AugMask: Training Diffusion Models on Incomplete Tabular Data via Stochastic Augmentation and Masking
Pith reviewed 2026-06-28 11:08 UTC · model grok-4.3
The pith
AugMask trains standard diffusion models on incomplete tabular data by stochastic augmentation for conditioning and observed-only denoising supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
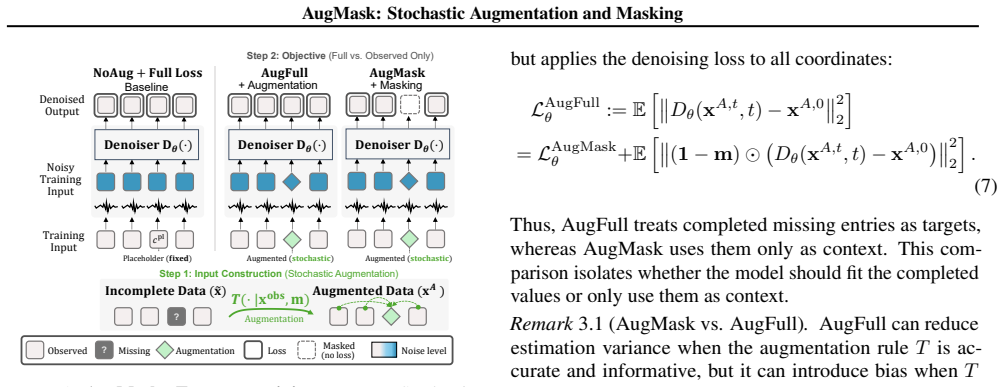
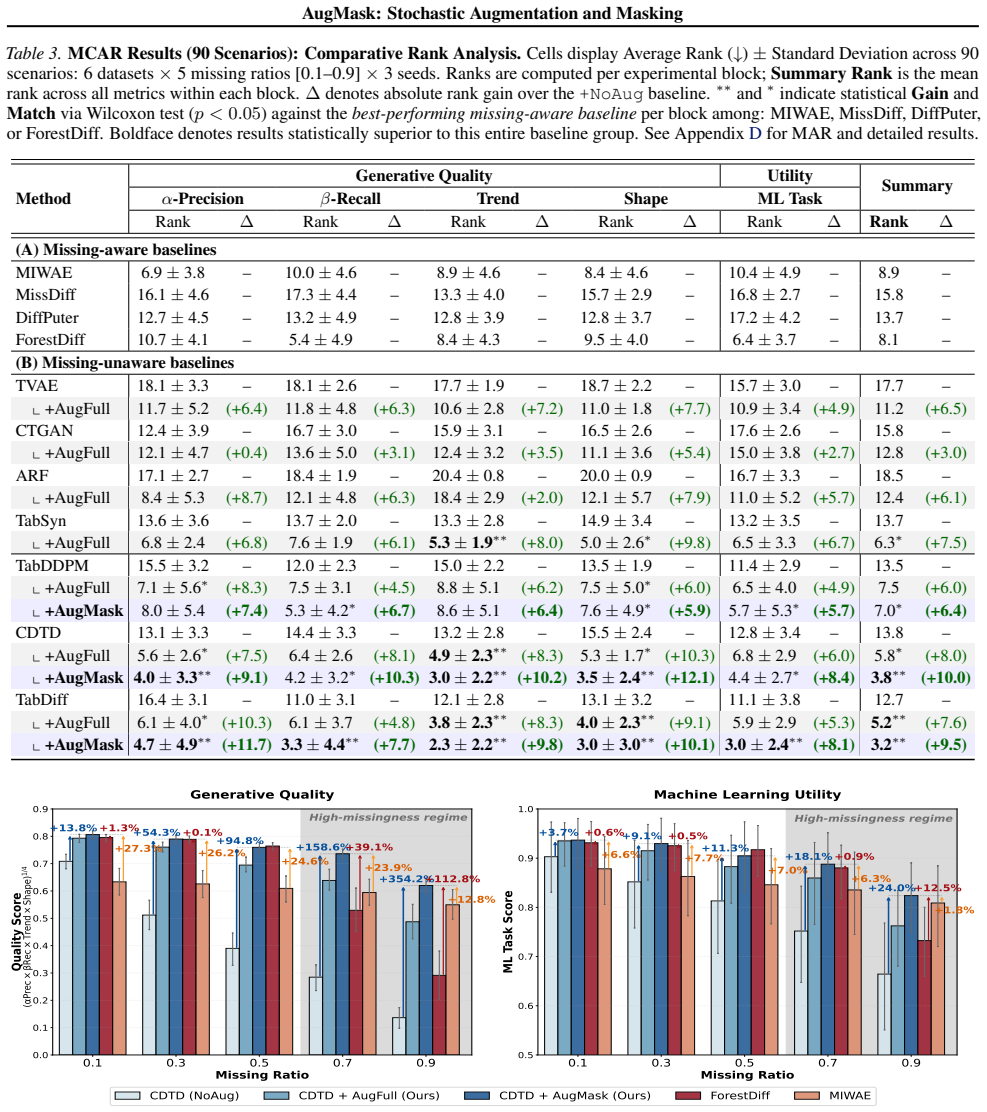
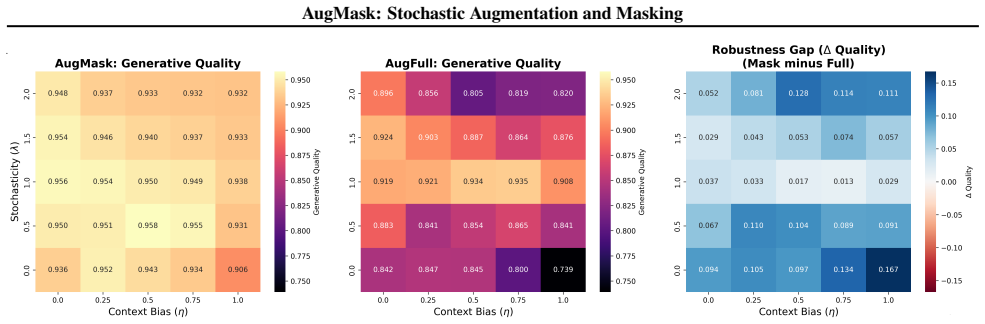
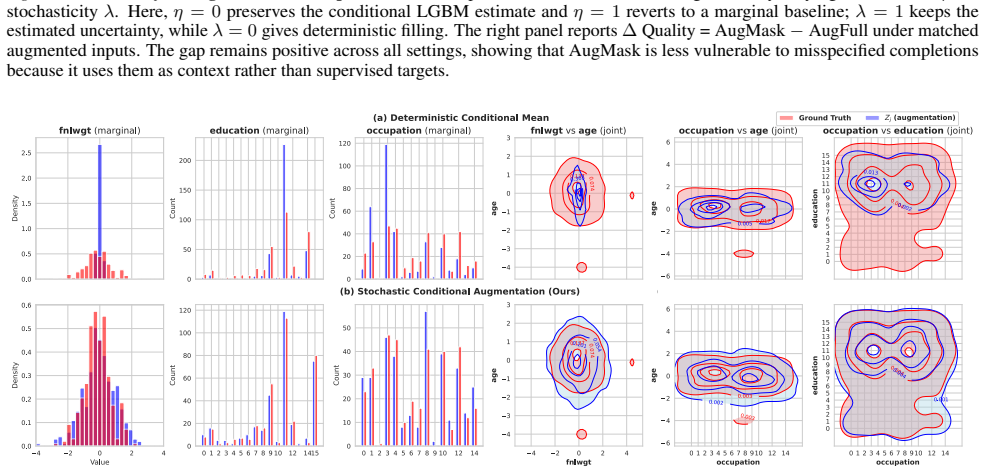
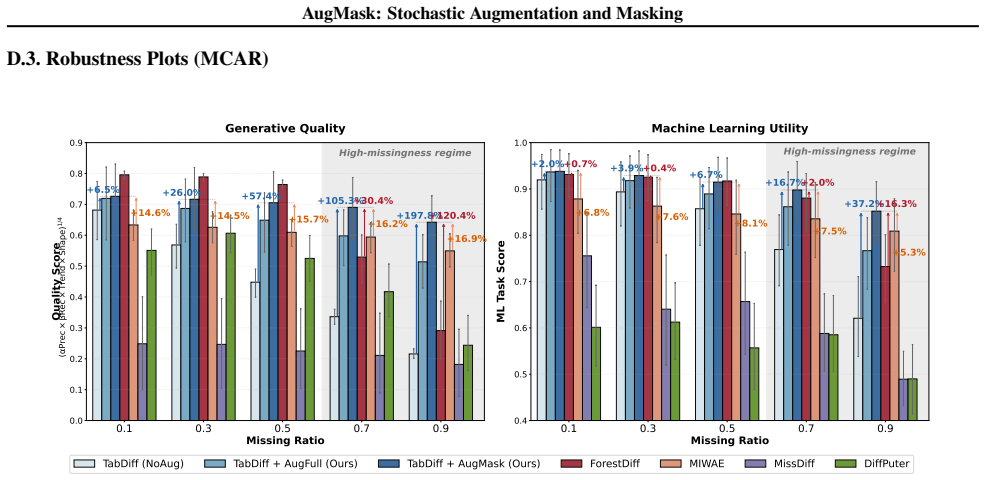
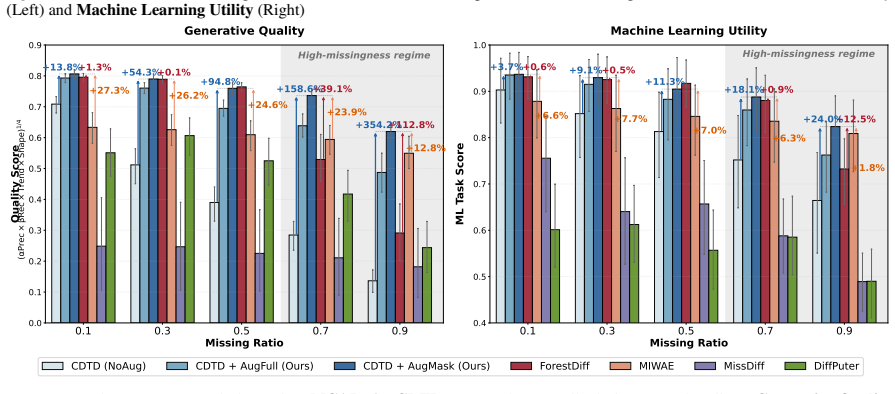
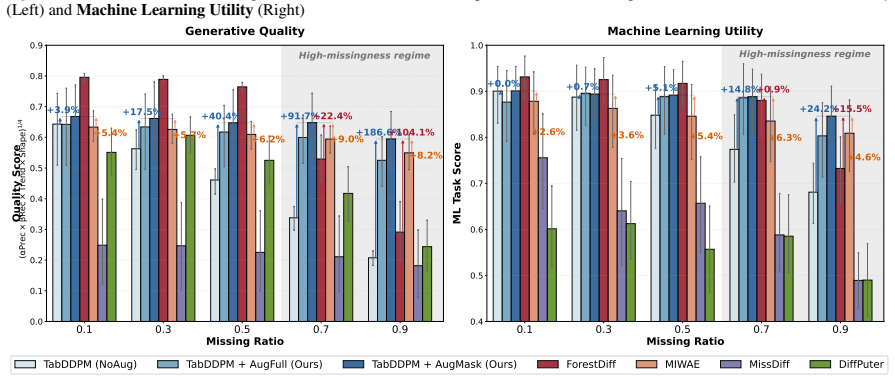
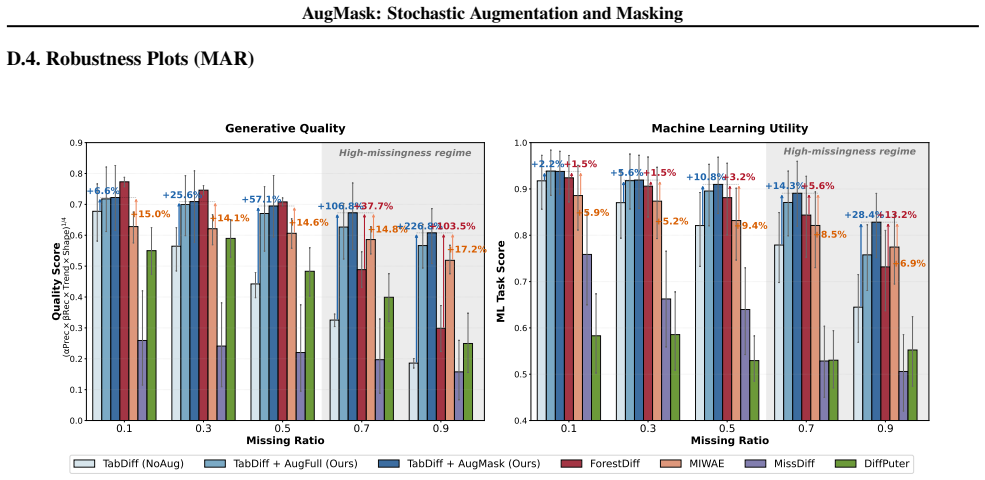
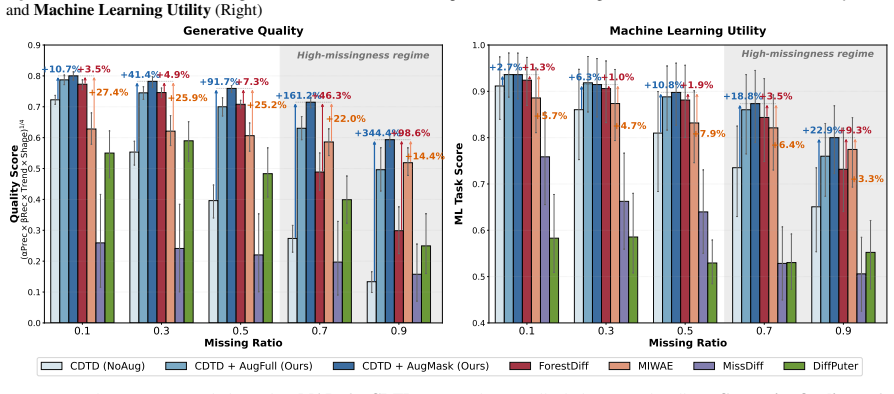
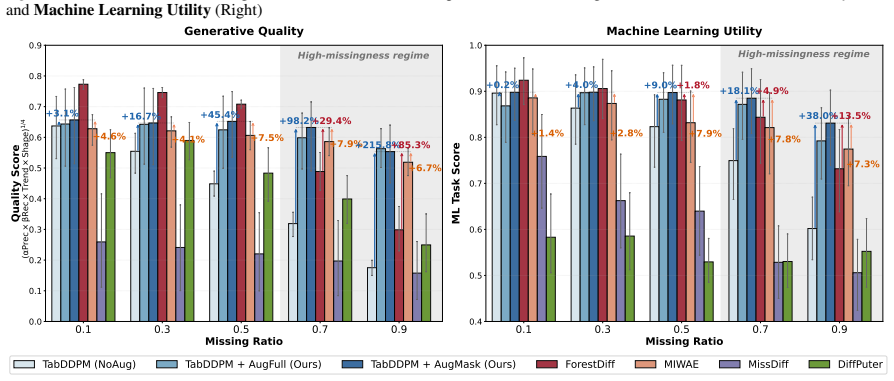
AugMask separates conditioning from supervision: missing entries receive conditional stochastic augmentation to produce numeric inputs, while denoising supervision is applied exclusively to observed coordinates. The resulting training objective is equivalent to a Rao-Blackwellized marginalization over missing entries, which induces a variance-weighted sensitivity penalty that discourages over-reliance on uncertain imputations. Across multiple datasets and missingness regimes, diffusion backbones trained under this rule outperform specialized missing-aware baselines.
What carries the argument
Conditional stochastic augmentation paired with observed-only denoising supervision, connected to a Rao-Blackwellized objective that produces a variance-weighted sensitivity penalty.
If this is right
- Standard diffusion tabular generators can be applied directly to incomplete data without architectural modifications for missingness.
- The variance-weighted penalty discourages the model from treating uncertain imputations as reliable targets.
- Performance gains hold across diverse datasets and multiple missingness regimes.
- The framework remains a plug-and-play addition rather than a replacement for the underlying diffusion backbone.
Where Pith is reading between the lines
- The same separation of conditioning from supervision could be tested on other score-based or flow-based generative models for tabular data.
- If auxiliary models improve over training, the variance penalty may automatically down-weight early noisy completions without extra scheduling.
- The approach may reduce reliance on separate imputation pipelines before feeding data into generative models.
Load-bearing premise
The auxiliary models produce completions whose uncertainty can be correctly marginalized by the Rao-Blackwellized objective without further assumptions on the missingness mechanism or the quality of those models.
What would settle it
Train the same diffusion backbone with AugMask and with a standard missing-aware baseline on a dataset where the auxiliary predictors are deliberately inaccurate; if AugMask no longer outperforms the baseline or produces visibly worse samples, the central claim is falsified.
Figures
read the original abstract
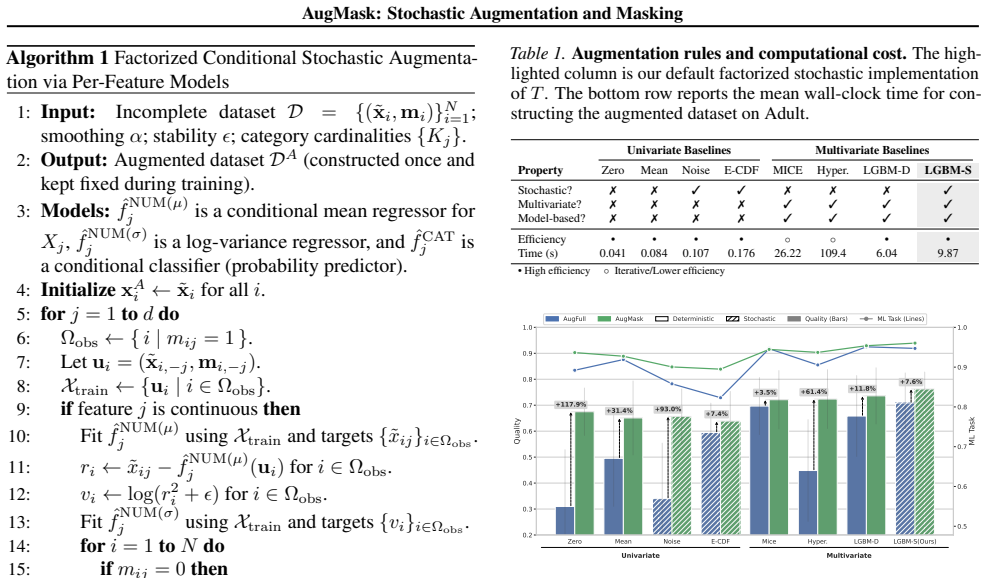
Score-based diffusion models have emerged as prominent deep generative models; however, their application to tabular data remains challenging because their backbones assume fully specified inputs, whereas real-world tabular data often contain missing values. We propose AugMask, a plug-and-play training framework that adapts missing-unaware backbones to incomplete data by separating conditioning from supervision. AugMask 1) constructs numeric inputs via conditional stochastic augmentation using lightweight auxiliary models, and 2) applies denoising supervision only to observed coordinates. In effect, augmented missing entries serve as uncertain conditioning context rather than training targets. We connect this training rule to a Rao--Blackwellized objective and show that marginalizing missing entries yields a variance-weighted sensitivity penalty, discouraging over-reliance on uncertain completions. Across diverse datasets and missingness regimes, AugMask enables standard diffusion-based tabular generators to outperform specialized missing-aware baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AugMask, a plug-and-play training framework for adapting standard score-based diffusion models to tabular data containing missing values. It separates conditioning from supervision by constructing numeric inputs via conditional stochastic augmentation with lightweight auxiliary models and applying denoising supervision exclusively to observed coordinates. Augmented missing entries function as uncertain conditioning context. The training rule is connected to a Rao-Blackwellized objective in which marginalization over missing entries produces a variance-weighted sensitivity penalty. The central empirical claim is that this enables unmodified diffusion-based tabular generators to outperform specialized missing-aware baselines across diverse datasets and missingness regimes.
Significance. If the empirical outperformance is demonstrated with appropriate controls and the Rao-Blackwellized connection is derived without unstated assumptions on the auxiliary models or missingness mechanism, the contribution would be significant. It would provide a lightweight way to retrofit existing diffusion backbones for incomplete tabular data, reducing the need for custom missing-aware architectures while supplying a principled penalty for reliance on uncertain imputations.
major comments (2)
- [Abstract] Abstract (paragraph on training rule and Rao-Blackwellized objective): the claim that marginalizing missing entries yields a variance-weighted sensitivity penalty that discourages over-reliance on uncertain completions without further assumptions on the missingness mechanism (MCAR/MAR/MNAR) or auxiliary predictor quality is load-bearing for the robustness claim. The derivation appears to presuppose that auxiliary completions are drawn from the correct conditional distribution; if this does not hold, the marginalization argument does not guarantee the stated penalty or the claimed performance across regimes.
- [Abstract] Abstract (empirical claim): the statement that AugMask enables outperformance across diverse datasets and missingness regimes is presented without any quantitative metrics, error bars, dataset names, missingness fractions, or baseline comparisons. This absence prevents evaluation of whether the central empirical result is supported.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on training rule and Rao-Blackwellized objective): the claim that marginalizing missing entries yields a variance-weighted sensitivity penalty that discourages over-reliance on uncertain completions without further assumptions on the missingness mechanism (MCAR/MAR/MNAR) or auxiliary predictor quality is load-bearing for the robustness claim. The derivation appears to presuppose that auxiliary completions are drawn from the correct conditional distribution; if this does not hold, the marginalization argument does not guarantee the stated penalty or the claimed performance across regimes.
Authors: We agree that the Rao-Blackwellized derivation relies on the auxiliary models generating samples from the true conditional distribution of the missing values. The manuscript connects the training rule to this objective under that modeling assumption, but does not explicitly discuss the consequences of approximation error in the auxiliaries. We will revise the relevant section (and abstract) to state the assumption clearly and note that the variance-weighted penalty holds exactly only when the auxiliaries match the conditional; in practice the method remains effective when the auxiliaries are reasonable approximations, as supported by the experiments. This clarification will be added in the next version. revision: yes
-
Referee: [Abstract] Abstract (empirical claim): the statement that AugMask enables outperformance across diverse datasets and missingness regimes is presented without any quantitative metrics, error bars, dataset names, missingness fractions, or baseline comparisons. This absence prevents evaluation of whether the central empirical result is supported.
Authors: The abstract is intentionally concise and defers quantitative detail to the body of the paper, where results are reported with metrics, standard errors, dataset names, missingness fractions, and baseline comparisons. To improve immediate readability of the central claim, we will revise the abstract to include one or two key quantitative highlights (e.g., average improvement and number of datasets) while remaining within length limits. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper introduces AugMask as a training framework that uses conditional stochastic augmentation and applies denoising only to observed coordinates, then connects this rule to a Rao-Blackwellized objective whose marginalization produces a variance-weighted penalty. No equations or self-citations are shown that reduce the claimed outperformance or the marginalization property to a quantity fitted or defined by the same paper's inputs. The central empirical claim rests on evaluation across datasets and regimes rather than a tautological reduction, and the auxiliary-model assumption is stated explicitly without being smuggled in via prior self-work. This is the normal case of a method paper whose justification does not collapse by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Real-valued (Medical) Time Series Generation with Recurrent Conditional GANs
PMLR, 2019. Esteban, C., Hyland, S. L., and R ¨atsch, G. Real-valued (medical) time series generation with recurrent condi- tional gans.arXiv preprint arXiv:1706.02633, 2017. Givens, J., Liu, S., and Reeve, H. W. Score matching with missing data.arXiv preprint arXiv:2506.00557, 2025. Grinsztajn, L., Oyallon, E., and Varoquaux, G. Why do tree- based models...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
Mueller, M., Gruber, K., and Fok, D
PMLR, 2019. Mueller, M., Gruber, K., and Fok, D. Continuous dif- fusion for mixed-type tabular data. InThe Thirteenth International Conference on Learning Representations,
2019
-
[3]
URL https://openreview.net/forum? id=QPtoBPn4lZ. Nazabal, A., Olmos, P. M., Ghahramani, Z., and Valera, I. Handling incomplete heterogeneous data using vaes. Pattern Recognition, 107:107501, 2020. Ouyang, Y ., Xie, L., Li, C., and Cheng, G. Missdiff: Train- ing diffusion models on tabular data with missing values. arXiv preprint arXiv:2307.00467, 2023. Pe...
-
[4]
URL https://openreview.net/forum? id=swvURjrt8z. Song, Y ., Durkan, C., Murray, I., and Ermon, S. Maxi- mum likelihood training of score-based diffusion models. Advances in neural information processing systems, 34: 1415–1428, 2021. Vincent, P. A connection between score matching and de- noising autoencoders.Neural computation, 23(7):1661– 1674, 2011. Wag...
-
[5]
com/vanderschaarlab/hyperimpute, which fits pθ(xobs|z) and qγ(z|xobs) so that it can be refactored into a generative model
MIWAE(Mattei & Frellsen, 2019): We have modified the MIWAE imputation plugin from https://github. com/vanderschaarlab/hyperimpute, which fits pθ(xobs|z) and qγ(z|xobs) so that it can be refactored into a generative model. We sample z from the prior distribution p(z) and generate x=p θ(x|z). For training, we set n epochs to 800 (default: 500), latent size ...
2019
-
[6]
To align the model size with other methods, we set batchsize to 64, diffusion embedding dim and timeembed to 1024, layers to 5, and channels to 256
MissDiffWe use the implementation provided in the supplementary material at https://openreview.net/ forum?id=PyyoSwPaSa, which is a variant of TabCSDI (Zheng & Charoenphakdee, 2022) (see https:// github.com/pfnet-research/TabCSDI). To align the model size with other methods, we set batchsize to 64, diffusion embedding dim and timeembed to 1024, layers to ...
2022
-
[7]
The default parameters (nt = 50, duplicateK = 100) did not converge within 3600 seconds
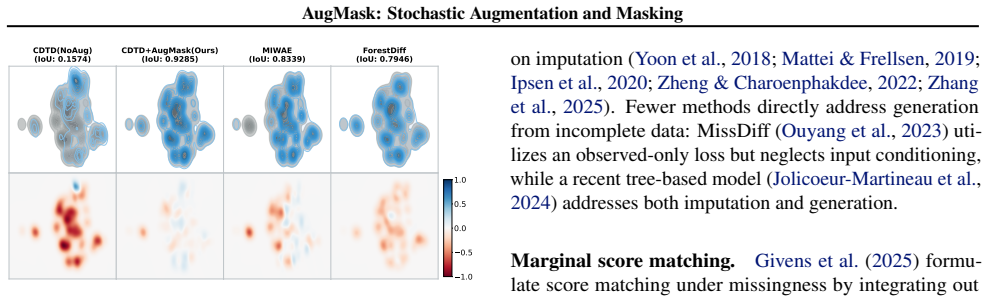
ForestDiff(Jolicoeur-Martineau et al., 2024) We use the default implementation from https://github.com/ SamsungSAILMontreal/ForestDiffusion, setting nt = 20 and duplicateK = 10 as recommended by the authors to reduce training time. The default parameters (nt = 50, duplicateK = 100) did not converge within 3600 seconds. For thenewsdataset (48 columns), we ...
2024
-
[8]
The official implementation ( https://github.com/hengruizhang98/ DiffPuter) applies binary encoding for categorical variables, while the paper describes one-hot encoding
DiffPuter(Zhang et al., 2025). The official implementation ( https://github.com/hengruizhang98/ DiffPuter) applies binary encoding for categorical variables, while the paper describes one-hot encoding. We tested both and found that binary encoding can introduce imputation artifacts (e.g., spurious categories) and consistently underperformed one-hot encodi...
2025
-
[9]
In particular, we use 20 trees, δ = 0 and a minimum node size of 5
ARF(Watson et al., 2023): We use the authors’s suggested default hyperparameters. In particular, we use 20 trees, δ = 0 and a minimum node size of 5. We follow the official package implementation and set the maximum number of iterations to 10 (see https://github.com/bips-hb/arfpy)
2023
-
[10]
For this model to work, the batch size must be divisible by 10
CTGAN(Xu et al., 2019): We follow the popular implementation in the Synthetic Data Vault package (see https://github.com/sdv-dev/CTGAN). For this model to work, the batch size must be divisible by 10. Therefore, we adjust the batch size if necessary. We use a 256-dimensional embedding (instead of the default embedding dimension of 128) to better align the...
2019
-
[11]
We use a 256-dimensional embedding to better align the architecture with CTGAN, TabSyn and CDTD
TV AE(Xu et al., 2019): We again follow the implementation in the Synthetic Data Vault. We use a 256-dimensional embedding to better align the architecture with CTGAN, TabSyn and CDTD
2019
-
[12]
The training steps that go towards training the V AE and the denoising network follow the proportions given in the official code (see https://github.com/amazon-science/tabsyn)
TabSyn(Zhang et al., 2023): We use the default hyperparameters as suggested by the authors. The training steps that go towards training the V AE and the denoising network follow the proportions given in the official code (see https://github.com/amazon-science/tabsyn). To improve comparability to CDTD, we use the same neural network architecture as TabDDPM...
2023
-
[13]
We train for 30k steps with Adam (lr 2·10 −4) and EMA decay 0.999; sampling batch size is 2000
TabDDPM(Kotelnikov et al., 2023): 3-layer MLP with 256 hidden units; 1000 diffusion steps with cosine scheduler and time embedding dim 128. We train for 30k steps with Adam (lr 2·10 −4) and EMA decay 0.999; sampling batch size is 2000
2023
-
[14]
Diffusion uses 50 timesteps with EDM-style preconditioning (e.g., σmin = 0.002, σmax = 80, σdata = 1.0)
TabDiff(Shi et al., 2025): Transformer-based denoiser with 2 layers ( dtoken = 4, 1 head) and a 5-layer MLP head (801 units), time embedding dim 256. Diffusion uses 50 timesteps with EDM-style preconditioning (e.g., σmin = 0.002, σmax = 80, σdata = 1.0). We train for 30k steps with Adam (lr 10−3) and EMA decay 0.997; we use 200 generation steps at sampling time
2025
-
[15]
CDTD(Mueller et al., 2025): We set the hidden layers to 796, number of layers to 5, dimension of the MLP/time embedding to 256. Also, as CDTD uses the EDM framework (Karras et al., 2022), withσcat min = 0, σcat max = 100, σcont min = 0, σcont max = 80, σcat data = 1.0, σcont data = 1.0., we do not change this. Also, we use the learned noise-schedule confi...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.