Think in English, Answer in Korean: Efficient Adaptation of Multilingual Tool-Using Agents
Pith reviewed 2026-07-01 05:19 UTC · model grok-4.3
The pith
Adapting a post-trained multilingual model with four targeted techniques improves tool-use and reasoning in Korean-English agents while preserving general instruction following.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
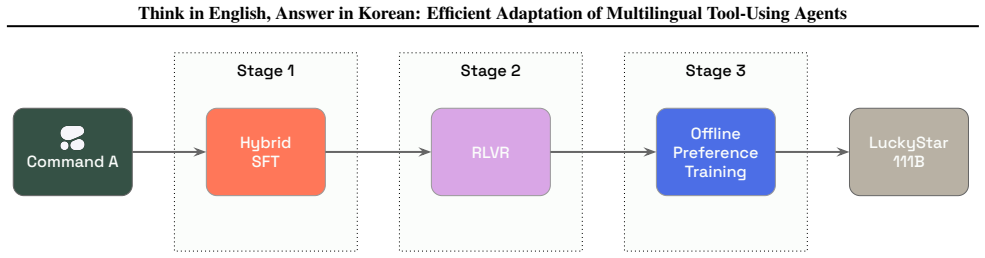
Applying multilingual supervised fine-tuning, reinforcement learning with verifiable rewards, language-consistency rewards, and 4-bit quantization to a post-trained model yields improved mathematical reasoning, function calling, and agentic natural-language-to-SQL performance while general Korean and English instruction-following quality stays intact.
What carries the argument
The four scaling choices of multilingual supervised fine-tuning, reinforcement learning with verifiable rewards for multi-step tool-use tasks, language-consistency rewards for Korean user-facing responses, and 4-bit quantization; these choices enable the performance gains under memory-constrained single-GPU deployment.
If this is right
- The adapted model supports single-GPU serving through 4-bit quantization.
- Preamble conditioning allows switching between concise replies and extended tool-oriented reasoning.
- Mathematical reasoning, function calling, and agentic natural-language-to-SQL all improve together.
- General instruction-following quality remains intact in both Korean and English.
Where Pith is reading between the lines
- Post-trained models can be specialized for verifiable agent workflows without a full pretraining run.
- Language-consistency rewards may prove necessary when user-facing output language must stay fixed across tasks.
- The same four choices could be tested on other language pairs or different base model sizes.
Load-bearing premise
The observed gains in tool-use and reasoning tasks result from the combination of multilingual supervised fine-tuning, reinforcement learning with verifiable rewards, language-consistency rewards, and 4-bit quantization rather than other factors or the base model's prior abilities.
What would settle it
An ablation experiment that removes the language-consistency rewards, retrains, and measures whether Korean response consistency and the reported task improvements both disappear would test the central attribution.
Figures

read the original abstract
We present LuckyStar 111B, a 111B-parameter hybrid reasoning model developed through a collaboration between Cohere and LG CNS for Korean-English enterprise agents under practical memory and serving constraints. The model trains from Cohere's fully post-trained Command A model rather than a new pretraining run, and uses preamble conditioning to switch between concise non-reasoning behavior and longer tool-oriented reasoning. We study four choices for scaling tool-using agents efficiently: multilingual supervised fine-tuning, reinforcement learning with verifiable rewards for multi-step tool-use tasks, language-consistency rewards for Korean user-facing responses, and 4-bit quantization for single-GPU serving. The adapted model improves mathematical reasoning, function calling, and agentic natural-language-to-SQL (NL2SQL) performance while preserving general Korean and English instruction-following quality. These results provide a practical recipe and failure-mode analysis for adapting post-trained multilingual models to verifiable agentic workflows under memory-constrained deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LuckyStar 111B, a 111B-parameter model adapted from Cohere's post-trained Command A checkpoint via preamble conditioning for switching between concise and tool-oriented reasoning modes. It studies four adaptation choices—multilingual supervised fine-tuning, RL with verifiable rewards on multi-step tool-use tasks, language-consistency rewards for Korean outputs, and 4-bit quantization—and claims that the resulting model improves mathematical reasoning, function calling, and agentic NL2SQL performance while preserving general Korean and English instruction-following quality. The work positions these choices as a practical recipe for memory-constrained enterprise agent deployment.
Significance. If the performance lifts can be causally attributed to the four listed interventions through controlled experiments, the paper would supply a concrete, reproducible recipe for efficient post-training adaptation of large multilingual models to verifiable agentic workflows. This would be of practical value for deployment under single-GPU constraints and could inform future work on language-consistent tool use.
major comments (2)
- [Abstract] Abstract: the central claim that the four techniques produce the reported improvements in math reasoning, function calling, and agentic NL2SQL cannot be evaluated because the manuscript supplies no baseline numbers for the starting Command A model on those exact tasks, no ablation tables removing one technique at a time, and no description of data splits, statistical tests, or evaluation protocols.
- [Abstract] The attribution of gains to the combination of multilingual SFT + RL with verifiable rewards + language-consistency rewards + 4-bit quantization is load-bearing for the paper's contribution, yet the text provides no evidence that all other training details were held fixed or that the base model's existing capabilities were controlled for.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger evidence in support of our claims. We agree that the abstract and manuscript require additional baselines, ablations, and protocol details to allow proper evaluation of the four adaptation techniques. We will revise the paper accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the four techniques produce the reported improvements in math reasoning, function calling, and agentic NL2SQL cannot be evaluated because the manuscript supplies no baseline numbers for the starting Command A model on those exact tasks, no ablation tables removing one technique at a time, and no description of data splits, statistical tests, or evaluation protocols.
Authors: We agree that the abstract as written does not contain these elements and that they are necessary to substantiate the central claim. The full manuscript reports results on the target tasks but does not include explicit baseline numbers for the unmodified Command A model on the exact same test sets, nor does it present ablation tables or detailed protocol descriptions. We will add (1) baseline performance of the starting Command A checkpoint on all reported tasks, (2) ablation tables that isolate each of the four techniques, and (3) a dedicated evaluation section describing data splits, metrics, statistical tests, and protocols. These additions will appear in both the abstract and the main body of the revised manuscript. revision: yes
-
Referee: [Abstract] The attribution of gains to the combination of multilingual SFT + RL with verifiable rewards + language-consistency rewards + 4-bit quantization is load-bearing for the paper's contribution, yet the text provides no evidence that all other training details were held fixed or that the base model's existing capabilities were controlled for.
Authors: We acknowledge that the current text does not explicitly document experimental controls. In the underlying experiments, only the four listed interventions were varied while all other hyperparameters, data, and training procedures remained fixed; the base Command A model served as the direct control. However, this information is not stated clearly enough. We will add a new subsection under Experiments that (a) confirms all non-intervention variables were held constant, (b) reports the base model's performance on the identical evaluation sets, and (c) describes how the four techniques were applied incrementally. These clarifications will be included in the revision. revision: yes
Circularity Check
No significant circularity; purely empirical adaptation results
full rationale
The paper reports empirical performance gains on math reasoning, function calling, and NL2SQL after applying multilingual SFT, RL with verifiable rewards, language-consistency rewards, and 4-bit quantization to the Command A base model. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content. All claims are grounded in external task benchmarks rather than any self-referential construction, satisfying the default expectation of non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2504.00698 , year=
Command. arXiv preprint arXiv:2504.00698 , year=. 2504.00698 , archivePrefix=
- [2]
-
[3]
2022 , eprint=
Training Language Models to Follow Instructions with Human Feedback , author=. 2022 , eprint=
2022
-
[4]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Ahmadian, Arash and Cremer, Chris and Gall. Back to Basics: Revisiting. arXiv preprint arXiv:2402.14740 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Advances in Neural Information Processing Systems , volume=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
2024 , eprint=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
2024
-
[7]
2025 , eprint=
OpenThoughts: Data Recipes for Reasoning Models , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning , author=. 2025 , eprint=
2025
-
[9]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
QwQ: Reflect Deeply on the Boundaries of the Unknown , url=
-
[11]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in. 2025 , eprint=
2025
-
[12]
Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-
Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and others , journal=. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-
-
[13]
Li, Jinyang and Hui, Binyuan and Qu, Ge and Yang, Jiaxi and Li, Binhua and Li, Bowen and Wang, Bailin and Qin, Bowen and Geng, Ruiying and Huo, Nan and others , booktitle=. Can
-
[14]
OmniSQL: Synthesizing High-Quality Text-to-
Li, Haoyang and Wu, Shang and Zhang, Xiaokang and Huang, Xinmei and Zhang, Jing and Jiang, Fuxin and Wang, Shuai and Zhang, Tieying and Chen, Jianjun and Shi, Rui and others , journal=. OmniSQL: Synthesizing High-Quality Text-to-
-
[15]
2025 , eprint=
Soft Best-of- n Sampling for Model Alignment , author=. 2025 , eprint=
2025
-
[16]
and Mao, Huanzhi and Ji, Charlie Cheng-Jie and Yan, Fanjia and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E
Patil, Shishir G. and Mao, Huanzhi and Ji, Charlie Cheng-Jie and Yan, Fanjia and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E. , booktitle=. The Berkeley Function Calling Leaderboard (
-
[17]
Claude 3.7 Sonnet , author=
-
[18]
American Invitational Mathematics Examination -
American Invitational Mathematics Examination -. American Invitational Mathematics Examination -. 2024 , month=
2024
-
[19]
Measuring Mathematical Problem Solving With the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , journal=. Measuring Mathematical Problem Solving With the
-
[20]
The Twelfth International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. The Twelfth International Conference on Learning Representations , year=
-
[21]
Son, Guijin and Lee, Hanwool and Kim, Sungdong and Kim, Seungone and Muennighoff, Niklas and Choi, Taekyoon and Park, Cheonbok and Yoo, Kang Min and Biderman, Stella , journal=
-
[22]
Measuring Massive Multitask Language Understanding
Measuring Massive Multitask Language Understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[23]
Think You Have Solved Question Answering? Try
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=. Think You Have Solved Question Answering? Try
-
[24]
Instruction-Following Evaluation for Large Language Models
Instruction-Following Evaluation for Large Language Models , author=. arXiv preprint arXiv:2311.07911 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , year=. Judging. 2306.05685 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.