Reason, Then Re-reason: Cross-view Revisiting Improves Spatial Reasoning
Pith reviewed 2026-06-27 10:39 UTC · model grok-4.3
The pith
A two-phase process lets an MLLM form a spatial hypothesis from video then revise it after seeing synthesized complementary views from predicted 3D geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
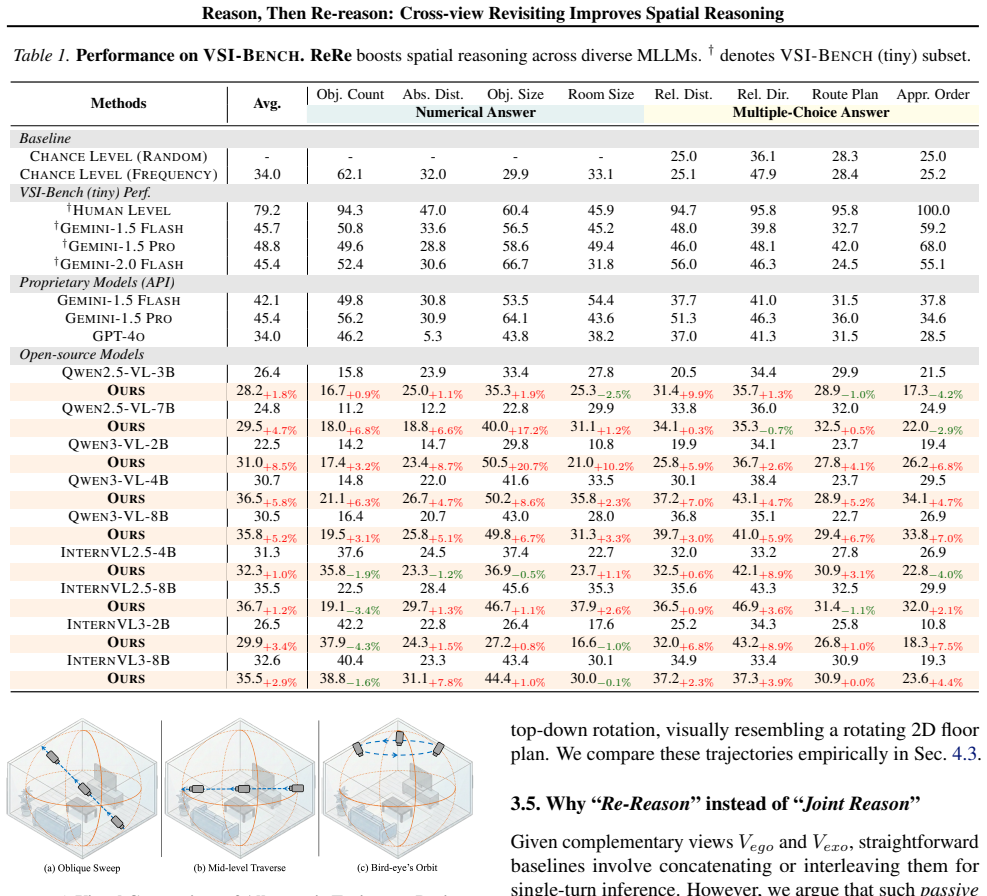
Conclusions drawn from limited video evidence remain open to revision when strategically complementary novel views, rendered from the same predicted 3D geometry, become available; feeding those views back to the same MLLM in a second inference pass produces measurable gains in spatial accuracy without any model retraining or architectural change.
What carries the argument
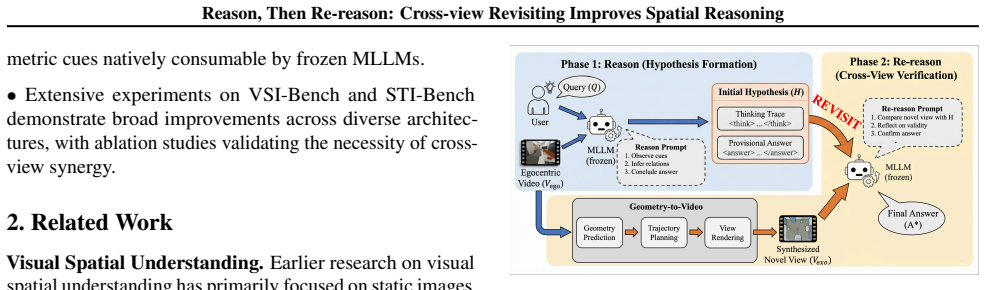
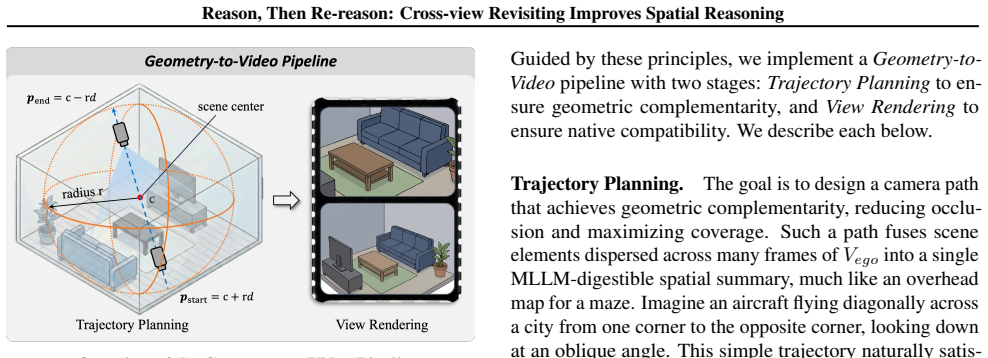
The ReRe two-phase framework whose Re-reason Phase consumes a Geometry-to-Video output that renders an elevated oblique video spanning the full scene from the initial 3D reconstruction.
If this is right
- Open-source MLLMs reach performance parity with proprietary state-of-the-art systems on the tested spatial benchmarks.
- Spatial reasoning shifts from reliance on semantic priors toward verification against additional geometric evidence.
- The same MLLM can be used for both phases without any fine-tuning or interface changes.
- The approach works for any video input that admits a usable 3D reconstruction step.
Where Pith is reading between the lines
- The same revisiting logic could be applied to other video tasks where initial evidence is incomplete, such as action anticipation or object permanence checks.
- Further gains may depend on improving the upstream 3D reconstruction quality rather than on larger language models.
- The method suggests a general inference-time pattern: generate an auxiliary representation, then let the model re-examine its own earlier output against that representation.
Load-bearing premise
The 3D geometry estimated from the original video is accurate enough that the rendered novel views supply genuine new spatial evidence rather than noise or contradictions.
What would settle it
Running the Re-reason Phase on the generated novel-view videos produces no accuracy gain or a net loss on VSI-Bench or STI-Bench relative to the single Reason Phase alone.
Figures


read the original abstract
Spatial reasoning from egocentric videos is inherently challenging because the observable evidence is constrained by the camera trajectory. Existing methods rely on single-turn inference, forcing models to resolve geometric ambiguity through semantic priors rather than verifiable evidence. We argue that spatial reasoning should be revisitable: conclusions formed under limited evidence should remain open to revision when complementary viewpoints become available. Building on this insight, we propose Reason, then Re-reason (ReRe), a training-free, inference-time framework with two phases: in the Reason Phase, an MLLM forms a spatial hypothesis from the original video; in the Re-reason Phase, it verifies or revises the hypothesis by observing a synthesized novel-view video. To enable effective cross-view revisiting, we design a Geometry-to-Video pipeline that renders strategically complementary novel views from predicted 3D geometry. These views feature an elevated, oblique perspective with scene-spanning coverage, while preserving the MLLM's native video interface without architectural modifications. Extensive evaluations on VSI-Bench and STI-Bench demonstrate that ReRe substantially boosts open-source MLLMs to rival proprietary state-of-the-art performance. Project page: https://zhenjiemao.github.io/ReRe/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Reason, then Re-reason (ReRe), a training-free inference-time framework for spatial reasoning from egocentric videos in MLLMs. It consists of a Reason Phase forming an initial spatial hypothesis from the input video, followed by a Re-reason Phase that verifies or revises the hypothesis using a synthesized novel-view video. The novel views are generated by a Geometry-to-Video pipeline that renders elevated, oblique perspectives from predicted 3D geometry. The central claim is that this cross-view revisiting substantially improves performance on VSI-Bench and STI-Bench, enabling open-source MLLMs to rival proprietary SOTA without model modifications.
Significance. If the experimental results hold and the pipeline is shown to be robust, the work would be significant as a practical, training-free method for addressing geometric ambiguity in video-based spatial reasoning. The approach preserves the MLLM's native video interface and avoids architectural changes, which are clear strengths. The emphasis on revisitable reasoning grounded in complementary viewpoints offers a falsifiable direction for improving inference-time performance on standard benchmarks.
major comments (3)
- [Abstract] Abstract: The claim that ReRe 'substantially boosts open-source MLLMs to rival proprietary state-of-the-art performance' on VSI-Bench and STI-Bench is presented without any quantitative results, specific baselines, ablation studies, or error analysis. This absence is load-bearing because the central claim cannot be evaluated for magnitude, statistical reliability, or comparison to existing methods.
- [§3] §3 (Geometry-to-Video pipeline and Re-reason Phase): The effectiveness of the re-reason phase depends on the rendered novel views supplying independent, verifiable spatial evidence rather than artifacts from upstream 3D prediction errors. No analysis, threshold experiments, or robustness tests are provided to show that the pipeline remains useful when monocular depth or structure prediction deviates from ground truth by amounts typical for open-source estimators. This directly undermines the claim that cross-view revisiting improves reasoning.
- [Evaluation sections] Evaluation sections: The manuscript references 'extensive evaluations' but supplies no details on the 3D prediction model used, how novel views are selected for complementarity, statistical significance of reported gains, or controls isolating the contribution of the Re-reason Phase versus the original video alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the manuscript would benefit from additional quantitative details in the abstract and expanded experimental analyses to better support our claims. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that ReRe 'substantially boosts open-source MLLMs to rival proprietary state-of-the-art performance' on VSI-Bench and STI-Bench is presented without any quantitative results, specific baselines, ablation studies, or error analysis. This absence is load-bearing because the central claim cannot be evaluated for magnitude, statistical reliability, or comparison to existing methods.
Authors: We agree the abstract should provide concrete quantitative support. In the revised version, we will insert specific metrics (e.g., absolute and relative gains on VSI-Bench and STI-Bench versus open-source and proprietary baselines) and a concise reference to key ablations. This directly addresses the evaluability concern without altering the core claim. revision: yes
-
Referee: [§3] §3 (Geometry-to-Video pipeline and Re-reason Phase): The effectiveness of the re-reason phase depends on the rendered novel views supplying independent, verifiable spatial evidence rather than artifacts from upstream 3D prediction errors. No analysis, threshold experiments, or robustness tests are provided to show that the pipeline remains useful when monocular depth or structure prediction deviates from ground truth by amounts typical for open-source estimators. This directly undermines the claim that cross-view revisiting improves reasoning.
Authors: We acknowledge the importance of demonstrating robustness. We will add a dedicated analysis subsection in §3 containing threshold experiments that inject controlled errors into depth and structure predictions at levels typical of open-source monocular estimators, plus robustness tests across multiple 3D predictors. These will quantify when and how the Re-reason phase remains beneficial. revision: yes
-
Referee: [Evaluation sections] Evaluation sections: The manuscript references 'extensive evaluations' but supplies no details on the 3D prediction model used, how novel views are selected for complementarity, statistical significance of reported gains, or controls isolating the contribution of the Re-reason Phase versus the original video alone.
Authors: We will expand the evaluation sections to specify the exact 3D model and hyperparameters, detail the complementarity criteria and selection procedure for novel views, report statistical significance (e.g., paired t-tests or bootstrap p-values) for all gains, and include explicit controls that isolate the Re-reason Phase contribution versus the original video. These additions will make the experimental protocol fully reproducible and transparent. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a training-free, inference-time framework (Reason Phase on original video followed by Re-reason Phase on novel views rendered via Geometry-to-Video from predicted 3D geometry) whose performance claims rest on evaluations against external public benchmarks VSI-Bench and STI-Bench. No equations, parameter fits, self-citations, or ansatzes are invoked in a load-bearing way that reduces any claimed result to the inputs by construction; the pipeline components are treated as independent external modules rather than self-referential derivations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal LLMs can natively process synthesized video inputs without architectural modifications
- domain assumption Predicted 3D geometry is accurate enough to generate complementary views that resolve spatial ambiguities
Reference graph
Works this paper leans on
-
[1]
Spacer: Reinforcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Reinforcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025
Pith/arXiv arXiv 2025
-
[2]
Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776, 2025
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776, 2025
Pith/arXiv arXiv 2025
-
[3]
Zhenyi Liao, Qingsong Xie, Yanhao Zhang, Zijian Kong, Haonan Lu, Zhenyu Yang, and Zhijie Deng. Im- proved visual-spatial reasoning via r1-zero-like train- ing.arXiv preprint arXiv:2504.00883, 2025
arXiv 2025
-
[4]
Pengteng Li, Pinhao Song, Wuyang Li, Weiyu Guo, Huizai Yao, Yijie Xu, Dugang Liu, and Hui Xiong. See&trek: Training-free spatial prompting for multimodal large language model.arXiv preprint arXiv:2509.16087, 2025
arXiv 2025
-
[5]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Ri- lyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
2025
-
[6]
Out of sight, not out of context? egocen- tric spatial reasoning in vlms across disjoint frames
Sahithya Ravi, Gabriel Herbert Sarch, Vibhav Vineet, Andrew D Wilson, and Balasaravanan Thoravi Ku- maravel. Out of sight, not out of context? egocen- tric spatial reasoning in vlms across disjoint frames. InProceedings of the 2025 Conference on Empiri- cal Methods in Natural Language Processing, pages 16146–16161, 2025
2025
-
[7]
Duo Zheng, Shijia Huang, Yanyang Li, and Liwei Wang. Learning from videos for 3d world: Enhancing mllms with 3d vision geometry priors.arXiv preprint arXiv:2505.24625, 2025
arXiv 2025
-
[8]
Video- 3d llm: Learning position-aware video representation for 3d scene understanding
Duo Zheng, Shijia Huang, and Liwei Wang. Video- 3d llm: Learning position-aware video representation for 3d scene understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8995–9006, 2025
2025
-
[9]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, An- drea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InPro- ceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 5294–5306, 2025
2025
-
[10]
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025
Pith/arXiv arXiv 2025
-
[11]
Zhongbin Guo, Jiahe Liu, Yushan Li, Wenyu Gao, Zhen Yang, Chenzhi Li, Xinyue Zhang, and Ping Jian. Beyond flatlands: Unlocking spatial intelligence by decoupling 3d reasoning from numerical regression. arXiv preprint arXiv:2511.11239, 2025
arXiv 2025
-
[12]
Xiaohu Huang, Jingjing Wu, Qunyi Xie, and Kai Han. Mllms need 3d-aware representation super- vision for scene understanding.arXiv preprint arXiv:2506.01946, 2025
arXiv 2025
-
[13]
Spatial forcing: Implicit spatial repre- sentation alignment for vision-language-action model
Fuhao Li, Wenxuan Song, Han Zhao, Jingbo Wang, Pengxiang Ding, Donglin Wang, Long Zeng, and Haoang Li. Spatial forcing: Implicit spatial repre- sentation alignment for vision-language-action model. arXiv preprint arXiv:2510.12276, 2025
arXiv 2025
-
[14]
Referitgame: Referring to objects in photographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014
2014
-
[15]
Visual spatial reasoning.Transactions of the Association for Computational Linguistics, 11:635–651, 2023
Fangyu Liu, Guy Emerson, and Nigel Collier. Visual spatial reasoning.Transactions of the Association for Computational Linguistics, 11:635–651, 2023
2023
-
[16]
Amita Kamath, Jack Hessel, and Kai-Wei Chang. What’s” up” with vision-language models? investi- gating their struggle with spatial reasoning.arXiv preprint arXiv:2310.19785, 2023. 10 Reason, Then Re-reason: Cross-view Revisiting Improves Spatial Reasoning
arXiv 2023
-
[17]
3dsrbench: A comprehensive 3d spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3dsrbench: A comprehensive 3d spatial reasoning benchmark. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 6924– 6934, 2025
2025
-
[18]
Open-vocabulary semantic segmenta- tion with frozen vision-language models
Chaofan Ma, Yuhuan Yang, Yanfeng Wang, Ya Zhang, and Weidi Xie. Open-vocabulary semantic segmenta- tion with frozen vision-language models. InBritish Machine Vision Conference (BMVC), 2022
2022
-
[19]
Safire: Saccade-fixation reiteration with mamba for referring image segmentation.Advances in Neural Information Processing Systems, 38:7122–7148, 2026
Zhenjie Mao, Yang Yuhuan, Chaofan Ma, Dongsheng Jiang, Jiangchao Yao, Ya Zhang, and Yanfeng Wang. Safire: Saccade-fixation reiteration with mamba for referring image segmentation.Advances in Neural Information Processing Systems, 38:7122–7148, 2026
2026
-
[20]
ReMamber: Referring image segmentation with mamba twister
Yuhuan Yang, Chaofan Ma, Jiangchao Yao, Zhun Zhong, Ya Zhang, and Yanfeng Wang. ReMamber: Referring image segmentation with mamba twister. In European Conference on Computer Vision (ECCV), 2024
2024
-
[21]
AttrSeg: Open- vocabulary semantic segmentation via attribute decomposition-aggregation
Chaofan Ma, Yuhuan Yang, Chen Ju, Fei Zhang, Ya Zhang, and Yanfeng Wang. AttrSeg: Open- vocabulary semantic segmentation via attribute decomposition-aggregation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[22]
Multi- modal prototypes for open-world semantic segmenta- tion.International Journal of Computer Vision (IJCV), 2024
Yuhuan Yang, Chaofan Ma, Chen Ju, Fei Zhang, Jiangchao Yao, Ya Zhang, and Yanfeng Wang. Multi- modal prototypes for open-world semantic segmenta- tion.International Journal of Computer Vision (IJCV), 2024
2024
-
[23]
Wufei Ma, Yu-Cheng Chou, Qihao Liu, Xingrui Wang, Celso de Melo, Jianwen Xie, and Alan Yuille. Spa- tialreasoner: Towards explicit and generalizable 3d spatial reasoning.arXiv preprint arXiv:2504.20024, 2025
arXiv 2025
-
[24]
Michael Ogezi and Freda Shi. Spare: Enhancing spa- tial reasoning in vision-language models with syn- thetic data.arXiv preprint arXiv:2504.20648, 2025
arXiv 2025
-
[25]
Spa- tialvlm: Endowing vision-language models with spa- tial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spa- tialvlm: Endowing vision-language models with spa- tial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14455–14465, 2024
2024
-
[26]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9777–9786, 2021
2021
-
[27]
Chen Ju, Haicheng Wang, Jinxiang Liu, Chaofan Ma, Ya Zhang, Peisen Zhao, Jianlong Chang, and Qi Tian. Constraint and union for partially-supervised temporal sentence grounding.arXiv preprint arXiv:2302.09850, 2023
arXiv 2023
-
[28]
MoMa: Modulat- ing mamba for adapting image foundation models to video recognition
Yuhuan Yang, Chaofan Ma, Zhenjie Mao, Jiangchao Yao, Ya Zhang, and Yanfeng Wang. MoMa: Modulat- ing mamba for adapting image foundation models to video recognition. InProceedings of the International Conference on Machine Learning (ICML), 2025
2025
-
[29]
Contrast-unity for partially-supervised temporal sen- tence grounding
Haicheng Wang, Chen Ju, Weixiong Lin, Chaofan Ma, Shuai Xiao, Ya Zhang, and Yanfeng Wang. Contrast-unity for partially-supervised temporal sen- tence grounding. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025
2025
-
[30]
Haoyu Zhang, Meng Liu, Zaijing Li, Haokun Wen, Weili Guan, Yaowei Wang, and Liqiang Nie. Spatial understanding from videos: Structured prompts meet simulation data.arXiv preprint arXiv:2506.03642, 2025
arXiv 2025
-
[31]
Shun Taguchi, Hideki Deguchi, Takumi Hamazaki, and Hiroyuki Sakai. Spatialprompting: Keyframe- driven zero-shot spatial reasoning with off-the-shelf multimodal large language models.arXiv preprint arXiv:2505.04911, 2025
arXiv 2025
-
[32]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023
2023
-
[33]
Geometric granularity aware pixel-to-mesh
Yue Shi, Bingbing Ni, Jinxian Liu, Dingyi Rong, Ye Qian, and Wenjun Zhang. Geometric granularity aware pixel-to-mesh. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13097–13106, October 2021
2021
-
[34]
Darf: Depth-aware generalizable neural radiance field.Displays, 88: 102996, 2025
Yue Shi, Dingyi Rong, Chang Chen, Chaofan Ma, Bingbing Ni, and Wenjun Zhang. Darf: Depth-aware generalizable neural radiance field.Displays, 88: 102996, 2025
2025
-
[35]
Mipmap-gs: Let gaussians deform with scale-specific mipmap for anti-aliasing rendering
Jiameng Li, Yue Shi, Jiezhang Cao, Bingbing Ni, Wen- jun Zhang, Kai Zhang, and Luc Van Gool. Mipmap-gs: Let gaussians deform with scale-specific mipmap for anti-aliasing rendering. In2025 International Confer- ence on 3D Vision (3DV), 2025
2025
-
[36]
Tianhao Peng, Haochen Wang, Yuanxing Zhang, Zekun Wang, Zili Wang, Gavin Chang, Jian Yang, Shihao Li, Yanghai Wang, Xintao Wang, et al. Mvu- eval: Towards multi-video understanding evaluation 11 Reason, Then Re-reason: Cross-view Revisiting Improves Spatial Reasoning for multimodal llms.arXiv preprint arXiv:2511.07250, 2025
arXiv 2025
-
[37]
Yun Li, Yiming Zhang, Tao Lin, XiangRui Liu, Wenx- iao Cai, Zheng Liu, and Bo Zhao. Sti-bench: Are mllms ready for precise spatial-temporal world under- standing?arXiv preprint arXiv:2503.23765, 2025
arXiv 2025
-
[38]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[39]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
Pith/arXiv arXiv 2025
-
[40]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding perfor- mance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
Pith/arXiv arXiv 2024
-
[41]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring ad- vanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
Pith/arXiv arXiv 2025
-
[42]
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Bur- nell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
Pith/arXiv arXiv 2024
-
[43]
Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[44]
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, et al. Spatialladder: Progressive training for spatial reasoning in vision- language models.arXiv preprint arXiv:2510.08531, 2025
arXiv 2025
-
[45]
FastVGGT: Training-free acceleration of visual ge- ometry transformer
You Shen, Zhipeng Zhang, Yansong Qu, Xiawu Zheng, Jiayi Ji, Shengchuan Zhang, and Liujuan Cao. FastVGGT: Training-free acceleration of visual ge- ometry transformer. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[46]
Zhijian Shu, Cheng Lin, Tao Xie, Wei Yin, Ben Li, Zhiyuan Pu, Weize Li, Yao Yao, Xun Cao, Xiaoyang Guo, and Xiao-Xiao Long. LiteVGGT: Boosting vanilla VGGT via geometry-aware cached token merg- ing.arXiv preprint arXiv:2512.04939, 2025
arXiv 2025
-
[47]
Deep extreme cut: From extreme points to object segmentation
Kevis-Kokitsi Maninis, Sergi Caelles, Jordi Pont- Tuset, and Luc Van Gool. Deep extreme cut: From extreme points to object segmentation. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 616–625, 2018
2018
-
[48]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, Piotr Doll´ar, and Ross Girshick. Segment anything. In Proceedings of the IEEE/CVF International Confer- ence on Computer Vision (ICCV), pages 4015–4026, 2023
2023
-
[49]
Chaofan Ma, Qisen Xu, Xiangfeng Wang, Bo Jin, Xiaoyun Zhang, Yanfeng Wang, and Ya Zhang. Boundary-aware supervoxel-level iteratively refined interactive 3D image segmentation with multi-agent re- inforcement learning.IEEE Transactions on Medical Imaging, 40(10):2563–2574, 2021
2021
-
[50]
Transforming the interactive segmen- tation for medical imaging
Wentao Liu, Chaofan Ma, Yuhuan Yang, Weidi Xie, and Ya Zhang. Transforming the interactive segmen- tation for medical imaging. InMedical Image Com- puting and Computer Assisted Intervention (MICCAI), 2022
2022
-
[51]
Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. InProceed- ings of the European Conference on Computer Vision (ECCV), 2024. 12 Reason, Then Re-reason: Cross-view Revisiting Im...
2024
-
[52]
Annotation-free audio- visual segmentation
Jinxiang Liu, Yu Wang, Chen Ju, Chaofan Ma, Ya Zhang, and Weidi Xie. Annotation-free audio- visual segmentation. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024
2024
-
[53]
Unsupervised domain adaptation via similarity-based prototypes for cross-modality segmentation
Ziyu Ye, Chen Ju, Chaofan Ma, and Xiaoyun Zhang. Unsupervised domain adaptation via similarity-based prototypes for cross-modality segmentation. InMed- ical Image Computing and Computer Assisted Inter- vention (MICCAI), 2021
2021
-
[54]
Jinxiang Liu, Chen Ju, Chaofan Ma, Yanfeng Wang, Yu Wang, and Ya Zhang. Audio-aware query-enhanced transformer for audio-visual segmentation.arXiv preprint arXiv:2307.13236, 2023
arXiv 2023
-
[55]
Open-vocabulary panoptic segmentation with text-to-image diffusion models
Jiarui Xu, Sifei Liu, Arash Vahdat, Wonmin Byeon, Xi- aolong Wang, and Shalini De Mello. Open-vocabulary panoptic segmentation with text-to-image diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2955–2966, 2023
2023
-
[56]
Chaofan Ma, Yuhuan Yang, Chen Ju, Fei Zhang, Jinxi- ang Liu, Yu Wang, Ya Zhang, and Yanfeng Wang. Dif- fusionSeg: Adapting diffusion towards unsupervised object discovery.arXiv preprint arXiv:2303.09813, 2023
arXiv 2023
-
[57]
GenMask: Adapting DiT for segmentation via direct mask generation
Yuhuan Yang, Xianwei Zhuang, Yuxuan Cai, Chaofan Ma, Shuai Bai, Jiangchao Yao, Ya Zhang, Junyang Lin, and Yanfeng Wang. GenMask: Adapting DiT for segmentation via direct mask generation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[58]
Tracking the rareness of diseases: Improving long-tail medical detection with a calibrated diffusion model
Tianjiao Zhang, Chaofan Ma, and Yanfeng Wang. Tracking the rareness of diseases: Improving long-tail medical detection with a calibrated diffusion model. Electronics, 13(23):4693, 2024
2024
-
[59]
FreeSegDiff: Annotation-free saliency segmentation with diffusion models
Chaofan Ma, Yuhuan Yang, Chen Ju, Yue Shi, Ya Zhang, and Yanfeng Wang. FreeSegDiff: Annotation-free saliency segmentation with diffusion models. InIEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2025
2025
-
[60]
Dianyi Wang, Chaofan Ma, Feng Han, Size Wu, Wei Song, Yibin Wang, Zhixiong Zhang, Tianhang Wang, Siyuan Wang, Zhongyu Wei, and Jiaqi Wang. UniReason 1.0: A unified reasoning framework for world knowledge aligned image generation and editing. arXiv preprint arXiv:2602.02437, 2026
arXiv 2026
-
[61]
Inter- leaving reasoning for better text-to-image generation
Wenxuan Huang, Shuang Chen, Zheyong Xie, Shaosheng Cao, Shixiang Tang, Yufan Shen, Qingyu Yin, Wenbo Hu, Xiaoman Wang, Yuntian Tang, Junbo Qiao, Yue Guo, Yao Hu, Zhenfei Yin, Philip Torr, Yu Cheng, Wanli Ouyang, and Shaohui Lin. Inter- leaving reasoning for better text-to-image generation. arXiv preprint arXiv:2509.06945, 2025
arXiv 2025
-
[62]
Luozheng Qin, Jia Gong, Yuqing Sun, Tianjiao Li, Mengping Yang, Xiaomeng Yang, Chao Qu, Zhiyu Tan, and Hao Li. Uni-CoT: Towards unified chain- of-thought reasoning across text and vision.arXiv preprint arXiv:2508.05606, 2025
arXiv 2025
-
[63]
Dianyi Wang, Ruihang Li, Feng Han, Chaofan Ma, Wei Song, Siyuan Wang, Yibin Wang, Yi Xin, Hongjian Liu, Zhixiong Zhang, Shengyuan Ding, Tian- hang Wang, Zhenglin Cheng, Tao Lin, Cheng Jin, Kaicheng Yu, Jingjing Chen, Wenjie Wang, Zhongyu Wei, and Jiaqi Wang. DeepGen 1.0: A lightweight unified multimodal model for advancing image gener- ation and editing.a...
arXiv 2026
-
[64]
**Observe** the video carefully and describe the key visual elements
-
[65]
**Infer** a plausible answer even if visual information is incomplete
-
[66]
Engage in an internal dialogue using expressions such as ’let me think’, ’wait’, ’Hmm’, ’oh, I see’, ’let’s break it down’, etc, or other natural language thought expressions
**Conclude** with a final answer. Engage in an internal dialogue using expressions such as ’let me think’, ’wait’, ’Hmm’, ’oh, I see’, ’let’s break it down’, etc, or other natural language thought expressions. It’s encouraged to include self-reflection or verification in the reasoning process. Provide your detailed reasoning between the <think> and </thin...
-
[67]
new views
**Compare** old vs. new views
-
[68]
If the question relates to temporal order, primarily maintain your answer from the first round
**Reflect** on whether your prior conclusion holds. If the question relates to temporal order, primarily maintain your answer from the first round
-
[69]
Follow this format strictly: <think>put your Step-by-step reasoning process here</think> <answer>put your specific answer here</answer> Rules: - Do not output text outside tags
**Confirm** your final answer. Follow this format strictly: <think>put your Step-by-step reasoning process here</think> <answer>put your specific answer here</answer> Rules: - Do not output text outside tags. - Only one final answer. - Avoid vague terms like ’around’ or ’approximately’. {Answer Format Constraint} Let’s think step by step about the compari...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.