Diagnosing Evidence Utilization in Long-Context and Retrieval-Augmented Language Models under Matched Evidence Conditions
Pith reviewed 2026-06-28 00:54 UTC · model grok-4.3
The pith
A four-condition protocol with oracle normalization measures actual evidence advantage recovered by long-context and retrieval models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
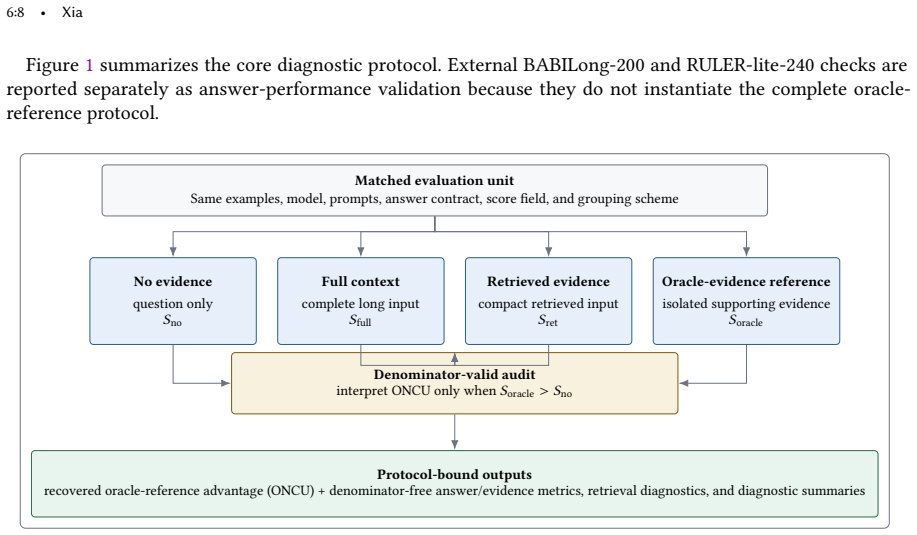
The paper claims that evidence utilization requires a matched diagnostic protocol comparing no-evidence answerability, oracle-evidence recoverability, full-context recovery, and retrieval-conditioned recovery, with ONCU supplying a denominator-valid estimate of the advantage recovered from the oracle reference under identical conditions.
What carries the argument
The four-condition matched diagnostic protocol that uses Oracle-Reference Normalized Context Utilization (ONCU) to isolate and normalize evidence advantage.
If this is right
- In controlled synthetic tasks the same evidence yields lower recovery when placed inside long inputs than when supplied compactly.
- On realistic multi-hop reconstructions full-context inputs produce higher answer and evidence metrics than the tested retrieved inputs.
- ONCU preserves the same performance ordering on the subset of cases where the oracle improves the answer.
- Stronger retrieval narrows some gaps but leaves the relative ordering between full-context and retrieved conditions intact.
Where Pith is reading between the lines
- The protocol could be applied to closed models to check whether the observed patterns depend on open-weight training details.
- Running the same conditions with varied prompt formats for the oracle case would test whether the normalization stays stable.
- The separation of conditions might be extended to measure utilization when evidence is noisy or partially contradictory.
Load-bearing premise
The oracle-evidence reference condition supplies a valid and unbiased upper bound that can normalize other conditions without bias from prompt formatting, model priors, or dataset differences.
What would settle it
Finding that accuracy or evidence metrics under the oracle-evidence condition fall below those under full-context or retrieved-evidence conditions on matched examples would show the reference bound is invalid.
Figures
read the original abstract
Final-answer accuracy, retrieval recall, and citation overlap do not reveal how much answer advantage a long-context or retrieval-augmented language model actually recovers from supplied evidence. A model may answer from parametric priors, fail to use evidence that is present, or cite relevant text without converting it into the final answer. This paper introduces a four-condition diagnostic protocol for evidence-utilization evaluation under matched examples, models, prompts, and scoring rules. The protocol compares no-evidence, full-context, retrieved-evidence, and oracle-evidence reference conditions, and uses Oracle-Reference Normalized Context Utilization (ONCU) as a denominator-valid estimate of recovered oracle-reference evidence advantage. The empirical study evaluates five local open-weight models from the Qwen, Gemma, Llama, and Mistral families over Controlled-ONCU-safe16K, HotpotQA-ONCU, and 2WikiMultiHopQA-ONCU, comprising 18,000 ONCU-compatible predictions. Results show a task-dependent diagnostic pattern: controlled synthetic settings expose reduced recovery when the same evidence is embedded in long input rather than supplied compactly, while realistic multi-hop reconstructions show that full-context inputs outperform the tested retrieved inputs in denominator-free answer and evidence metrics, with ONCU supporting the same direction on oracle-improving groups. Sensitivity audits with stronger retrieval settings narrow some gaps but do not overturn the scoped interpretation. The main contribution is therefore not a single utilization ratio, but a matched diagnostic protocol that separates no-evidence answerability, oracle-evidence recoverability, full-context recovery, retrieval-conditioned recovery, denominator validity, and companion answer/evidence diagnostics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard metrics fail to capture evidence utilization in long-context and RAG models and introduces a four-condition matched diagnostic protocol (no-evidence, full-context, retrieved-evidence, oracle-evidence reference) together with the ONCU metric to quantify recovered oracle-reference evidence advantage. It reports results from five open-weight models on three datasets (Controlled-ONCU-safe16K, HotpotQA-ONCU, 2WikiMultiHopQA-ONCU) comprising 18,000 predictions, showing task-dependent patterns where full-context often outperforms retrieved inputs and synthetic settings expose reduced recovery in long inputs.
Significance. If the oracle reference supplies an unbiased upper bound, the protocol offers a useful separation of answerability, recoverability, and normalized utilization that could improve diagnosis of evidence use beyond accuracy or recall. The scale of the empirical evaluation and focus on open models are positive features; the contribution is primarily methodological rather than a single numeric finding.
major comments (2)
- [Abstract] Abstract / protocol description: The central claim that ONCU is a 'denominator-valid estimate' requires the oracle-evidence condition to be matched to the other conditions in every respect except evidence content and compactness. The abstract states the conditions are 'matched' but supplies no explicit description of oracle prompt templates, instruction phrasing, or context-window handling relative to full-context and retrieved conditions; any systematic formatting difference would invalidate the normalization.
- [Abstract] Empirical study description: The reported task-dependent patterns (reduced recovery in long inputs for synthetic data; full-context advantage on multi-hop) rest on the assumption that the oracle condition provides a valid, unbiased upper bound. Without details on statistical controls, exact prompt construction, or checks for prompt-engineering confounds, it is impossible to confirm that observed differences reflect evidence utilization rather than condition-specific artifacts.
minor comments (2)
- [Abstract] Abstract: The phrase 'Controlled-ONCU-safe16K' is introduced without definition; a brief parenthetical or footnote would improve readability.
- [Abstract] Abstract: Consider adding a short table or diagram enumerating the four conditions and the quantities each isolates (no-evidence answerability, oracle recoverability, etc.) to make the protocol's separation clearer on first reading.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on the abstract and protocol. We address each point below and will incorporate clarifications into a revised manuscript to strengthen the description of the matched conditions and empirical controls.
read point-by-point responses
-
Referee: [Abstract] Abstract / protocol description: The central claim that ONCU is a 'denominator-valid estimate' requires the oracle-evidence condition to be matched to the other conditions in every respect except evidence content and compactness. The abstract states the conditions are 'matched' but supplies no explicit description of oracle prompt templates, instruction phrasing, or context-window handling relative to full-context and retrieved conditions; any systematic formatting difference would invalidate the normalization.
Authors: We agree that the abstract would benefit from greater specificity on matching. The full manuscript already defines the four conditions as sharing the same base prompt template, instruction phrasing, and context-window handling, with the oracle condition differing only by providing the complete relevant evidence in compact form rather than the full or retrieved context. In revision we will add the exact prompt templates for the oracle-evidence reference condition (and note their identity to the retrieved-evidence template except for evidence content) directly into the abstract or a new methods subsection to make the denominator-valid claim fully transparent. revision: yes
-
Referee: [Abstract] Empirical study description: The reported task-dependent patterns (reduced recovery in long inputs for synthetic data; full-context advantage on multi-hop) rest on the assumption that the oracle condition provides a valid, unbiased upper bound. Without details on statistical controls, exact prompt construction, or checks for prompt-engineering confounds, it is impossible to confirm that observed differences reflect evidence utilization rather than condition-specific artifacts.
Authors: We acknowledge that the abstract alone does not convey the full experimental controls. The manuscript reports fixed decoding parameters, consistent random seeds across conditions, and sensitivity audits with stronger retrieval settings. To address the concern directly, the revision will expand the methods section with the precise prompt-construction details, any formatting consistency checks performed, and explicit discussion of potential prompt-engineering confounds (including why the oracle condition was not further engineered beyond compactness). These additions will allow readers to evaluate whether the observed patterns reflect evidence utilization. revision: yes
Circularity Check
No circularity: ONCU is a normalized measurement protocol under explicitly matched conditions, not a self-referential derivation
full rationale
The paper introduces a four-condition diagnostic protocol (no-evidence, full-context, retrieved-evidence, oracle-evidence) and defines ONCU as a normalized estimate of recovered evidence advantage relative to the oracle reference. No equations, fitted parameters, or self-citations are shown that reduce any reported quantity to its own inputs by construction. The protocol is presented as an empirical measurement framework that separates multiple diagnostics; the oracle condition is invoked as an external reference under the claim of matched prompts and scoring, with no reduction to a fitted value or prior self-result. This is the normal case of a self-contained evaluation method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Oracle-evidence condition serves as a valid reference for maximum recoverable evidence advantage
invented entities (1)
-
ONCU (Oracle-Reference Normalized Context Utilization)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
“LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. ” In:Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. https://aclanthology.org/2024.acl-long.172/. Y. Benjamini and Y. Hochberg
2024
-
[2]
Journal of the Royal Statistical Society Series B: Statistical Methodology , author =
“Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. ”Journal of the Royal Statistical Society: Series B, 57, 1, 289–300. doi:10.1111/j.2517-6161.1995.tb02031.x. J. Cohen
-
[3]
“Reciprocal Rank Fusion Outperforms Condorcet and Individual Rank Learning Methods. ” In:Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, 758–759. doi:10.1145/1571941.1572114. S. Es, J. James, L. Espinosa-Anke, and S. Schockaert
-
[4]
“Gemma 3 Technical Report. ”arXiv preprint arXiv:2503.19786. https://arxiv.org/abs/2503.19786. O. E. Gundersen, M. Helmert, and H. Hoos
-
[5]
“Interactive-engagement versus traditional methods: A six-thousand-student survey of mechanics test data for introductory physics courses. ”American Journal of Physics, 66, 1, 64–74. doi:10.1119/1.18809. X. Ho, A.-K. D. Nguyen, S. Sugawara, and A. Aizawa
-
[6]
“Constructing a Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps. ” In:Proceedings of the 28th International Conference on Computational Linguistics, 6609–6625. doi:10.18653/v1/2020.coling-main.580. S. Holm
-
[7]
A Simple Sequentially Rejective Multiple Test Procedure
“A Simple Sequentially Rejective Multiple Test Procedure. ”Scandinavian Journal of Statistics, 6, 2, 65–70. https://www.jstor.org/ stable/4615733. C.-P. Hsieh, S. Sun, S. Kriman, S. Acharya, D. Rekesh, F. Jia, and Y. Zhang
-
[8]
RULER: What’s the Real Context Size of Your Long-Context Language Models?
“RULER: What’s the Real Context Size of Your Long-Context Language Models?”arXiv preprint arXiv:2404.06654. https://arxiv.org/abs/2404.06654. K. Järvelin and J. Kekäläinen
-
[9]
Cumulated gain-based evaluation of IR techniques , year =
“Cumulated gain-based evaluation of IR techniques. ”ACM Transactions on Information Systems, 20, 4, 422–446. doi:10.1145/582415.582418. G. Kamradt. 2023.Needle In A Haystack: Pressure Testing LLMs. https://github.com/gkamradt/LLMTest_NeedleInAHaystack. GitHub repository. (2023). V. Karpukhin, B. Oğuz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-t. Yih
-
[10]
In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
“Dense Passage Retrieval for Open-Domain Question Answering. ” In:Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, 6769–6781. doi:10.18653/v1/2020. emnlp-main.550. Y. Kuratov, A. Bulatov, P. Anokhin, I. Rodkin, D. Sorokin, A. Sorokin, and M. Burtsev
-
[11]
BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack
“BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack. ”arXiv preprint arXiv:2406.10149. https://arxiv.org/abs/2406.10149. E. La Malfa, A. Petrov, S. Frieder, C. Weinhuber, R. Burnell, R. Nazar, A. G. Cohn, N. Shadbolt, and M. Wooldridge
-
[12]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
“Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. ” In:Advances in Neural Information Processing Systems. Vol. 33, 9459–9474. https://arxiv.org/abs/2005.11401. N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang
Pith/arXiv arXiv 2005
-
[13]
“Lost in the Middle: How Language Models Use Long Contexts. ”Transactions of the Association for Computational Linguistics, 12, 157–173. doi:10.1162/tacl_a_00638. Meta AI. 2024.Introducing Llama 3.1: Our Most Capable Models to Date. https://ai.meta.com/blog/meta-llama-3-1/. Accessed 2026-06-01. (2024). Mistral AI. 2025.Mistral Small 3.1. https://mistral.a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1162/tacl_a_00638 2024
-
[14]
SQuAD: 100, 000+ Questions for Machine Comprehension of Text , booktitle =
“SQuAD: 100,000+ Questions for Machine Comprehension of Text. ” In:Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 2383–2392. doi:10.18653/v1/D16-1264. H. Rashkin et al
-
[15]
Sentence-BERT: Sentence embeddings using siamese BERT- networks
“Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. ” In:Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, 3982–3992. doi:10.18653/v1/D19-1410. S. Robertson and H. Zaragoza
-
[16]
“The Probabilistic Relevance Framework: BM25 and Beyond. ”Foundations and Trends in Information Retrieval, 3, 4, 333–389. doi:10.1561/1500000019. Journal of Artificial Intelligence Research, Vol. 4, Article
-
[17]
“The ASA Statement on𝑝-Values: Context, Process, and Purpose. ”The American Statistician, 70, 2, 129–133. doi:10.1080/00031305.2016.1154108. Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/00031305.2016.1154108 2016
-
[18]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
“HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. ” In:Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2369–2380. doi:10.18653/v1/D18-1259. Journal of Artificial Intelligence Research, Vol. 4, Article
-
[19]
Label Operational rule Localization The predicted evidence has zero or near-zero overlap with the oracle evidence and the answer is incorrect
Operational Rules for Failure-Type Assignment. Label Operational rule Localization The predicted evidence has zero or near-zero overlap with the oracle evidence and the answer is incorrect. Selection The prediction cites some relevant evidence, but the cited set is incomplete, distractor- heavy, or misses a required supporting passage. Integration The cit...
1960
-
[20]
ONCU is bootstrapped over valid metadata groups using 5,000 bootstrap resamples
Bootstrap 95% Confidence Intervals for Final 200-Sample ONCU-Relaxed-F1. ONCU is bootstrapped over valid metadata groups using 5,000 bootstrap resamples. Full denotes full-context input and Ret. denotes retrieved evidence. Model Dataset Full ONCU [95% CI] Ret. ONCU [95% CI] Valid Groups Qwen2.5-14B Controlled-safe16K-200 0.583 [0.506, 0.663]0.981 [0.955, ...
2000
-
[21]
CE@𝑚→𝑘 denotes hybrid first-stage retrieval with 𝑚 candidates, cross-encoder reranking, and final reader budget 𝑘
Five-Model Cross-Encoder Reranking Audit. CE@𝑚→𝑘 denotes hybrid first-stage retrieval with 𝑚 candidates, cross-encoder reranking, and final reader budget 𝑘. The table reports the best answer-F1 reranked setting for each model– dataset pair; ONCU is computed by joining each reranked retrieved prediction with the corresponding no-evidence and oracle-evidenc...
2024
-
[22]
BABILong is reported as answer-performance validation rather than as an ONCU benchmark because the current adapter does not provide oracle-evidence annotations
External BABILong-200 Validation. BABILong is reported as answer-performance validation rather than as an ONCU benchmark because the current adapter does not provide oracle-evidence annotations. Bracketed values are 95% bootstrap confidence intervals for relaxed answer F1. Model No-Evidence F1 [95% CI] Full-Context F1 [95% CI] Retrieved-Evidence F1 [95% C...
2024
-
[23]
Publication date: August 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.