Towards Diverse Scientific Hypothesis Search with Large Language Models
Pith reviewed 2026-06-27 14:07 UTC · model grok-4.3
The pith
A multi-temperature evolutionary framework generates more diverse and higher-quality scientific hypotheses than standard search methods under fixed budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
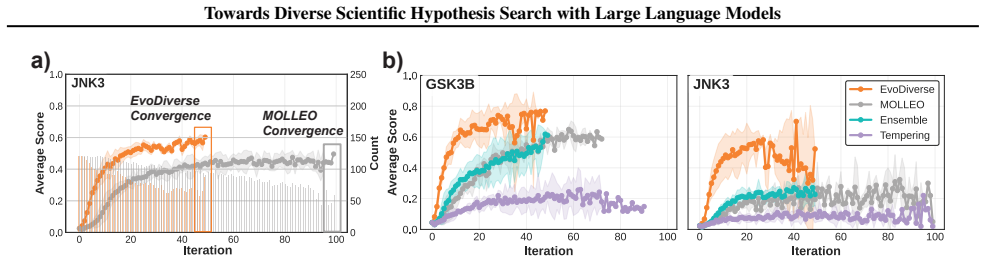
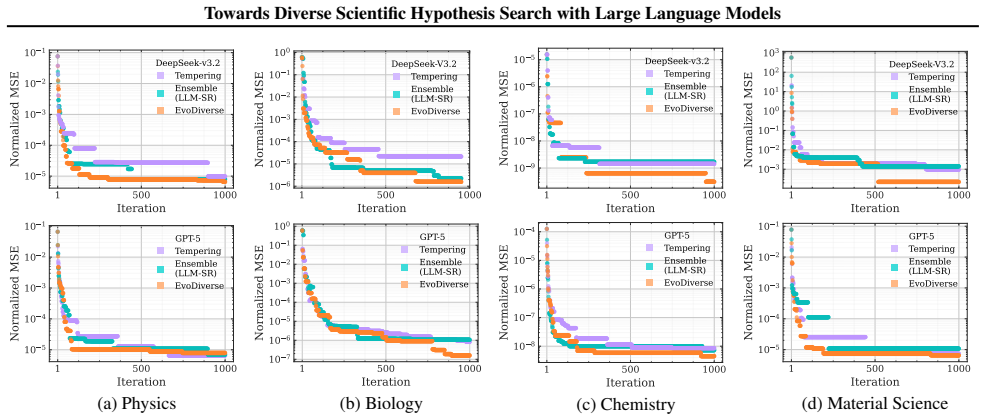
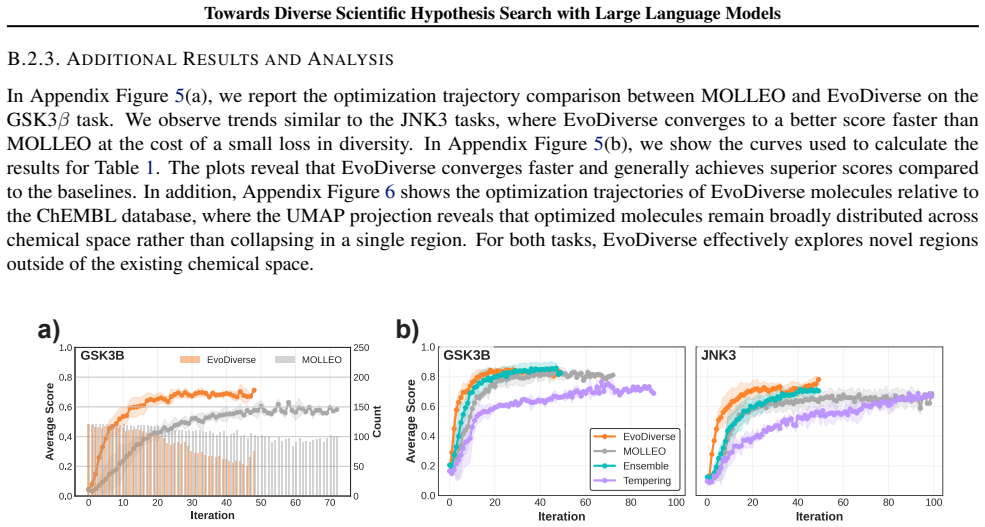
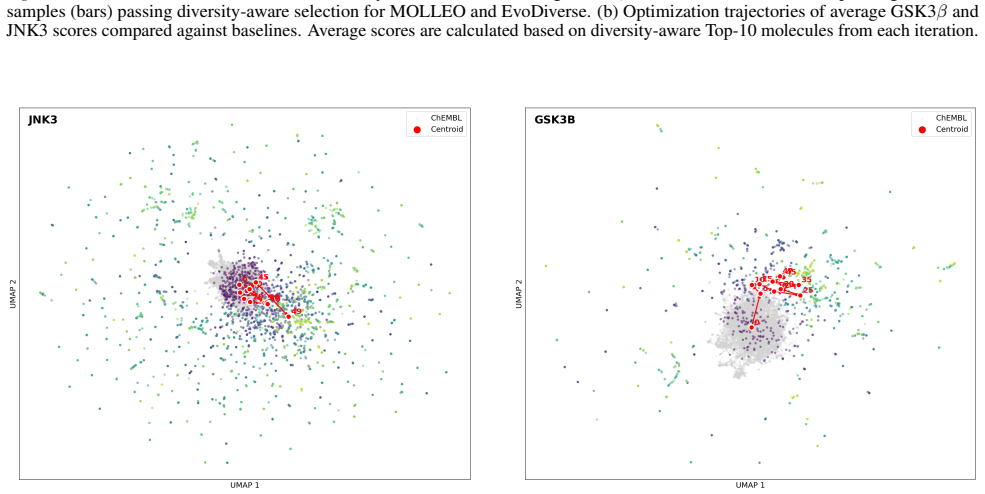
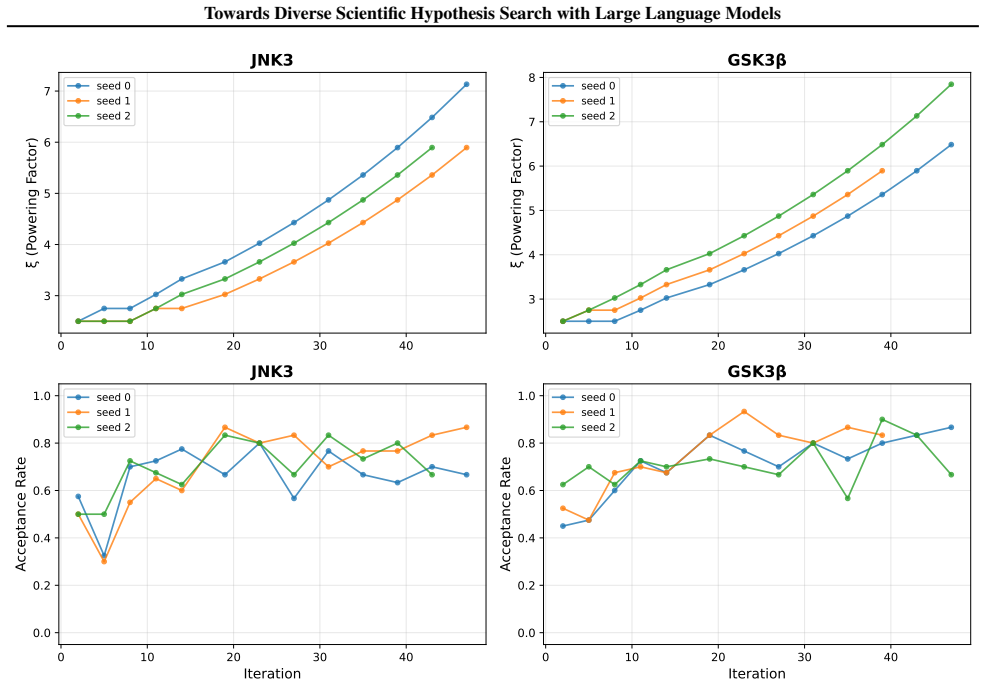
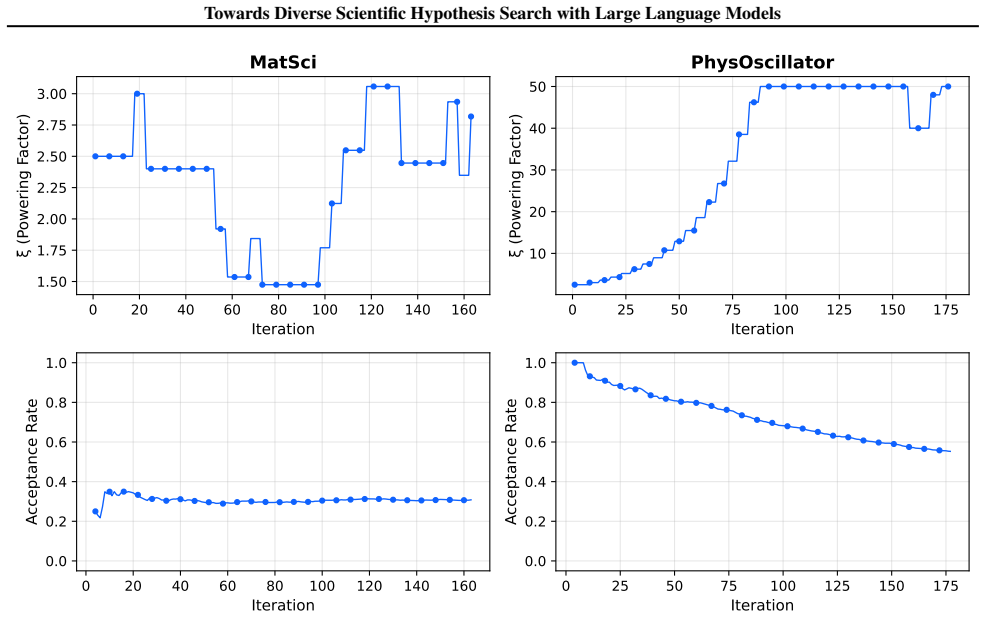
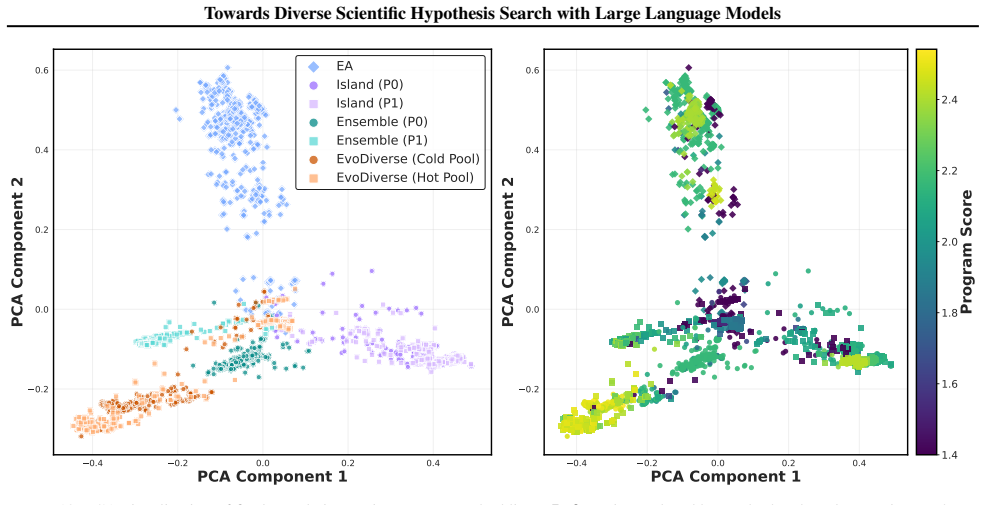
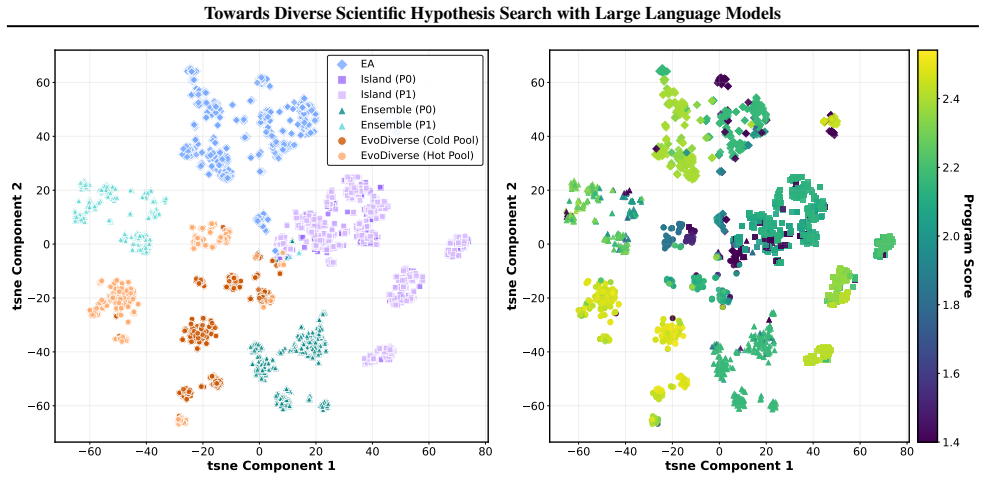
By treating hypothesis search as a sampling task instead of pure optimization, the evolutionary framework performs searches at multiple temperature levels and enables information exchange between them. This produces sets of hypotheses that are simultaneously higher in quality and greater in diversity than those obtained from conventional single-temperature evolutionary search, and the improvement holds across molecular, equation, and algorithm discovery domains under an identical validation budget.
What carries the argument
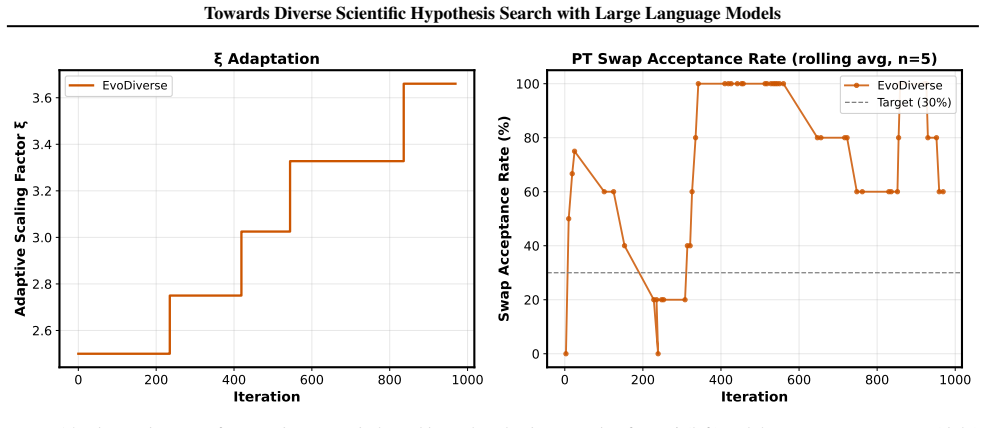
The evolutionary framework that searches hypotheses at multiple temperature levels and performs principled information exchange across temperatures, modeled on parallel tempering.
If this is right
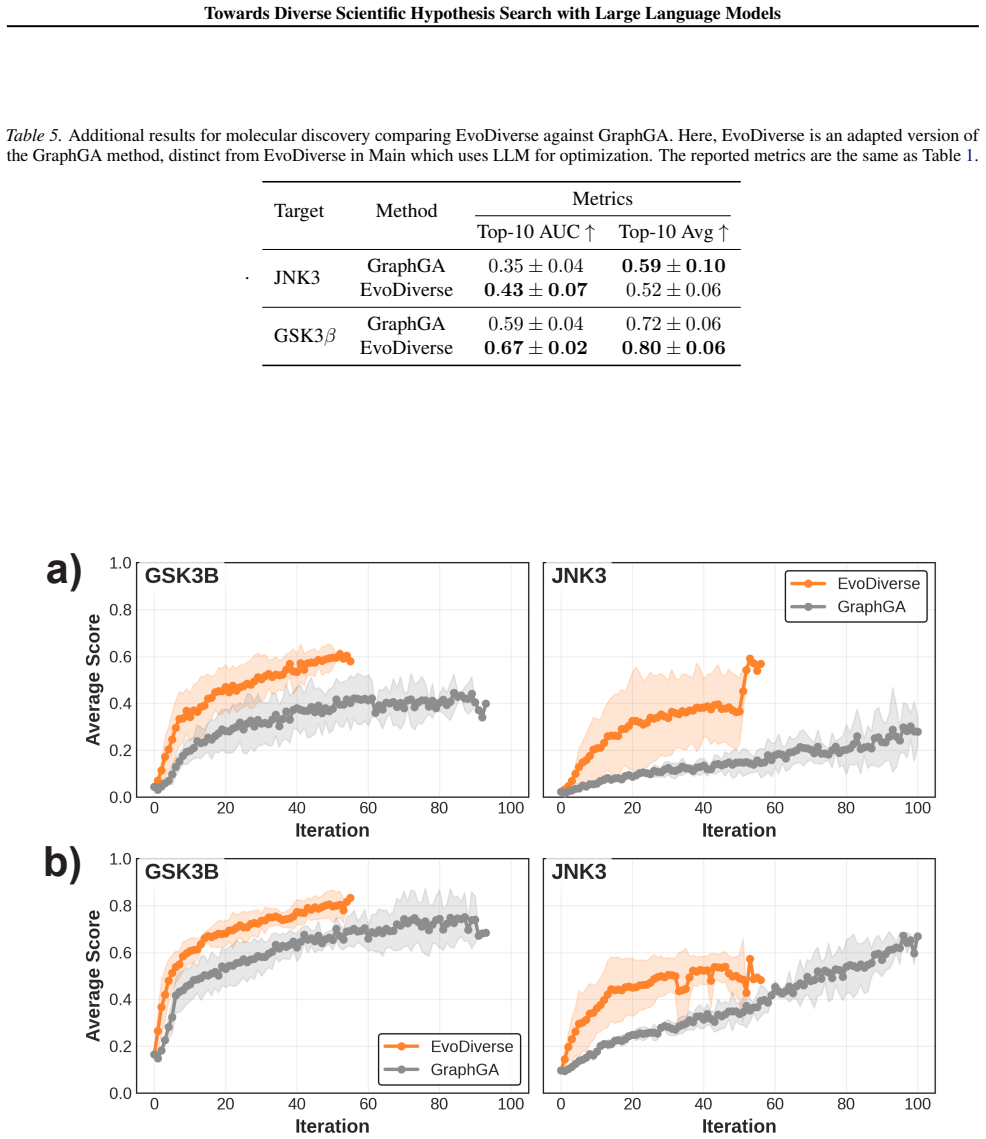
- Higher-quality and more diverse hypothesis sets are obtained in molecular discovery under the same validation budget.
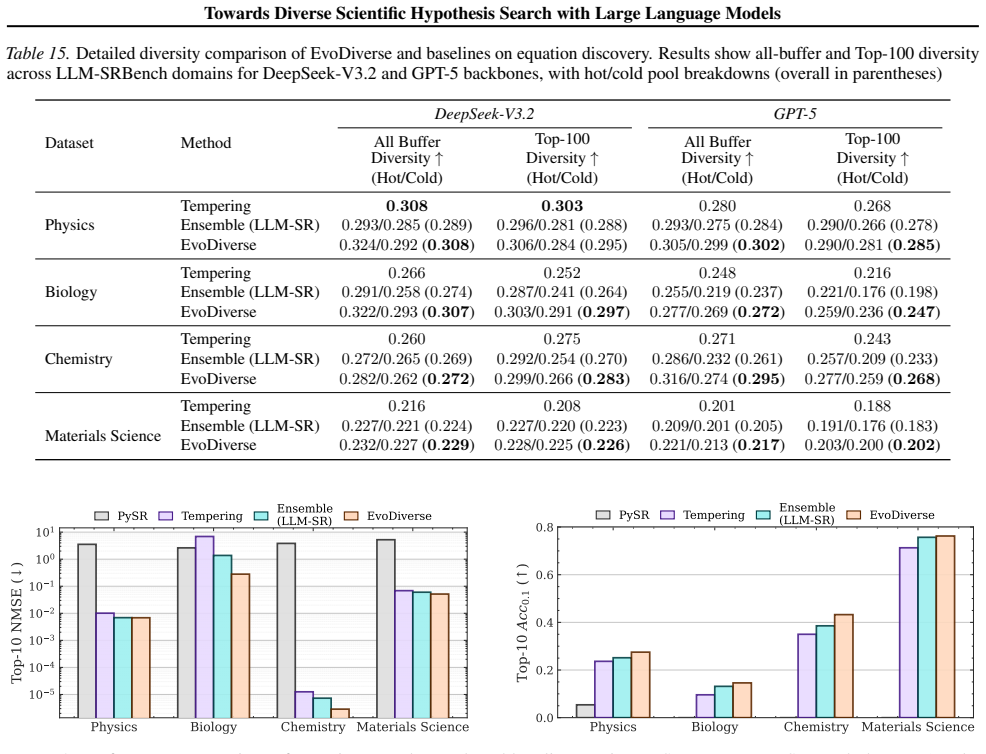
- The same gains appear in equation discovery and algorithm discovery tasks.
- Generated candidates remain effective when later subjected to more expensive computational validation procedures.
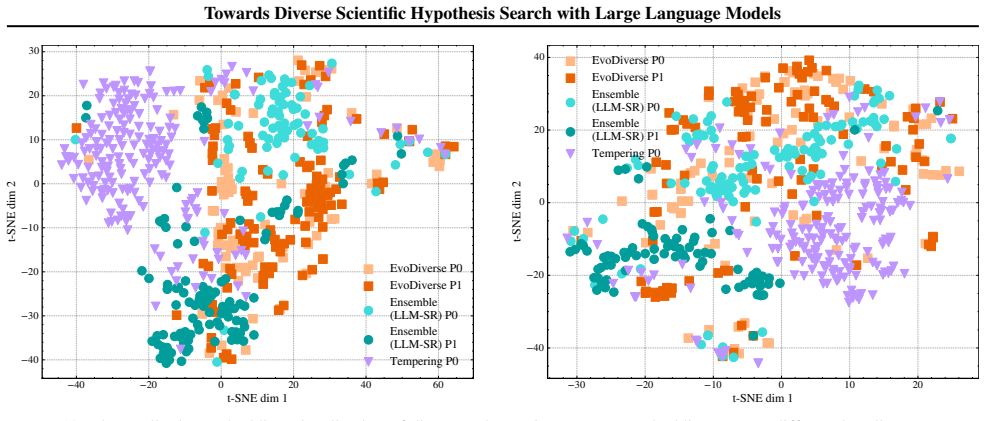
- Diversity does not come at the expense of quality when the multi-temperature exchange is used.
Where Pith is reading between the lines
- The temperature-exchange mechanism may transfer to other LLM-driven creative search tasks where mode collapse is a known issue.
- One could test whether the number of temperature levels or the exchange frequency can be tuned per domain to further increase gains.
- The sampling perspective suggests that similar multi-level strategies could be applied to non-evolutionary LLM generation pipelines.
- If the robustness under downstream validation generalizes, the method could reduce wasted effort on hypotheses that fail expensive checks.
Load-bearing premise
That running hypothesis search at multiple temperature levels with information exchange improves exploration without harming convergence.
What would settle it
A controlled comparison in one of the tested domains where the multi-temperature method yields either lower average hypothesis quality or lower diversity than single-temperature evolutionary search when both are given the same number of validation evaluations.
Figures


read the original abstract
Large language models (LLMs) are on the rise for accelerating scientific discovery, most recently in advanced tasks such as generating valid scientific hypotheses. Yet in many discovery settings, the goal is not to identify a single best hypothesis since validation can be noisy and expensive, and scientists benefit from a set of high-quality alternative hypotheses that hedge against downstream uncertainty for the best solutions. Nevertheless, commonly used evolutionary search recipes tend to prioritize optimization over exploration in hypothesis generation, and the resulting selection pressure during the search process leads to diversity collapse. Motivated by these limitations, we formulate hypothesis search as a sampling problem, where the objective is to efficiently produce diverse, high-quality hypotheses under a fixed validation budget. Building on this perspective, we propose \ours, an evolutionary framework inspired by the classical parallel tempering algorithm that searches hypotheses at multiple temperature levels and enables principled information exchange across temperatures to improve exploration without disrupting convergence. Across domains including molecular discovery, equation discovery, and algorithm discovery, our approach consistently improves both hypothesis quality and diversity under the same validation budget, and produces candidates that remain robust under more expensive downstream computational validations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates hypothesis search with LLMs as a sampling problem rather than pure optimization, and introduces ours, a parallel-tempering-inspired evolutionary framework that runs searches at multiple temperature levels with cross-temperature information exchange. It claims that this produces higher-quality and more diverse hypotheses than standard evolutionary recipes under a fixed validation budget, with results shown across molecular discovery, equation discovery, and algorithm discovery; the generated candidates are also reported to remain robust under more expensive downstream validations.
Significance. If the empirical improvements and robustness claims hold after detailed verification of the sampling procedure and controls, the work would offer a concrete, reusable technique for mitigating premature diversity collapse in LLM-driven scientific search, directly addressing a practical bottleneck in hypothesis generation pipelines.
major comments (1)
- [Abstract] Abstract (paragraph on the proposed framework): the central claim that multi-temperature search with principled information exchange improves exploration without disrupting convergence is presented as load-bearing for the method, yet the manuscript provides no derivation, pseudocode, or ablation isolating the exchange operator, temperature schedule, or acceptance rule, leaving the assumption unverified and preventing assessment of whether the reported gains are attributable to the framework.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract and the need to verify the framework components. We address this directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on the proposed framework): the central claim that multi-temperature search with principled information exchange improves exploration without disrupting convergence is presented as load-bearing for the method, yet the manuscript provides no derivation, pseudocode, or ablation isolating the exchange operator, temperature schedule, or acceptance rule, leaving the assumption unverified and preventing assessment of whether the reported gains are attributable to the framework.
Authors: We agree that the abstract presents the central claim at a high level and that the manuscript as described does not include a derivation, pseudocode, or isolating ablations for the exchange operator, temperature schedule, or acceptance rule. This leaves the attribution of gains unverified in the current version. We will revise the manuscript to add (1) a short derivation section explaining the parallel-tempering motivation and how the exchange and acceptance rules preserve convergence properties, (2) explicit pseudocode for the full procedure, and (3) targeted ablations that isolate each component while holding the validation budget fixed. These will appear in the methods and experimental sections, and the abstract will be updated to reference the new supporting material. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper formulates hypothesis search as a sampling problem and introduces a new evolutionary framework ( exttt{\\ours}) inspired by parallel tempering with multi-temperature search and cross-temperature exchange. No equations, fitted parameters, or self-citations are shown in the abstract or context that reduce the central claims (improved quality and diversity under fixed budget) to inputs by construction. The method is presented as an independent algorithmic proposal whose performance is evaluated empirically across domains, rendering the derivation chain self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Reasoning with Sampling: Your Base Model is Smarter Than You Think , author=. 2025 , eprint=
2025
-
[2]
Proceedings of the National Academy of Sciences , volume=
Sampling can be faster than optimization , author=. Proceedings of the National Academy of Sciences , volume=. 2019 , publisher=
2019
-
[3]
Conference on Learning Theory , pages=
Non-convex learning via stochastic gradient langevin dynamics: a nonasymptotic analysis , author=. Conference on Learning Theory , pages=. 2017 , organization=
2017
-
[4]
arXiv preprint arXiv:2512.15567 , year=
Evaluating Large Language Models in Scientific Discovery , author=. arXiv preprint arXiv:2512.15567 , year=
-
[5]
Optimization: Methods and Applications, Possibilities and Limitations: Proceedings of an International Seminar Organized by Deutsche Forschungsanstalt f
Evolution strategy: Nature’s way of optimization , author=. Optimization: Methods and Applications, Possibilities and Limitations: Proceedings of an International Seminar Organized by Deutsche Forschungsanstalt f. 1989 , organization=
1989
-
[6]
1992 , publisher=
Adaptation in natural and artificial systems: an introductory analysis with applications to biology, control, and artificial intelligence , author=. 1992 , publisher=
1992
-
[7]
Physical Chemistry Chemical Physics , volume=
Parallel tempering: Theory, applications, and new perspectives , author=. Physical Chemistry Chemical Physics , volume=. 2005 , publisher=
2005
-
[8]
The Annals of Probability , pages=
Laplace's method revisited: weak convergence of probability measures , author=. The Annals of Probability , pages=. 1980 , publisher=
1980
-
[9]
Recursive stochastic algorithms for global optimization in R\^
Gelfand, Saul B and Mitter, Sanjoy K , journal=. Recursive stochastic algorithms for global optimization in R\^. 1991 , publisher=
1991
-
[10]
AI for Accelerated Materials Design-ICLR 2025 , year=
Large language models are innate crystal structure generators , author=. AI for Accelerated Materials Design-ICLR 2025 , year=
2025
-
[11]
Journal of the American Chemical Society , year=
Generative Design of Functional Metal Complexes Utilizing the Internal Knowledge and Reasoning Capability of Large Language Models , author=. Journal of the American Chemical Society , year=
-
[12]
Forty-second International Conference on Machine Learning , year=
LLM-Augmented Chemical Synthesis and Design Decision Programs , author=. Forty-second International Conference on Machine Learning , year=
-
[13]
arXiv preprint arXiv:2509.20988 , year=
AOT*: Efficient Synthesis Planning via LLM-Empowered AND-OR Tree Search , author=. arXiv preprint arXiv:2509.20988 , year=
-
[14]
ACS Central Science , volume=
SynLlama: generating synthesizable molecules and their analogs with large language models , author=. ACS Central Science , volume=. 2025 , publisher=
2025
-
[15]
arXiv preprint arXiv:2102.09548 , year=
Therapeutics data commons: Machine learning datasets and tasks for drug discovery and development , author=. arXiv preprint arXiv:2102.09548 , year=
-
[16]
Nature Computational Science , ISSN =
Smileyllama: Modifying large language models for directed chemical space exploration , author=. Nature Computational Science , ISSN =. 2026 , type =. doi:10.1038/s43588-026-00986-y , url =
-
[17]
Journal of Experimental & Theoretical Artificial Intelligence , volume=
Genitor II: A distributed genetic algorithm , author=. Journal of Experimental & Theoretical Artificial Intelligence , volume=. 1990 , publisher=
1990
-
[18]
Foundations of genetic algorithms , volume=
Evolution in time and space--the parallel genetic algorithm , author=. Foundations of genetic algorithms , volume=. 1991 , publisher=
1991
-
[19]
Markov chain
Geyer, Charles J , year=. Markov chain
-
[20]
Exchange
Hukushima, Koji and Nemoto, Koji , journal=. Exchange. 1996 , publisher=
1996
-
[21]
and Wang, Jian-Sheng , journal =
Swendsen, Robert H. and Wang, Jian-Sheng , journal =. Replica
-
[22]
arXiv preprint arXiv:2509.23265 , year=
CREPE: Controlling Diffusion with Replica Exchange , author=. arXiv preprint arXiv:2509.23265 , year=
-
[23]
Frontiers in Robotics and AI , volume=
Quality diversity: A new frontier for evolutionary computation , author=. Frontiers in Robotics and AI , volume=. 2016 , publisher=
2016
-
[24]
Forty-first International Conference on Machine Learning , year=
Evolution of Heuristics: Towards Efficient Automatic Algorithm Design Using Large Language Model , author=. Forty-first International Conference on Machine Learning , year=
-
[25]
Nguyen and Nakul Rampal and Ali H
Zhiling Zheng and Oufan Zhang and Ha L. Nguyen and Nakul Rampal and Ali H. Alawadhi and Zichao Rong and Teresa Head-Gordon and Christian Borgs and Jennifer T. Chayes and Omar M. Yaghi , doi =. ChatGPT Research Group for Optimizing the Crystallinity of MOFs and COFs , volume =. ACS Cent. Sci. , month =
-
[26]
arXiv preprint arXiv:2512.21782 , year=
Accelerating Scientific Discovery with Autonomous Goal-evolving Agents , author=. arXiv preprint arXiv:2512.21782 , year=
-
[27]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Non-reversible parallel tempering: a scalable highly parallel MCMC scheme , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2022 , publisher=
2022
-
[28]
Brown, S. and Head-Gordon, T. , title =. J Comput Chem , volume =. doi:10.1002/jcc.10181 , year =
-
[29]
Drug Discovery Today: Technologies , volume=
On failure modes in molecule generation and optimization , author=. Drug Discovery Today: Technologies , volume=. 2019 , publisher=
2019
-
[30]
Science , number=
The method of multiple working hypotheses , author=. Science , number=. 1890 , publisher=
-
[31]
Proceedings of the 13th annual conference on Genetic and evolutionary computation , pages=
Evolving a diversity of virtual creatures through novelty search and local competition , author=. Proceedings of the 13th annual conference on Genetic and evolutionary computation , pages=
-
[32]
1970 , publisher=
The structure of scientific revolutions , author=. 1970 , publisher=
1970
-
[33]
The Structure of Scientific Revolutions , author=
-
[34]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[35]
Forty-first International Conference on Machine Learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first International Conference on Machine Learning , year=
-
[36]
arXiv preprint arXiv:2508.15260 , year=
Deep think with confidence , author=. arXiv preprint arXiv:2508.15260 , year=
-
[37]
International Conference on Machine Learning , pages=
Fast inference from transformers via speculative decoding , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[38]
arXiv preprint arXiv:2203.11171 , year=
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
-
[39]
Advances in Neural Information Processing Systems , volume=
Aligning large language models with representation editing: A control perspective , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
arXiv preprint arXiv:2309.08600 , year=
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
-
[42]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[43]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[44]
arXiv preprint arXiv:2310.17022 , year=
Controlled decoding from language models , author=. arXiv preprint arXiv:2310.17022 , year=
-
[45]
arXiv preprint arXiv:2305.18090 , year=
Chatgpt-powered conversational drug editing using retrieval and domain feedback , author=. arXiv preprint arXiv:2305.18090 , year=
-
[46]
Nature , volume=
Optimizing generative AI by backpropagating language model feedback , author=. Nature , volume=. 2025 , publisher=
2025
-
[47]
arXiv preprint arXiv:2501.09274 , year=
Large Language Model is Secretly a Protein Sequence Optimizer , author=. arXiv preprint arXiv:2501.09274 , year=
-
[48]
NeurIPS 2024 Workshop on AI for New Drug Modalities , year=
LLMs are highly-constrained biophysical sequence optimizers , author=. NeurIPS 2024 Workshop on AI for New Drug Modalities , year=
2024
-
[49]
Nature , volume=
Mathematical discoveries from program search with large language models , author=. Nature , volume=. 2024 , publisher=
2024
-
[50]
Nature , volume=
Autonomous chemical research with large language models , author=. Nature , volume=. 2023 , publisher=
2023
-
[51]
Nature Machine Intelligence , volume=
Augmenting large language models with chemistry tools , author=. Nature Machine Intelligence , volume=. 2024 , publisher=
2024
-
[52]
arXiv preprint arXiv:2511.02824 , year=
Kosmos: An ai scientist for autonomous discovery , author=. arXiv preprint arXiv:2511.02824 , year=
-
[53]
The Thirteenth International Conference on Learning Representations , year=
LLM-SR: Scientific Equation Discovery via Programming with Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[54]
The Thirteenth International Conference on Learning Representations , year=
Efficient Evolutionary Search Over Chemical Space with Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[55]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[56]
arXiv preprint arXiv:2506.13131 , year=
AlphaEvolve: A coding agent for scientific and algorithmic discovery , author=. arXiv preprint arXiv:2506.13131 , year=
-
[57]
2025 , publisher =
OpenEvolve: an open-source evolutionary coding agent , author =. 2025 , publisher =
2025
-
[58]
arXiv preprint arXiv:2509.19349 , year=
Shinkaevolve: Towards open-ended and sample-efficient program evolution , author=. arXiv preprint arXiv:2509.19349 , year=
-
[59]
arXiv preprint arXiv:2511.08522 , year=
Alpharesearch: Accelerating new algorithm discovery with language models , author=. arXiv preprint arXiv:2511.08522 , year=
-
[60]
Advances in Neural Information Processing Systems , volume=
Symbolic regression with a learned concept library , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
arXiv preprint arXiv:2408.06292 , year=
The ai scientist: Towards fully automated open-ended scientific discovery , author=. arXiv preprint arXiv:2408.06292 , year=
-
[62]
biorxiv , year=
Biomni: A general-purpose biomedical ai agent , author=. biorxiv , year=
-
[63]
arXiv preprint arXiv:2002.08155 , year=
Codebert: A pre-trained model for program-ming and natural languages , author=. arXiv preprint arXiv:2002.08155 , year=
Pith/arXiv arXiv 2002
-
[64]
arXiv preprint arXiv:2504.10415 , year=
Llm-srbench: A new benchmark for scientific equation discovery with large language models , author=. arXiv preprint arXiv:2504.10415 , year=
-
[65]
Journal of chemical information and modeling , volume=
ZINC- a free database of commercially available compounds for virtual screening , author=. Journal of chemical information and modeling , volume=. 2005 , publisher=
2005
-
[66]
Advances in neural information processing systems , volume=
Sample efficiency matters: a benchmark for practical molecular optimization , author=. Advances in neural information processing systems , volume=
-
[67]
2: Pushing the frontier of open large language models , author=
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
-
[68]
Interpretable machine learning for science with PySR and SymbolicRegression. jl , author=. arXiv preprint arXiv:2305.01582 , year=
-
[69]
Mendez, David and Gaulton, Anna and Bento, A. Patr. Nucleic Acids Research , volume =. 2019 , doi =
2019
-
[70]
Chemical science , volume=
A graph-based genetic algorithm and generative model/Monte Carlo tree search for the exploration of chemical space , author=. Chemical science , volume=. 2019 , publisher=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.