sungbok Lee, and Shrikanth S Narayanan. Iemocap: Interactive emotional dyadic motion capture database.Language resources and evaluation, 42(4):335–359, 2008
2008
-
[11]
Affectgpt: A new dataset, model, and benchmark for emotion understanding with multimodal large language models
Zheng Lian, Haoyu Chen, Lan Chen, Haiyang Sun, Licai Sun, Yong Ren, Zebang Cheng, Bin Liu, Rui Liu, Xiaojiang Peng, et al. Affectgpt: A new dataset, model, and benchmark for emotion understanding with multimodal large language models. InICML, 2025
2025
-
[12]
Ov-mer: Towards open-vocabulary multimodal emotion recognition
Zheng Lian, Haiyang Sun, Licai Sun, Haoyu Chen, Lan Chen, Hao Gu, Zhuofan Wen, Shun Chen, Siyuan Zhang, Hailiang Yao, et al. Ov-mer: Towards open-vocabulary multimodal emotion recognition. InICML, 2025
2025
-
[13]
Explainable multimodal emotion reasoning.CoRR, 2023
Zheng Lian, Licai Sun, Mingyu Xu, Haiyang Sun, Ke Xu, Zhuofan Wen, Shun Chen, Bin Liu, and Jianhua Tao. Explainable multimodal emotion reasoning.CoRR, 2023
2023
-
[14]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[15]
Zheng Lian, Fan Zhang, Yazhou Zhang, Jianhua Tao, Rui Liu, Haoyu Chen, and Xiaobai Li. Affectgpt-r1: Leveraging reinforcement learning for open-vocabulary multimodal emotion recognition.arXiv preprint arXiv:2508.01318, 2025
-
[16]
Qize Yang, Shimin Yao, Weixuan Chen, Shenghao Fu, Detao Bai, Jiaxing Zhao, Boyuan Sun, Bowen Yin, Xihan Wei, and Jingren Zhou. Humanomniv2: From understanding to omni-modal reasoning with context.arXiv preprint arXiv:2506.21277, 2025. 10
-
[17]
From system 1 to system 2: A survey of reasoning large language models.TPAMI, 2026
Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, et al. From system 1 to system 2: A survey of reasoning large language models.TPAMI, 2026
2026
-
[18]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, Bin Zhang, Ziyang Ma, Xipin Wei, Shuai Bai, Keqin Chen, Xuejing Liu, Peng Wang, Mingkun Yang, Dayiheng Liu, Xingzhang Ren, Bo ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Visual instruction tuning.NeurIPS, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.NeurIPS, 2024
2024
-
[21]
Parallel diffusion solver via residual dirichlet policy optimization.IEEE TPAMI, pages 1–17, 2026
Ruoyu Wang, Ziyu Li, Beier Zhu, Liangyu Yuan, Hanwang Zhang, Xun Yang, Xiaojun Chang, and Chi Zhang. Parallel diffusion solver via residual dirichlet policy optimization.IEEE TPAMI, pages 1–17, 2026
2026
-
[22]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, et al. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2503.07365, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Perception-aware policy optimization for multimodal reasoning
Zhenhailong Wang, Xuehang Guo, Sofia Stoica, Haiyang Xu, Hongru Wang, Hyeonjeong Ha, Xiusi Chen, Yangyi Chen, Ming Yan, Fei Huang, et al. Perception-aware policy optimization for multimodal reasoning. InICLR, 2026
2026
-
[24]
Visual-rft: Visual reinforcement fine-tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-rft: Visual reinforcement fine-tuning. InICCV, 2025
2025
-
[25]
Vl- rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl- rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning. InNeurIPS, 2025
2025
-
[26]
Shuming Liu, Mingchen Zhuge, Changsheng Zhao, Jun Chen, Lemeng Wu, Zechun Liu, Chenchen Zhu, Zhipeng Cai, Chong Zhou, Haozhe Liu, et al. Videoauto-r1: Video auto reasoning via thinking once, answering twice.arXiv preprint arXiv:2601.05175, 2026
-
[27]
Emotion-llama: Multimodal emotion recognition and reasoning with instruction tuning.NeurIPS, 2024
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, and Alexander Hauptmann. Emotion-llama: Multimodal emotion recognition and reasoning with instruction tuning.NeurIPS, 2024
2024
-
[28]
Benchmarking and bridging emotion conflicts for multimodal emotion reasoning
Zhiyuan Han, Beier Zhu, Yanlong Xu, Peipei Song, and Xun Yang. Benchmarking and bridging emotion conflicts for multimodal emotion reasoning. InACM MM, 2025
2025
-
[29]
Mme-emotion: A holistic evaluation benchmark for emotional intelligence in multimodal large language models
Fan Zhang, Zebang Cheng, Chong Deng, Haoxuan Li, Zheng Lian, Qian Chen, Huadai Liu, Wen Wang, Yi-Fan Zhang, Renrui Zhang, et al. Mme-emotion: A holistic evaluation benchmark for emotional intelligence in multimodal large language models. InICLR, 2026
2026
-
[30]
Jiaxing Zhao, Xihan Wei, and Liefeng Bo. R1-omni: Explainable omni-multimodal emotion recognition with reinforcing learning.arXiv preprint arXiv:2503.05379, 2025
-
[31]
Emotion-coherent reasoning for multimodal llms via emotional rationale verifier
Hyeongseop Rha, Jeong Hun Yeo, Yeonju Kim, and Yong Man Ro. Emotion-coherent reasoning for multimodal llms via emotional rationale verifier. InAAAI, 2026
2026
-
[32]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models.arXiv preprint arXiv:2311.07919, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Salmonn: Towards generic hearing abilities for large language models
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. Salmonn: Towards generic hearing abilities for large language models. In ICLR, 2024
2024
-
[34]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InCVPR, 2024
2024
-
[35]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. InECCV, 2024
2024
-
[36]
Chat-univi: Unified visual representation empowers large language models with image and video understanding
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. In CVPR, 2024
2024
-
[37]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality.arXiv preprint arXiv:2304.14178, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Pandagpt: One model to instruction-follow them all
Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. Pandagpt: One model to instruction-follow them all. InTLLM, 2023
2023
-
[39]
Mosi: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos
Amir Zadeh, Rowan Zellers, Eli Pincus, and Louis-Philippe Morency. Mosi: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos. InCoRR, 2016
2016
-
[40]
Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph
AmirAli Bagher Zadeh, Paul Pu Liang, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. InACL, 2018
2018
-
[41]
Ch-sims: A chinese multimodal sentiment analysis dataset with fine-grained annotation of modality
Wenmeng Yu, Hua Xu, Fanyang Meng, Yilin Zhu, Yixiao Ma, Jiele Wu, Jiyun Zou, and Kaicheng Yang. Ch-sims: A chinese multimodal sentiment analysis dataset with fine-grained annotation of modality. InACL, 2020
2020
-
[42]
Make acoustic and visual cues matter: Ch-sims v2
Yihe Liu, Ziqi Yuan, Huisheng Mao, Zhiyun Liang, Wanqiuyue Yang, Yuanzhe Qiu, Tie Cheng, Xiaoteng Li, Hua Xu, and Kai Gao. Make acoustic and visual cues matter: Ch-sims v2. 0 dataset and av-mixup consistent module. InICMI, 2022
2022
-
[43]
Unsupervised visual chain-of-thought reasoning via preference optimization
Kesen Zhao, Beier Zhu, Qianru Sun, and Hanwang Zhang. Unsupervised visual chain-of-thought reasoning via preference optimization. InICCV, 2025
2025
-
[44]
I’ll tell you, it’s not easy for a woman who has divorced and is raising a child to find a partner
Xingyu Zhu, Kesen Zhao, Liang Yi, Shuo Wang, Zhicai Wang, Beier Zhu, Hanwang Zhang, and Xiangnan He. Look carefully: Adaptive visual reinforcements in multimodal large language models for hallucination mitigation. InICLR, 2026. 12 Appendix A Theoretical analysis of dual-objective disentanglement We provide a theoretical analysis of the dual-objective dise...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.