Goal-Conditioned Supervised Learning for LLM Fine-Tuning
Pith reviewed 2026-05-20 22:33 UTC · model grok-4.3
The pith
Treating feedback as an explicit quality goal in supervised learning guides LLMs to improve response quality without paired preferences or reward models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
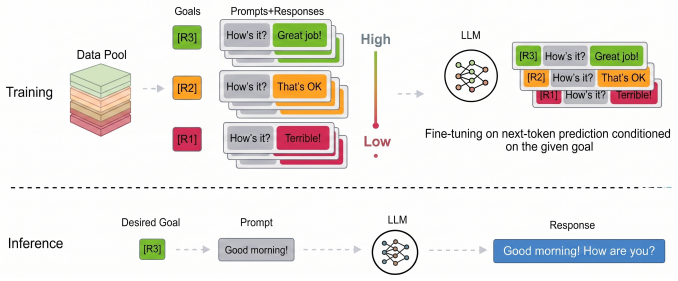
By casting feedback as a natural-language goal and defining the objective as generating responses that exceed a target quality level rather than imitating a high-quality subset, goal-conditioned supervised learning enables pure supervised training to produce measurable quality gains and outperforms standard offline fine-tuning methods on non-toxic generation, code generation, and recommendation tasks.
What carries the argument
Goal-conditioned supervised learning with a threshold-based goal formulation that directs the model to pursue outcomes above a specified quality level, represented in natural language.
If this is right
- The method outperforms standard supervised fine-tuning and direct preference optimization on non-toxic generation, code generation, and LLM-based recommendation tasks.
- It preserves the efficiency, scalability, and minimal data requirements of ordinary supervised learning.
- Natural-language goal statements allow the model to use its existing semantic understanding when pursuing the target quality level.
- The threshold formulation reduces the bounded-learning effect that occurs when models only imitate selected high-quality samples.
Where Pith is reading between the lines
- The same threshold goal structure might be applied to other graded feedback settings such as summarization or dialogue quality without requiring new data collection methods.
- Because the approach stays fully offline, it could be combined with existing preference datasets to create hybrid training signals.
- Testing whether the learned quality direction transfers to unseen tasks or larger model scales would be a natural next measurement.
Load-bearing premise
The premise that training to exceed a quality threshold will cause the model to learn directional quality progression instead of merely matching the best examples.
What would settle it
An experiment in which models trained with the threshold goal show no consistent improvement over ordinary supervised fine-tuning on the same graded feedback data would falsify the central claim.
Figures




read the original abstract
Large language models often require fine-tuning to better align their behavior with user intent at deployment. Existing approaches are commonly divided into online and offline paradigms. Online methods, such as RL-based alignment, can directly optimize outcome quality but typically rely on external reward models and iterative rollouts, making them costly and difficult to deploy in many cases. Offline methods are more efficient, but prevailing approaches such as supervised fine-tuning (SFT) and direct preference optimization (DPO) remain limited: SFT typically collapses graded feedback into binary supervision, while DPO depends on paired preference data that is often unavailable or expensive to construct. In this paper, we propose goal-conditioned supervised learning (GCSL) as an offline fine-tuning framework for LLMs. Our core idea is to treat feedback signals directly as an explicit goal and train the model, purely through supervised learning, to generate responses that achieve that goal. To better exploit graded feedback, we further introduce a novel goal formulation that defines learning as consistently pursuing outcomes above a target quality threshold, rather than imitating samples from a selected high-quality subset. This design mitigates the bounded-learning effect of SFT and classic GCSL by explicitly guiding the model to learn the directional progression of quality. We also propose natural-language goal representations to better leverage the semantic understanding and reasoning capabilities of LLMs. We evaluate our method on three tasks: non-toxic generation, code generation, and LLM for recommendation. Results show that our approach consistently outperforms standard offline fine-tuning baselines while retaining the efficiency, scalability, and simple data requirements of supervised learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes goal-conditioned supervised learning (GCSL) as an offline fine-tuning framework for LLMs. Feedback signals are treated as explicit goals, with a novel formulation that trains the model via supervised learning to generate responses achieving quality above a target threshold (rather than imitating a high-quality subset). Natural-language goal representations are used to leverage LLM reasoning. The method is evaluated on non-toxic generation, code generation, and LLM-for-recommendation tasks, with claims of consistent outperformance over standard offline baselines (SFT, DPO) while retaining supervised learning's efficiency and scalability.
Significance. If the empirical results and the claimed distinction from filtered SFT hold under scrutiny, the work offers a simple, scalable way to exploit graded feedback without reward models, paired preferences, or online rollouts. This could meaningfully narrow the gap between offline and online alignment methods for LLMs. The natural-language goal design is a practical strength that aligns with existing LLM capabilities.
major comments (1)
- Abstract: The central claim that the threshold-based goal formulation 'explicitly guiding the model to learn the directional progression of quality' and mitigates bounded learning is load-bearing but insufficiently justified. The described training remains standard next-token prediction on observed responses that satisfy the threshold for each prompt; no contrastive, value-based, or iterative mechanism is indicated that would support extrapolation beyond the support of the training distribution. This makes the distinction from SFT on a filtered high-quality subset fragile and requires either a formal argument or targeted ablation to substantiate.
minor comments (1)
- Abstract: The outperformance claim would be strengthened by naming the concrete baselines, metrics, and task-specific results rather than the generic statement 'consistently outperforms standard offline fine-tuning baselines'.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the need to strengthen the justification of our central claim. We address the major comment below and will revise the manuscript accordingly to provide a clearer formal argument and supporting ablation.
read point-by-point responses
-
Referee: Abstract: The central claim that the threshold-based goal formulation 'explicitly guiding the model to learn the directional progression of quality' and mitigates bounded learning is load-bearing but insufficiently justified. The described training remains standard next-token prediction on observed responses that satisfy the threshold for each prompt; no contrastive, value-based, or iterative mechanism is indicated that would support extrapolation beyond the support of the training distribution. This makes the distinction from SFT on a filtered high-quality subset fragile and requires either a formal argument or targeted ablation to substantiate.
Authors: We agree that additional clarification is warranted. Although the objective is next-token prediction, the training data pairs each prompt with a natural-language goal that explicitly encodes a quality threshold derived from the graded feedback (e.g., “produce a response whose toxicity score is below 0.2”). When the same prompt appears with responses of varying quality, each is paired with its corresponding threshold goal. This conditioning teaches the model a mapping from goal specification to output quality, so that at inference a higher-threshold goal can elicit responses beyond the exact support of any single training subset. We will add a short formal argument in Section 3 showing that the goal-conditioned distribution encourages monotonic improvement in quality as the threshold increases, and we will include a targeted ablation that compares GCSL against plain filtered SFT (identical data, no goal tokens). These changes will appear in the revised manuscript. revision: yes
Circularity Check
Empirical method proposal with no load-bearing circular derivations
full rationale
The paper introduces GCSL as an offline fine-tuning framework and a novel goal formulation using quality thresholds. Claims of outperforming baselines and mitigating bounded learning rest on experimental results across three tasks rather than any closed mathematical derivation. No equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claims to inputs are present. The approach is self-contained as a supervised learning variant with natural-language conditioning, evaluated empirically without internal tautologies.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a novel goal-achieving objective to overcome a key limitation of SFT and classic GCSL... By formulating learning as consistently pursuing outcomes above a target quality threshold
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GCSL-bey-NL achieves the best performance... outperforming standard offline fine-tuning baselines
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Optimal design for reward modeling in rlhf.arXiv preprint arXiv:2410.17055, 2024
Antoine Scheid, Etienne Boursier, Alain Durmus, Michael I Jordan, Pierre Ménard, Eric Moulines, and Michal Valko. Optimal design for reward modeling in rlhf.arXiv preprint arXiv:2410.17055, 2024
-
[2]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. InInternational Conference on Machine Learning, pages 10835–10866. PMLR, 2023
work page 2023
-
[3]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
work page 2023
-
[4]
Xin Qiu, Yulu Gan, Conor F Hayes, Qiyao Liang, Yinggan Xu, Roberto Dailey, Elliot Meyerson, Babak Hodjat, and Risto Miikkulainen. Evolution strategies at scale: Llm fine-tuning beyond reinforcement learning.arXiv preprint arXiv:2509.24372, 2025
-
[5]
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems, 37:124198–124235, 2024
work page 2024
-
[6]
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. Raft: Reward ranked finetuning for generative foundation model alignment.arXiv preprint arXiv:2304.06767, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Goal-conditioned reinforcement learning: Problems and solutions
Minghuan Liu, Menghui Zhu, and Weinan Zhang. Goal-conditioned reinforcement learning: Problems and solutions.arXiv preprint arXiv:2201.08299, 2022
-
[9]
Quark: Controllable text generation with reinforced unlearning
Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, and Yejin Choi. Quark: Controllable text generation with reinforced unlearning. Advances in neural information processing systems, 35:27591–27609, 2022
work page 2022
-
[10]
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling.Advances in neural information processing systems, 34:15084–15097, 2021
work page 2021
-
[11]
Steerlm: Attribute conditioned sft as an (user-steerable) alternative to rlhf
Yi Dong, Zhilin Wang, Makesh Sreedhar, Xianchao Wu, and Oleksii Kuchaiev. Steerlm: Attribute conditioned sft as an (user-steerable) alternative to rlhf. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 11275–11288, 2023
work page 2023
-
[12]
Vaskar Nath, Dylan Slack, Jeff Da, Yuntao Ma, Hugh Zhang, Spencer Whitehead, and Sean Hendryx. Learning goal-conditioned representations for language reward models.Advances in Neural Information Processing Systems, 37:117070–117108, 2024
work page 2024
-
[13]
Joey Hong, Anca Dragan, and Sergey Levine. Planning without search: Refining frontier llms with offline goal-conditioned rl.arXiv preprint arXiv:2505.18098, 2025
-
[14]
Michael Janner, Qiyang Li, and Sergey Levine. Offline reinforcement learning as one big sequence modeling problem.Advances in neural information processing systems, 34:1273– 1286, 2021
work page 2021
-
[15]
Realtox- icityprompts: Evaluating neural toxic degeneration in language models
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. Realtox- icityprompts: Evaluating neural toxic degeneration in language models. InFindings of the association for computational linguistics: EMNLP 2020, pages 3356–3369, 2020
work page 2020
-
[16]
Dexperts: Decoding-time controlled text generation with experts and anti-experts
Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A Smith, and Yejin Choi. Dexperts: Decoding-time controlled text generation with experts and anti-experts. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Vol...
work page 2021
-
[17]
A new generation of perspective api: Efficient multilingual character-level trans- formers
Alyssa Lees, Vinh Q Tran, Yi Tay, Jeffrey Sorensen, Jai Gupta, Donald Metzler, and Lucy Vasserman. A new generation of perspective api: Efficient multilingual character-level trans- formers. InProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining, pages 3197–3207, 2022
work page 2022
-
[18]
Plug and play language models: A simple approach to controlled text generation.ICLR, 2020
Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language models: A simple approach to controlled text generation.ICLR, 2020
work page 2020
-
[19]
Unified parameter-efficient unlearning for llms.ICLR, 2025
Chenlu Ding, Jiancan Wu, Yancheng Yuan, Jinda Lu, Kai Zhang, Alex Su, Xiang Wang, and Xiangnan He. Unified parameter-efficient unlearning for llms.ICLR, 2025
work page 2025
-
[20]
Mingzhe Du, Luu A Tuan, Bin Ji, Qian Liu, and See-Kiong Ng. Mercury: A code efficiency benchmark for code large language models.Advances in Neural Information Processing Systems, 37:16601–16622, 2024
work page 2024
-
[21]
Alphadpo: Adaptive reward margin for direct preference optimization
Junkang Wu, Xue Wang, Zhengyi Yang, Jiancan Wu, Jinyang Gao, Bolin Ding, Xiang Wang, and Xiangnan He. Alphadpo: Adaptive reward margin for direct preference optimization. In International Conference on Machine Learning, pages 67793–67809. PMLR, 2025
work page 2025
-
[22]
Ruining He and Julian McAuley. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. Inproceedings of the 25th international conference on world wide web, pages 507–517, 2016
work page 2016
-
[23]
Decoding matters: Addressing amplification bias and homogeneity issue for llm-based recommendation
Keqin Bao, Jizhi Zhang, Yang Zhang, Xinyue Huo, Chong Chen, and Fuli Feng. Decoding matters: Addressing amplification bias and homogeneity issue for llm-based recommendation. arXiv preprint arXiv:2406.14900, 2024
-
[24]
Yuxin Chen, Junfei Tan, An Zhang, Zhengyi Yang, Leheng Sheng, Enzhi Zhang, Xiang Wang, and Tat-Seng Chua. On softmax direct preference optimization for recommendation.Advances in Neural Information Processing Systems, 37:27463–27489, 2024
work page 2024
-
[25]
Sprec: Self-play to debias llm-based recommendation
Chongming Gao, Ruijun Chen, Shuai Yuan, Kexin Huang, Yuanqing Yu, and Xiangnan He. Sprec: Self-play to debias llm-based recommendation. InProceedings of the ACM on Web Conference 2025, pages 5075–5084, 2025
work page 2025
-
[26]
Keqin Bao, Jizhi Zhang, Wenjie Wang, Yang Zhang, Zhengyi Yang, Yanchen Luo, Chong Chen, Fuli Feng, and Qi Tian. A bi-step grounding paradigm for large language models in recommendation systems.ACM Transactions on Recommender Systems, 3(4):1–27, 2025
work page 2025
-
[27]
Sentence-bert: Sentence embeddings using siamese bert- networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), pages 3982–3992, 2019
work page 2019
-
[28]
Rosepo: Aligning llm-based recommenders with human values.arXiv preprint arXiv:2410.12519, 2024
Jiayi Liao, Xiangnan He, Ruobing Xie, Jiancan Wu, Yancheng Yuan, Xingwu Sun, Zhanhui Kang, and Xiang Wang. Rosepo: Aligning llm-based recommenders with human values.arXiv preprint arXiv:2410.12519, 2024
-
[29]
Lightgcn: Simplifying and powering graph convolution network for recommendation
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. Lightgcn: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 639–648, 2020
work page 2020
-
[30]
Self-attentive sequential recommendation
Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommendation. In2018 IEEE international conference on data mining (ICDM), pages 197–206. IEEE, 2018
work page 2018
-
[31]
Expected reciprocal rank for graded relevance
Olivier Chapelle, Donald Metlzer, Ya Zhang, and Pierre Grinspan. Expected reciprocal rank for graded relevance. InProceedings of the 18th ACM conference on Information and knowledge management, pages 621–630, 2009
work page 2009
-
[32]
Lora: Low-rank adaptation of large language models.ICLR, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 2022. 11
work page 2022
-
[33]
Rishabh Agarwal, Avi Singh, Lei Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, et al. Many-shot in-context learning. Advances in Neural Information Processing Systems, 37:76930–76966, 2024
work page 2024
-
[34]
Does few-shot learning help llm performance in code synthesis?arXiv preprint arXiv:2412.02906, 2024
Derek Xu, Tong Xie, Botao Xia, Haoyu Li, Yunsheng Bai, Yizhou Sun, and Wei Wang. Does few-shot learning help llm performance in code synthesis?arXiv preprint arXiv:2412.02906, 2024
-
[35]
Subhojyoti Mukherjee, Viet Dac Lai, Raghavendra Addanki, Ryan Rossi, Seunghyun Yoon, Trung Bui, Anup Rao, Jayakumar Subramanian, and Branislav Kveton. Offline rl by reward- weighted fine-tuning for conversation optimization.arXiv preprint arXiv:2506.06964, 2025
-
[36]
Jian Hu, Li Tao, June Yang, and Chandler Zhou. Aligning language models with offline learning from human feedback.arXiv preprint arXiv:2308.12050, 2023
-
[37]
KTO: Model Alignment as Prospect Theoretic Optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Soft labels for ordinal regression
Raul Diaz and Amit Marathe. Soft labels for ordinal regression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4738–4747, 2019
work page 2019
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 12 A Ablation Results Figure 3 shows the effect of the threshold numbers on the performance of GCSL-bey-NL. Figure 3: Perform...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Amazon Reviews [22] is released under the MIT License
is released under the Creative Commons Attribution-NonCommercial 4.0 (CC BY-NC 4.0) license. Amazon Reviews [22] is released under the MIT License. We use all datasets in accordance with their original release terms and intended research usage. Models.Qwen3-4B-Instruct-2507 [ 39] is released under the Apache License 2.0. Llama-3.1-8B- Instruct [40], used ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.