Hard or Just Unreached? Diagnosing the Sampling Blind Spot in Math-Reasoning Difficulty Estimation
Pith reviewed 2026-06-26 20:40 UTC · model grok-4.3
The pith
Some math problems that no sampling seed solves are identifiable via residual-stream perturbations at matched compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
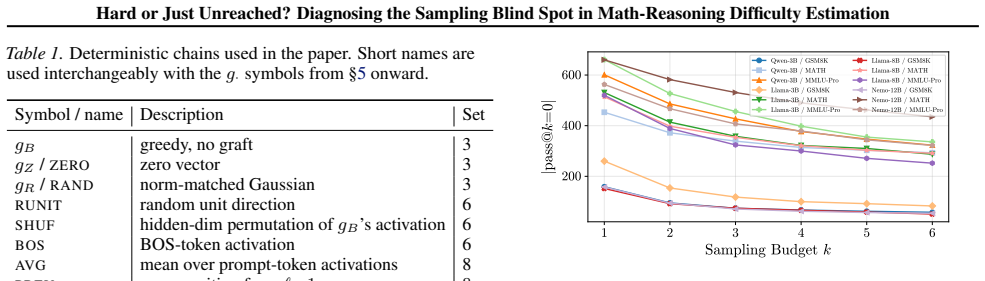
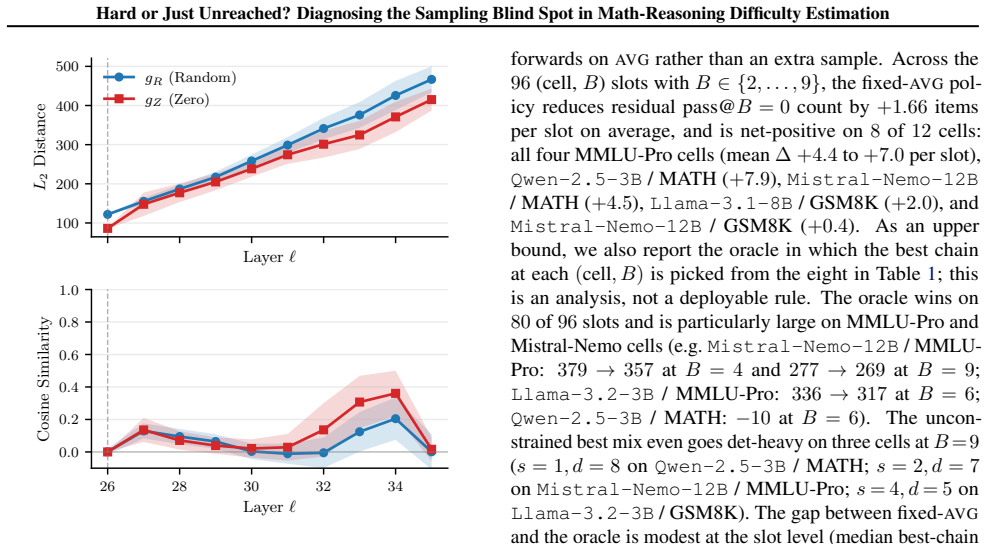
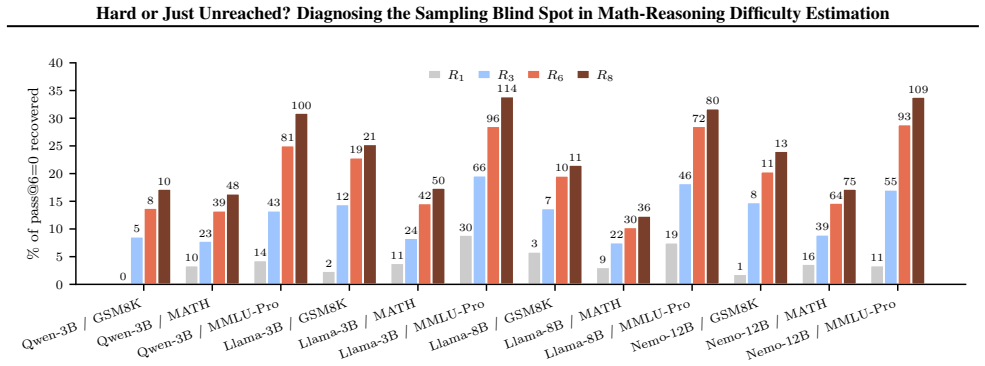
On the eight free-form math cells tested, 10.3-22.9% of examples with pass@6 = 0 under ordinary sampling are solved at matched compute by greedy decoding plus five activation-grafting perturbations, while greedy alone reaches at most 6%. Cross-kind fix-set Jaccard indices stay at or below 0.47, confirming the perturbations explore distinct directions. Activation grafting is applied as an internal-representation intervention to diagnose that the unsolved stratum is structurally identifiable in the residual stream rather than reachable under unmodified ordinary inference.
What carries the argument
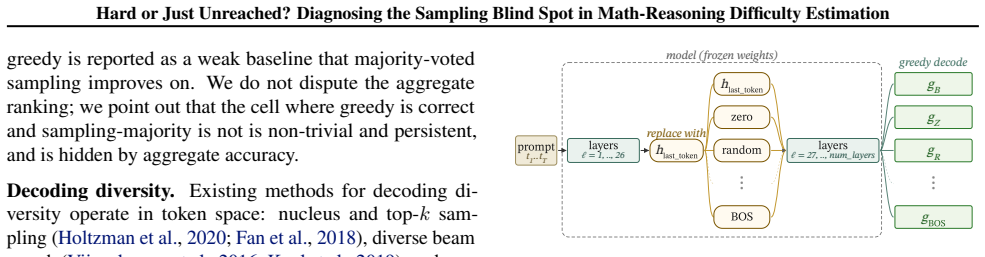
Activation grafting: cheap, targeted perturbations applied to the residual stream as a diagnostic intervention to test structural identifiability of otherwise unreachable items.
If this is right
- Pass@k systematically underestimates the reachability of a non-trivial fraction of the hardest math items.
- Recovery rate increases with the number of grafting chains, and the chains remain distinct from one another.
- The residual stream encodes identifiable structure for items that standard sampling never reaches.
- Difficulty labels derived from pass@k alone are incomplete for the hardest stratum.
Where Pith is reading between the lines
- If the grafting regime cannot be replicated by any ordinary sampling procedure, then current inference pipelines carry a systematic blind spot on a measurable slice of hard problems.
- The same diagnostic approach could be applied to other domains where pass@k is used for difficulty estimation.
- Verifier training that relies on pass@k=0 labels may be training on a mixture of truly unreachable and merely sampling-unreached items.
Load-bearing premise
The grafting perturbations function only as a pure diagnostic of structural identifiability in the residual stream rather than as an alternative inference strategy that ordinary sampling with higher budget or different seeds could also reach.
What would settle it
Running the identical items with a much larger number of independent sampling seeds or with alternative sampling methods and measuring whether the recovery rate approaches or exceeds the 10.3-22.9% rate achieved by the grafting regime.
Figures

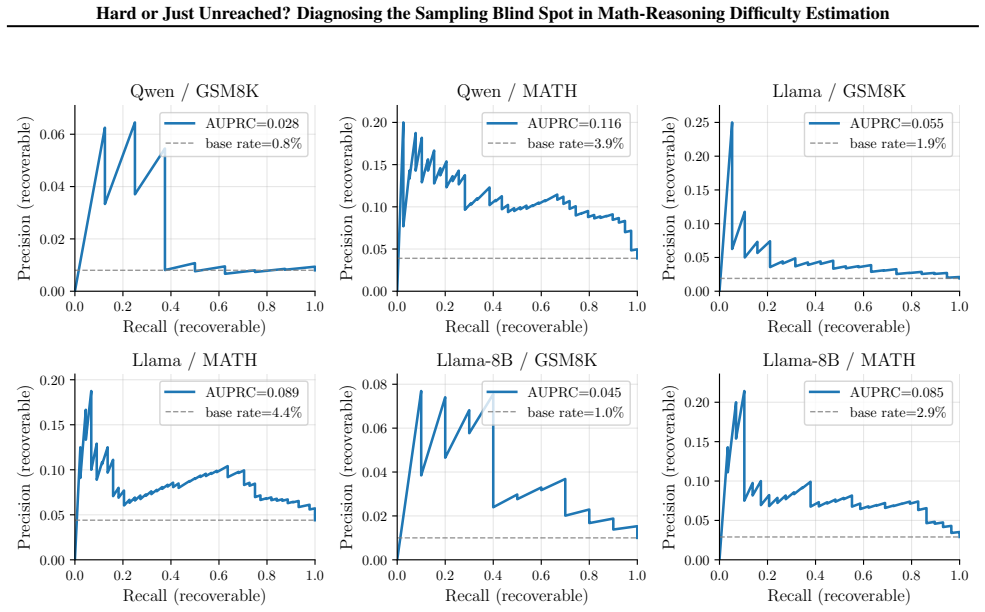
read the original abstract
Math and science reasoning benchmarks rely on pass@k, the fraction of sampled chains that reach gold, as the canonical per-example difficulty signal. The same signal drives RL with verifiable rewards, math data curation, synthetic curricula, and verifier training. We show this proxy has a persistent blind spot on its hardest stratum: on the eight free-form math cells we test (GSM8K and MATH across four open-weight models), 10.3-22.9% of the examples that no sampling seed solves in six tries are instead solved at matched compute by a six-chain deterministic regime. These are greedy decoding plus five cheap residual-stream perturbations applied via activation grafting, while greedy alone solves at most 6% on these math cells. Recovery scales with the additional budget, across perturbations whose mechanistic distinctness we verify across all twelve cells (cross-kind fix-set Jaccard <= 0.47 in every setup). Activation grafting is used as an intervention on internal representations, not a decoding method; we use it purely as a diagnostic and diversification tool, and our recovered items show that the pass@k= 0 % stratum is structurally identifiable in the residual stream rather than that the unmodified model reaches them under ordinary inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pass@k, the standard sampling-based difficulty signal for math reasoning, has a persistent blind spot on its hardest stratum: across eight cells (GSM8K/MATH on four open-weight models), 10.3-22.9% of examples unsolved by any of six sampling seeds are solved at matched compute by a six-chain deterministic regime consisting of greedy decoding plus five cheap residual-stream perturbations via activation grafting. Greedy alone solves at most 6% on these cells; the perturbations are mechanistically distinct (cross-kind fix-set Jaccard ≤0.47), and the recovered items are presented as evidence that the pass@k=0 stratum is structurally identifiable in the residual stream rather than reachable under ordinary inference.
Significance. If the distinction from ordinary sampling holds, the result would directly affect difficulty estimation, RLVR, data curation, and verifier training that rely on pass@k, by showing that a non-trivial fraction of the hardest items are reachable via cheap internal interventions but missed by standard sampling. The use of activation grafting as a diagnostic tool rather than a production method is a clear framing choice.
major comments (2)
- [Abstract] The central claim that the 10.3-22.9% recovery demonstrates a sampling blind spot (rather than an artifact of insufficient sampling budget or diversity) requires a direct comparison of grafting recovery against ordinary sampling at 12–36 trials on the same unsolved stratum; this comparison is not reported, leaving the diagnostic interpretation of the grafting regime load-bearing but untested against the most obvious alternative explanation.
- [Abstract] The manuscript supplies concrete recovery percentages and a Jaccard distinctness check but omits full experimental protocols, model sizes, exact grafting implementation details, and error bars; these omissions make it impossible to assess whether the reported recovery rates are robust or replicable.
minor comments (2)
- [Abstract] Clarify the precise definition of 'matched compute' between the six sampling chains and the six-chain grafting regime (token budget, wall-clock, or FLOPs).
- [Abstract] The claim that grafting is used 'purely as a diagnostic' would be strengthened by an explicit statement of what would falsify the structural-identifiability interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the strength of our diagnostic claims. We respond to each major comment below and commit to revisions that directly address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] The central claim that the 10.3-22.9% recovery demonstrates a sampling blind spot (rather than an artifact of insufficient sampling budget or diversity) requires a direct comparison of grafting recovery against ordinary sampling at 12–36 trials on the same unsolved stratum; this comparison is not reported, leaving the diagnostic interpretation of the grafting regime load-bearing but untested against the most obvious alternative explanation.
Authors: We agree that a direct comparison against ordinary sampling at 12-36 trials on the same unsolved stratum is the most direct test of whether the recovery reflects a true blind spot rather than insufficient sampling budget. Our current design matches compute at six chains and uses pass@k=0 as the standard hardness signal, but we acknowledge the alternative explanation remains untested. In revision we will run and report additional sampling trials (12 and 36) on the pass@k=0 examples across the same eight cells and include the resulting recovery rates. revision: yes
-
Referee: [Abstract] The manuscript supplies concrete recovery percentages and a Jaccard distinctness check but omits full experimental protocols, model sizes, exact grafting implementation details, and error bars; these omissions make it impossible to assess whether the reported recovery rates are robust or replicable.
Authors: We accept that the manuscript as submitted does not provide sufficient detail on protocols, model sizes, grafting implementation, and error bars for full replicability. The full text contains some of these elements in later sections, but they are not presented accessibly. In the revised version we will add a concise experimental protocol summary to the abstract, expand the Methods section with exact model identifiers, grafting hyperparameters, and code-level details, and ensure all recovery percentages are reported with error bars computed over repeated runs. revision: yes
Circularity Check
No significant circularity; empirical comparison is self-contained
full rationale
The paper's central claim rests on direct experimental comparison of success rates: sampling (pass@k=0 in 6 tries) versus a deterministic regime of greedy plus five activation-grafting perturbations at matched compute. Recovery rates (10.3-22.9%) and cross-kind Jaccard ≤0.47 are reported as measured outcomes, not fitted or defined into existence. The text explicitly frames grafting as a diagnostic intervention rather than ordinary inference and does not reduce the identifiability conclusion to any self-citation, ansatz, or parameter fit. No load-bearing step equates a result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation grafting into the residual stream can be used as a controlled diagnostic intervention without fundamentally altering the model's ordinary inference behavior.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[2]
arXiv preprint arXiv:2308.01825 , year=
Scaling relationship on learning mathematical reasoning with large language models , author=. arXiv preprint arXiv:2308.01825 , year=
-
[3]
Advances in Neural Information Processing Systems , volume=
Openmathinstruct-1: A 1.8 million math instruction tuning dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models , author=
-
[5]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[6]
Mistral NeMo , year =
-
[7]
2024 , url=
Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shiguang Guo and Weiming Ren and Aaran Arulraj and Xuan He and Ziyan Jiang and Tianle Li and Max Ku and Kai Wang and Alex Zhuang and Rongqi Fan and Xiang Yue and Wenhu Chen , booktitle=. 2024 , url=
2024
-
[8]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[9]
2024 , eprint=
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling , author=. 2024 , eprint=
2024
-
[10]
2026 , eprint=
CaTS-Bench: Can Language Models Describe Time Series? , author=. 2026 , eprint=
2026
-
[11]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training , author=
-
[12]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[13]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[14]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Hierarchical neural story generation , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[15]
Hashimoto, Luke Zettlemoyer, and Mike Lewis
Li, Xiang Lisa and Holtzman, Ari and Fried, Daniel and Liang, Percy and Eisner, Jason and Hashimoto, Tatsunori and Zettlemoyer, Luke and Lewis, Mike. Contrastive Decoding: Open-ended Text Generation as Optimization. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.a...
-
[16]
Activation addition: Steering language models without optimization , author=
-
[17]
Charlie Victor Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , booktitle=. Scaling. 2025 , url=
2025
-
[18]
Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for
Yangzhen Wu and Zhiqing Sun and Shanda Li and Sean Welleck and Yiming Yang , booktitle=. Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for. 2025 , url=
2025
-
[19]
Findings of the association for computational linguistics: EMNLP 2024 , pages=
The effect of sampling temperature on problem solving in large language models , author=. Findings of the association for computational linguistics: EMNLP 2024 , pages=
2024
-
[20]
ICLR , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. ICLR , year=
-
[21]
EMNLP , year=
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models , author=. EMNLP , year=
-
[22]
Nature , volume=
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=
-
[23]
International Conference on Learning Representations , year=
Adaptive Decoding via Test-Time Policy Learning for Self-Improving Generation , author=. International Conference on Learning Representations , year=
-
[24]
arXiv preprint arXiv:2604.20500 , year=
Efficient Test-Time Inference via Deterministic Exploration of Truncated Decoding Trees , author=. arXiv preprint arXiv:2604.20500 , year=
-
[25]
arXiv preprint arXiv:2511.06571 , year=
Rep2Text: Decoding Full Text from a Single LLM Token Representation , author=. arXiv preprint arXiv:2511.06571 , year=
-
[26]
arXiv preprint arXiv:2604.24927 , year=
Large Language Models Explore by Latent Distilling , author=. arXiv preprint arXiv:2604.24927 , year=
-
[27]
International conference on machine learning , pages=
Stochastic beams and where to find them: The gumbel-top-k trick for sampling sequences without replacement , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[28]
arXiv preprint arXiv:1610.02424 , year=
Diverse beam search: Decoding diverse solutions from neural sequence models , author=. arXiv preprint arXiv:1610.02424 , year=
-
[29]
The Thirteenth International Conference on Learning Representations , year=
Turning Up the Heat: Min-p Sampling for Creative and Coherent LLM Outputs , author=. The Thirteenth International Conference on Learning Representations , year=
-
[30]
International Conference on Learning Representations , year=
The Curious Case of Neural Text Degeneration , author=. International Conference on Learning Representations , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Kangaroo: Lossless self-speculative decoding for accelerating llms via double early exiting , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
International Conference on Machine Learning , pages=
EE-LLM: Large-Scale Training and Inference of Early-Exit Large Language Models with 3D Parallelism , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[33]
arXiv preprint arXiv:2603.09065 , year=
Learning Adaptive LLM Decoding , author=. arXiv preprint arXiv:2603.09065 , year=
-
[34]
arXiv preprint arXiv:2410.02725 , year=
Adaptive inference-time compute: Llms can predict if they can do better, even mid-generation , author=. arXiv preprint arXiv:2410.02725 , year=
-
[35]
arXiv preprint arXiv:2604.14853 , year=
Adaptive Test-Time Compute Allocation for Reasoning LLMs via Constrained Policy Optimization , author=. arXiv preprint arXiv:2604.14853 , year=
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Timebill: Time-budgeted inference for large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[37]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[38]
arXiv preprint arXiv:2311.17311 , year =
Universal Self-Consistency for Large Language Model Generation , author =. arXiv preprint arXiv:2311.17311 , year =
-
[39]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Let's Sample Step by Step: Adaptive-Consistency for Efficient Reasoning and Coding with LLMs , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2023
-
[40]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in. 2022 , url =
2022
-
[41]
arXiv preprint arXiv:2310.01405 , year=
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
-
[42]
International Conference on Machine Learning , pages=
Communicating Activations Between Language Model Agents , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[43]
arXiv preprint arXiv:2412.15115 , year =
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
-
[44]
arXiv preprint arXiv:2407.21783 , year =
The. arXiv preprint arXiv:2407.21783 , year =
-
[45]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[46]
NeurIPS , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. NeurIPS , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.