Towards Lightweight Reliability: Using Soft Prompts for Hallucination Mitigation in Large Language Models
Pith reviewed 2026-06-28 18:30 UTC · model grok-4.3
The pith
Soft prompts trained with contrastive loss can reduce hallucinations in LLMs while preserving factual recall on generative QA tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
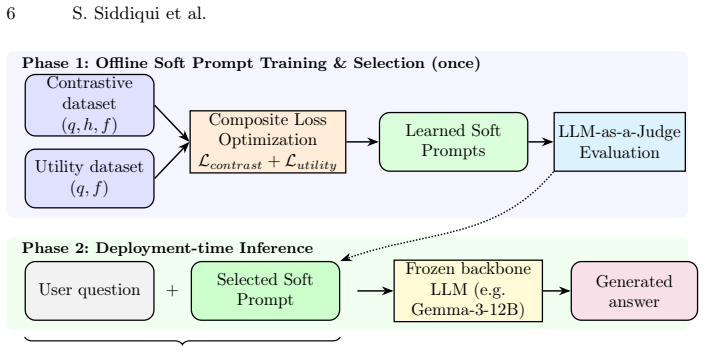
RCSP trains soft prompts via a composite loss incorporating contrastive loss, curriculum learning, and KL regularization to simultaneously suppress hallucinations, promote abstention under uncertainty, and preserve factual recall, resulting in generally superior F-scores over baselines on five generative QA datasets when applied to Gemma 3 and Llama 3.1 models.
What carries the argument
Responsible Contrastive Soft Prompting (RCSP), a soft-prompt tuning procedure whose composite loss balances hallucination suppression, abstention, and factual recall.
Load-bearing premise
The LLM-as-a-Judge evaluation on the five QA datasets accurately measures hallucination, abstention, and recall in a way that matches human judgment.
What would settle it
Human evaluation of model outputs on the same five datasets that shows the LLM judge systematically over- or under-estimates hallucination rates compared to human raters.
Figures
read the original abstract
Large language models (LLMs) have seen widespread adoption across various domains, yet their reliability is frequently undermined by hallucinations - responses that are plausible-sounding but factually incorrect. In high-stakes domains, these errors can reduce trust and introduce real-world risk. To address this challenge, we present a parameter-efficient approach that uses soft prompts to mitigate hallucinated content and promote responsible abstention in generative question-answering (QA) tasks. Our method, called Responsible Contrastive Soft Prompting (RCSP), uses a composite loss to train soft prompts that balance three goals: suppressing hallucinatory content, encouraging abstention under uncertainty, and preserving or improving factual recall. To achieve these goals, we incorporate contrastive loss, curriculum learning, and KL regularization into our training mechanism. We evaluate our approach on five diverse generative QA datasets using an LLM-as-a-Judge framework. Experimental results on the Gemma 3 (12B) and Llama 3.1 (8B) backbones demonstrate that RCSP effectively balances factual recall with hallucination suppression and abstention, yielding a generally superior F-score over standard reasoning and instruction-based prompting baselines. Notably, these improvements are achieved by training only a fraction of the parameters required by other tuning techniques. Our results demonstrate that soft prompts provide a modular and computationally efficient path toward improving LLM reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
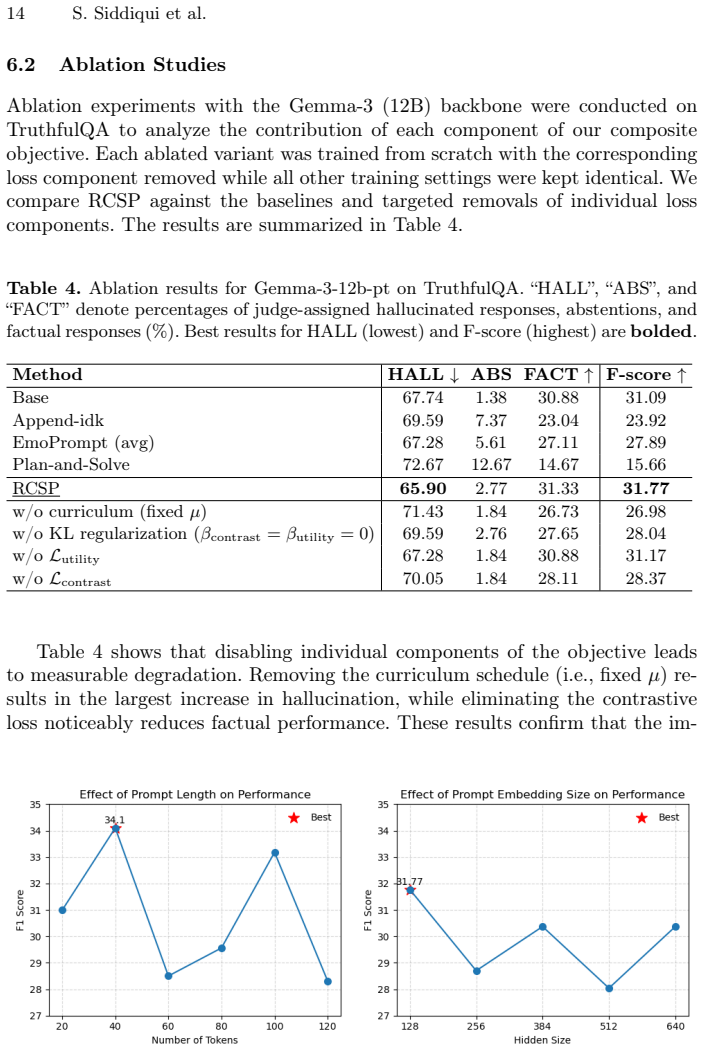
Summary. The paper introduces Responsible Contrastive Soft Prompting (RCSP), a parameter-efficient technique that trains soft prompts via a composite loss (contrastive + curriculum + KL regularization) to suppress hallucinations, encourage abstention under uncertainty, and preserve factual recall in generative QA. It reports results on five datasets using an LLM-as-a-Judge evaluation, claiming generally superior F-scores on Gemma-3 (12B) and Llama-3.1 (8B) backbones relative to standard reasoning and instruction baselines, while tuning only a small fraction of parameters.
Significance. If the empirical claims hold under validated metrics, the work would be significant for demonstrating a modular, low-parameter path to improved LLM reliability that explicitly trades off recall against suppression and abstention. The explicit composite-loss design and focus on parameter efficiency are clear strengths that distinguish it from full fine-tuning approaches.
major comments (2)
- [Experimental results / LLM-as-a-Judge framework] The headline result (superior F-scores via RCSP) is measured exclusively through an LLM-as-a-Judge framework on the five generative QA datasets. No human validation, inter-annotator agreement, judge-prompt ablation, or calibration against human labels is reported, which directly undermines whether the reported balance of recall, suppression, and abstention reflects genuine model behavior rather than judge bias.
- [Experimental results] The abstract and results description provide no quantitative details on effect sizes, variance across runs, statistical significance tests, or confidence intervals for the F-score improvements. This information is required to assess whether the gains are robust or could arise from post-hoc component selection in the composite loss.
minor comments (2)
- [Abstract] The abstract would benefit from reporting the actual F-score values (or deltas) rather than the qualitative claim of 'generally superior.'
- [Method] Notation for the three loss terms and their weighting schedule should be introduced with explicit equations in the method section to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Experimental results / LLM-as-a-Judge framework] The headline result (superior F-scores via RCSP) is measured exclusively through an LLM-as-a-Judge framework on the five generative QA datasets. No human validation, inter-annotator agreement, judge-prompt ablation, or calibration against human labels is reported, which directly undermines whether the reported balance of recall, suppression, and abstention reflects genuine model behavior rather than judge bias.
Authors: We agree that the absence of human validation or calibration is a limitation. LLM-as-a-Judge is used for scalability on generative outputs, but we will add a limitations section discussing potential judge bias and include a judge-prompt ablation study in the revision. A full human evaluation on all datasets is not feasible within this revision cycle due to annotation costs and time, though we plan it for future work. revision: partial
-
Referee: [Experimental results] The abstract and results description provide no quantitative details on effect sizes, variance across runs, statistical significance tests, or confidence intervals for the F-score improvements. This information is required to assess whether the gains are robust or could arise from post-hoc component selection in the composite loss.
Authors: We accept this point. Experiments used three random seeds; we will revise the results section and abstract to report mean F-scores with standard deviations, Cohen's d effect sizes, and p-values from paired statistical tests (e.g., Wilcoxon) against baselines. These details were computed internally and will be added to demonstrate robustness. revision: yes
Circularity Check
No circularity: empirical method with explicitly defined composite loss and external evaluation
full rationale
The paper presents RCSP as a training procedure on soft prompts using a composite loss (contrastive + curriculum + KL) whose components are standard techniques applied to the three stated goals; the central claim is an empirical F-score comparison on Gemma-3 and Llama-3.1 backbones against prompting baselines, measured on five QA datasets via LLM-as-Judge. No equations, uniqueness theorems, or predictions are shown that reduce by construction to fitted parameters or self-citations. The derivation chain consists of method definition followed by independent experimental measurement, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
free parameters (1)
- composite loss weights
axioms (1)
- domain assumption Soft prompts can be trained to control high-level behavioral properties such as hallucination rate and abstention in frozen LLMs
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 2013 Conference on Empirical Meth- ods in Natural Language Processing
Berant, J., Chou, A., Frostig, R., Liang, P.: Semantic parsing on Freebase from question-answer pairs. In: Proceedings of the 2013 Conference on Empirical Meth- ods in Natural Language Processing. pp. 1533–1544 (2013) 18 S. Siddiqui et al
2013
-
[2]
Bhaila, K., Van, M.H., Wu, X.: Soft prompting for unlearning in large language models. In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Tech- nologies (Volume 1: Long Papers). pp. 4046–4056 (2025)
2025
-
[3]
In: Practice and experience in advanced research computing 2023: Com- puting for the common good, pp
Boerner, T.J., Deems, S., Furlani, T.R., Knuth, S.L., Towns, J.: Access: Advancing innovation: Nsf’s advanced cyberinfrastructure coordination ecosystem: Services & support. In: Practice and experience in advanced research computing 2023: Com- puting for the common good, pp. 173–176 (2023)
2023
-
[4]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[5]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Choi, J.Y., Kim, J., Park, J.H., Mok, W.L., Lee, S.: Smop: Towards efficient and ef- fective prompt tuning with sparse mixture-of-prompts. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 14306– 14316 (2023)
2023
-
[6]
Chowdhury, N., Haque, M., Ahmed, A., Tasnim, N., Shihab, M.I.H., Rahman, S., Sadeque, F.: From facts to folklore: Evaluating large language models on bengali cultural knowledge. In: Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational L...
2025
-
[7]
In: The Twelfth International Conference on Learning Representations (2024)
Chuang, Y.S., Xie, Y., Luo, H., Kim, Y., Glass, J.R., He, P.: Dola: Decoding by contrasting layers improves factuality in large language models. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[8]
ACM Computing Surveys57(6), 1–39 (2025)
Das, B.C., Amini, M.H., Wu, Y.: Security and privacy challenges of large language models: A survey. ACM Computing Surveys57(6), 1–39 (2025)
2025
-
[9]
Advances in neural information processing systems36, 10088–10115 (2023)
Dettmers, T., Pagnoni, A., Holtzman, A., Zettlemoyer, L.: Qlora: Efficient fine- tuning of quantized llms. Advances in neural information processing systems36, 10088–10115 (2023)
2023
-
[10]
In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidi- rectional transformers for language understanding. In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). pp. 4171–4186 (2019)
2019
-
[11]
Internet of Things and Cyber-Physical Systems5, 1–46 (2025)
Ferrag, M.A., Alwahedi, F., Battah, A., Cherif, B., Mechri, A., Tihanyi, N., Bisz- tray,T.,Debbah,M.:Generativeaiincybersecurity:Acomprehensivereviewofllm applications and vulnerabilities. Internet of Things and Cyber-Physical Systems5, 1–46 (2025)
2025
-
[12]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
In: International conference on machine learning
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Ges- mundo, A., Attariyan, M., Gelly, S.: Parameter-efficient transfer learning for nlp. In: International conference on machine learning. pp. 2790–2799. PMLR (2019)
2019
-
[14]
In: International Conference on Learning Representations (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Conference on Learning Representations (2022)
2022
-
[15]
ACM Transactions on Information Systems43(2), 1–55 (2025) Lightweight Hallucination Mitigation Using Soft Prompts 19
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., et al.: A survey on hallucination in large language mod- els: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems43(2), 1–55 (2025) Lightweight Hallucination Mitigation Using Soft Prompts 19
2025
-
[16]
Jin, Q., Dhingra, B., Liu, Z., Cohen, W., Lu, X.: Pubmedqa: A dataset for biomed- ical research question answering. In: Proceedings of the 2019 Conference on Em- pirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). pp. 2567–2577 (2019)
2019
-
[17]
In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Joshi, M., Choi, E., Weld, D., Zettlemoyer, L.: TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 1601–1611 (2017)
2017
-
[18]
Why Language Models Hallucinate
Kalai, A.T., Nachum, O., Vempala, S.S., Zhang, E.: Why language models hallu- cinate. arXiv preprint arXiv:2509.04664 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
arXiv preprint arXiv:2311.15548 (2023)
Kang, H., Liu, X.Y.: Deficiency of large language models in finance: An empirical examination of hallucination. arXiv preprint arXiv:2311.15548 (2023)
-
[20]
Proceedings of the national academy of sciences114(13), 3521–3526 (2017)
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al.: Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences114(13), 3521–3526 (2017)
2017
-
[21]
Advances in neural information processing systems35, 22199–22213 (2022)
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners. Advances in neural information processing systems35, 22199–22213 (2022)
2022
-
[22]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Lester, B., Al-Rfou, R., Constant, N.: The power of scale for parameter-efficient prompt tuning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 3045–3059 (2021)
2021
-
[23]
Advances in neural information processing systems 33, 9459–9474 (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33, 9459–9474 (2020)
2020
-
[24]
arXiv preprint arXiv:2307.11760 (2023)
Li, C., Wang, J., Zhang, Y., Zhu, K., Hou, W., Lian, J., Luo, F., Yang, Q., Xie, X.: Large language models understand and can be enhanced by emotional stimuli. arXiv preprint arXiv:2307.11760 (2023)
-
[25]
Li, J., Cheng, X., Zhao, W.X., Nie, J.Y., Wen, J.R.: Halueval: A large-scale halluci- nationevaluationbenchmarkforlargelanguagemodels.In:Proceedingsofthe2023 Conference on Empirical Methods in Natural Language Processing. pp. 6449–6464 (2023)
2023
-
[26]
Advances in Neural Information Processing Systems36, 41451–41530 (2023)
Li, K., Patel, O., Viégas, F., Pfister, H., Wattenberg, M.: Inference-time inter- vention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems36, 41451–41530 (2023)
2023
-
[27]
In: Proceedings of the 60th annual meeting of the association for com- putational linguistics (volume 1: long papers)
Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th annual meeting of the association for com- putational linguistics (volume 1: long papers). pp. 3214–3252 (2022)
2022
-
[28]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Long, X., Zeng, J., Meng, F., Ma, Z., Zhang, K., Zhou, B., Zhou, J.: Generative multi-modal knowledge retrieval with large language models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 18733–18741 (2024)
2024
-
[29]
Luo, Y., Yang, Z., Meng, F., Li, Y., Zhou, J., Zhang, Y.: An empirical study of catastrophicforgettinginlargelanguagemodelsduringcontinualfine-tuning.IEEE Transactions on Audio, Speech and Language Processing33, 3776–3786 (2025)
2025
-
[30]
Advances in neural information processing systems36, 46534–46594 (2023) 20 S
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., et al.: Self-refine: Iterative refinement with self-feedback. Advances in neural information processing systems36, 46534–46594 (2023) 20 S. Siddiqui et al
2023
-
[31]
OpenAI (Apr 2025), https://openai.com/ index/gpt-4-1/, accessed: 2026-04-09
OpenAI: Introducing gpt-4.1 in the api. OpenAI (Apr 2025), https://openai.com/ index/gpt-4-1/, accessed: 2026-04-09
2025
-
[32]
Advances in neural information processing sys- tems35, 27730–27744 (2022)
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing sys- tems35, 27730–27744 (2022)
2022
-
[33]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Pandit, S., Xu, J., Hong, J., Wang, Z., Tianlong, C., Xu, K., Ding, Y.: MedHallu: A comprehensive benchmark for detecting medical hallucinations in large language models. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 2858–2873 (2025)
2025
-
[34]
Scientific Reports14(1), 30667 (2024)
Prottasha, N.J., Mahmud, A., Sobuj, M.S.I., Bhat, P., Kowsher, M., Yousefi, N., Garibay, O.O.: Parameter-efficient fine-tuning of large language models using se- mantic knowledge tuning. Scientific Reports14(1), 30667 (2024)
2024
-
[35]
Qin, S., Zhou, L., Sun, L., Wang, N.: Do large language models know when they lack knowledge? Electronics15(2), 253 (2026)
2026
-
[36]
Advances in neural information processing systems36, 53728–53741 (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems36, 53728–53741 (2023)
2023
-
[37]
In: Findings of the Association for Compu- tational Linguistics: EMNLP 2021
Shuster, K., Poff, S., Chen, M., Kiela, D., Weston, J.: Retrieval augmentation reduces hallucination in conversation. In: Findings of the Association for Compu- tational Linguistics: EMNLP 2021. pp. 3784–3803 (2021)
2021
-
[38]
Team, G., DeepMind, G.: Gemma 3 technical report. arXiv preprint arXiv:2503.19786 (2025), https://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Wang, D., Yang, K., Zhu, H., Yang, X., Cohen, A., Li, L., Tian, Y.: Learning personalized alignment for evaluating open-ended text generation. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 13274–13292 (2024)
2024
-
[40]
In: Proceedings of the 61st annual meeting of the association for compu- tational linguistics (volume 1: long papers)
Wang, L., Xu, W., Lan, Y., Hu, Z., Lan, Y., Lee, R.K.W., Lim, E.P.: Plan-and- solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. In: Proceedings of the 61st annual meeting of the association for compu- tational linguistics (volume 1: long papers). pp. 2609–2634 (2023)
2023
-
[41]
Measuring short-form factuality in large language models
Wei, J., Karina, N., Chung, H.W., Jiao, Y.J., Papay, S., Glaese, A., Schulman, J., Fedus, W.: Measuring short-form factuality in large language models. arXiv preprint arXiv:2411.04368 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Advances in neural information processing systems35, 24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022)
2022
-
[43]
arXiv preprint arXiv:2503.01332 (2025)
Wu, C.K., Tam, Z.R., Lin, C.Y., Chen, Y.N., Lee, H.y.: Answer, refuse, or guess? investigating risk-aware decision making in language models. arXiv preprint arXiv:2503.01332 (2025)
-
[44]
In: Proceed- ings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Zhang, H., Diao, S., Lin, Y., Fung, Y., Lian, Q., Wang, X., Chen, Y., Ji, H., Zhang, T.: R-tuning: Instructing large language models to say ‘i don’t know’. In: Proceed- ings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 7113–7139 (2024)
2024
-
[45]
Advances in neural information processing systems36, 46595–46623 (2023)
Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems36, 46595–46623 (2023)
2023
- [46]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.