Drop-Then-Recovery: How Redundant Are Vision-Language-Action Models?
Pith reviewed 2026-06-29 04:54 UTC · model grok-4.3
The pith
Language backbones in vision-language-action models are highly redundant for standard robotic manipulation tasks while vision and action pathways are not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
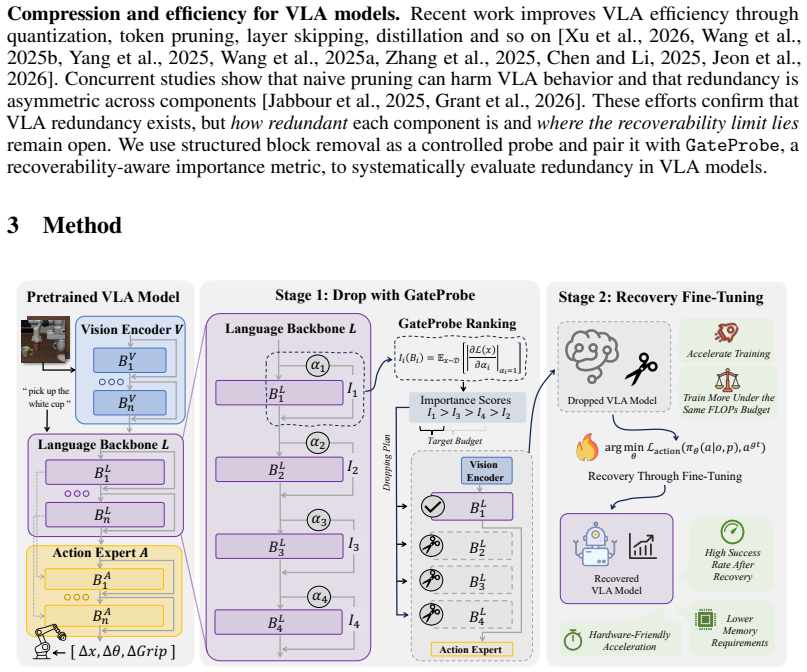
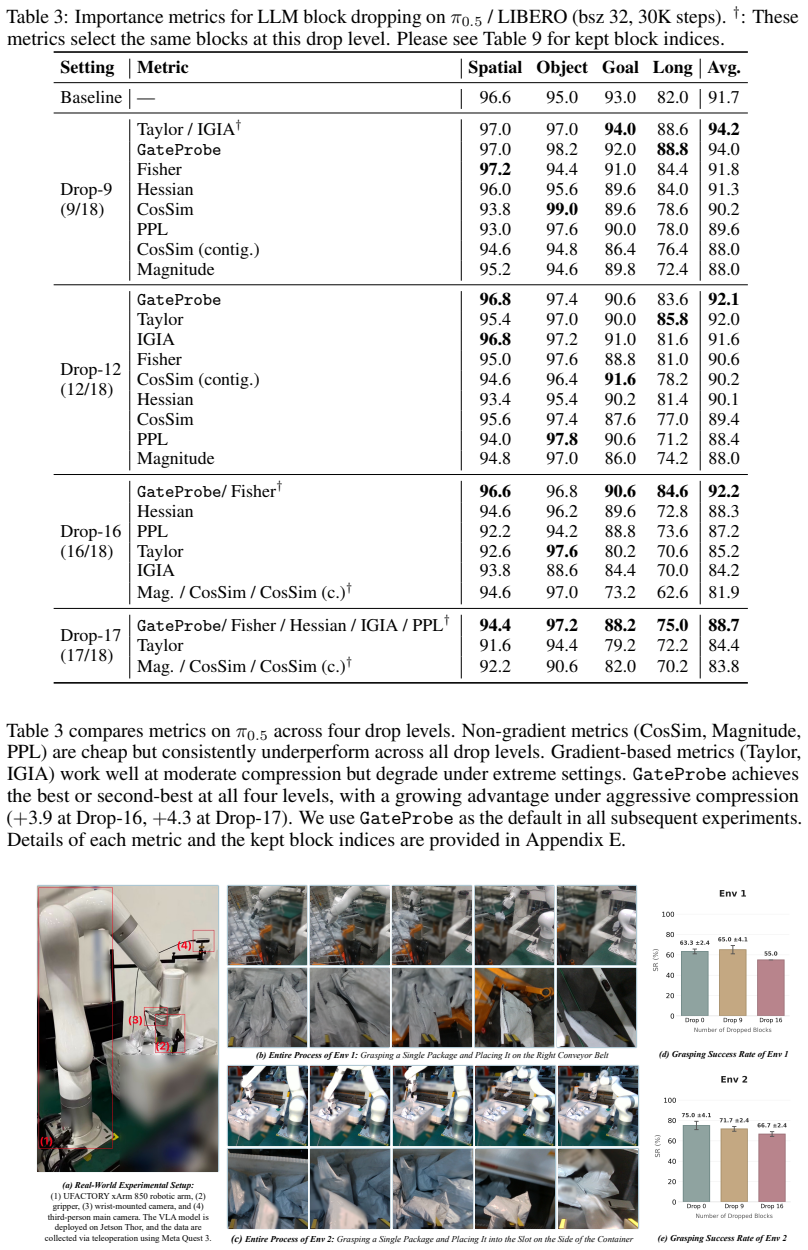
Using the Drop-Then-Recovery protocol, which removes selected transformer blocks from a pretrained VLA model and fine-tunes the rest, the authors show a strong asymmetry: language backbones are highly redundant for standard robotic manipulation tasks, whereas vision and action pathways are substantially less tolerant to removal. On the LIBERO benchmark, removing half of the LLM blocks improved OpenVLA-OFT from 95.0% to 98.3%, and keeping only two language blocks still matched baseline performance.
What carries the argument
The Drop-Then-Recovery (DTR) protocol, which removes transformer blocks followed by fine-tuning to test necessity, guided by the GateProbe one-shot sensitivity metric that ranks blocks by contribution to downstream action loss.
If this is right
- Current VLA benchmarks exert limited pressure on deep language grounding and compositional instruction understanding.
- Retaining only two language blocks can still recover baseline-level performance on standard tasks.
- Removing half the language blocks can raise success rates under a fixed fine-tuning budget.
- Future VLA designs should allocate capacity more deliberately across language, vision, and action components.
Where Pith is reading between the lines
- Simpler language models could be substituted into VLA architectures to cut compute and latency with little effect on manipulation.
- New benchmarks that force richer instruction following might reveal greater need for language capacity than current suites do.
- Robotic system designers could prioritize vision and action modules over expanding language backbones.
Load-bearing premise
Fine-tuning after block removal fully reveals whether the removed capacity was necessary, rather than the fine-tuning process allowing recovery through unrelated mechanisms.
What would settle it
A manipulation benchmark requiring compositional language understanding on which removing most language blocks produces large, unrecoverable performance drops even after the same fine-tuning budget.
Figures

read the original abstract
Vision-Language-Action (VLA) models enable instruction-driven robotic manipulation, but they inherit oversized language backbones from pretrained VLMs whose capacity far exceeds what is needed for short robotic instructions. This raises a basic question: how much of a VLA model is actually necessary for closed-loop control? In this work, we study architectural redundancy in VLA models by using transformer block removal as a controlled intervention. We introduce \textbf{Drop-Then-Recovery (DTR)}, an analysis protocol that removes selected blocks from a pretrained VLA model and then fine-tunes the resulting model to measure whether the removed capacity was necessary for downstream control. To make this intervention reliable, we propose \textbf{GateProbe}, a one-shot virtual-gate sensitivity metric that ranks blocks by their contribution to the downstream action loss. Across multiple VLA architectures, manipulation benchmarks and even real-robot industrial scenarios, we find a strong asymmetry in post-removal recoverability: \ul{\textit{language backbones are highly redundant for standard robotic manipulation tasks, whereas vision and action pathways are substantially less tolerant to removal}}. On LIBERO, removing half of the LLM blocks even improves OpenVLA-OFT from 95.0% to 98.3% under the same downstream fine-tuning budget, and retaining only two language blocks still recovers baseline-level performance. These results suggest that current VLA benchmarks may exert limited pressure on deep language grounding and compositional instruction understanding, and that future VLA architectures should allocate capacity more deliberately across language, vision, and action components. The code is available at https://github.com/s1ghhh/VLADrop.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Drop-Then-Recovery (DTR) protocol, which removes selected transformer blocks from pretrained Vision-Language-Action (VLA) models and fine-tunes the resulting architecture to assess whether the removed capacity was necessary for robotic manipulation. Using GateProbe to rank block sensitivity, experiments across multiple VLA models, the LIBERO benchmark, and real-robot scenarios show a strong asymmetry: language backbone blocks are highly redundant (e.g., removing half the LLM blocks in OpenVLA-OFT improves success from 95.0% to 98.3%, and two blocks suffice for baseline performance), while vision and action pathways are far less tolerant to removal. The authors conclude that current VLA benchmarks exert limited pressure on deep language grounding and recommend more deliberate capacity allocation.
Significance. If the empirical results hold under the reported conditions, the work provides concrete evidence that language components in current VLA models are oversized relative to task demands, with direct implications for designing more efficient architectures. Credit is due for testing multiple architectures, including real-robot validation, releasing code, and explicitly noting the possibility that recovery reflects benchmark limitations rather than true redundancy.
major comments (2)
- [Abstract / Results] Abstract and results on OpenVLA-OFT: the reported improvement from 95.0% to 98.3% after removing half the LLM blocks is presented without variance estimates, number of runs, or statistical significance tests; this weakens the claim that removal can improve performance and leaves open whether the change lies within baseline variability.
- [DTR protocol] DTR protocol description: the central interpretation that post-fine-tuning recovery demonstrates language redundancy assumes identical fine-tuning budgets and task distributions cannot enable compensatory mechanisms in the remaining vision-action stack; while the manuscript flags this possibility, the asymmetry conclusion would be strengthened by explicit controls (e.g., harder compositional instructions or language-grounding probes) that are not reported.
minor comments (1)
- [Abstract] The abstract uses inline LaTeX markup (\ul{\textit{...}}) that should be rendered or removed for clarity in the final version.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results on OpenVLA-OFT: the reported improvement from 95.0% to 98.3% after removing half the LLM blocks is presented without variance estimates, number of runs, or statistical significance tests; this weakens the claim that removal can improve performance and leaves open whether the change lies within baseline variability.
Authors: We agree that the absence of variance estimates and statistical tests weakens the presentation of the 95.0% to 98.3% improvement. In the revised manuscript we will report results aggregated over multiple random seeds (minimum three runs per condition) with standard deviations and paired statistical tests to establish whether observed differences exceed baseline variability. revision: yes
-
Referee: [DTR protocol] DTR protocol description: the central interpretation that post-fine-tuning recovery demonstrates language redundancy assumes identical fine-tuning budgets and task distributions cannot enable compensatory mechanisms in the remaining vision-action stack; while the manuscript flags this possibility, the asymmetry conclusion would be strengthened by explicit controls (e.g., harder compositional instructions or language-grounding probes) that are not reported.
Authors: The manuscript already explicitly flags that post-removal recovery may reflect limitations of existing benchmarks rather than intrinsic redundancy (Section 4.3 and concluding paragraph). While additional controls such as harder compositional tasks or dedicated language-grounding probes would provide further support, we maintain that the reported asymmetry is robust under the standard manipulation benchmarks and real-robot settings examined. Extending the evaluation to new, more demanding language tasks constitutes a natural direction for follow-up work rather than a requirement for the current claims. revision: partial
Circularity Check
No circularity: purely empirical intervention study
full rationale
The paper defines an experimental protocol (Drop-Then-Recovery with GateProbe ranking) and reports measured post-fine-tuning success rates on fixed benchmarks. No equations, parameter fits, or derivations appear that would reduce the reported recovery percentages to quantities defined by the same measurements or by self-citation chains. The asymmetry conclusion follows directly from the observed numbers rather than from any self-referential construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fine-tuning the remaining model after block removal can recover performance if the removed blocks were redundant for the task
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[2]
PaliGemma: A versatile 3B VLM for transfer
Paligemma: A versatile 3b vlm for transfer , author=. arXiv preprint arXiv:2407.07726 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
PaliGemma 2: A Family of Versatile VLMs for Transfer
Paligemma 2: A family of versatile vlms for transfer , author=. arXiv preprint arXiv:2412.03555 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Gemma: Open Models Based on Gemini Research and Technology
Gemma: Open models based on gemini research and technology , author=. arXiv preprint arXiv:2403.08295 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
A Simple and Effective Pruning Approach for Large Language Models
A simple and effective pruning approach for large language models , author=. arXiv preprint arXiv:2306.11695 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Advances in neural information processing systems , volume=
Llm-pruner: On the structural pruning of large language models , author=. Advances in neural information processing systems , volume=
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Prune&comp: Free lunch for layer-pruned llms via iterative pruning with magnitude compensation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[11]
2025 , doi =
Men, Xin and Xu, Mingyu and Zhang, Qingyu and Yuan, Qianhao and Wang, Bingning and Lin, Hongyu and Lu, Yaojie and Han, Xianpei and Chen, Weipeng , booktitle =. 2025 , doi =
2025
-
[12]
arXiv preprint arXiv:2406.15786 , year =
What Matters in Transformers? Not All Attention is Needed , author =. arXiv preprint arXiv:2406.15786 , year =
-
[13]
International Conference on Learning Representations , year =
The Unreasonable Ineffectiveness of the Deeper Layers , author =. International Conference on Learning Representations , year =
-
[14]
arXiv preprint arXiv:2601.19503 , year=
GradPruner: Gradient-Guided Layer Pruning Enabling Efficient Fine-Tuning and Inference for LLMs , author=. arXiv preprint arXiv:2601.19503 , year=
-
[15]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Laco: Large language model pruning via layer collapse , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[16]
Demystifying When Pruning Works via Representation Hierarchies
Demystifying When Pruning Works via Representation Hierarchies , author=. arXiv preprint arXiv:2603.24652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Importance estimation for neural network pruning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[18]
and Soricut, Radu and Singh, Anikait and Singh, Jaspiar and Sermanet, Pierre and Sanketi, Pannag R
Zitkovich, Brianna and Yu, Tianhe and Xu, Sichun and Xu, Peng and Xiao, Ted and Xia, Fei and Wu, Jialin and Wohlhart, Paul and Welker, Stefan and Wahid, Ayzaan and Vuong, Quan and Vanhoucke, Vincent and Tran, Huong T. and Soricut, Radu and Singh, Anikait and Singh, Jaspiar and Sermanet, Pierre and Sanketi, Pannag R. and Salazar, Grecia and Ryoo, Michael S...
2023
-
[19]
and Sanketi, Pannag R
Kim, Moo Jin and Pertsch, Karl and Karamcheti, Siddharth and Xiao, Ted and Balakrishna, Ashwin and Nair, Suraj and Rafailov, Rafael and Foster, Ethan P. and Sanketi, Pannag R. and Vuong, Quan and Kollar, Thomas and Burchfiel, Benjamin and Tedrake, Russ and Sadigh, Dorsa and Levine, Sergey and Liang, Percy and Finn, Chelsea , booktitle =. 2025 , publisher =
2025
-
[20]
2025 , doi =
Black, Kevin and Brown, Noah and Driess, Danny and Esmail, Adnan and Equi, Michael Robert and Finn, Chelsea and Fusai, Niccolo and Groom, Lachy and Hausman, Karol and Ichter, Brian and Jakubczak, Szymon and Jones, Tim and Ke, Liyiming and Levine, Sergey and Li-Bell, Adrian and Mothukuri, Mohith and Nair, Suraj and Pertsch, Karl and Shi, Lucy Xiaoyang and ...
2025
-
[21]
Black, Kevin and Brown, Noah and Darpinian, James and Dhabalia, Karan and Driess, Danny and Esmail, Adnan and Equi, Michael Robert and Finn, Chelsea and Fusai, Niccolo and Galliker, Manuel Y. and Ghosh, Dibya and Groom, Lachy and Hausman, Karol and Ichter, Brian and Jakubczak, Szymon and Jones, Tim and Ke, Liyiming and LeBlanc, Devin and Levine, Sergey an...
2025
-
[22]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success , author =. arXiv preprint arXiv:2502.19645 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics: Bringing. arXiv preprint arXiv:2503.20020 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment: Robotic Learning Datasets and. arXiv preprint arXiv:2310.08864 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Frantar, Elias and Ashkboos, Saleh and Hoefler, Torsten and Alistarh, Dan , booktitle =
-
[26]
International Conference on Learning Representations , year =
A Simple and Effective Pruning Approach for Large Language Models , author =. International Conference on Learning Representations , year =
-
[27]
2023 , publisher =
Frantar, Elias and Alistarh, Dan , booktitle =. 2023 , publisher =
2023
-
[28]
Ma, Xinyin and Fang, Gongfan and Wang, Xinchao , booktitle =
-
[29]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , booktitle =
-
[30]
and do Nascimento, Marcelo Gennari and Hoefler, Torsten and Hensman, James , booktitle =
Ashkboos, Saleh and Croci, Maximilian L. and do Nascimento, Marcelo Gennari and Hoefler, Torsten and Hensman, James , booktitle =
-
[31]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Router-Tuning: A Simple and Effective Approach for Dynamic Depth , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[32]
Song, Jiwon and Oh, Kyungseok and Kim, Taesu and Kim, Hyungjun and Kim, Yulhwa and Kim, Jae-Joon , journal =
-
[33]
arXiv preprint arXiv:2510.24795 , year =
A Survey on Efficient Vision-Language-Action Models , author =. arXiv preprint arXiv:2510.24795 , year =
-
[34]
Xu, Yuhao and Yang, Yantai and Fan, Zhenyang and Liu, Yufan and Li, Yuming and Li, Bing and Zhang, Zhipeng , journal =
-
[35]
Wang, Hongyu and Xiong, Chuyan and Wang, Ruiping and Chen, Xilin , journal =
-
[36]
Yang, Yantai and Wang, Yuhao and Wen, Zichen and Luo, Zhongwei and Zou, Chang and Zhang, Zhipeng and Wen, Chuan and Zhang, Linfeng , journal =
-
[37]
Wang, Hanzhen and Xu, Jiaming and Xiang, Yushun and Pan, Jiayi and Zhou, Yongkang and Li, Yong-Lu and Dai, Guohao , journal =
-
[38]
Zhang, Rongyu and Dong, Menghang and Zhang, Yuan and Heng, Liang and Chi, Xiaowei and Dai, Gaole and Du, Li and Du, Yuan and Zhang, Shanghang , journal =
-
[39]
Chen, Yuxuan and Li, Xiao , journal =
-
[40]
Shallow- : Knowledge Distillation for Flow-based
Jeon, Boseong and Choi, Yunho and Kim, Taehan , journal =. Shallow- : Knowledge Distillation for Flow-based
-
[41]
Don't Run with Scissors: Pruning Breaks
Jabbour, Jason and Kim, Dong-Ki and Smith, Max and Patrikar, Jay and Ghosal, Radhika and Wang, Youhui and Agha, Ali and Janapa Reddi, Vijay and Omidshafiei, Shayegan , journal =. Don't Run with Scissors: Pruning Breaks
-
[42]
arXiv preprint arXiv:2603.19233 , year =
Not All Features Are Created Equal: A Mechanistic Study of Vision-Language-Action Models , author =. arXiv preprint arXiv:2603.19233 , year =
-
[43]
arXiv preprint arXiv:2505.21200 , year =
Think Twice, Act Once: Token-Aware Compression and Action Reuse for Efficient Inference in Vision-Language-Action Models , author =. arXiv preprint arXiv:2505.21200 , year =
-
[44]
arXiv preprint arXiv:2509.12594 , year =
The Better You Learn, The Smarter You Prune: Towards Efficient Vision-language-action Models via Differentiable Token Pruning , author =. arXiv preprint arXiv:2509.12594 , year =
-
[45]
2023 , note =
Liu, Bo and Zhu, Yifeng and Gao, Chongkai and Feng, Yihao and Liu, Qiang and Zhu, Yuke and Stone, Peter , booktitle =. 2023 , note =
2023
-
[46]
Fei, Senyu and Wang, Siyin and Shi, Junhao and Dai, Zihao and Cai, Jikun and Qian, Pengfang and Ji, Li and He, Xinzhe and Zhang, Shiduo and Fei, Zhaoye and Fu, Jinlan and Gong, Jingjing and Qiu, Xipeng , journal =
-
[47]
Vision-Language-Action in Robotics: A Survey of Datasets, Benchmarks, and Data Engines
Vision-Language-Action in Robotics: A Survey of Datasets, Benchmarks, and Data Engines , author=. arXiv preprint arXiv:2604.23001 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Chen, Tianxing and Chen, Zanxin and Chen, Baijun and Cai, Zijian and Liu, Yibin and Li, Zixuan and Liang, Qiwei and Lin, Xianliang and Ge, Yiheng and Gu, Zhenyu and Deng, Weiliang and Guo, Yubin and Nian, Tian and Xie, Xuanbing and Chen, Qiangyu and Su, Kailun and Xu, Tianling and Liu, Guodong and Hu, Mengkang and Gao, Huan-ang and Wang, Kaixuan and Liang...
-
[49]
A Pragmatic
Wu, Wei and Lu, Fan and Wang, Yunnan and Yang, Shuai and Liu, Shi and Wang, Fangjing and Zhu, Qian and Sun, He and Wang, Yong and Ma, Shuailei and Ren, Yiyu and Zhang, Kejia and Yu, Hui and Zhao, Jingmei and Zhou, Shuai and Qiu, Zhenqi and Xiong, Houlong and Wang, Ziyu and Wang, Zechen and Cheng, Ran and Li, Yong-Lu and Huang, Yongtao and Zhu, Xing and Sh...
-
[50]
arXiv preprint arXiv:2602.17951 , year=
ROCKET: Residual-Oriented Multi-Layer Alignment for Spatially-Aware Vision-Language-Action Models , author=. arXiv preprint arXiv:2602.17951 , year=
-
[51]
arXiv preprint arXiv:2510.12276 , year=
Spatial forcing: Implicit spatial representation alignment for vision-language-action model , author=. arXiv preprint arXiv:2510.12276 , year=
- [52]
-
[53]
2026 , howpublished =
2026
-
[54]
2026 , howpublished =
Working with Quantized Types , author =. 2026 , howpublished =
2026
-
[55]
Structured Sparsity in the
Bai, Hongxiao and Li, Yun , year =. Structured Sparsity in the
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.