GeoVolDiff: Taming 3D Geological Volumes with Latent Diffusion
Pith reviewed 2026-06-28 07:26 UTC · model grok-4.3
The pith
A latent diffusion model trained on physics-simulated 3D geological volumes produces surrogate data that trains inversion networks to competitive performance on both synthetic and real field datasets without added priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Without incorporating any additional physical or geological prior, inversion networks pre-trained exclusively on synthesized data attain competitive performance on both synthetic and field datasets, indicating that data synthesised by the generative model can serve as an effective surrogate for costly field-acquired labels.
What carries the argument
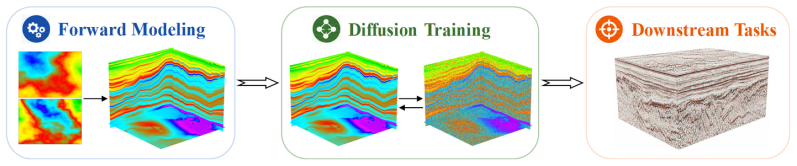
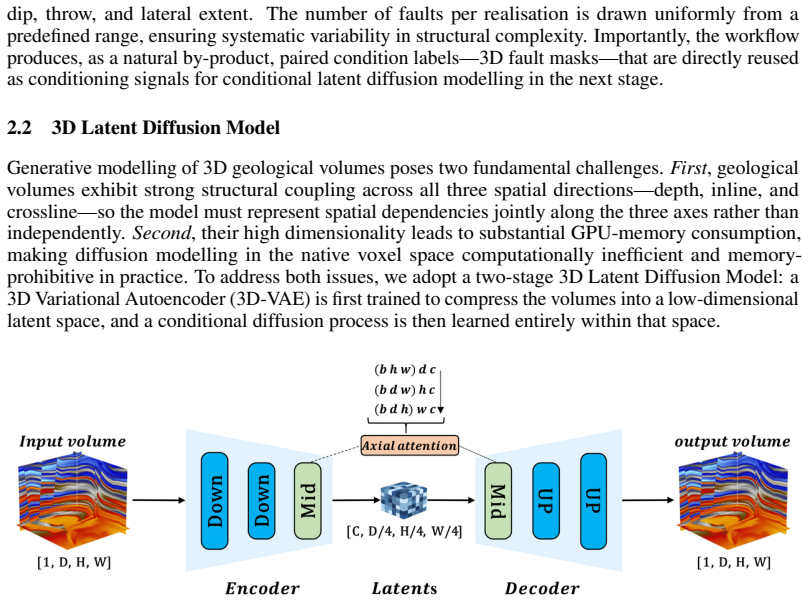
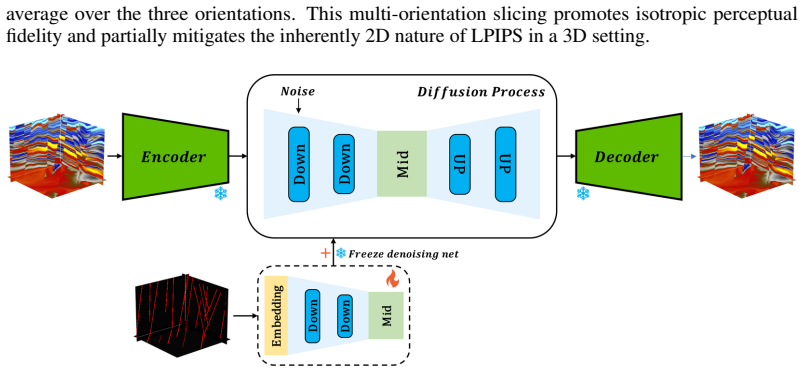
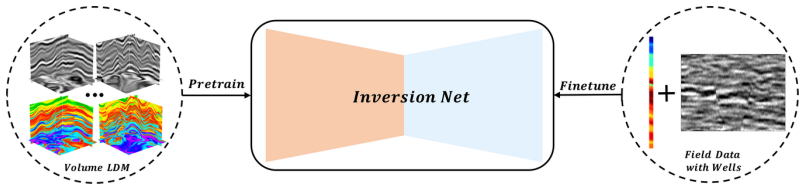
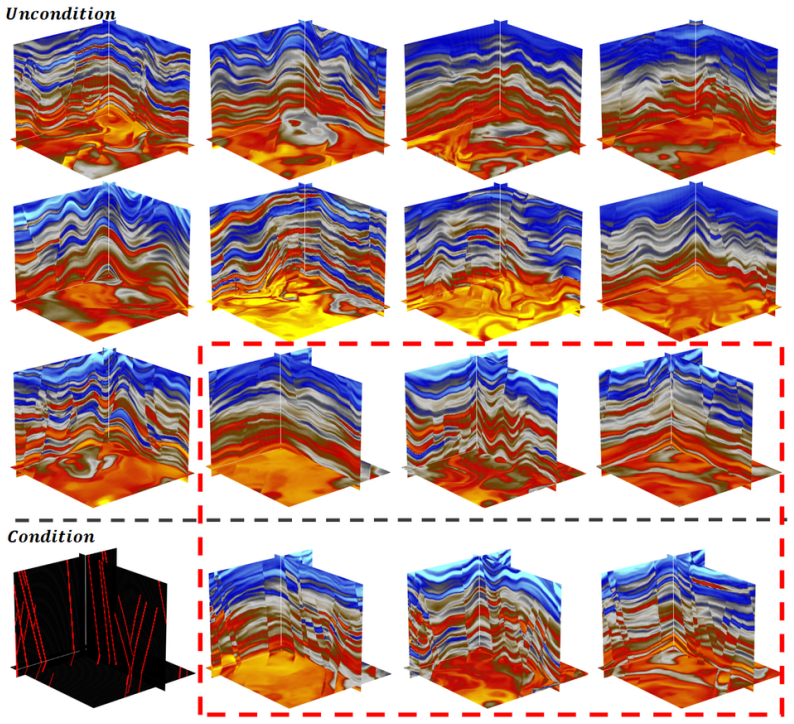
Latent Diffusion Model (LDM) that learns the statistical distribution of 3D geological structures from a physics-based forward-simulated corpus and then generates new structurally plausible volumes.
If this is right
- Inversion networks can be pre-trained solely on generated volumes and still reach competitive accuracy on field data.
- No extra physical or geological priors need to be injected into the inversion stage for the performance to hold.
- The generative pipeline supplies training data at a scale that would be prohibitive to acquire directly in the field.
Where Pith is reading between the lines
- The same synthesis pipeline could be tested on other geophysical tasks such as velocity model building or fault detection where labeled volumes are also scarce.
- Performance gaps between synthetic and field results would point to mismatches in the forward simulation rather than to the diffusion model itself.
- Increasing the resolution or diversity of the initial physics-simulated corpus would likely improve the quality of the generated surrogate volumes.
Load-bearing premise
The physics-based forward simulation produces a training corpus whose statistical distribution of 3D geological structures is sufficiently representative of real field conditions for the latent diffusion model to generate useful surrogate data.
What would settle it
If inversion networks trained only on the synthesized volumes show markedly lower accuracy than networks trained on real labeled field data when both are evaluated on the same held-out field dataset, the surrogate-data claim would be falsified.
Figures
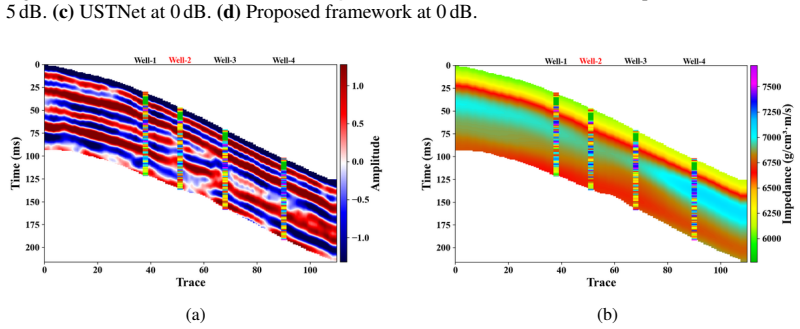
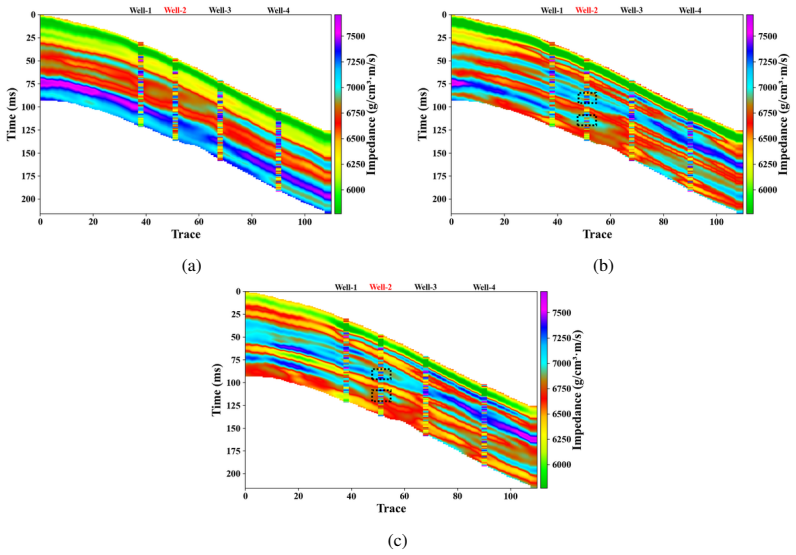
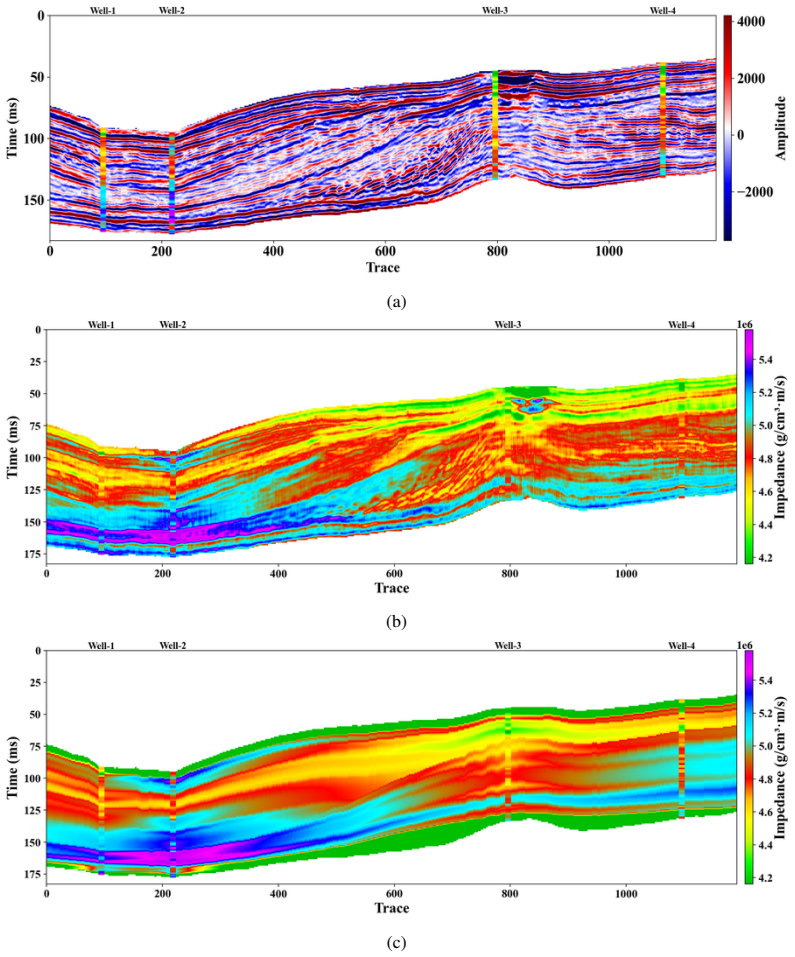
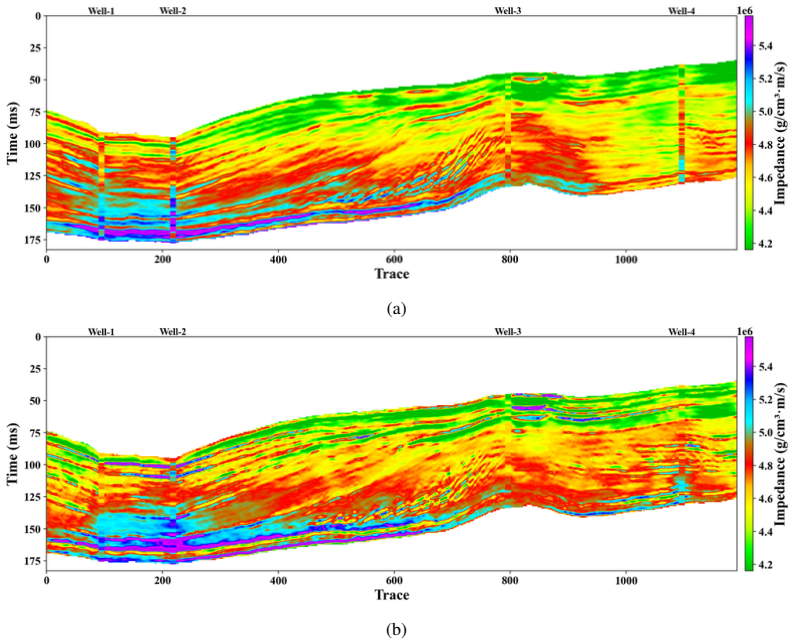
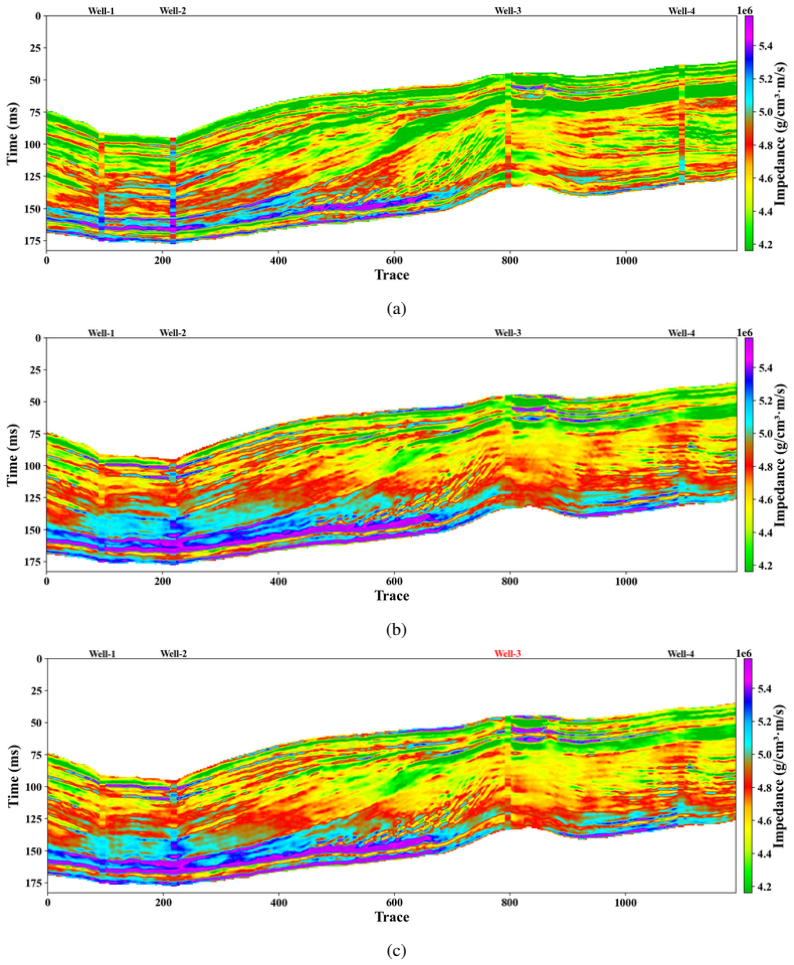
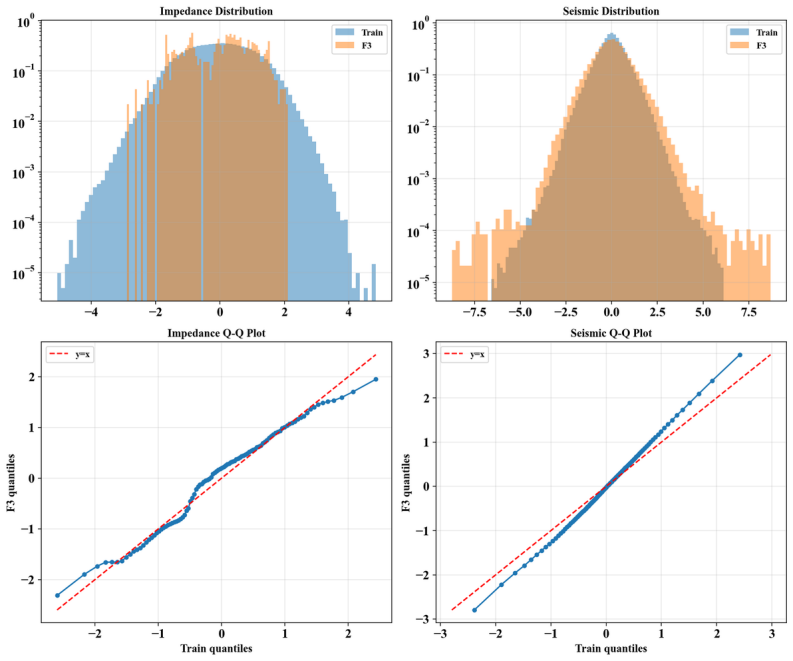
read the original abstract
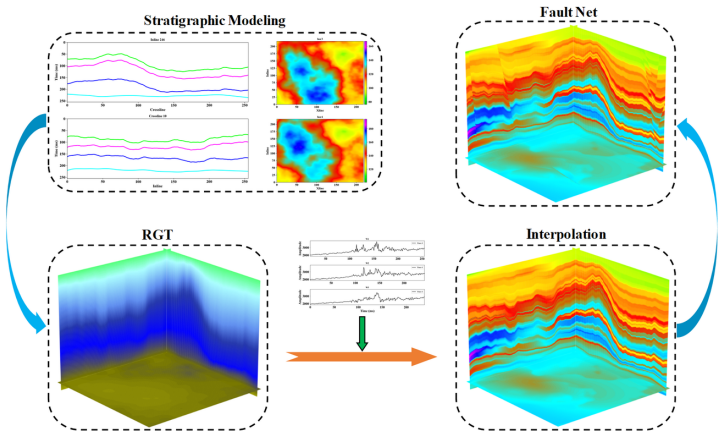
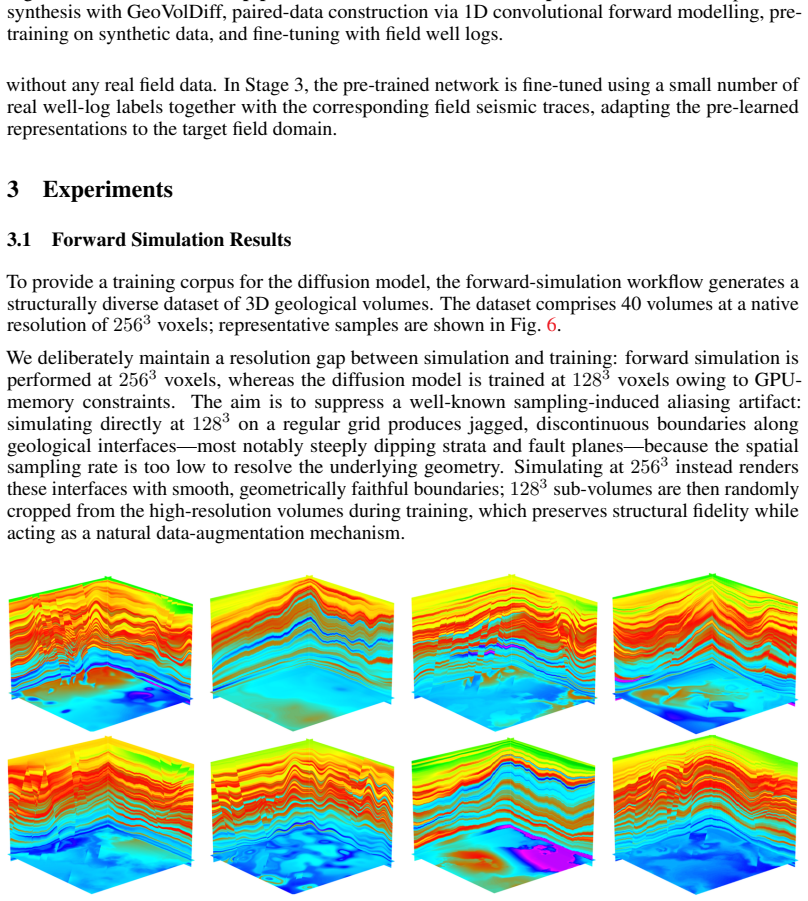
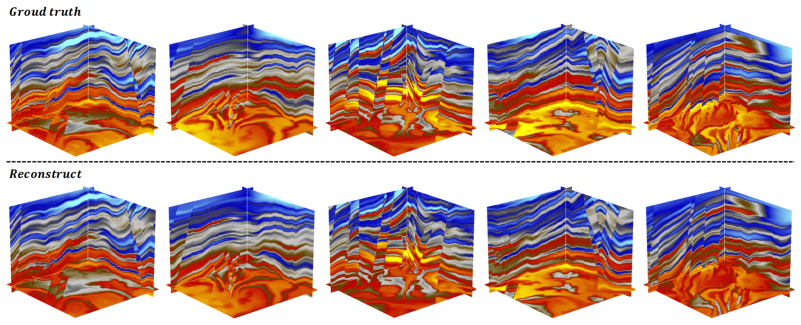
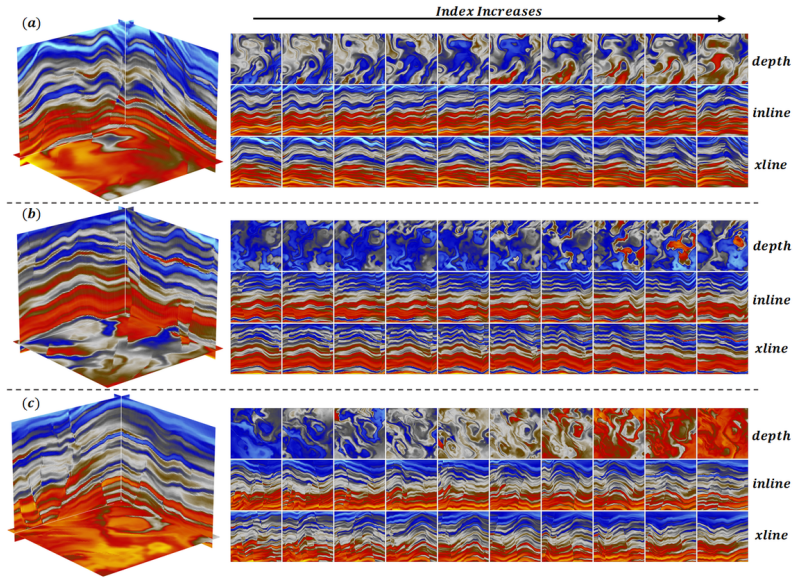
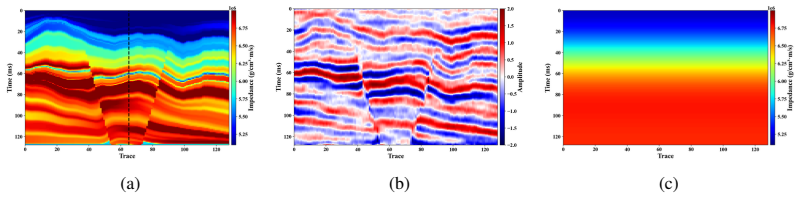
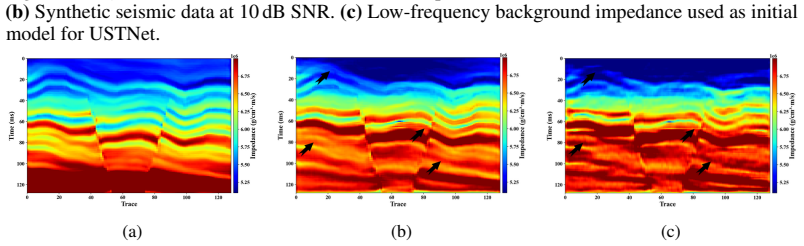
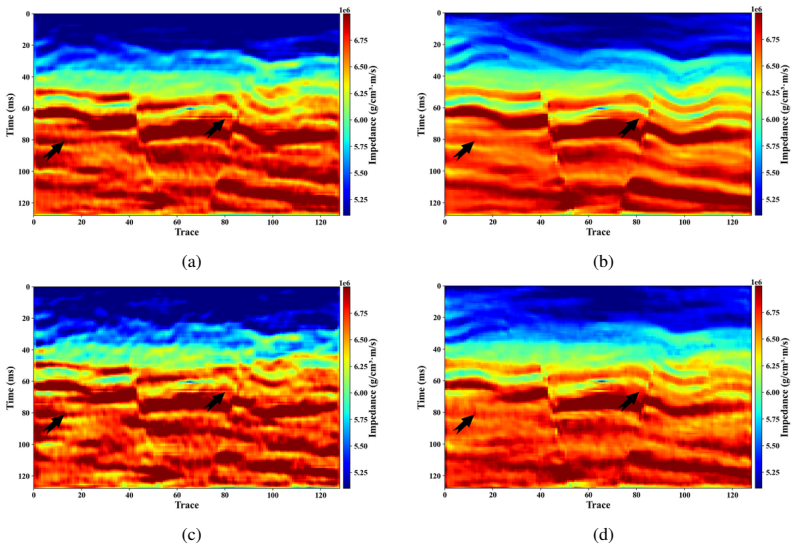
Deep learning has become a prevailing paradigm across a wide range of geophysical applications. Yet most existing studies concentrate on methodological refinements -- novel network architectures, physics-informed constraints, or taskspecific loss functions -- while paying comparatively little attention to a more fundamental challenge of any data-driven approach: the availability and representativeness of high-quality training data. This limitation is especially pronounced in geophysics. Unlike computer vision, which benefits from large-scale, well-curated benchmarks such as ImageNet, comparably abundant and reliably labelled geophysical data are prohibitively expensive to acquire and, in most field settings, lack accessible ground-truth supervision. To alleviate this data deficiency, we propose GeoVolDiff, a generative framework for three-dimensional geological volumes. It comprises three coupled stages: (i) constructing a foundational training corpus through physics-based forward simulation; (ii) training a Latent Diffusion Model (LDM) to capture the statistical distribution of 3D geological structures; and (iii) synthesizing diverse, structurally plausible volumes at scale for downstream geophysical tasks. We examine the utility of the synthesized data on a representative downstream task, seismic impedance inversion. Without incorporating any additional physical or geological prior, inversion networks pre-trained exclusively on synthesized data attain competitive performance on both synthetic and field datasets, indicating that data synthesised by the generative model can serve as an effective surrogate for costly field-acquired labels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GeoVolDiff, a three-stage generative framework for 3D geological volumes: (i) physics-based forward simulation to construct a foundational training corpus, (ii) training a Latent Diffusion Model (LDM) to capture the statistical distribution of geological structures, and (iii) synthesizing diverse volumes at scale. The central empirical claim is that inversion networks pre-trained exclusively on the LDM-synthesized data attain competitive performance on seismic impedance inversion for both synthetic and field datasets, without any additional physical or geological priors, indicating that the generated data can serve as an effective surrogate for costly field-acquired labels.
Significance. If the transfer results hold under proper validation, the work addresses a core practical bottleneck in geophysical machine learning by demonstrating scalable surrogate data generation. A strength is the explicit focus on downstream field-data transfer using only synthesized volumes rather than architectural innovations alone.
major comments (2)
- [Abstract] Abstract: the statement that inversion networks 'attain competitive performance' on field datasets supplies no quantitative metrics, baselines, error bars, or dataset details, which is load-bearing for assessing whether the surrogate-data claim is supported.
- [Training corpus construction] The description of the training corpus (stage i) provides no quantitative comparison (e.g., variogram, facies proportions, or spectral statistics) between the physics-simulated volumes and real field data, nor any sensitivity analysis on simulation parameters; this directly undermines the representativeness assumption required for the field-data transfer result.
minor comments (1)
- The abstract could include a short statement of the LDM architecture, conditioning mechanism, or loss used in stage (ii) to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our claims. We address each major point below and will revise the manuscript to strengthen the supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that inversion networks 'attain competitive performance' on field datasets supplies no quantitative metrics, baselines, error bars, or dataset details, which is load-bearing for assessing whether the surrogate-data claim is supported.
Authors: We agree that the abstract would benefit from explicit quantitative support. The body of the manuscript reports the relevant metrics (including error values, baselines, and dataset descriptions) for the field-data experiments. In revision we will condense and incorporate key quantitative results and dataset details into the abstract while remaining within length limits. revision: yes
-
Referee: [Training corpus construction] The description of the training corpus (stage i) provides no quantitative comparison (e.g., variogram, facies proportions, or spectral statistics) between the physics-simulated volumes and real field data, nor any sensitivity analysis on simulation parameters; this directly undermines the representativeness assumption required for the field-data transfer result.
Authors: The corpus is generated from standard physics-based forward modeling. The manuscript relies on downstream transfer performance as indirect evidence of utility rather than direct statistical matching. We accept that explicit comparisons would strengthen the argument and will add variogram, facies-proportion, and spectral analyses between the simulated volumes and available field data, together with a sensitivity study on the main simulation parameters. revision: yes
Circularity Check
No circularity: empirical validation stands independent of training distribution
full rationale
The manuscript describes a three-stage pipeline (physics simulation corpus → LDM training → synthesis) whose utility is asserted solely via downstream empirical performance of inversion networks on held-out synthetic and field datasets. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the abstract or described framework; the performance numbers are external measurements rather than algebraic identities or re-labeled fits. The representativeness assumption is an empirical premise subject to falsification by the field-data results themselves, not a definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Physics-based forward simulation produces volumes whose statistical distribution matches real 3D geological structures well enough for downstream utility.
Forward citations
Cited by 1 Pith paper
-
Multi-Condition Guided Diffusion Model for Controllable Elastic Parameter Synthesis
A diffusion model framework with iterative refinement, adapter conditioning, and DPS-projection guidance generates elastic parameters consistent with multi-source conditions and improves seismic inversion predictions ...
Reference graph
Works this paper leans on
-
[1]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22563–22575, 2023. 2
2023
-
[3]
Unsupervised seismic acoustic impedance inversion based on generative diffusion model.Geophysics, 90(4): M109–M121, 2025
Hongling Chen, Jie Chen, Mauricio D Sacchi, Jinghuai Gao, and Ping Yang. Unsupervised seismic acoustic impedance inversion based on generative diffusion model.Geophysics, 90(4): M109–M121, 2025. 1
2025
-
[4]
F3 Demo Dataset
dGB Earth Sciences. F3 Demo Dataset. Open Seismic Repository, 2009. URL https: //terranubis.com/datainfo/F3-Demo-2020. Accessed: 2024. 11
2009
-
[5]
Channelseg3d: Channel simulation and deep learning for channel interpretation in 3d seismic images.Geophysics, 86(4):IM73–IM83, 2021
Hang Gao, Xinming Wu, and Guofeng Liu. Channelseg3d: Channel simulation and deep learning for channel interpretation in 3d seismic images.Geophysics, 86(4):IM73–IM83, 2021. 1
2021
-
[6]
Fault detection on seismic structural images using a nested residual u-net.IEEE Transactions on Geoscience and Remote Sensing, 60:1–15, 2021
Kai Gao, Lianjie Huang, and Yingcai Zheng. Fault detection on seismic structural images using a nested residual u-net.IEEE Transactions on Geoscience and Remote Sensing, 60:1–15, 2021. 1 16
2021
-
[7]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 5
2020
-
[9]
High-fidelity seismic super-resolution using prior-informed deep learning with 3d awareness.IEEE Transactions on Image Processing, 2026
Jintao Li, Xinming Wu, Xianwen Zhang, Xin Du, Xiaoming Sun, Bao Deng, and Guangyu Wang. High-fidelity seismic super-resolution using prior-informed deep learning with 3d awareness.IEEE Transactions on Image Processing, 2026. 1
2026
-
[10]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22511–22521,
-
[11]
Improving vertical resolution of vintage seismic data by a weakly supervised method based on cycle generative adversarial network.Geophysics, 88(6):V445–V458, 2023
Dawei Liu, Wenli Niu, Xiaokai Wang, Mauricio D Sacchi, Wenchao Chen, and Cheng Wang. Improving vertical resolution of vintage seismic data by a weakly supervised method based on cycle generative adversarial network.Geophysics, 88(6):V445–V458, 2023. 1
2023
-
[12]
Seismic random noise attenua- tion based on non-iid pixel-wise gaussian noise modeling.IEEE Transactions on Geoscience and Remote Sensing, 60:1–16, 2022
Chuangji Meng, Jinghuai Gao, Yajun Tian, and Zhiqiang Wang. Seismic random noise attenua- tion based on non-iid pixel-wise gaussian noise modeling.IEEE Transactions on Geoscience and Remote Sensing, 60:1–16, 2022. 1
2022
-
[13]
Chuangji Meng, Jinghuai Gao, Wenting Shang, and Yajun Tian. A self-supervised method for attenuating seismic random and tracewise coherent noise under the nonpixelwise independence assumption.IEEE Transactions on Geoscience and Remote Sensing, 63:1–12, 2025. doi: 10.1109/TGRS.2025.3571390. 1
-
[14]
Posterior sampling for random noise attenuation via score-based generative models.Geophysics, 90(2):V83–V95,
Chuangji Meng, Jinghuai Gao, Baohai Wu, Hongling Chen, and Yajun Tian. Posterior sampling for random noise attenuation via score-based generative models.Geophysics, 90(2):V83–V95,
-
[15]
Synthetic seismic data for training deep learning networks.Interpretation, 10(3):SE31–SE39, 2022
Tom P Merrifield, Donald P Griffith, S Ahmad Zamanian, Stephane Gesbert, Satyakee Sen, Jorge De La Torre Guzman, R David Potter, and Henning Kuehl. Synthetic seismic data for training deep learning networks.Interpretation, 10(3):SE31–SE39, 2022. 2
2022
-
[16]
T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 4296–4304, 2024. 2
2024
-
[17]
Scaling the subsurface: Deep generative synthesis of 3d seismic properties
Q Pang, H Chen, J Gao, and X Sun. Scaling the subsurface: Deep generative synthesis of 3d seismic properties. In87th EAGE Annual Conference & Exhibition, volume 2026, pages 1–5. European Association of Geoscientists & Engineers, 2026. 2, 7
2026
-
[18]
Iterative gradient corrected semi-supervised seismic impedance inversion via swin transformer.IEEE Transactions on Geoscience and Remote Sensing, 2025
Qi Pang, Hongling Chen, Jinghuai Gao, Zhiqiang Wang, and Ping Yang. Iterative gradient corrected semi-supervised seismic impedance inversion via swin transformer.IEEE Transactions on Geoscience and Remote Sensing, 2025. 1, 8
2025
-
[19]
An image synthesizer.ACM Siggraph Computer Graphics, 19(3):287–296, 1985
Ken Perlin. An image synthesizer.ACM Siggraph Computer Graphics, 19(3):287–296, 1985. 3
1985
-
[20]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2, 4, 5
2022
-
[21]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Well-logging constrained seismic inversion based on closed-loop convolutional neural network.IEEE Transactions on Geoscience and Remote Sensing, 58(8):5564–5574, 2020
Yuqing Wang, Qiang Ge, Wenkai Lu, and Xinfei Yan. Well-logging constrained seismic inversion based on closed-loop convolutional neural network.IEEE Transactions on Geoscience and Remote Sensing, 58(8):5564–5574, 2020. 1 17
2020
-
[23]
Faultseg3d: Using synthetic data sets to train an end-to-end convolutional neural network for 3d seismic fault segmentation
Xinming Wu, Luming Liang, Yunzhi Shi, and Sergey Fomel. Faultseg3d: Using synthetic data sets to train an end-to-end convolutional neural network for 3d seismic fault segmentation. Geophysics, 84(3):IM35–IM45, 2019. 1
2019
-
[24]
Building realistic structure models to train convolutional neural networks for seismic structural interpretation.Geophysics, 85(4):W A27–W A39, 2020
Xinming Wu, Zhicheng Geng, Yunzhi Shi, Nam Pham, Sergey Fomel, and Guillaume Caumon. Building realistic structure models to train convolutional neural networks for seismic structural interpretation.Geophysics, 85(4):W A27–W A39, 2020. 2, 3
2020
-
[25]
Deep learning for multidimensional seismic impedance inversion.Geophysics, 86(5):R735–R745, 2021
Xinming Wu, Shangsheng Yan, Zhengfa Bi, Sibo Zhang, and Hongjie Si. Deep learning for multidimensional seismic impedance inversion.Geophysics, 86(5):R735–R745, 2021. 1
2021
-
[26]
Seismic resolution enhancement using physics-assisted seismic deconvolution network and domain adaptation.Geophysics, 90(3):R113–R125, 2025
Yang Yang, Zhuo Wang, Naihao Liu, Yuxin Zhang, Rongchang Liu, and Jinghuai Gao. Seismic resolution enhancement using physics-assisted seismic deconvolution network and domain adaptation.Geophysics, 90(3):R113–R125, 2025. 1
2025
-
[27]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 2, 5
2023
-
[28]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018. 4
2018
-
[29]
Deep-learning full-waveform inversion using seismic migration images.IEEE Transactions on Geoscience and Remote Sensing, 60:1–18, 2021
Wei Zhang and Jinghuai Gao. Deep-learning full-waveform inversion using seismic migration images.IEEE Transactions on Geoscience and Remote Sensing, 60:1–18, 2021. 1
2021
-
[30]
Adjoint-driven deep-learning seismic full-waveform inversion.IEEE Transactions on Geoscience and Remote Sensing, 59 (10):8913–8932, 2020
Wei Zhang, Jinghuai Gao, Zhaoqi Gao, and Hongling Chen. Adjoint-driven deep-learning seismic full-waveform inversion.IEEE Transactions on Geoscience and Remote Sensing, 59 (10):8913–8932, 2020. 1
2020
-
[31]
Regularized elastic full-waveform inversion using deep learning
Zhendong Zhang and Tariq Alkhalifah. Regularized elastic full-waveform inversion using deep learning. InAdvances in subsurface data analytics, pages 219–250. Elsevier, 2022. 1
2022
-
[32]
Lin Zhou, Jinghuai Gao, Jihao Yang, Hongling Chen, and Chuangji Meng. Ca-diffseg: Cross- attention guided diffusion model for seismic facies segmentation.IEEE Transactions on Geoscience and Remote Sensing, 64:1–15, 2026. doi: 10.1109/TGRS.2025.3612494. 1 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.