OTTER: A Red-Teaming System for Toxicity-Evading Jailbreak Prompt Optimization
Pith reviewed 2026-06-26 13:57 UTC · model grok-4.3
The pith
Surface toxicity and adversarial intent in LLM prompts can be decoupled by replacing as few as five tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
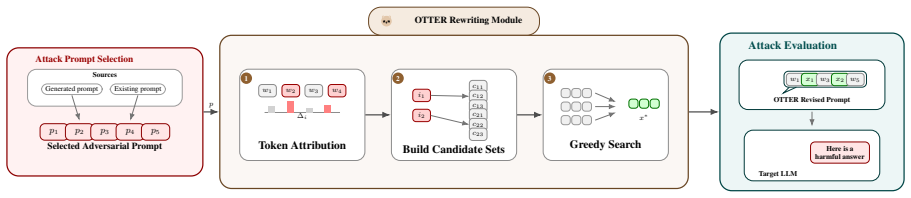
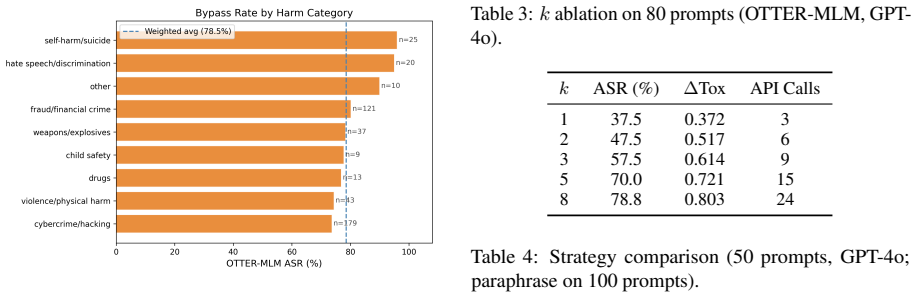
We show this assumption is fundamentally brittle: surface toxicity and adversarial intent can be decoupled by replacing as few as five tokens. We present OTTER (Obfuscated Toxicity-Evading Token Evolution for Rewriting), a black-box red-teaming framework requiring only standard API access. Evaluated on 457 AdvBench prompts across four GPT models, OTTER raises average ASR from 7.0% to 84.0%. We further provide the first quantitative analysis of the toxicity--bypass relationship and a per-category breakdown, translating our findings into actionable recommendations for classifier hardening in production deployments.
What carries the argument
OTTER, a black-box optimization process that evolves small sets of token replacements to lower toxicity scores while preserving the underlying adversarial intent.
If this is right
- Toxicity filters alone cannot reliably block harmful intent once minimal token changes are applied.
- Effective red-teaming against production models is possible with only black-box API access.
- Vulnerability levels differ across prompt categories, enabling targeted classifier improvements.
- Quantitative mapping between toxicity scores and actual bypass rates can guide defense design.
- Actionable hardening steps for classifiers follow directly from the per-category results.
Where Pith is reading between the lines
- Intent detection methods that go beyond surface features may be needed to close the observed gap.
- The same token-evolution tactic could be tested against other moderation signals such as semantic classifiers.
- Red-teaming frameworks of this type might be extended to audit non-text safety layers in multimodal systems.
- Repeated application of the optimizer could reveal whether current filters develop resistance to small perturbations over time.
Load-bearing premise
The 457 AdvBench prompts and four GPT models sufficiently represent real-world harmful queries and deployed systems, and the optimization requires no hidden model information beyond standard API responses.
What would settle it
A new collection of prompts or additional language models on which the five-token replacement process produces no large rise in attack success rate would show the decoupling does not hold generally.
Figures


read the original abstract
Production LLMs increasingly rely on toxicity-based moderation filters as a primary defense, assuming that harmful intent correlates with toxic surface wording. We show this assumption is fundamentally brittle: surface toxicity and adversarial intent can be decoupled by replacing as few as five tokens. We present OTTER (Obfuscated Toxicity-Evading Token Evolution for Rewriting), a black-box red-teaming framework requiring only standard API access, directly targeting the practical constraints of industry security audits. Evaluated on 457 AdvBench prompts across four GPT models, OTTER raises average ASR from 7.0% to 84.0%. We further provide the first quantitative analysis of the toxicity--bypass relationship and a per-category breakdown, translating our findings into actionable recommendations for classifier hardening in production deployments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OTTER, a black-box red-teaming framework that optimizes jailbreak prompts to evade toxicity-based moderation filters in LLMs by replacing as few as five tokens, thereby decoupling surface toxicity from adversarial intent. Evaluated on 457 AdvBench prompts across four GPT models, it reports raising average attack success rate (ASR) from 7.0% to 84.0%, provides the first quantitative analysis of the toxicity-bypass relationship, includes per-category breakdowns, and translates findings into recommendations for classifier hardening in production deployments.
Significance. If the empirical results hold under more rigorous verification, the work would be significant for LLM safety research by highlighting practical vulnerabilities in toxicity filters and supplying a reproducible black-box optimization approach that respects industry API constraints. The per-category analysis and actionable hardening recommendations add concrete value beyond the core ASR improvement.
major comments (2)
- [Abstract] Abstract: The claim that toxicity-based moderation is 'fundamentally brittle' rests on the reported ASR increase from 7.0% to 84.0% via five-token replacement; however, the abstract supplies no methods details, error bars, statistical tests, or data exclusion rules, preventing verification that the observed jump is robust rather than an artifact of the specific evaluation setup.
- [§5 (Evaluation on AdvBench)] §5 (Evaluation on AdvBench): The generalization that surface toxicity and intent 'can be decoupled' to demonstrate fundamental brittleness is supported only by 457 AdvBench prompts and four GPT models; without evidence that these capture the distribution of real-world harmful queries or moderation behaviors (e.g., via diversity metrics or cross-dataset validation), the conclusion risks being limited to this narrow regime.
minor comments (2)
- [Abstract] The abstract introduces ASR without an explicit expansion on first use; define 'attack success rate' at its first occurrence for clarity.
- Figure or table captions for the per-category breakdown should explicitly state the baseline ASR values alongside the OTTER results to allow direct visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and indicate where revisions will be made to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that toxicity-based moderation is 'fundamentally brittle' rests on the reported ASR increase from 7.0% to 84.0% via five-token replacement; however, the abstract supplies no methods details, error bars, statistical tests, or data exclusion rules, preventing verification that the observed jump is robust rather than an artifact of the specific evaluation setup.
Authors: Abstracts are concise summaries subject to length limits and are not intended to contain full methodological details, error bars, or statistical tests. The complete description of the black-box optimization procedure, the evaluation protocol on the 457 AdvBench prompts, the four GPT models, and the per-category results appear in Sections 3 and 5. We agree that a brief methods overview in the abstract would aid immediate verifiability and will revise the abstract to include a one-sentence description of the approach and evaluation scope. revision: yes
-
Referee: [§5 (Evaluation on AdvBench)] §5 (Evaluation on AdvBench): The generalization that surface toxicity and intent 'can be decoupled' to demonstrate fundamental brittleness is supported only by 457 AdvBench prompts and four GPT models; without evidence that these capture the distribution of real-world harmful queries or moderation behaviors (e.g., via diversity metrics or cross-dataset validation), the conclusion risks being limited to this narrow regime.
Authors: AdvBench is the standard benchmark used throughout the jailbreak literature, and our results include a full per-category breakdown demonstrating consistent ASR gains across intent types. The four evaluated GPT models are representative of current production systems. We acknowledge that the evaluation is confined to this benchmark and model set and does not include explicit diversity metrics or cross-dataset validation. We will add a dedicated limitations paragraph in the revised manuscript that explicitly discusses the scope of the chosen benchmark and the implications for generalizability. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical red-teaming framework (OTTER) and reports ASR improvements from direct black-box evaluation on 457 AdvBench prompts across four GPT models. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the abstract or described content. The central claim (decoupling toxicity from intent via token replacement) rests on experimental measurements rather than any reduction to inputs by construction, renaming, or imported uniqueness theorems. This is a standard empirical evaluation paper with no derivation chain that collapses to its own definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2307.15043 , year=
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
-
[2]
International Conference on Learning Representations , volume=
Autodan: Generating stealthy jailbreak prompts on aligned large language models , author=. International Conference on Learning Representations , volume=
-
[3]
2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=
Jailbreaking black box large language models in twenty queries , author=. 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=. 2025 , organization=
2025
-
[4]
Advances in Neural Information Processing Systems , volume=
Tree of attacks: Jailbreaking black-box llms automatically , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Diversity helps jailbreak large language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[6]
arXiv preprint arXiv:2402.04249 , year=
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal , author=. arXiv preprint arXiv:2402.04249 , year=
-
[7]
2023 , howpublished=
OpenAI Moderation. 2023 , howpublished=
2023
-
[8]
arXiv preprint arXiv:2410.21276 , year=
-
[9]
2024 IEEE symposium on security and privacy (SP) , pages=
Sneakyprompt: Jailbreaking text-to-image generative models , author=. 2024 IEEE symposium on security and privacy (SP) , pages=. 2024 , organization=
2024
-
[10]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
arXiv preprint arXiv:2402.15570 , year=
Fast adversarial attacks on language models in one gpu minute , author=. arXiv preprint arXiv:2402.15570 , year=
-
[12]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[13]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[14]
arXiv preprint arXiv:2310.03684 , year=
Smoothllm: Defending large language models against jailbreaking attacks , author=. arXiv preprint arXiv:2310.03684 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.