Retroactive Advantage Correction: Closed-Form V-Trace Bias Correction for Delay-Aware RLHF
Pith reviewed 2026-06-29 01:20 UTC · model grok-4.3
The pith
RAC corrects delayed rewards in RLHF by reinjecting aged clipped residuals into advantages, staying exactly unbiased when the delay kernel reinjects all mass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
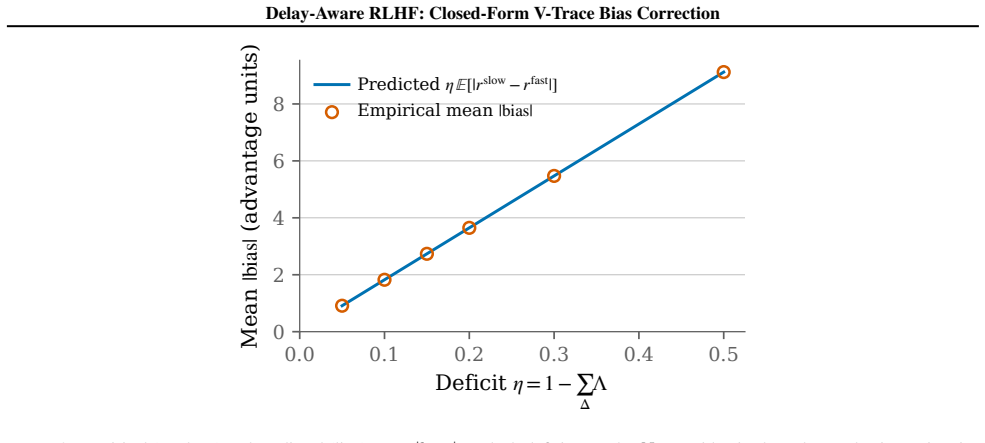
Under an unbiased clipped importance ratio, the cumulative RAC correction is exactly unbiased when the effective delay kernel reinjects all of its mass, and carries a bias linear in the unreinjected fraction otherwise; at the no-delay identity kernel it reduces to V-trace.
What carries the argument
Retroactive Advantage Correction (RAC): each pending slow completion is queued, aged through a non-negative kernel, and reinjected as a clipped residual into the next optimiser step's advantage.
Load-bearing premise
The clipped importance ratio must itself be unbiased.
What would settle it
Compute the observed policy bias on a delayed tabular MDP when the kernel leaves a known fraction of mass unreinjected and check whether the bias scales exactly linearly with that fraction.
Figures

read the original abstract
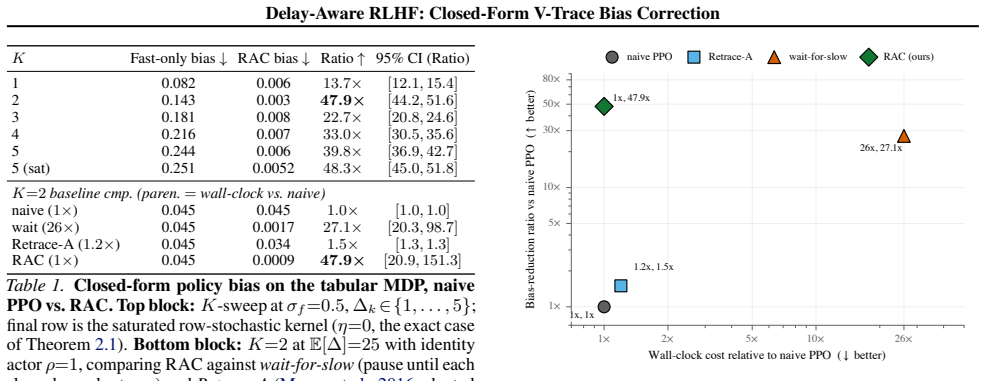
Reinforcement learning from human feedback (RLHF) in production does not always have a synchronous reward signal. Code-execution verifiers, slow judge ensembles, and queued human review can return several gradient steps after the rollout that produced them, breaking the synchronous-reward assumption underlying standard PPO. We address this gap with Retroactive Advantage Correction (RAC): each pending slow completion is queued, aged through a non-negative kernel, and reinjected as a clipped residual into the next optimiser step's advantage. We prove that under an unbiased clipped importance ratio, the cumulative RAC correction is exactly unbiased when the effective delay kernel reinjects all of its mass, and carries a bias linear in the unreinjected fraction otherwise; at the no-delay identity kernel it reduces to V-trace. On a tabular Markov decision process (MDP) proof-of-concept, RAC reduces the closed-form policy bias by up to 47.9x at the two-slow-channel configuration, beating wait-for-slow at lower wall-clock cost. RAC integrates with PPO and GRPO through a two-line reward-manager patch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Retroactive Advantage Correction (RAC) to address asynchronous/delayed rewards in RLHF training (e.g., slow verifiers or human review). RAC queues pending completions, ages them via a non-negative delay kernel, and reinjects clipped residuals into the advantage at subsequent optimizer steps. It claims a proof that the cumulative correction is exactly unbiased when an unbiased clipped importance ratio is used and the kernel reinjects all mass (reducing to standard V-trace at the identity kernel), with bias linear in the unreinjected fraction otherwise. On a tabular MDP, RAC yields up to 47.9x lower closed-form policy bias than wait-for-slow at lower wall-clock cost and integrates via a two-line patch into PPO/GRPO.
Significance. If the claims hold, RAC fills a practical gap in production RLHF where synchronous rewards cannot be assumed, offering a closed-form extension of V-trace that avoids full waiting without introducing uncontrolled bias. The reduction to V-trace and the kernel-based reinjection mechanism are clean; the tabular-MDP result provides a controlled demonstration of bias reduction. Broader impact would depend on scaling beyond the proof-of-concept MDP and confirming the precondition on the clipped ratio.
major comments (1)
- [unbiasedness theorem / proof of cumulative RAC correction] Main unbiasedness result (stated in the abstract and presumably proved in the theoretical section): the claim of exact unbiasedness is conditioned on the existence of an 'unbiased clipped importance ratio,' but the manuscript provides neither a construction nor a proof that such a ratio can be obtained under the standard clipping operator used in V-trace. Since clipping is known to introduce bias in the importance ratio, the 'exactly unbiased' regime appears unreachable under the paper's own operator, rendering the linear-bias claim a restatement of the precondition rather than a new guarantee.
minor comments (2)
- [Introduction] The abstract and introduction should explicitly state the journal or conference target and clarify how RAC differs from prior delayed-RL methods (e.g., those using experience replay buffers or asynchronous advantage estimation).
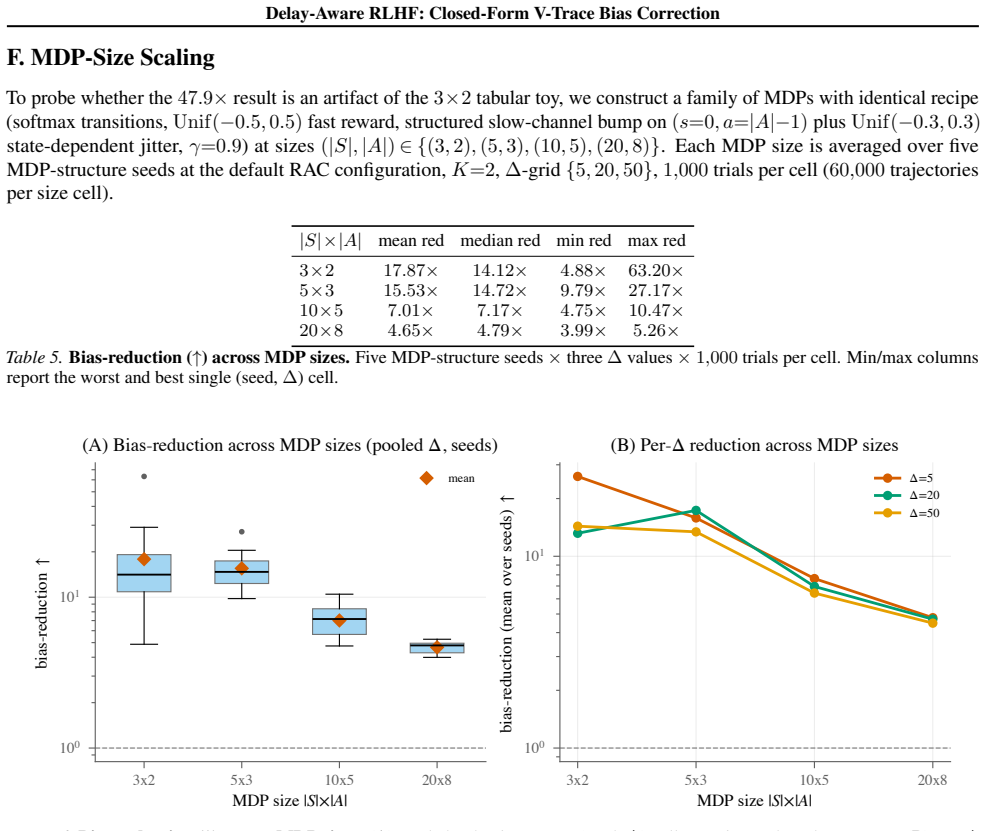
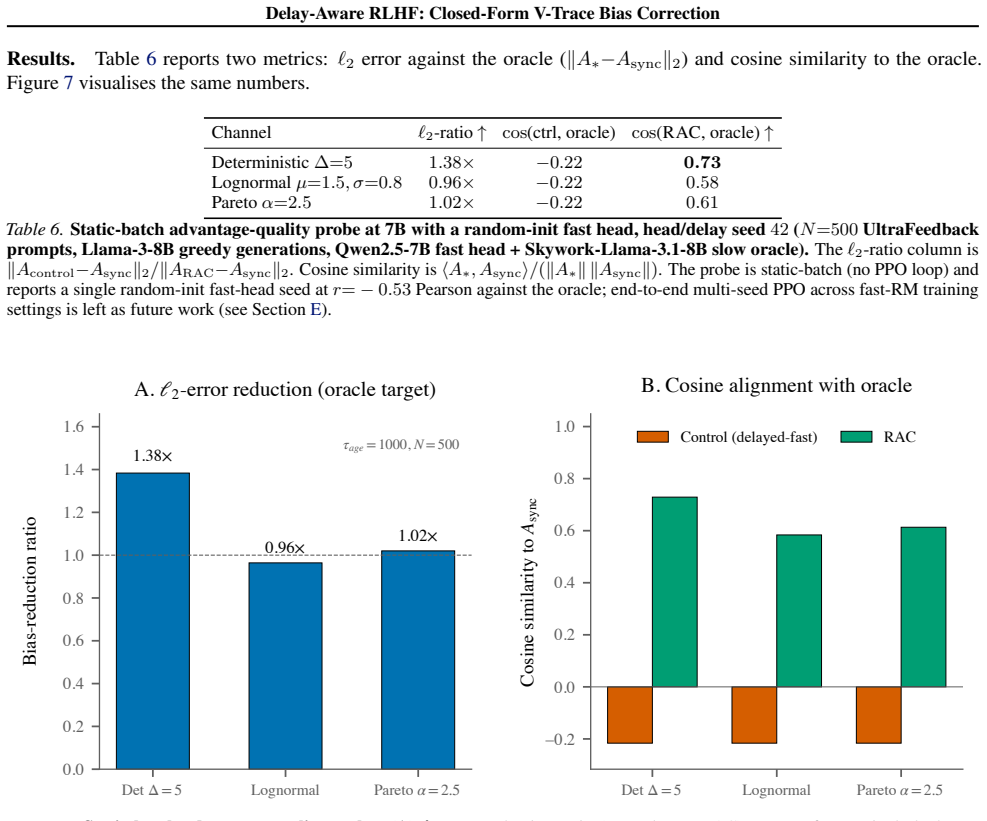
- [Experiments] The tabular-MDP experiment description lacks details on state/action space size, number of independent runs, variance of the reported 47.9x factor, and the precise definition of 'closed-form policy bias' used for measurement.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for recognizing the practical relevance of addressing delayed rewards in RLHF. We address the single major comment below.
read point-by-point responses
-
Referee: [unbiasedness theorem / proof of cumulative RAC correction] Main unbiasedness result (stated in the abstract and presumably proved in the theoretical section): the claim of exact unbiasedness is conditioned on the existence of an 'unbiased clipped importance ratio,' but the manuscript provides neither a construction nor a proof that such a ratio can be obtained under the standard clipping operator used in V-trace. Since clipping is known to introduce bias in the importance ratio, the 'exactly unbiased' regime appears unreachable under the paper's own operator, rendering the linear-bias claim a restatement of the precondition rather than a new guarantee.
Authors: We agree that the exact-unbiasedness statement is conditional on the existence of an unbiased clipped importance ratio and that the manuscript does not construct or prove the existence of such a ratio under the standard V-trace clipping operator. The core contribution of the theorem is therefore the propagation of that (preconditioned) unbiasedness through the delay kernel: when the kernel reinjects all mass the cumulative correction remains exactly unbiased (reducing to V-trace), while any unreinjected mass produces bias linear in the missing fraction. This linear-bias guarantee is new relative to the precondition and is the quantity measured in the tabular experiments. We will revise the abstract, theorem statement, and discussion to foreground the conditional nature and to clarify that RAC does not remove clipping-induced bias but only controls the additional bias arising from delay. revision: yes
Circularity Check
No significant circularity; result is explicitly conditional on external precondition
full rationale
The paper's strongest claim is a conditional proof of unbiasedness for the cumulative RAC correction, explicitly conditioned on the clipped importance ratio being unbiased (a precondition stated as such, not derived internally). The no-delay case is noted to reduce to the established V-trace method, which supplies independent external grounding rather than a self-referential loop. No load-bearing self-citations, fitted parameters renamed as predictions, or self-definitional steps appear in the derivation chain. The result therefore remains self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The clipped importance ratio is unbiased
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/ 1806.07857. Bretagnolle, J. and Huber, C. Estimation des densit´es: risque minimax.Zeitschrift f ¨ur Wahrscheinlichkeitstheorie und Verwandte Gebiete, 47(2):119–137,
-
[2]
Canonne, C. L. A short note on an inequality between KL and TV. arXiv preprint arXiv:2202.07198,
-
[3]
arXiv:2506.13585. Christiano, P. F., Leike, J., Brown, T. B., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[4]
arXiv:1706.03741. Espeholt, L., Soyer, H., Munos, R., Simonyan, K., Mnih, V ., Ward, T., Doron, Y ., Firoiu, V ., Harley, T., Dunning, I., Legg, S., and Kavukcuoglu, K. IMPALA: Scalable dis- tributed deep-RL with importance weighted actor–learner architectures. InInternational Conference on Machine Learning (ICML),
-
[5]
arXiv:1802.01561. Fan, T., Liu, L., Yue, Y ., Chen, J., Wang, C., Yu, Q., Zhang, C., Lin, Z., Zhu, R., Yuan, Y ., Zuo, X., Ma, B., Zhang, M., Liu, G., Zhang, R., Zhou, H., Xie, C., Zhu, R., Zhang, Z., Liu, X., Wang, M., Yan, L., and Wu, Y . Trun- cated proximal policy optimization. arXiv preprint,
-
[6]
arXiv:2506.15050. Fu, W., Gao, J., Shen, X., Zhu, C., Mei, Z., He, C., Xu, S., Wei, G., Mei, J., Wang, J., Yang, T., Yuan, B., and Wu, Y . AReaL: A large-scale asynchronous reinforce- ment learning system for language reasoning.arXiv preprint arXiv:2505.24298,
-
[7]
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
doi: 10.48550/arXiv. 2505.24298. Han, B., Ren, Z., Wu, Z., Zhou, Y ., and Peng, J. Off- policy reinforcement learning with delayed rewards. In Proceedings of the 39th International Conference on Ma- chine Learning (ICML),
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv
-
[8]
URL https://arxiv. org/abs/2106.11854. Huang, L. J., Zhang, Z., Hu, Q., Yang, S., and Han, S. Stable asynchrony: Variance-controlled off-policy RL for LLMs. arXiv preprint arXiv:2602.17616,
-
[9]
LiveCodeBench: Holistic and contamination free evalu- ation of large language models for code
Jain, N., Han, K., Gu, A., Li, W.-D., Yan, F., Zhang, T., Wang, S., Solar-Lezama, A., Sen, K., and Stoica, I. LiveCodeBench: Holistic and contamination free evalu- ation of large language models for code. arXiv preprint arXiv:2403.07974,
-
[10]
arXiv:2404.16019. Li, C., Elmahdy, A., Boyd, A., Wang, Z., Zeng, S., Garcia, A., Bhatia, P., Kass-Hout, T., Xiao, C., and Hong, M. Sta- bilizing off-policy training for long-horizon LLM agent via turn-level importance sampling and clipping-triggered normalization. arXiv preprint, 2025a. arXiv:2511.20718. Li, X., Wu, S., and Shen, Z. A-3PO: Accelerating as...
-
[11]
Lu, C., Zhang, Z., Wang, S., Lin, Q., Sun, B., and Liu, Y
arXiv:2604.02721. Lu, C., Zhang, Z., Wang, S., Lin, Q., Sun, B., and Liu, Y . GIPO: Gaussian importance sampling policy optimiza- tion. arXiv preprint arXiv:2603.03955,
-
[12]
Noukhovitch, M., Huang, S., Xhonneux, S., Hosseini, A., Agarwal, R., and Courville, A
arXiv:1606.02647. Noukhovitch, M., Huang, S., Xhonneux, S., Hosseini, A., Agarwal, R., and Courville, A. Asynchronous RLHF: Faster and more efficient off-policy RL for language mod- els. InInternational Conference on Learning Representa- tions (ICLR),
-
[13]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C
arXiv:2410.18252. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., and Lowe, R. Training language models to follow instructions with human feedback. InAdvances in Neural I...
-
[14]
Ramstedt, S., Bouteiller, Y ., Beltrame, G., Pal, C., and Binas, J
arXiv:2203.02155. Ramstedt, S., Bouteiller, Y ., Beltrame, G., Pal, C., and Binas, J. Reinforcement learning with random delays. InInternational Conference on Learning Representa- tions (ICLR),
-
[15]
Schulman, J., Moritz, P., Levine, S., Jordan, M., and Abbeel, P
URL https://arxiv.org/ abs/2010.02966. Schulman, J., Moritz, P., Levine, S., Jordan, M., and Abbeel, P. High-dimensional continuous control us- ing generalized advantage estimation. InInternational 5 Delay-Aware RLHF: Closed-Form V-Trace Bias Correction Conference on Learning Representations (ICLR),
arXiv 2010
-
[16]
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O
arXiv:1506.02438. Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
-
[17]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. DeepSeek- Math: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[18]
HybridFlow: A flexible and efficient RLHF framework.arXiv preprint arXiv:2409.19256,
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., and Wu, C. HybridFlow: A flexible and efficient RLHF framework.arXiv preprint arXiv:2409.19256,
-
[19]
Laminar: A scalable asynchronous RL post-training framework
Sheng, G., Tong, Y ., Wan, B., Zhang, W., et al. Laminar: A scalable asynchronous RL post-training framework. arXiv preprint arXiv:2510.12633,
-
[20]
arXiv:2009.01325. von Werra, L., Belkada, Y ., Tunstall, L., Beeching, E., Thrush, T., Lambert, N., Huang, S., Rasul, K., and Gallou ´edec, Q. TRL: Transformer reinforce- ment learning,
Pith/arXiv arXiv 2009
-
[21]
Xi, Z., Guo, X., Nan, Y ., Zhou, E., et al
URL https://github.com/ huggingface/trl. Xi, Z., Guo, X., Nan, Y ., Zhou, E., et al. BAPO: Stabilizing off-policy reinforcement learning for LLMs via balanced policy optimization with adaptive clipping. arXiv preprint arXiv:2510.18927,
-
[22]
OPPO: Ac- celerating PPO-based RLHF via pipeline overlap
Yan, K., Yu, Y ., Yu, Y ., Zheng, H., and Lai, F. OPPO: Ac- celerating PPO-based RLHF via pipeline overlap. arXiv preprint arXiv:2509.25762,
-
[23]
Zheng, H., Zhao, J., and Chen, B
URL https://arxiv.org/ abs/2212.01441. Zheng, H., Zhao, J., and Chen, B. Prosperity before collapse: How far can off-policy RL reach with stale data on LLMs? arXiv preprint arXiv:2510.01161,
-
[24]
The composite bound is the pointwise minimum, and the crossover point is the unique root of q 1 2KL−(1− 1 2 exp(−KL)) = 0 on [0,∞) (numerical root KL∗ ≈1.6259)
statesTV(π∥eπ)≤q 1 2KL(π∥eπ); Bretagnolle & Huber (1979) states TV(π∥eπ)≤1− 1 2 exp(−KL(π∥eπ)). The composite bound is the pointwise minimum, and the crossover point is the unique root of q 1 2KL−(1− 1 2 exp(−KL)) = 0 on [0,∞) (numerical root KL∗ ≈1.6259). Both inequalities hold per state s; assumptions (A1)-(A2) bound the clipped ratio and the slow-resid...
1979
-
[25]
B. Proof of Theorem 2.1 (Cumulative Unbiasedness) Substituting Equation (1) and using linearity of expectation, E hP t δt,i i = P t PD ∆=0α wage(∆) Λ[k,∆]E ρclip t,∆,i (rslow t,i −rfast,bl t,i ) = P t PD ∆=0eΛ[k,∆]E ρclip t,∆,i Xt,i , whereeΛ[k,∆]=α w age(∆) Λ[k,∆] is the effective kernel andXt,i ≜r slow t,i −rfast,bl t,i . Conditioning on (st,i, at,i) an...
2018
-
[26]
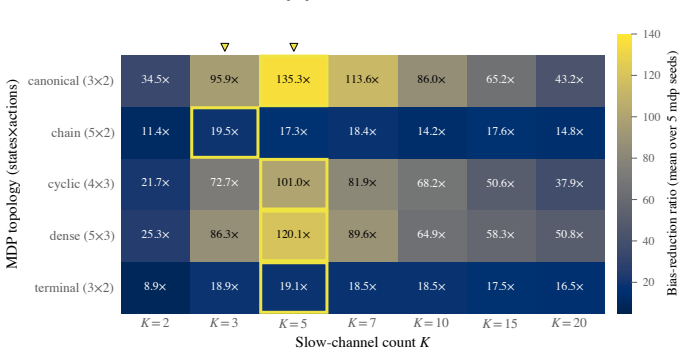
Table 2 and Figure 5 report per-topology argmax-K, the 5%-tolerance peak-band, reduction at argmax, and reduction at K=15
and the K-th noise term pinned to εK =−P k<K εk to preserve channel-sum invarianceP k rk =rtotal, and deterministic per-channel delay ∆k=k. Table 2 and Figure 5 report per-topology argmax-K, the 5%-tolerance peak-band, reduction at argmax, and reduction at K=15. Retrace-A baseline adaptation.The Retrace-A comparator (Table 1 bottom block) applies the Muno...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.