A Neuromorphic Reinforcement Learning Framework for Efficient Pathfinding in Robotic Mobile Fulfillment Systems
Pith reviewed 2026-06-26 17:29 UTC · model grok-4.3
The pith
The SDQN-RMFS framework converts a trained ANN reinforcement learning policy into a spiking neural network via hard-label knowledge distillation and deploys it on neuromorphic hardware for energy-efficient pathfinding in robotic mobile fulf
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
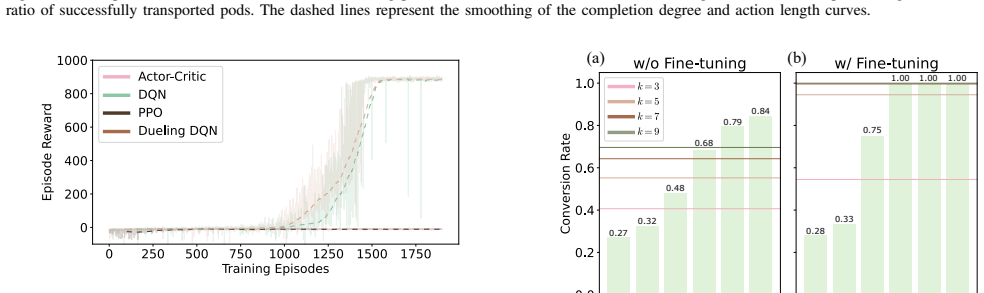
By training an ANN policy with collision-allowing trajectories and converting it to an SNN through hard-label knowledge distillation, the framework achieves high-fidelity deployment on neuromorphic hardware, resulting in up to 11,281 times energy savings and nearly two-fold latency reduction compared to GPU baselines while preserving pathfinding decision quality.
What carries the argument
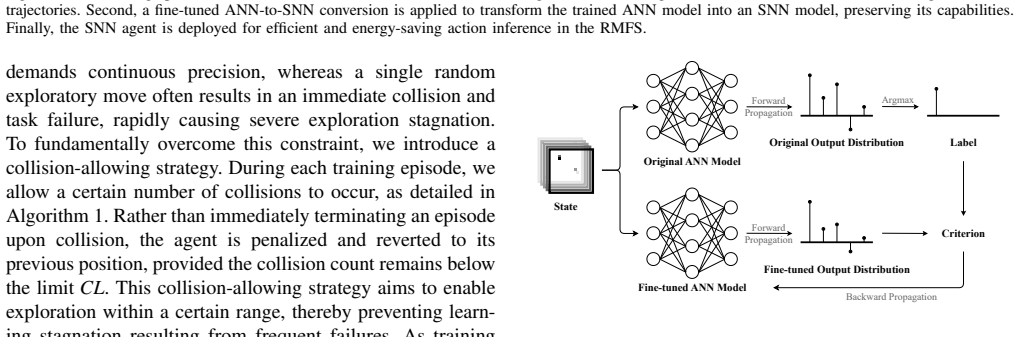
Hard-label knowledge distillation for ANN-to-SNN conversion, which mitigates output distribution mismatch to preserve the RL policy's decision-making capability.
If this is right
- RL-trained policies become deployable on ultra-low-power neuromorphic chips for real-time RMFS operations.
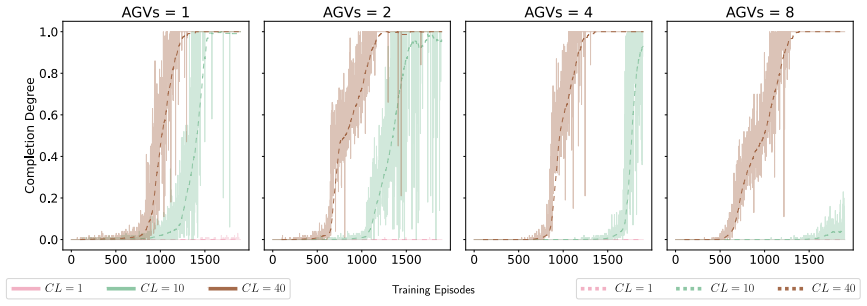
- Collision-allowing training strategies can densify informative data for better policy learning in constrained spaces.
- Neuromorphic inference supports large-scale RMFS without the energy demands of traditional hardware.
- Event-driven SNN computation reduces latency in pathfinding decisions under real-time constraints.
Where Pith is reading between the lines
- This approach could extend to other robotic navigation tasks in confined or dynamic settings where energy is limited.
- Integration with larger warehouse systems might allow more robots to operate simultaneously on the same power budget.
- Future hardware improvements in neuromorphic chips could amplify these efficiency gains further.
Load-bearing premise
The hard-label knowledge distillation approach effectively addresses the output distribution mismatch and preserves policy capability across the full ANN-to-SNN conversion pipeline without substantial degradation in pathfinding performance.
What would settle it
A hardware experiment on the neuromorphic chip that shows pathfinding success rates or decision quality dropping substantially below the original ANN policy level.
Figures

read the original abstract
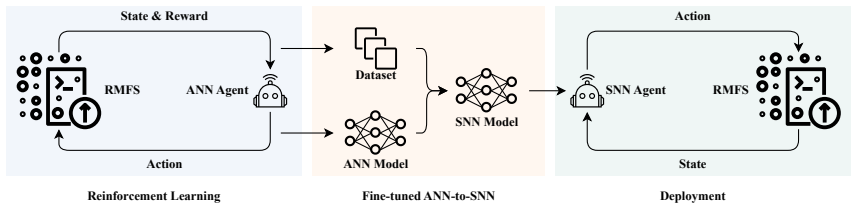
Dynamic environmental changes, confined workspaces, and stringent real-time constraints make pathfinding in Robotic Mobile Fulfillment Systems (RMFS) a challenging problem for conventional search- and rule-based methods, which typically suffer from high computational complexity and long decision latency. While reinforcement learning (RL) has emerged as a powerful alternative, deploying learned policies with extreme energy efficiency on resource-constrained hardware remains an open challenge. We present SDQN-RMFS, an end-to-end framework that achieves high-fidelity deployment of an RL-trained policy from a full-precision artificial neural network (ANN) through to a neuromorphic chip. By computing only when triggered by sparse events, this framework unlocks ultra-low-power RMFS pathfinding. Our full-stack pipeline operates as follows: an ANN policy is first efficiently trained via a collision-allowing strategy to densify informative trajectories, and then converted into a spiking neural network (SNN) via a hard-label knowledge distillation approach. This effectively addresses the output distribution mismatch, preserving policy capability across the ANN-to-SNN pipeline while substantially reducing inference latency. Hardware experiments demonstrate up to 11,281$\times$ energy savings and a nearly two-fold reduction in latency compared to a high-performance GPU baseline, while maintaining decision quality on par with the original trained policy. These results establish physical neuromorphic inference as a practical and energy-sustainable pathway for large-scale RMFS operations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SDQN-RMFS, an end-to-end framework for pathfinding in Robotic Mobile Fulfillment Systems. An ANN policy is trained via a collision-allowing strategy to densify trajectories, converted to an SNN using hard-label knowledge distillation to mitigate output distribution mismatch, and deployed on neuromorphic hardware. Hardware experiments are reported to achieve up to 11,281× energy savings and nearly 2× latency reduction versus a high-performance GPU baseline while preserving decision quality comparable to the original policy.
Significance. If the hardware results are robust, the work would demonstrate a practical pathway for energy-efficient neuromorphic deployment of RL policies in real-time robotic systems under stringent constraints, with potential impact on sustainable large-scale warehouse automation. The complete pipeline from training to hardware inference is a strength.
major comments (1)
- [Hardware Experiments / abstract] The central empirical claim rests on hardware experiments showing 11,281× energy savings and ~2× latency reduction, but the manuscript supplies no details on trial counts, statistical tests, error bars, baseline implementations, or data exclusion criteria (see abstract and any Experimental Results section). This prevents verification of the reported factors and decision-quality parity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in our hardware experiments. We agree that the current manuscript does not provide sufficient methodological details to allow independent verification of the reported energy savings, latency improvements, and decision-quality parity. We will address this by expanding the relevant sections in the revised manuscript.
read point-by-point responses
-
Referee: [Hardware Experiments / abstract] The central empirical claim rests on hardware experiments showing 11,281× energy savings and ~2× latency reduction, but the manuscript supplies no details on trial counts, statistical tests, error bars, baseline implementations, or data exclusion criteria (see abstract and any Experimental Results section). This prevents verification of the reported factors and decision-quality parity.
Authors: We acknowledge this limitation in the submitted manuscript. The Experimental Results section will be revised to include: (i) the total number of independent trials and hardware runs performed for each metric; (ii) the statistical tests used (e.g., paired t-tests or Wilcoxon tests) together with p-values; (iii) error bars or standard deviations for all reported energy and latency figures; (iv) precise specifications of the GPU baseline (model, precision, batch size, and measurement methodology); and (v) any data exclusion criteria applied (e.g., outlier removal rules). These additions will be placed in both the main text and supplementary material to substantiate the 11,281× energy saving and ~2× latency claims while confirming decision-quality equivalence. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's pipeline consists of ANN policy training with a collision-allowing strategy, hard-label distillation to SNN, and neuromorphic hardware deployment. The load-bearing claims (11,281× energy savings, ~2× latency reduction, on-par decision quality) rest on direct hardware measurements rather than any derivation that reduces to fitted inputs, self-definitions, or self-citation chains. No equations, ansatzes, or uniqueness theorems are invoked in the provided text that would create circularity by construction. The results are externally falsifiable via physical experiments and do not rename known patterns or smuggle assumptions through citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Robotic mobile ful- fillment systems: A survey on recent developments and research opportunities,
´I. R. da Costa Barros and T. P. Nascimento, “Robotic mobile ful- fillment systems: A survey on recent developments and research opportunities,”Robotics and Autonomous Systems, vol. 137, p. 103729, 2021
2021
-
[2]
Primal: Pathfinding via reinforcement and imitation multi-agent learning,
G. Sartoretti, J. Kerr, Y . Shi, G. Wagner, T. S. Kumar, S. Koenig, and H. Choset, “Primal: Pathfinding via reinforcement and imitation multi-agent learning,”IEEE Robotics and Automation Letters, vol. 4, no. 3, pp. 2378–2385, 2019
2019
-
[3]
Primal 2: Pathfind- ing via reinforcement and imitation multi-agent learning-lifelong,
M. Damani, Z. Luo, E. Wenzel, and G. Sartoretti, “Primal 2: Pathfind- ing via reinforcement and imitation multi-agent learning-lifelong,” IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 2666–2673, 2021
2021
- [4]
-
[5]
A formal basis for the heuristic determination of minimum cost paths,
P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,”IEEE transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968
1968
-
[6]
Path planning for multiple mobile robots in smart warehouse,
A. Bolu and ¨O. Korc ¸ak, “Path planning for multiple mobile robots in smart warehouse,” in2019 7th International Conference on Control, Mechatronics and Automation (ICCMA). IEEE, 2019, pp. 144–150
2019
-
[7]
Integrated task assignment and path planning for capacitated multi- agent pickup and delivery,
Z. Chen, J. Alonso-Mora, X. Bai, D. D. Harabor, and P. J. Stuckey, “Integrated task assignment and path planning for capacitated multi- agent pickup and delivery,”IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 5816–5823, 2021
2021
-
[8]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[9]
Acquisition of automated guided vehicle route planning policy using deep reinforcement learning,
R. Kamoshida and Y . Kazama, “Acquisition of automated guided vehicle route planning policy using deep reinforcement learning,” in 2017 6th IEEE international conference on advanced logistics and transport (ICALT). IEEE, 2017, pp. 1–6
2017
-
[10]
Deep reinforcement learning: A brief survey,
K. Arulkumaran, M. P. Deisenroth, M. Brundage, and A. A. Bharath, “Deep reinforcement learning: A brief survey,”IEEE signal processing magazine, vol. 34, no. 6, pp. 26–38, 2017
2017
-
[11]
A* guiding dqn algorithm for automated guided vehicle pathfinding problem of robotic mobile fulfillment systems,
L. Luo, N. Zhao, Y . Zhu, and Y . Sun, “A* guiding dqn algorithm for automated guided vehicle pathfinding problem of robotic mobile fulfillment systems,”Computers & Industrial Engineering, vol. 178, p. 109112, 2023
2023
-
[12]
Reinforcement co-learning of deep and spiking neural networks for energy-efficient mapless navi- gation with neuromorphic hardware,
G. Tang, N. Kumar, and K. P. Michmizos, “Reinforcement co-learning of deep and spiking neural networks for energy-efficient mapless navi- gation with neuromorphic hardware,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020, pp. 6090– 6097
2020
-
[13]
Toward energy-efficient spike-based deep reinforcement learning with temporal coding,
M. Zhang, S. Wang, J. Wu, W. Wei, D. Zhang, Z. Zhou, S. Wang, F. Zhang, and Y . Yang, “Toward energy-efficient spike-based deep reinforcement learning with temporal coding,”IEEE Computational Intelligence Magazine, vol. 20, no. 2, pp. 45–57, 2025
2025
-
[14]
Networks of spiking neurons: the third generation of neural network models,
W. Maass, “Networks of spiking neurons: the third generation of neural network models,”Neural networks, vol. 10, no. 9, pp. 1659–1671, 1997
1997
-
[15]
Loihi: A neuromorphic manycore processor with on-chip learning,
M. Davies, N. Srinivasa, T.-H. Lin, G. Chinya, Y . Cao, S. H. Choday, G. Dimou, P. Joshi, N. Imam, S. Jain,et al., “Loihi: A neuromorphic manycore processor with on-chip learning,”Ieee Micro, vol. 38, no. 1, pp. 82–99, 2018
2018
-
[16]
Improved robustness of reinforcement learning policies upon conver- sion to spiking neuronal network platforms applied to atari breakout game,
D. Patel, H. Hazan, D. J. Saunders, H. T. Siegelmann, and R. Kozma, “Improved robustness of reinforcement learning policies upon conver- sion to spiking neuronal network platforms applied to atari breakout game,”Neural Networks, vol. 120, pp. 108–115, 2019
2019
-
[17]
A neuro-inspired approach to intelligent collision avoidance and navigation,
N. Salvatore, S. Mian, C. Abidi, and A. D. George, “A neuro-inspired approach to intelligent collision avoidance and navigation,” in2020 AIAA/IEEE 39th Digital Avionics Systems Conference (DASC). IEEE, 2020, pp. 1–9
2020
-
[18]
O. Richter, Y . Xing, M. De Marchi, C. Nielsen, M. Katsimpris, R. Cattaneo, Y . Ren, Y . Hu, Q. Liu, S. Sheik,et al., “Speck: A smart event-based vision sensor with a low latency 327k neuron convolutional neuronal network processing pipeline,”arXiv preprint arXiv:2304.06793, 2023
-
[19]
Strategy and benchmark for con- verting deep q-networks to event-driven spiking neural networks,
W. Tan, D. Patel, and R. Kozma, “Strategy and benchmark for con- verting deep q-networks to event-driven spiking neural networks,” in Proceedings of the AAAI conference on artificial intelligence, vol. 35, no. 11, 2021, pp. 9816–9824
2021
-
[20]
Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing,
P. U. Diehl, D. Neil, J. Binas, M. Cook, S.-C. Liu, and M. Pfeiffer, “Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing,” in2015 International joint conference on neural networks (IJCNN). ieee, 2015, pp. 1–8
2015
-
[21]
Optimal conversion of conventional artificial neural networks to spiking neural networks,
S. Deng and S. Gu, “Optimal conversion of conventional artificial neural networks to spiking neural networks,” inInternational Conference on Learning Representations, 2021. [Online]. Available: https://openreview.net/forum?id=FZ1oTwcXchK
2021
-
[22]
Optimal ANN-SNN conversion for high-accuracy and ultra-low- latency spiking neural networks,
T. Bu, W. Fang, J. Ding, P. DAI, Z. Yu, and T. Huang, “Optimal ANN-SNN conversion for high-accuracy and ultra-low- latency spiking neural networks,” inInternational Conference on Learning Representations, 2022. [Online]. Available: https: //openreview.net/forum?id=7B3IJMM1k M
2022
-
[23]
Error-aware conversion from ann to snn via post-training parameter calibration,
Y . Li, S. Deng, X. Dong, and S. Gu, “Error-aware conversion from ann to snn via post-training parameter calibration,”International Journal of Computer Vision, vol. 132, no. 9, pp. 3586–3609, 2024
2024
-
[24]
Masked spiking transformer,
Z. Wang, Y . Fang, J. Cao, Q. Zhang, Z. Wang, and R. Xu, “Masked spiking transformer,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 1761–1771
2023
-
[25]
Deep reinforcement learning with double q-learning,
H. Van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning,” inProceedings of the AAAI conference on artificial intelligence, vol. 30, no. 1, 2016
2016
-
[26]
Differential coding for training-free ann-to-snn conversion,
Z. Huang, W. Fang, T. Bu, P. Xue, Z. Hao, W. Liu, Y . Tang, Z. Yu, and T. Huang, “Differential coding for training-free ann-to-snn conversion,”arXiv preprint arXiv:2503.00301, 2025
-
[27]
A free lunch from ann: Towards efficient, accurate spiking neural networks calibration,
Y . Li, S. Deng, X. Dong, R. Gong, and S. Gu, “A free lunch from ann: Towards efficient, accurate spiking neural networks calibration,” inInternational conference on machine learning. PMLR, 2021, pp. 6316–6325
2021
-
[28]
Dueling network architectures for deep reinforcement learning,
Z. Wang, T. Schaul, M. Hessel, H. Hasselt, M. Lanctot, and N. Freitas, “Dueling network architectures for deep reinforcement learning,” in International conference on machine learning. PMLR, 2016, pp. 1995–2003
2016
-
[29]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Actor-critic algorithms,
V . Konda and J. Tsitsiklis, “Actor-critic algorithms,”Advances in neural information processing systems, vol. 12, 1999
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.