Recoverable but Not Stationary:Local Linear Structures in Weights and Activations
Pith reviewed 2026-06-27 13:49 UTC · model grok-4.3
The pith
Linear structures in neural network weights and activations recover task behavior through early updates but drift rapidly instead of forming fixed global directions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
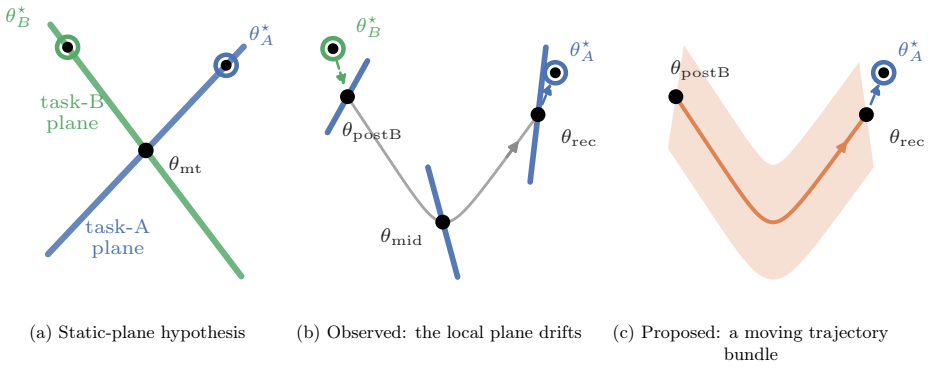
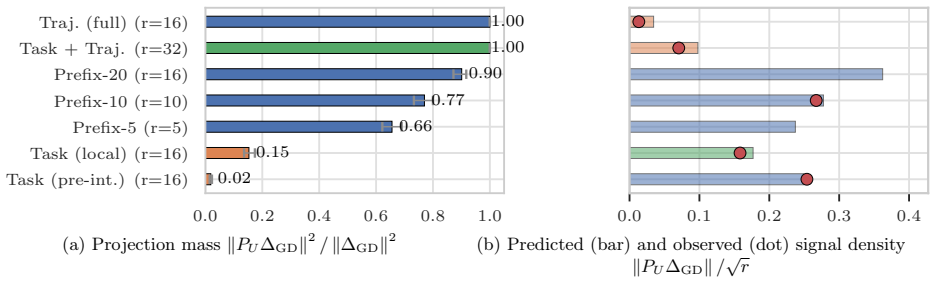
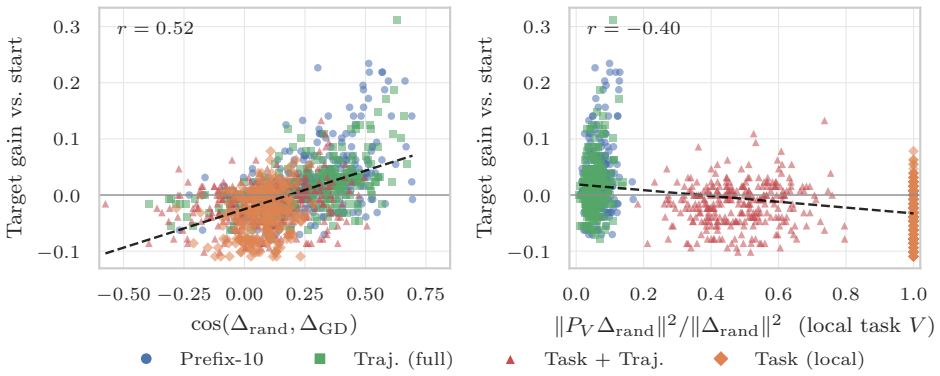
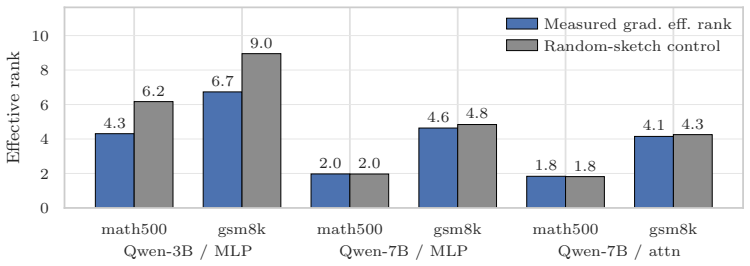
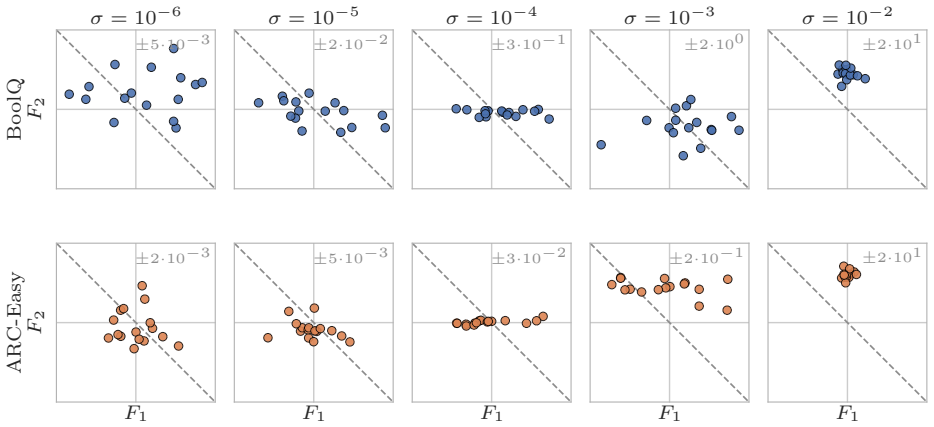
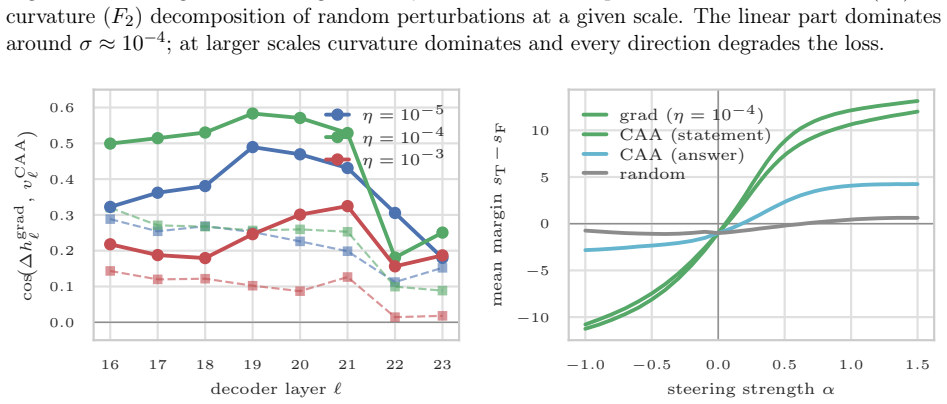
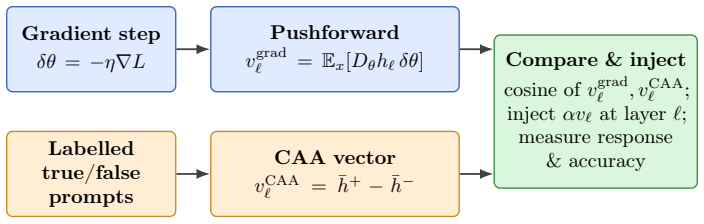
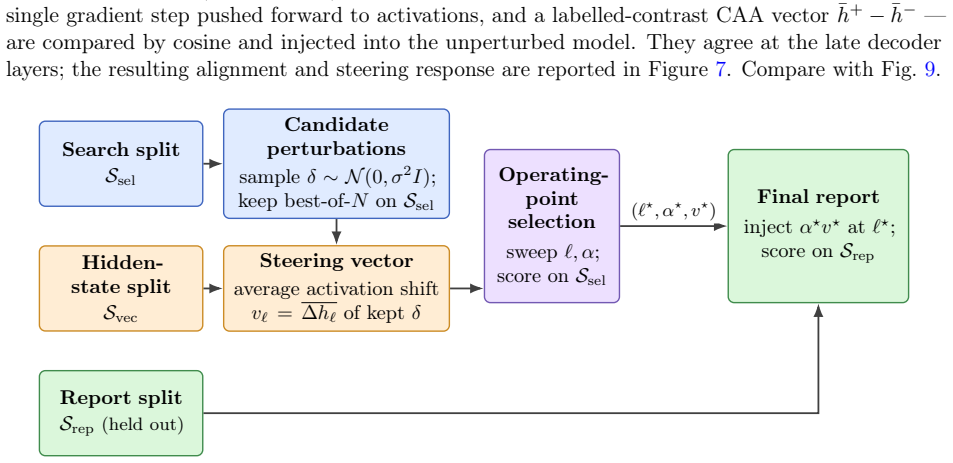
Strong local low-rank task-gradient structure exists in trained networks but the fixed-task-plane hypothesis is rejected because static bases miss the recovery direction and the useful basis drifts substantially within 100 steps; the first recovery updates form a trajectory-prefix basis capturing 77% of the LoRA recovery displacement, while a single gradient step produces an activation shift with 0.58 cosine to a labelled-contrast CAA steering vector with similar steering effect on Qwen-0.5B BoolQ statements.
What carries the argument
The trajectory-prefix basis formed by the first few recovery updates, which spans most of the LoRA recovery displacement in parameter space and aligns with activation steering shifts.
If this is right
- Random parameter search succeeds in high dimensions because a Gaussian local-linear theorem shows local linearity around pretrained weights.
- Gradient steps in weight space produce activation changes that can be used directly for steering with measurable cosine alignment.
- Linear control of behavior operates through evolving local geometries that partially persist across parameter and activation spaces rather than global task directions.
- Recovery trajectories contain recoverable prefix bases that explain most displacement even when later directions change.
Where Pith is reading between the lines
- If the local structures appear in larger models, then small targeted weight updates could steer behavior more precisely than full fine-tuning.
- The observed drift between weight and activation spaces suggests hybrid editing methods that combine early LoRA steps with activation steering.
- Tracking how the trajectory-prefix basis evolves could improve continual learning by updating the active linear directions instead of assuming fixed planes.
Load-bearing premise
The observed local low-rank structures, 77% capture rate, and 0.58 cosine alignment hold across architectures and tasks without substantial variation.
What would settle it
Measuring that the first recovery updates capture below 30% of total LoRA displacement or that single-step activation shifts fall below 0.2 cosine similarity to steering vectors on a new model or task would show the local structures do not persist.
Figures
read the original abstract
Task vectors, LoRA, activation steering, and random search around pretrained weights all suggest that learned behaviour can be controlled by linear directions. We ask which linear structures actually exist and on what scale. In a synthetic multitask transformer and LoRA adapters on DistilGPT-2 / GPT-2 we find strong local low-rank task-gradient structure but reject the fixed-task-plane hypothesis: static bases miss the recovery direction, and the useful basis drifts substantially within 100 steps. However, the first recovery updates form a trajectory-prefix basis capturing 77% of the LoRA recovery displacement. We develop random search theory with a Gaussian local-linear theorem that justifies the effectiveness of random parameter search even in very high dimensions. We also study the relation between parameter perturbations and activation steering: a single gradient step produces an activation shift with 0.58 cosine to a labelled-contrast CAA steering vector, with a similar steering effect on Qwen-0.5B BoolQ statements. We validate our results with experiments on synthetic Transformers and LLMs. Our results suggest that linear structures in trained networks are not global task directions, but evolving local geometries that partially persist across parameter and activation spaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that linear structures in neural network weights and activations are local and evolving rather than fixed global task directions. Experiments on a synthetic multitask transformer and LoRA adapters on DistilGPT-2/GPT-2 show strong local low-rank task-gradient structure, with the first recovery updates forming a trajectory-prefix basis that captures 77% of the LoRA recovery displacement; static bases miss the recovery direction and the useful basis drifts within 100 steps. A Gaussian local-linear theorem is developed to justify random parameter search in high dimensions. A single gradient step produces an activation shift with 0.58 cosine similarity to a labelled-contrast CAA steering vector, with similar steering effects observed on Qwen-0.5B BoolQ statements. Results are validated on synthetic Transformers and LLMs, suggesting evolving local geometries that partially persist across parameter and activation spaces.
Significance. If the empirical findings hold, the work advances understanding of the geometry of trained networks by demonstrating that useful linear directions for recovery and steering are local, non-stationary, and only partially persistent, rather than global fixed planes. A clear strength is the Gaussian local-linear theorem, which supplies a parameter-free theoretical justification for the effectiveness of random search even in very high dimensions. These results could inform more targeted approaches to model editing, task vectors, and activation steering, though the narrow experimental scope limits immediate generality.
major comments (2)
- [Abstract] Abstract: the central quantitative claim that the trajectory-prefix basis captures 77% of the LoRA recovery displacement is presented without a null baseline (random subspace, shuffled trajectories, or expected value under the paper's Gaussian local-linear theorem), error bars, or statistical test. In spaces of dimension 10^6–10^8, subspace capture rates of this magnitude can occur by chance depending on how the target displacement is defined, so the evidence that this constitutes a meaningful 'trajectory-prefix basis' is not yet secured.
- [Abstract] Abstract: the reported 0.58 cosine similarity between the single-gradient-step activation shift and the CAA steering vector lacks a null distribution, statistical test, details on hyperparameter choices, or data exclusion criteria. Without these, it is impossible to determine whether the alignment exceeds chance levels or what would be predicted by the Gaussian local-linear model introduced in the paper, weakening support for the claimed relation between parameter perturbations and activation steering.
minor comments (1)
- [Abstract] The abstract and methods descriptions would benefit from an explicit definition of 'recovery displacement' and the precise construction of the trajectory-prefix basis to allow readers to assess the measurement procedure.
Simulated Author's Rebuttal
We thank the referee for their careful review and for pointing out the need for stronger statistical grounding of our quantitative claims. We agree these additions will improve the manuscript and address each comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central quantitative claim that the trajectory-prefix basis captures 77% of the LoRA recovery displacement is presented without a null baseline (random subspace, shuffled trajectories, or expected value under the paper's Gaussian local-linear theorem), error bars, or statistical test. In spaces of dimension 10^6–10^8, subspace capture rates of this magnitude can occur by chance depending on how the target displacement is defined, so the evidence that this constitutes a meaningful 'trajectory-prefix basis' is not yet secured.
Authors: We agree that a null baseline is required to establish that the 77% capture is meaningful rather than chance. In revision we will add: (i) overlap with random subspaces of identical dimension, (ii) overlap with shuffled trajectory prefixes, (iii) the analytic expectation under the Gaussian local-linear theorem, (iv) error bars across independent runs, and (v) a statistical test against the null. These will be reported both in the abstract and in the main results section. revision: yes
-
Referee: [Abstract] Abstract: the reported 0.58 cosine similarity between the single-gradient-step activation shift and the CAA steering vector lacks a null distribution, statistical test, details on hyperparameter choices, or data exclusion criteria. Without these, it is impossible to determine whether the alignment exceeds chance levels or what would be predicted by the Gaussian local-linear model introduced in the paper, weakening support for the claimed relation between parameter perturbations and activation steering.
Authors: We accept that the 0.58 cosine result needs a null distribution and supporting details. The revised manuscript will include: a null distribution obtained from random activation shifts and from permuted CAA vectors, a statistical test of the observed similarity, explicit hyperparameter values for the single gradient step and CAA computation, and data exclusion criteria. We will also compare the empirical value to the prediction of the Gaussian local-linear theorem. revision: yes
Circularity Check
No circularity; empirical measurements and developed theorem are self-contained.
full rationale
The paper reports direct experimental measurements (77% subspace capture, 0.58 cosine alignment) on specific models and develops a Gaussian local-linear theorem to justify random search. No derivation step reduces by the paper's own equations to a fitted quantity from the same data, nor relies on load-bearing self-citation chains or ansatzes smuggled from prior author work. The central claims rest on observable quantities and an independently stated theorem rather than tautological redefinitions or predictions forced by construction. This is the normal case of an empirical paper whose quantitative support is external to its own fitting procedure.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Local linearity of the loss landscape around pretrained weights
- ad hoc to paper Gaussian local-linear theorem for random parameter search
Reference graph
Works this paper leans on
-
[1]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2021
2021
-
[2]
GradNorm: Gradient normalization for adaptive loss balancing in deep multitask networks
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. GradNorm: Gradient normalization for adaptive loss balancing in deep multitask networks. InInternational Conference on Machine Learning (ICML), 2018
2018
-
[3]
Felix Draxler, Kambis Veschgini, Manfred Salmhofer, and Fred A. Hamprecht. Essentially no barriers in neural network energy landscape. InInternational Conference on Machine Learning (ICML), 2018. URLhttps://arxiv.org/abs/1803.00885
Pith/arXiv arXiv 2018
-
[4]
Deep ensembles: A loss landscape perspective.arXiv preprint arXiv:1912.02757, 2019
Stanislav Fort, Huiyi Hu, and Balaji Lakshminarayanan. Deep ensembles: A loss landscape perspective.arXiv preprint arXiv:1912.02757, 2019
arXiv 1912
-
[5]
Gan et al. Neural thickets: Diverse task experts are dense around pretrained weights.arXiv preprint arXiv:2603.12228, 2026. URLhttps://arxiv.org/abs/2603.12228
arXiv 2026
-
[6]
Loss surfaces, mode connectivity, and fast ensembling of DNNs
Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry Vetrov, and Andrew Gordon Wilson. Loss surfaces, mode connectivity, and fast ensembling of DNNs. InAdvances in Neural Information Processing Systems (NeurIPS), 2018. URLhttps://arxiv.org/abs/1802.10026
Pith/arXiv arXiv 2018
-
[7]
Parameter-efficient transfer learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanisław Jastrzębski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. InInternational Conference on Machine Learning (ICML), 2019
2019
-
[8]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations (ICLR), 2022. URLhttps://arxiv.org/abs/2106. 09685
2022
-
[9]
Editing models with task arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. InInternational Conference on Learning Representations (ICLR), 2023. URLhttps://arxiv.org/abs/2212.04089
Pith/arXiv arXiv 2023
-
[10]
Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017. 19
2017
-
[11]
Measuring the intrinsic dimension of objective landscapes
Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objective landscapes. InInternational Conference on Learning Representations (ICLR), 2018. URLhttps://arxiv.org/abs/1804.08838
Pith/arXiv arXiv 2018
-
[12]
Visualizing the loss landscape of neural nets
Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Goldstein. Visualizing the loss landscape of neural nets. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[13]
Conflict-averse gradient descent for multi-task learning
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-averse gradient descent for multi-task learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[14]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[15]
Fine-tuning language models with just forward passes
Sadhika Malladi, Tianyu Gao, Eshaan Nichani, Alex Damian, Jason D Lee, Danqi Chen, and Sanjeev Arora. Fine-tuning language models with just forward passes. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[16]
Tim Salimans, Jonathan Ho, Xi Chen, Szymon Sidor, and Ilya Sutskever. Evolution strategies as a scalable alternative to reinforcement learning.arXiv preprint arXiv:1703.03864, 2017
Pith/arXiv arXiv 2017
-
[17]
Multi-task learning as multi-objective optimization
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimization. In Advances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[18]
Li, Arnab Sen Sharma, Aaron Mueller, Byron C
Eric Todd, Millicent L. Li, Arnab Sen Sharma, Aaron Mueller, Byron C. Wallace, and David Bau. Function vectors in large language models. InInternational Conference on Learning Representations (ICLR), 2024. URLhttps://arxiv.org/abs/2310.15213
arXiv 2024
-
[19]
Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023. URLhttps://arxiv.org/abs/2308.10248
Pith/arXiv arXiv 2023
-
[20]
Mitchell Wortsman, Gabriel Ilharco, Samir Yitzhak Gadre, Rebecca Roelofs, Raphael Gontijo- Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt. Model soups: Averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. InInternational Conference on Machine Learning (I...
arXiv 2022
-
[21]
Manning, and Christopher Potts
Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D. Manning, and Christopher Potts. ReFT: Representation finetuning for language models. In Advances in Neural Information Processing Systems (NeurIPS), 2024. URLhttps://arxiv. org/abs/2404.03592
arXiv 2024
-
[22]
TIES-merging: Resolving interference when merging models
Prateek Yadav, Derek Tam, Leshem Choshen, Colin Raffel, and Mohit Bansal. TIES-merging: Resolving interference when merging models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URLhttps://arxiv.org/abs/2306.01708
arXiv 2023
-
[23]
Gradient surgery for multi-task learning
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2020. URLhttps://arxiv.org/abs/2001.06782. 20
arXiv 2020
-
[24]
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405, 2023. URL https://arxiv.org/abs/2310.01405. 21 Table 7: Per-run LoRA random search, ens-k-of-Nand pass@NatK=...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.