Ultra Diffusion Poser: Diffusion-Based Human Motion Tracking From Sparse Inertial Sensors and Ranging-Based Between-Sensor Distances
Pith reviewed 2026-06-28 15:06 UTC · model grok-4.3
The pith
Diffusion model reconstructs 3D sensor positions from UWB distances to improve human motion tracking accuracy by up to 22%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
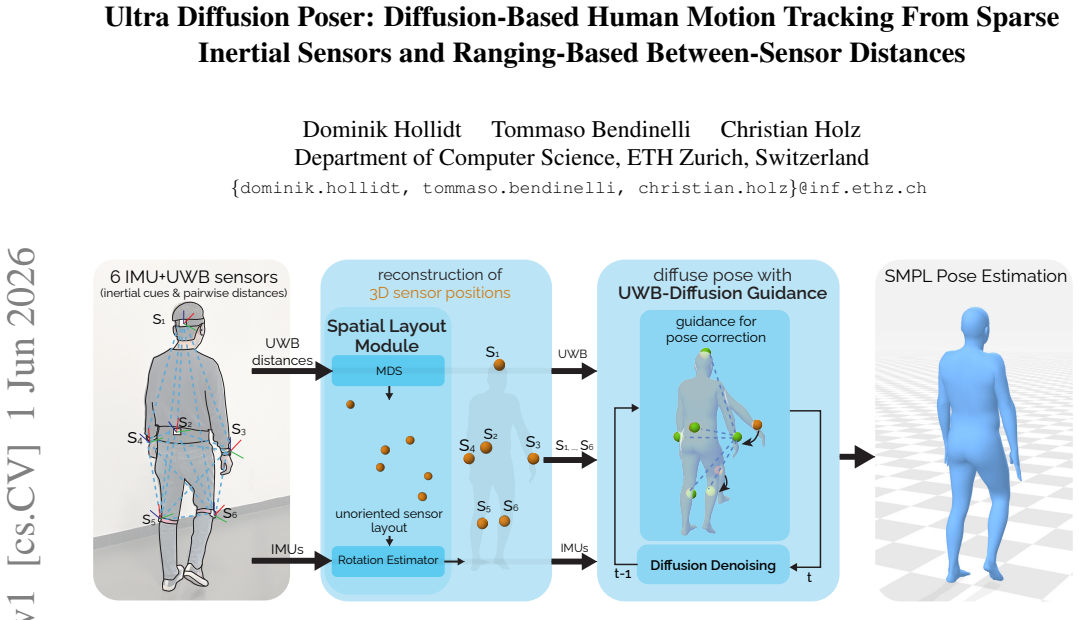
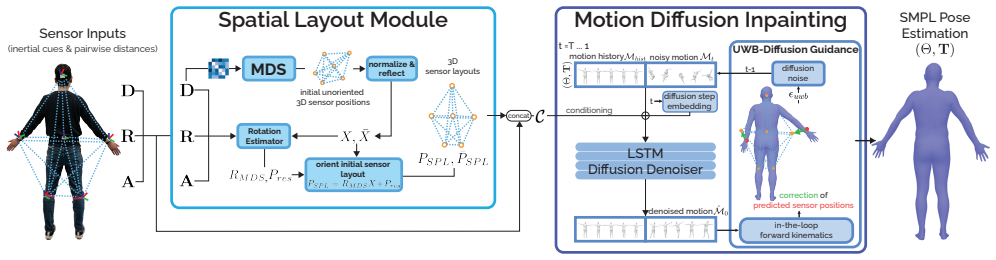
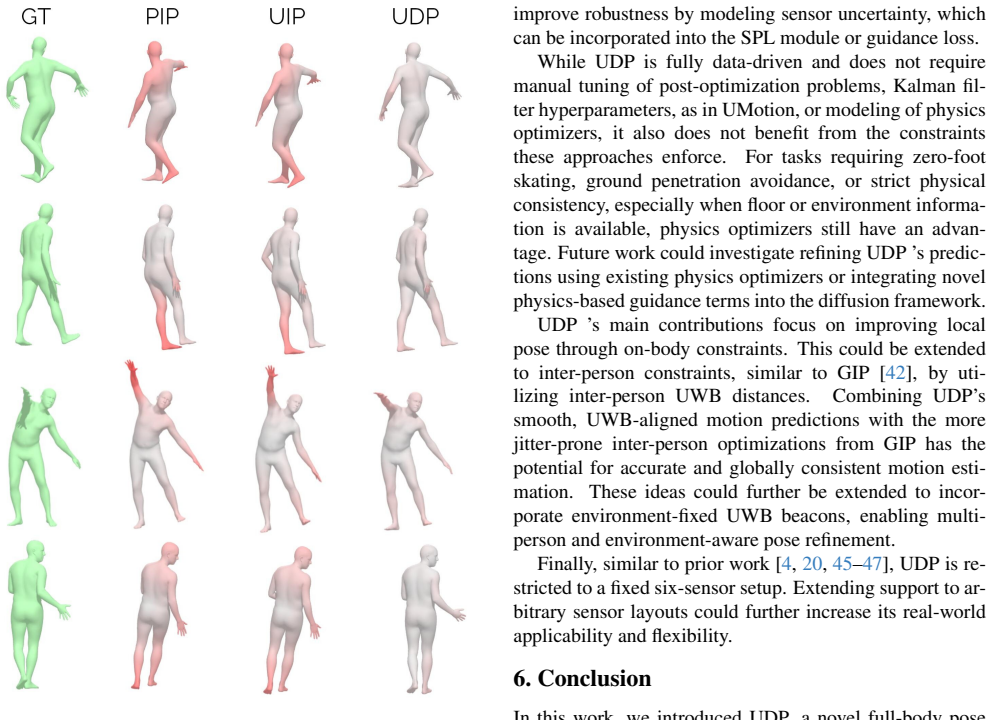
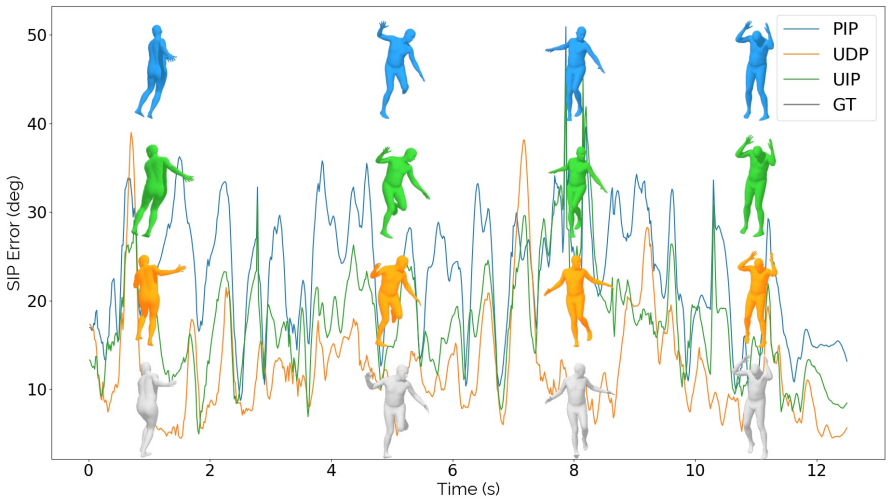
Ultra Diffusion Poser is a diffusion model that conditions on IMU signals, UWB distances, and 3D sensor positions reconstructed analytically from those distances via a Spatial Layout Module. It further applies UWB-Diffusion Guidance during sampling to ensure predicted poses respect the measured inter-sensor distances. This combination allows the model to achieve state-of-the-art results, with joint position error reduced by as much as 22% compared to prior methods.
What carries the argument
The Spatial Layout Module for analytical 3D sensor position reconstruction from UWB measurements, used as additional conditioning input, along with the UWB-Diffusion Guidance that enforces distance alignment in the diffusion process.
If this is right
- The approach outperforms prior sparse inertial pose estimators that use UWB only as input features.
- Explicit geometric reconstruction provides more informative conditioning for the diffusion model.
- Guidance during sampling prevents violations of physical distance constraints in generated poses.
- Overall, this leads to lower joint position errors in human motion tracking tasks.
Where Pith is reading between the lines
- Such methods might extend to dynamic environments where sensor layouts change over time.
- Combining analytical reconstruction with learned components could apply to other sensor fusion problems in robotics.
- The guidance technique might reduce the need for large training datasets by enforcing constraints at inference time.
Load-bearing premise
UWB distance measurements are accurate enough to support reliable analytical reconstruction of the three-dimensional sensor layout.
What would settle it
Running the model on a dataset where UWB measurements contain significant noise or errors and checking if the claimed error reduction over baselines still holds.
Figures

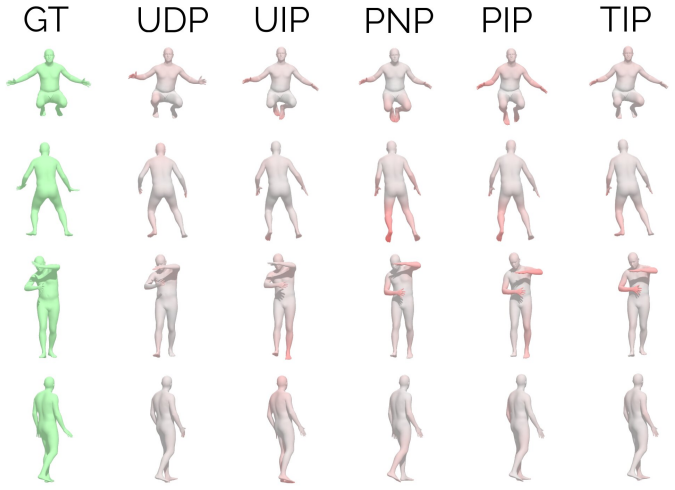
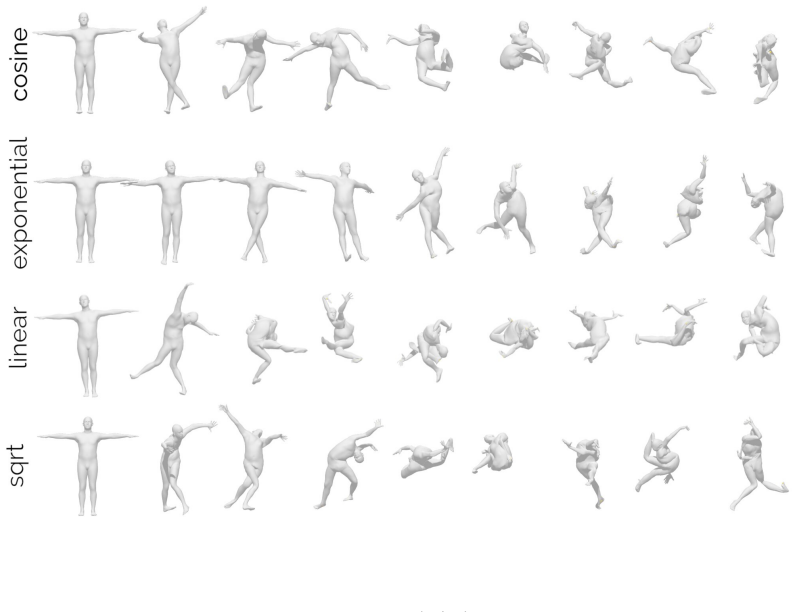
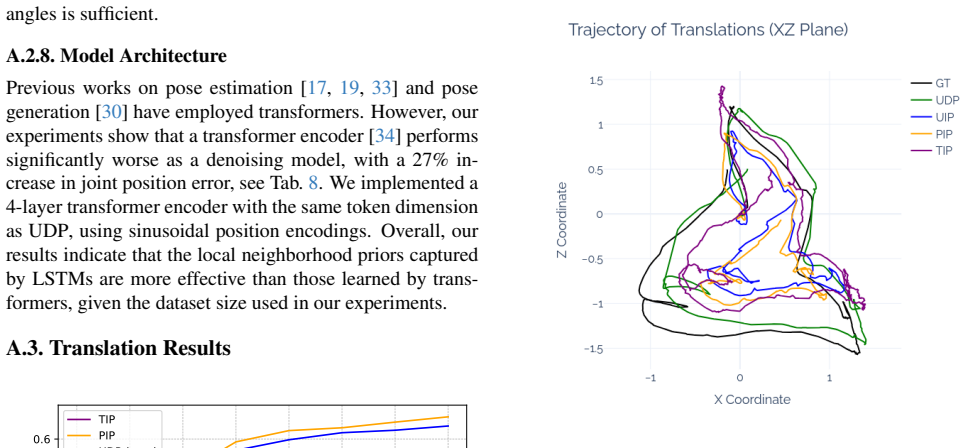
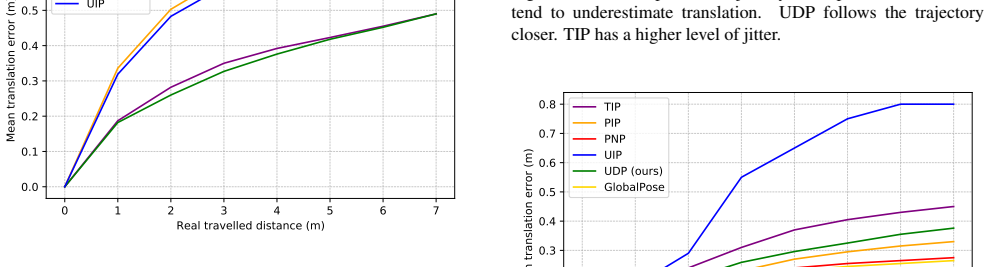
read the original abstract
Methods using inertial measurement units (IMUs) provide a wearable alternative to camera-based motion capture. To mitigate drift from inertial signals, recent sparse inertial pose estimators integrate inter-sensor distances measured by ultra-wideband (UWB) ranging. So far, UWB distances have only been used as an additional input feature, ignoring the physical constraints they impose on sensor positions. However, these distances can also be used to reconstruct the underlying 3D sensor layout, which in turn provides more informative input for pose reconstruction. We propose Ultra Diffusion Poser, a diffusion model that explicitly models these geometric constraints. It includes a Spatial Layout Module that analytically reconstructs the 3D sensor positions from UWB measurements. These sensor positions are used alongside IMU signals and UWB distances as a conditioning signal during diffusion. Still, network predictions can violate inter-sensor distance measurements. To address this, we introduce UWB-Diffusion Guidance, which encourages alignment between predicted poses and measured distances during diffusion sampling. Together, these contributions enable our model to achieve state-of-the-art performance, reducing joint position error by up to 22% over prior work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Ultra Diffusion Poser, a diffusion model for human motion tracking from sparse IMUs augmented by UWB inter-sensor distances. It introduces a Spatial Layout Module that analytically reconstructs 3D sensor positions from the UWB measurements to serve as additional conditioning, and an UWB-Diffusion Guidance term applied during sampling to enforce consistency with the measured distances. The authors claim these components together yield state-of-the-art performance, with up to 22% reduction in joint position error over prior work.
Significance. If the performance gains are shown to be robust, the explicit use of analytically reconstructed geometry as conditioning and the diffusion guidance mechanism could meaningfully advance sparse wearable motion capture by better exploiting the physical constraints encoded in ranging data. The approach builds on standard diffusion models with targeted additions rather than relying solely on learned features.
major comments (2)
- [Abstract (Spatial Layout Module description)] Abstract (Spatial Layout Module): the analytical 3D reconstruction from UWB distances with only sparse sensors is under-determined; small ranging errors (typical for UWB) can produce large position deviations or multiple feasible configurations. The manuscript provides no quantitative evaluation of reconstruction error or stability under realistic noise, which is load-bearing for the claim that the reconstructed positions supply more informative conditioning and enable the reported 22% error reduction.
- [Abstract (UWB-Diffusion Guidance description)] Abstract (UWB-Diffusion Guidance): if the initial layout reconstruction is already noisy or inconsistent, the guidance term may trade one error source for another without net gain. The paper should include targeted ablations or noise-injection experiments demonstrating that the guidance improves rather than degrades overall pose quality; without this, the central performance claim rests on an unverified assumption.
minor comments (1)
- The abstract supplies no experimental details (sensor count, dataset, baselines, or validation protocol), which makes the 22% improvement claim difficult to contextualize even though the full manuscript presumably contains the results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the Spatial Layout Module and UWB-Diffusion Guidance. We address the two major comments point by point below and will revise the manuscript to incorporate additional evaluations as requested.
read point-by-point responses
-
Referee: [Abstract (Spatial Layout Module description)] Abstract (Spatial Layout Module): the analytical 3D reconstruction from UWB distances with only sparse sensors is under-determined; small ranging errors (typical for UWB) can produce large position deviations or multiple feasible configurations. The manuscript provides no quantitative evaluation of reconstruction error or stability under realistic noise, which is load-bearing for the claim that the reconstructed positions supply more informative conditioning and enable the reported 22% error reduction.
Authors: We agree that the reconstruction from sparse UWB distances is under-determined and sensitive to ranging noise. The Spatial Layout Module formulates the problem as a constrained optimization incorporating known body segment lengths to reduce ambiguities, but the manuscript indeed lacks a dedicated quantitative analysis of reconstruction accuracy. In revision we will add experiments reporting sensor position errors under injected UWB noise levels representative of real hardware (5-20 cm) and compare against ground-truth layouts. revision: yes
-
Referee: [Abstract (UWB-Diffusion Guidance description)] Abstract (UWB-Diffusion Guidance): if the initial layout reconstruction is already noisy or inconsistent, the guidance term may trade one error source for another without net gain. The paper should include targeted ablations or noise-injection experiments demonstrating that the guidance improves rather than degrades overall pose quality; without this, the central performance claim rests on an unverified assumption.
Authors: We acknowledge that the benefit of guidance must be verified when the reconstructed layout contains noise. The guidance term is intended to softly correct distance violations during sampling, yet the current manuscript does not isolate its effect under noisy layouts. We will add targeted ablations in the revision that inject controlled noise into the Spatial Layout Module output and report joint position error with versus without the guidance term. revision: yes
Circularity Check
No circularity: derivation chain is self-contained
full rationale
The paper describes a diffusion model augmented with an analytical Spatial Layout Module that reconstructs 3D sensor positions from UWB distances and a UWB-Diffusion Guidance term to enforce distance consistency during sampling. These components are introduced as independent additions to standard diffusion conditioning, with the claimed 22% error reduction presented as an empirical outcome rather than a quantity forced by definition, fitting, or self-citation. No equations or steps reduce the output to the inputs by construction, and the abstract provides no load-bearing self-citations or renamed known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption UWB ranging measurements permit accurate analytical reconstruction of 3D sensor positions
invented entities (1)
-
UWB-Diffusion Guidance
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Karan Ahuja, Eyal Ofek, Mar Gonzalez-Franco, Christian Holz, and Andrew D. Wilson. Coolmoves: User motion ac- centuation in virtual reality. InProceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, pages 1–23, 2021. 2
2021
-
[2]
Con- ceptual and empirical comparison of dimensionality reduc- tion algorithms (pca, kpca, lda, mds, svd, lle, isomap, le, ica, t-sne).Computer Science Review, 40:100378, 2021
Farzana Anowar, Samira Sadaoui, and Bassant Selim. Con- ceptual and empirical comparison of dimensionality reduc- tion algorithms (pca, kpca, lda, mds, svd, lle, isomap, le, ica, t-sne).Computer Science Review, 40:100378, 2021. 4
2021
-
[3]
Digital dance ethnography: Organizing large dance collec- tions.J
Andreas Aristidou, Ariel Shamir, and Yiorgos Chrysanthou. Digital dance ethnography: Organizing large dance collec- tions.J. Comput. Cult. Herit., 12(4), 2019. 6
2019
-
[4]
Ultra inertial poser: Scalable motion capture and track- ing from sparse inertial sensors and ultra-wideband ranging
Rayan Armani, Changlin Qian, Jiaxi Jiang, and Christian Holz. Ultra inertial poser: Scalable motion capture and track- ing from sparse inertial sensors and ultra-wideband ranging. InACM SIGGRAPH 2024 Conference Papers, pages 1–11,
2024
-
[5]
2, 3, 5, 6, 8, 12, 17
-
[6]
Occlusion-aware networks for 3d human pose estima- tion in video
Yu Cheng, Bo Yang, Bo Wang, Wending Yan, and Robby T Tan. Occlusion-aware networks for 3d human pose estima- tion in video. InProceedings of the IEEE/CVF international conference on computer vision, pages 723–732, 2019. 1
2019
-
[7]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. InAdvances in Neural Infor- mation Processing Systems, pages 8780–8794. Curran Asso- ciates, Inc., 2021. 2, 5
2021
-
[8]
Avatars grow legs: Generating smooth human motion from sparse tracking in- puts with diffusion model
Yuming Du, Robin Kips, Albert Pumarola, Sebastian Starke, Ali Thabet, and Artsiom Sanakoyeu. Avatars grow legs: Generating smooth human motion from sparse tracking in- puts with diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 481–490, 2023. 3
2023
-
[9]
A comprehensive survey on human pose estimation approaches.Multimedia Systems, 29(1):167–195, 2023
Shradha Dubey and Manish Dixit. A comprehensive survey on human pose estimation approaches.Multimedia Systems, 29(1):167–195, 2023. 1
2023
-
[10]
Human poseitioning system (hps): 3d human pose estimation and self-localization in large scenes from body-mounted sensors
Vladimir Guzov, Aymen Mir, Torsten Sattler, and Gerard Pons-Moll. Human poseitioning system (hps): 3d human pose estimation and self-localization in large scenes from body-mounted sensors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4318–4329, 2021. 2
2021
-
[11]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 3, 5
2020
-
[12]
Long short-term memory.Neural Comput., 9(8):1735–1780, 1997
Sepp Hochreiter and J ¨urgen Schmidhuber. Long short-term memory.Neural Comput., 9(8):1735–1780, 1997. 5
1997
-
[13]
Dominik Hollidt, Paul Streli, Jiaxi Jiang, Yasaman Haghighi, Changlin Qian, Xintong Liu, and Christian Holz. Egosim: An egocentric multi-view simulator and real dataset for body-worn cameras during motion and activity.Advances in Neural Information Processing Systems, 37:106607– 106627, 2025. 1, 2
2025
-
[14]
Diffpose: Multi- hypothesis human pose estimation using diffusion models
Karl Holmquist and Bastian Wandt. Diffpose: Multi- hypothesis human pose estimation using diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 15977–15987, 2023. 3
2023
-
[15]
Deep iner- tial poser: Learning to reconstruct human pose from sparse inertial measurements in real time.ACM Transactions on Graphics (TOG), 37(6):1–15, 2018
Yinghao Huang, Manuel Kaufmann, Emre Aksan, Michael J Black, Otmar Hilliges, and Gerard Pons-Moll. Deep iner- tial poser: Learning to reconstruct human pose from sparse inertial measurements in real time.ACM Transactions on Graphics (TOG), 37(6):1–15, 2018. 2, 3, 6
2018
-
[16]
Human motion capture from loose and sparse in- ertial sensors with garment-aware diffusion models
Andela Ilic, Jiaxi Jiang, Paul Streli, Xintong Liu, and Chris- tian Holz. Human motion capture from loose and sparse in- ertial sensors with garment-aware diffusion models. InPro- ceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-25, pages 1206–1214. Inter- national Joint Conferences on Artificial Intelligence ...
2025
-
[17]
Motiongpt: Human motion as a foreign lan- guage.Advances in Neural Information Processing Systems, 36:20067–20079, 2023
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign lan- guage.Advances in Neural Information Processing Systems, 36:20067–20079, 2023. 3
2023
-
[18]
Avatarposer: Ar- ticulated full-body pose tracking from sparse motion sens- ing
Jiaxi Jiang, Paul Streli, Huajian Qiu, Andreas Fender, Larissa Laich, Patrick Snape, and Christian Holz. Avatarposer: Ar- ticulated full-body pose tracking from sparse motion sens- ing. InComputer Vision–ECCV 2022: 17th European Con- ference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part V, pages 443–460, 2022. 17
2022
-
[19]
Egoposer: Robust real-time egocentric pose estimation from sparse and intermittent observations everywhere
Jiaxi Jiang, Paul Streli, Manuel Meier, and Christian Holz. Egoposer: Robust real-time egocentric pose estimation from sparse and intermittent observations everywhere. InEu- ropean Conference on Computer Vision, pages 277–294. Springer, 2024. 2
2024
-
[20]
Transformer inertial poser: Real-time human motion reconstruction from sparse imus with simultaneous terrain generation
Yifeng Jiang, Yuting Ye, Deepak Gopinath, Jungdam Won, Alexander W Winkler, and C Karen Liu. Transformer inertial poser: Real-time human motion reconstruction from sparse imus with simultaneous terrain generation. InSIGGRAPH Asia 2022 Conference Papers, pages 1–9, 2022. 2, 3, 6, 12, 17
2022
-
[21]
Umotion: Uncertainty-driven human motion es- timation from inertial and ultra-wideband units
Huakun Liu, Hiroki Ota, Xin Wei, Yutaro Hirao, Mon- ica Perusquia-Hernandez, Hideaki Uchiyama, and Kiyoshi Kiyokawa. Umotion: Uncertainty-driven human motion es- timation from inertial and ultra-wideband units. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 7085–7094, 2025. 2, 3, 6, 8, 15
2025
-
[22]
Smpl: a skinned multi- person linear model.ACM Transactions on Graphics (TOG), 34(6):1–16, 2015
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: a skinned multi- person linear model.ACM Transactions on Graphics (TOG), 34(6):1–16, 2015. 3
2015
-
[23]
PoseGPT: Quantization-based 3D Human Motion Generation and Forecasting, 2022
Thomas Lucas, Fabien Baradel, Philippe Weinzaepfel, and Gr ´egory Rogez. PoseGPT: Quantization-based 3D Human Motion Generation and Forecasting, 2022. arXiv:2210.10542 [cs]. 3
-
[24]
Troje, Ger- ard Pons-Moll, and Michael J
Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Ger- ard Pons-Moll, and Michael J. Black. Amass: Archive of motion capture as surface shapes. InProceedings of the International Conference on Computer Vision, pages 5442– 5451, 2019. 2, 5
2019
-
[25]
Review of the development of multidimensional scaling methods.Journal of the Royal Statistical Society: Series D (The Statistician), 41(1):27–39, 1992
Al Mead. Review of the development of multidimensional scaling methods.Journal of the Royal Statistical Society: Series D (The Statistician), 41(1):27–39, 1992. 4
1992
-
[26]
Mds-based multiresolution nonlinear di- mensionality reduction model for color image segmenta- tion.IEEE transactions on neural networks, 22(3):447–460,
Max Mignotte. Mds-based multiresolution nonlinear di- mensionality reduction model for color image segmenta- tion.IEEE transactions on neural networks, 22(3):447–460,
-
[27]
Imuposer: Full-body pose estimation using imus in phones, watches, and earbuds
Vimal Mollyn, Riku Arakawa, Mayank Goel, Chris Harri- son, and Karan Ahuja. Imuposer: Full-body pose estimation using imus in phones, watches, and earbuds. InProceedings of the 2023 CHI Conference on Human Factors in Comput- ing Systems, page Article 529, Hamburg, Germany, 2023. Association for Computing Machinery. 2
2023
-
[28]
Noitom motion capture.https : / / www
Noitom. Noitom motion capture.https : / / www . noitom.com/, 2024. 2
2024
-
[29]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InInternational Conference on Learning Representations, 2021. 3, 13
2021
-
[30]
Hoov: Hand out-of-view tracking for proprioceptive interaction using inertial sensing
Paul Streli, Rayan Armani, Yi Fei Cheng, and Christian Holz. Hoov: Hand out-of-view tracking for proprioceptive interaction using inertial sensing. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pages 1–16, 2023. 2
2023
-
[31]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. Human motion dif- fusion model.arXiv preprint arXiv:2209.14916, 2022. 2, 3, 5, 17
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
xR-EgoPose: Egocentric 3D Human Pose from an HMD Camera
Denis Tome, Patrick Peluse, Lourdes Agapito, and Hernan Badino. xR-EgoPose: Egocentric 3D Human Pose from an HMD Camera, 2019. arXiv:1907.10045 [cs]. 1
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[33]
Total capture: 3d hu- man pose estimation fusing video and inertial sensors
Matthew Trumble, Andrew Gilbert, Charles Malleson, Adrian Hilton, and John Collo-mosse. Total capture: 3d hu- man pose estimation fusing video and inertial sensors. In Proceedings of the 28th British Machine Vision Conference, pages 1–13, 2017. 2, 6
2017
-
[34]
Diffusionposer: Real-time human motion reconstruction from arbitrary sparse sensors using autoregressive diffusion
Tom Van Wouwe, Seunghwan Lee, Antoine Falisse, Scott Delp, and C Karen Liu. Diffusionposer: Real-time human motion reconstruction from arbitrary sparse sensors using autoregressive diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2513–2523, 2024. 2, 3, 5, 16, 17
2024
-
[35]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 17
2017
-
[36]
Sparse inertial poser: Automatic 3d hu- man pose estimation from sparse imus
Timo V on Marcard, Bodo Rosenhahn, Michael J Black, and Gerard Pons-Moll. Sparse inertial poser: Automatic 3d hu- man pose estimation from sparse imus. InComputer graph- ics forum, pages 349–360. Wiley Online Library, 2017. 2
2017
-
[37]
Scene-Aware Ego- centric 3D Human Pose Estimation
Jian Wang, Diogo Luvizon, Weipeng Xu, Lingjie Liu, Kri- pasindhu Sarkar, and Christian Theobalt. Scene-Aware Ego- centric 3D Human Pose Estimation. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13031–13040, Vancouver, BC, Canada,
-
[38]
Richard Wilkinson
Prof. Richard Wilkinson. 6.1 Classical MDS — Multi- variate Statistics — rich-d-wilkinson.github.io.https: //rich-d-wilkinson.github.io/MATH3030/6. 1-classical-mds.html. 4
-
[39]
Ac- curate and steady inertial pose estimation through sequence structure learning and modulation.Advances in Neural In- formation Processing Systems, 37:42468–42493, 2024
Yinghao Wu, Lu Yin, Shihui Guo, Yipeng Qin, et al. Ac- curate and steady inertial pose estimation through sequence structure learning and modulation.Advances in Neural In- formation Processing Systems, 37:42468–42493, 2024. 2
2024
-
[40]
Moda: Motion- drift augmentation for inertial human motion analysis
Yinghao Wu, Shihui Guo, and Yipeng Qin. Moda: Motion- drift augmentation for inertial human motion analysis. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 27771–27781, 2025. 2
2025
-
[41]
Xsens motion capture.https://www.xsens
Xsens. Xsens motion capture.https://www.xsens. com, 2024. 2, 12
2024
-
[42]
Mo2Cap2: Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera
Weipeng Xu, Avishek Chatterjee, Michael Zollhoefer, Helge Rhodin, Pascal Fua, Hans-Peter Seidel, and Chris- tian Theobalt. Mo2Cap2: Real-time Mobile 3D Mo- tion Capture with a Cap-mounted Fisheye Camera, 2019. arXiv:1803.05959 [cs]. 1
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[43]
Group inertial poser: Multi- person pose and global translation from sparse inertial sen- sors and ultra-wideband ranging
Ying Xue, Jiaxi Jiang, Rayan Armani, Dominik Hollidt, Yi- Chi Liao, and Christian Holz. Group inertial poser: Multi- person pose and global translation from sparse inertial sen- sors and ultra-wideband ranging. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24910–24921, 2025. 2, 3, 6, 8, 12
2025
-
[44]
Tof-ip: time-of-flight enhanced sparse inertial poser for real-time human motion capture
Yuan Yao, Shifan Jiang, Yangqing Hou, Chengxu Zuo, Xin- rui Chen, Shihui Guo, and Yipeng Qin. Tof-ip: time-of-flight enhanced sparse inertial poser for real-time human motion capture. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 3
2025
-
[45]
Estimating body and hand motion in an ego-sensed world
Brent Yi, Vickie Ye, Maya Zheng, Lea M ¨uller, Georgios Pavlakos, Yi Ma, Jitendra Malik, and Angjoo Kanazawa. Estimating body and hand motion in an ego-sensed world. arXiv preprint arXiv:2410.03665, 2024. 3
-
[46]
Phys- ical inertial poser (pip): Physics-aware real-time human mo- tion tracking from sparse inertial sensors
Xinyu Yi, Yuxiao Zhou, Marc Habermann, Soshi Shimada, Vladislav Golyanik, Christian Theobalt, and Feng Xu. Phys- ical inertial poser (pip): Physics-aware real-time human mo- tion tracking from sparse inertial sensors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13167–13178, 2022. 2, 3, 5, 6, 8, 12, 17
2022
-
[47]
Physical non-inertial poser (pnp): modeling non-inertial effects in sparse-inertial human motion capture
Xinyu Yi, Yuxiao Zhou, and Feng Xu. Physical non-inertial poser (pnp): modeling non-inertial effects in sparse-inertial human motion capture. InACM SIGGRAPH 2024 Confer- ence Papers, pages 1–11, 2024. 2, 5, 6, 12, 17
2024
-
[48]
Improving global motion estimation in sparse imu-based motion capture with physics.ACM Transactions on Graphics (TOG), 44(4):1–16,
Xinyu Yi, Shaohua Pan, and Feng Xu. Improving global motion estimation in sparse imu-based motion capture with physics.ACM Transactions on Graphics (TOG), 44(4):1–16,
-
[49]
Rohm: Robust human motion reconstruction via diffusion
Siwei Zhang, Bharat Lal Bhatnagar, Yuanlu Xu, Alexan- der Winkler, Petr Kadlecek, Siyu Tang, and Federica Bogo. Rohm: Robust human motion reconstruction via diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14606–14617, 2024. 1, 3, 5
2024
-
[50]
Dynamic inertial poser (dynaip): Part- based motion dynamics learning for enhanced human pose estimation with sparse inertial sensors
Yu Zhang, Songpengcheng Xia, Lei Chu, Jiarui Yang, Qi Wu, and Ling Pei. Dynamic inertial poser (dynaip): Part- based motion dynamics learning for enhanced human pose estimation with sparse inertial sensors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1889–1899, 2024. 6, 16
2024
-
[51]
Deep learning-based human pose estimation: A survey.ACM Computing Surveys, 56(1):1–37, 2023
Ce Zheng, Wenhan Wu, Chen Chen, Taojiannan Yang, Si- jie Zhu, Ju Shen, Nasser Kehtarnavaz, and Mubarak Shah. Deep learning-based human pose estimation: A survey.ACM Computing Surveys, 56(1):1–37, 2023. 1
2023
-
[52]
Xiaozheng Zheng, Zhuo Su, Chao Wen, Zhou Xue, and Xiaojie Jin. Realistic full-body tracking from sparse observations via joint-level modeling.arXiv preprint arXiv:2308.08855, 2023. 2
-
[53]
On the Continuity of Rotation Representations in Neu- ral Networks
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the Continuity of Rotation Representations in Neu- ral Networks. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5738–5746. IEEE, 2019. 4
2019
-
[54]
Loose inertial poser: Motion capture with imu-attached loose-wear jacket
Chengxu Zuo, Yiming Wang, Lishuang Zhan, Shihui Guo, Xinyu Yi, Feng Xu, and Yipeng Qin. Loose inertial poser: Motion capture with imu-attached loose-wear jacket. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2209–2219, 2024. 2
2024
-
[55]
Transformer imu calibrator: Dynamic on-body imu calibration for inertial motion capture.ACM Transac- tions on Graphics (TOG), 44(4):1–14, 2025
Chengxu Zuo, Jiawei Huang, Xiao Jiang, Yuan Yao, Xian- gren Shi, Rui Cao, Xinyu Yi, Feng Xu, Shihui Guo, and Yipeng Qin. Transformer imu calibrator: Dynamic on-body imu calibration for inertial motion capture.ACM Transac- tions on Graphics (TOG), 44(4):1–14, 2025. 2 A. Supplementary A.1. Training and Evaluation Details In the following section, we provide...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.