Neuro-Inspired Inverse Learning for Planning and Control
Pith reviewed 2026-06-30 16:04 UTC · model grok-4.3
The pith
Inverse Learning optimizes full action sequences through a learned forward model to match or exceed offline RL on maze navigation tasks while using one to two orders of magnitude less inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By optimizing the entire action sequence through the forward model rather than emitting one action at a time, the learned inverse model produces smooth, goal-coherent trajectories that reach control policies closer to the analytic optimum than the policy that generated the training data.
What carries the argument
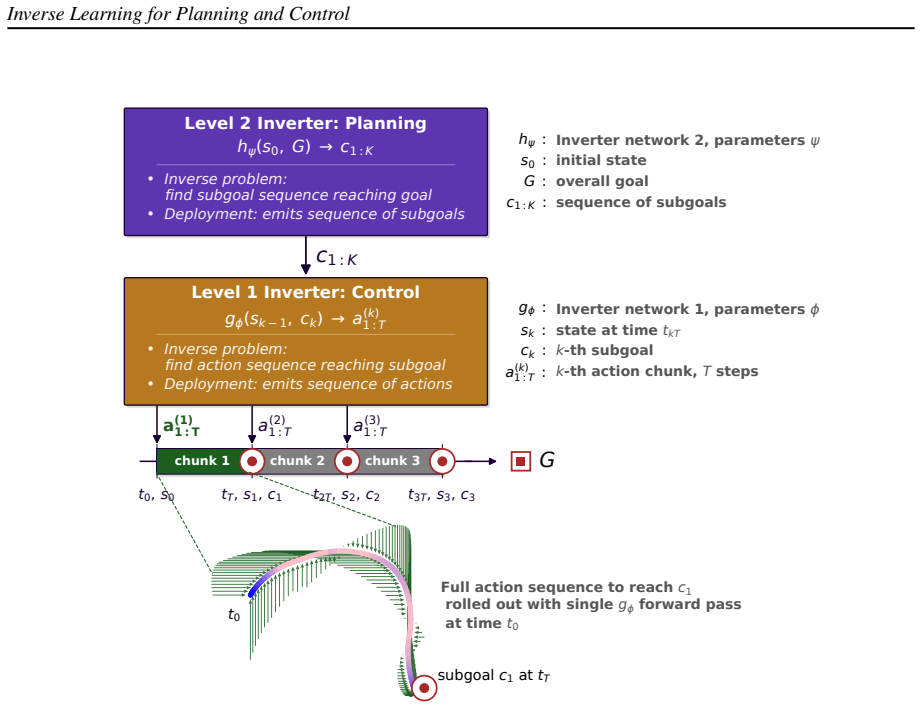
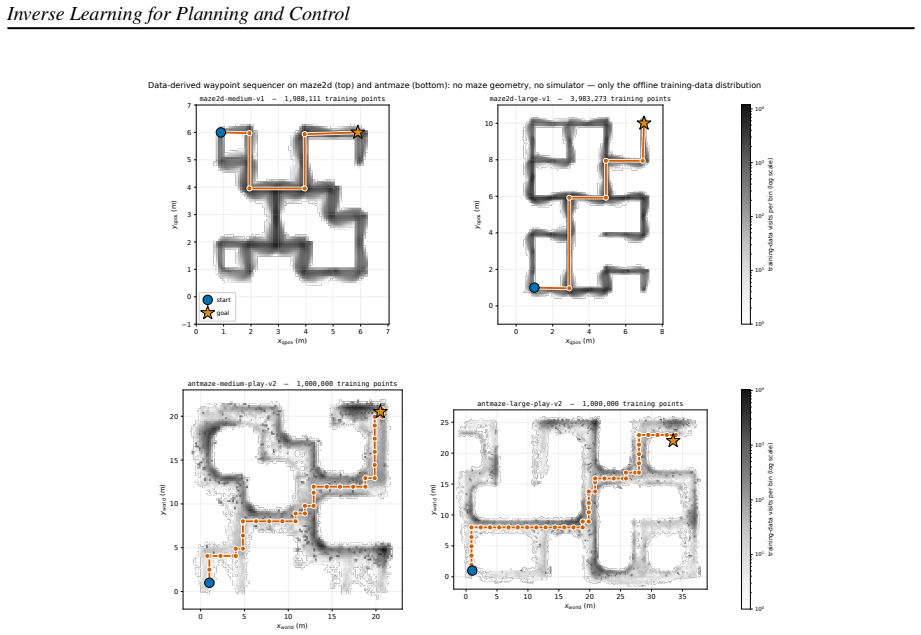
The Inverter, a learned inverse model that, given a goal and a forward model, iteratively optimizes a full T-step action sequence at test time.
If this is right
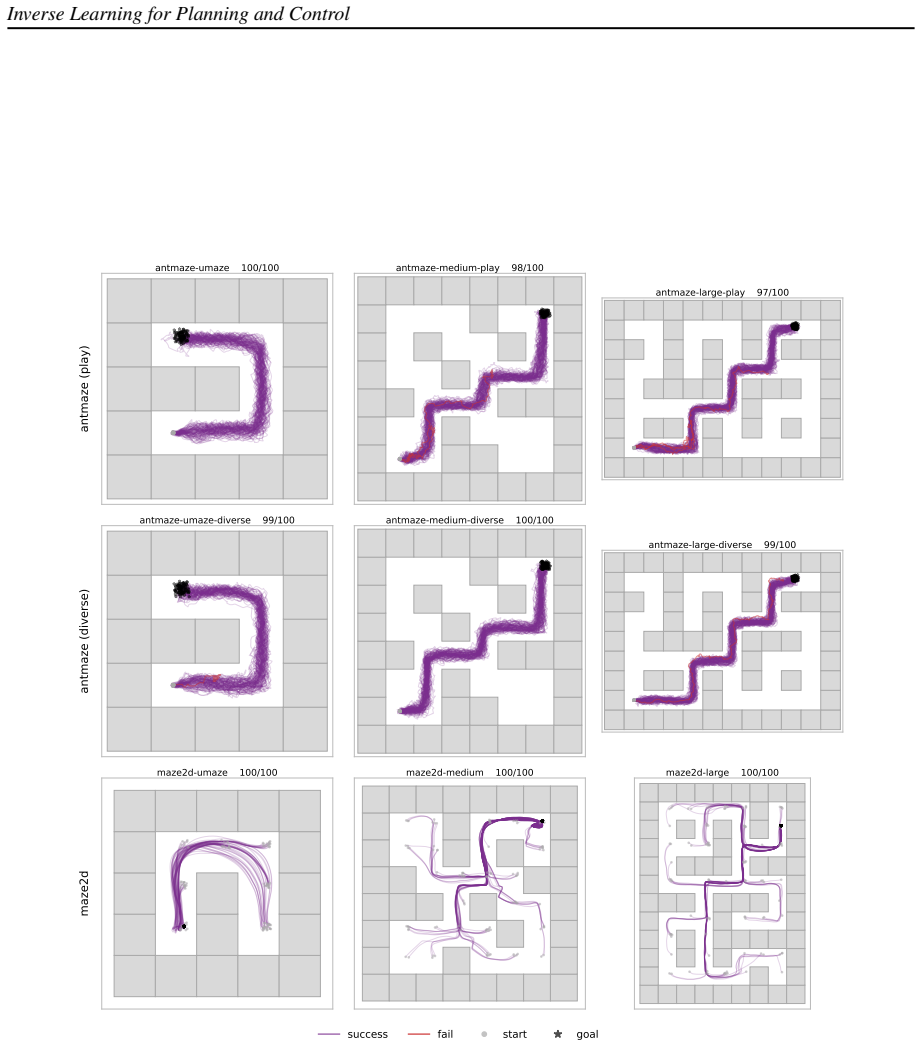
- Inverters match or beat current offline RL and diffusion planners across all nine evaluated D4RL maze environments while requiring 10-100 times less inference compute.
- Optimizing full trajectories rather than single steps yields policies that exceed the performance of the data-generating policy itself.
- Hierarchical n=2 inverter stacks extend the method to longer-horizon tasks without proportional increase in compute.
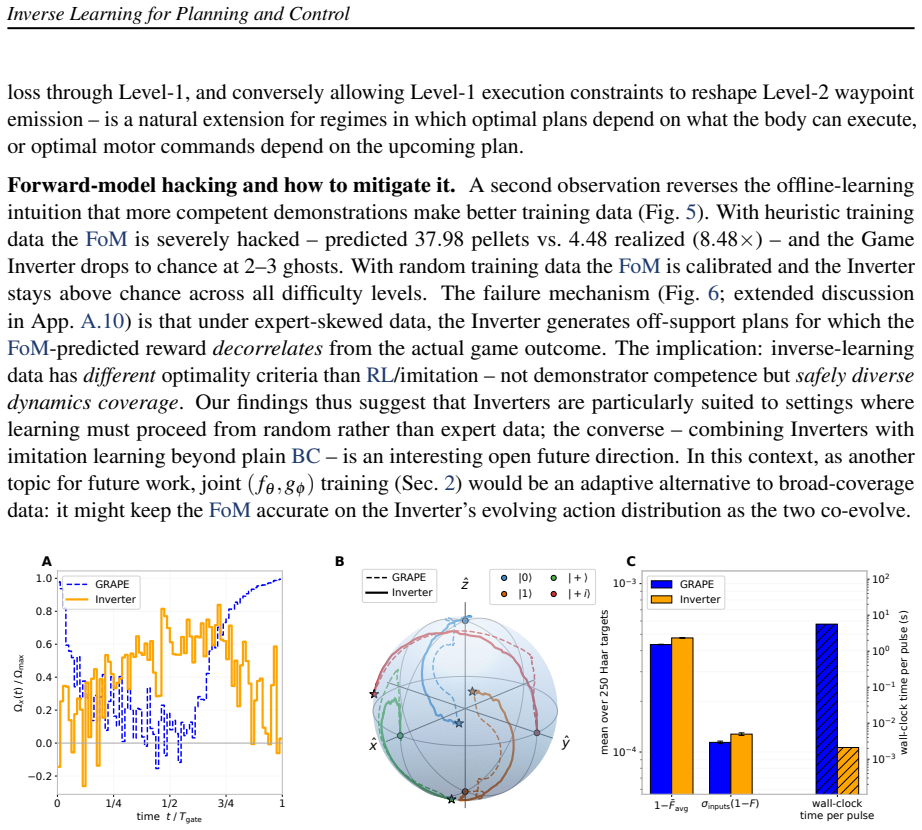
- The same inverse-learning procedure applies to continuous quantum control, reproducing GRAPE-level gate fidelity at over 1000 times lower per-gate cost.
Where Pith is reading between the lines
- The method could be tested on continuous control domains beyond mazes by replacing the analytic forward model with a learned dynamics model that covers a wider state distribution.
- Combining inverters with online model updates might reduce the need for broad offline data collection while preserving the trajectory-wide coherence benefit.
- The hierarchical stacking pattern suggests a natural route to multi-agent or multi-timescale planning by nesting inverters at different temporal resolutions.
Load-bearing premise
The forward model used in inverse optimization must accurately capture environment dynamics over the full planning horizon without exploitable errors that allow unrealistic but high-scoring trajectories.
What would settle it
Train the forward model on a narrow subset of the data and check whether inverters produce trajectories that achieve high simulated reward yet fail when executed in the real environment.
Figures

read the original abstract
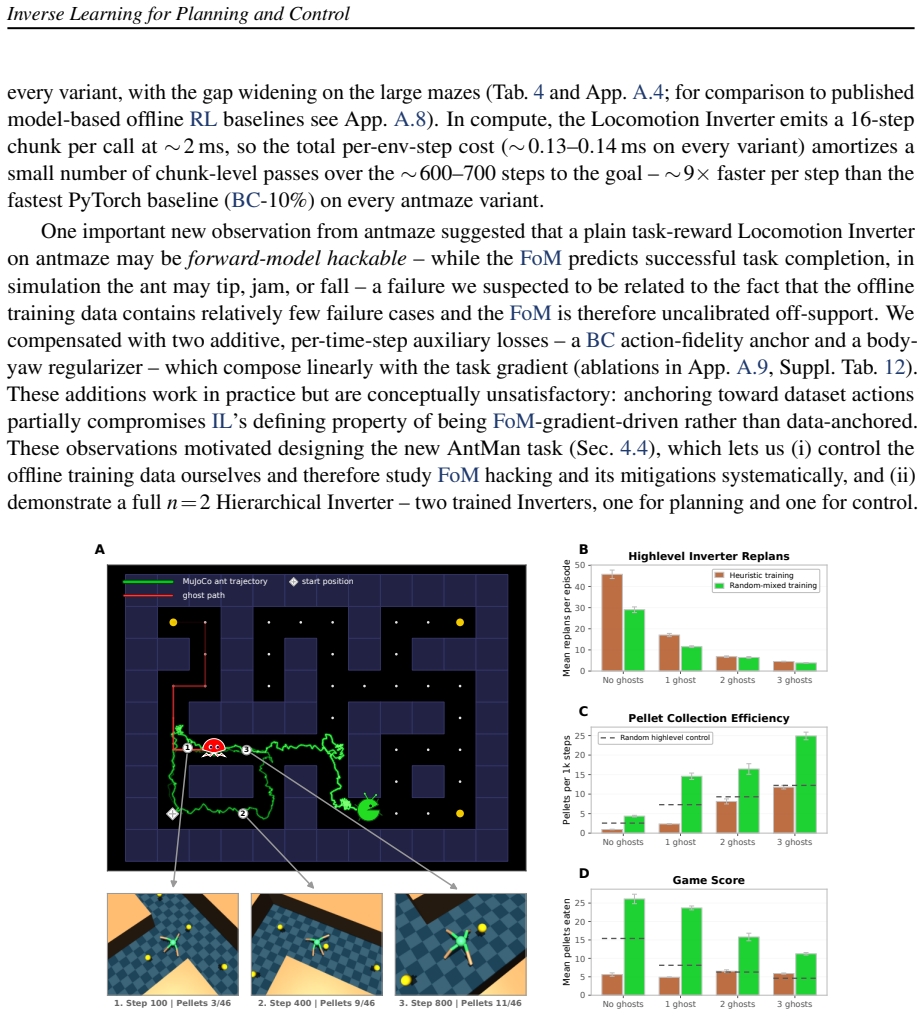
We present a neuro-inspired framework for embodied planning and control. Building on three principles that enable fast and highly effective goal-directed behavior in the mammalian brain - paired forward/inverse internal models, open-loop multi-step motor commands, and sequential, hierarchical organization of action - our Inverter framework uses learned components, trained end-to-end through Inverse Learning (IL) and supplemented where natural by analytic or algorithmic modules; we formalize IL and delineate it from supervised, reinforcement, and imitation learning. IL bridges Reinforcement Learning (RL)-style amortization, which runs in a single forward pass but emits only one action at a time, and Optimal Control (OC)-style sequence planning over whole trajectories, but with iterative test-time computation. Single Inverters or hierarchical n=2 Inverter stacks match or improve on offline-RL and diffusion-planner baselines on all 3 maze2d and 6 antmaze D4RL variants by an average of +24.2% (range -1.9% to +78.2%), at one-to-two orders of magnitude less inference compute time. Distinctively, optimizing through the Forward Model (FoM) over the entire T-step action sequence - rather than per step - lets Inverters produce smooth, goal-coherent, trajectory-wide structure and reach control policies closer to the analytic optimum than the policy underlying the training data itself. We also identify a failure mode of IL: FoM hacking under narrow training-data coverage, which we mitigate by using random training data with broader coverage. As an application example, a Pulse Inverter synthesizes arbitrary single-qubit quantum gates with fidelity matching the standard iterative numerical baseline (GRAPE), at more than 1000x lower per-gate compute time. In summary, we conclude that IL enables a versatile class of world-interfaces, especially for latency- and resource-critical embodied AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a neuro-inspired Inverter framework for embodied planning and control that uses paired forward/inverse internal models, open-loop multi-step commands, and hierarchical organization, trained via Inverse Learning (IL). It claims that single Inverters or n=2 hierarchical stacks match or exceed offline-RL and diffusion-planner baselines on all 3 maze2d and 6 antmaze D4RL tasks by +24.2% average (range -1.9% to +78.2%) at 10-100x lower inference compute, while producing smoother trajectory-wide structure; it also reports an application to single-qubit quantum gate synthesis matching GRAPE fidelity at >1000x lower compute, and identifies FoM hacking as a failure mode under narrow data coverage that is mitigated by broader random training data.
Significance. If the empirical claims hold after verification of the forward-model assumption, the work offers a distinct bridge between amortized RL policies and full-horizon optimal control, with neuro-inspired structure enabling efficient test-time optimization over entire trajectories. The quantum-control application demonstrates versatility beyond robotics benchmarks. Strengths include the explicit delineation of IL from supervised/RL/imitation learning and the identification of a concrete failure mode with a proposed mitigation.
major comments (1)
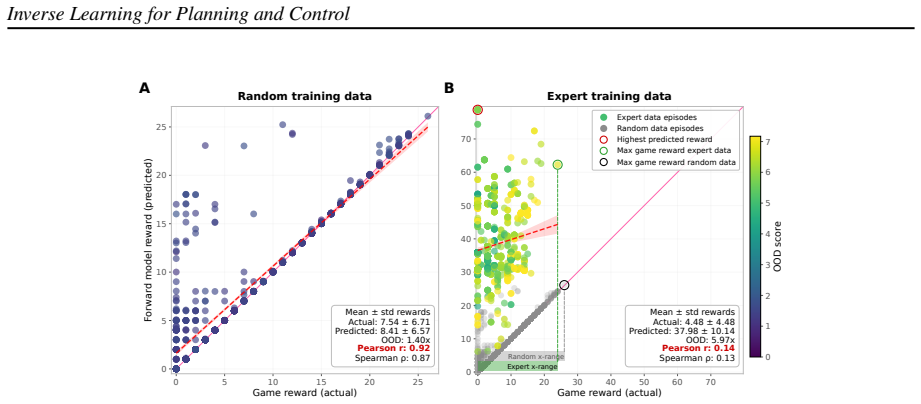
- [Abstract / D4RL experiments] Abstract and D4RL experiments section: the headline +24.2% performance claim requires that optimization through the learned Forward Model (FoM) over the full T-step horizon produces trajectories whose dynamics match the true environment (i.e., no exploitable FoM hacking). The abstract itself states that this assumption fails under narrow training-data coverage and is only mitigated by switching to broader random data; however, the manuscript provides no quantitative diagnostics (e.g., per-step or cumulative prediction error on held-out trajectories, or comparison of FoM-optimized vs. true-environment rollouts) confirming that residual discrepancies do not drive the reported gains on the specific D4RL variants.
minor comments (1)
- [Methods] Notation for the hierarchical n=2 Inverter stack and the exact definition of Inverse Learning (IL) objective should be introduced with an equation in the methods section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for highlighting the need to substantiate the Forward Model (FoM) assumption underlying the D4RL performance claims. We address this point directly below and will incorporate additional diagnostics in the revision.
read point-by-point responses
-
Referee: [Abstract / D4RL experiments] Abstract and D4RL experiments section: the headline +24.2% performance claim requires that optimization through the learned Forward Model (FoM) over the full T-step horizon produces trajectories whose dynamics match the true environment (i.e., no exploitable FoM hacking). The abstract itself states that this assumption fails under narrow training-data coverage and is only mitigated by switching to broader random data; however, the manuscript provides no quantitative diagnostics (e.g., per-step or cumulative prediction error on held-out trajectories, or comparison of FoM-optimized vs. true-environment rollouts) confirming that residual discrepancies do not drive the reported gains on the specific D4RL variants.
Authors: We agree that quantitative validation of FoM fidelity on the specific D4RL tasks is necessary to rule out exploitable discrepancies as a driver of the reported gains. The manuscript already notes that narrow data coverage induces FoM hacking and that broader random training data mitigates it; however, we did not include explicit error metrics or true-environment rollout comparisons for the D4RL variants. In the revised version we will add (i) per-step and cumulative prediction error on held-out trajectories drawn from the same D4RL datasets and (ii) side-by-side comparison of FoM-optimized trajectories versus their execution in the true environment. These additions will directly confirm that the +24.2 % average improvement (and the per-task range) arises from genuine trajectory optimization rather than model exploitation. revision: yes
Circularity Check
No circularity: empirical claims rest on benchmark results, not self-referential derivations
full rationale
The paper presents an empirical framework (Inverter stacks trained via Inverse Learning) whose headline results are performance numbers on public D4RL maze2d and antmaze tasks, compared against offline-RL and diffusion baselines. No derivation chain, uniqueness theorem, or ansatz is shown that reduces by construction to fitted inputs or self-citations; the abstract explicitly flags and mitigates the FoM-hacking failure mode rather than assuming it away. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Emanuel Todorov and Michael I. Jordan. Optimal feedback control as a theory of motor coordination.Nature Neuroscience, 5(11):1226–1235, 2002. doi: 10.1038/nn963
-
[2]
David C. Knill and Alexandre Pouget. The Bayesian brain: The role of uncertainty in neural coding and computation.Trends in Neurosciences, 27(12):712–719, 2004. doi: 10.1016/j.tins.2004.10.007
-
[3]
The free-energy principle: A unified brain theory?Nature Reviews Neuroscience, 11(2): 127–138, 2010
Karl Friston. The free-energy principle: A unified brain theory?Nature Reviews Neuroscience, 11(2): 127–138, 2010. doi: 10.1038/nrn2787
-
[4]
Gershman, Eric J
Samuel J. Gershman, Eric J. Horvitz, and Joshua B. Tenenbaum. Computational rationality: A converging paradigm for intelligence in brains, minds, and machines.Science, 349(6245):273–278, 2015. doi: 10.1126/ science.aac6076
2015
-
[5]
Resource-rational analysis: Understanding human cognition as the optimal use of limited computational resources.Behavioral and brain sciences, 43:e1, 2020
Falk Lieder and Thomas L Griffiths. Resource-rational analysis: Understanding human cognition as the optimal use of limited computational resources.Behavioral and brain sciences, 43:e1, 2020
2020
-
[6]
Homo heuristicus: Why biased minds make better inferences.Topics in cognitive science, 1(1):107–143, 2009
Gerd Gigerenzer and Henry Brighton. Homo heuristicus: Why biased minds make better inferences.Topics in cognitive science, 1(1):107–143, 2009
2009
-
[7]
Michael I. Jordan and David E. Rumelhart. Forward models: Supervised learning with a distal teacher. Cognitive Science, 16(3):307–354, 1992. doi: 10.1207/s15516709cog1603_1
-
[8]
Mitsuo Kawato. Internal models for motor control and trajectory planning.Current Opinion in Neurobiology, 9(6):718–727, 1999. doi: 10.1016/S0959-4388(99)00028-8
-
[9]
Daniel M. Wolpert and Mitsuo Kawato. Multiple paired forward and inverse models for motor control. Neural Networks, 11(7–8):1317–1329, 1998. doi: 10.1016/S0893-6080(98)00066-5
-
[10]
Ballistic movement: muscle activation and neuromuscular adaptation
E Paul Zehr and Digby G Sale. Ballistic movement: muscle activation and neuromuscular adaptation. Canadian Journal of applied physiology, 19(4):363–378, 1994
1994
-
[11]
Forward modeling allows feedback control for fast reaching movements
Michel Desmurget and Scott Grafton. Forward modeling allows feedback control for fast reaching movements. Trends in Cognitive Sciences, 4(11):423–431, 2000
2000
-
[12]
Ann M. Graybiel. The basal ganglia and chunking of action repertoires.Neurobiology of Learning and Memory, 70(1–2):119–136, 1998. doi: 10.1006/nlme.1998.3843
-
[13]
Motor skill learning between selection and execution.Trends in Cognitive Sciences, 19(4):227–233, 2015
Jörn Diedrichsen and Katja Kornysheva. Motor skill learning between selection and execution.Trends in Cognitive Sciences, 19(4):227–233, 2015
2015
-
[14]
The role of higher-order motor areas in voluntary movement as revealed by high-resolution eeg and fmri.Neuroimage, 10(6):682–694, 1999
Tonio Ball, Axel Schreiber, Bernd Feige, Michael Wagner, Carl Hermann Lücking, and Rumyana Kristeva- Feige. The role of higher-order motor areas in voluntary movement as revealed by high-resolution eeg and fmri.Neuroimage, 10(6):682–694, 1999
1999
-
[15]
Uncovering a timescale hierarchy by studying the brain in a natural context.The Journal of Neuroscience, 45(12):e2368242025, 2025
Uri Hasson. Uncovering a timescale hierarchy by studying the brain in a natural context.The Journal of Neuroscience, 45(12):e2368242025, 2025
2025
-
[16]
Pontryagin, Vladimir G
Lev S. Pontryagin, Vladimir G. Boltyansky, Revaz V . Gamkrelidze, and Evgenii F. Mishchenko.The Mathematical Theory of Optimal Processes. Interscience Publishers, New York, 1962
1962
-
[17]
Oskar Bolza.Vorlesungen über Variationsrechnung. B. G. Teubner, Leipzig and Berlin, 1909
1909
-
[18]
Bellman.Dynamic Programming
Richard E. Bellman.Dynamic Programming. Princeton University Press, 1957
1957
-
[19]
Solving inverse problems using data-driven models.Acta numerica, 28:1–174, 2019
Simon Arridge, Peter Maass, Ozan Öktem, and Carola-Bibiane Schönlieb. Solving inverse problems using data-driven models.Acta numerica, 28:1–174, 2019. 18 Inverse Learning for Planning and Control
2019
-
[20]
Deep learning techniques for inverse problems in imaging.IEEE Journal on Selected Areas in Information Theory, 1(1):39–56, 2020
Gregory Ongie, Ajil Jalal, Christopher A Metzler, Richard G Baraniuk, Alexandros G Dimakis, and Rebecca Willett. Deep learning techniques for inverse problems in imaging.IEEE Journal on Selected Areas in Information Theory, 1(1):39–56, 2020
2020
-
[21]
Learning fast approximations of sparse coding
Karol Gregor and Yann LeCun. Learning fast approximations of sparse coding. InProceedings of the 27th international conference on international conference on machine learning, pages 399–406, 2010
2010
-
[22]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Alberto Bemporad, Manfred Morari, Vivek Dua, and Efstratios N. Pistikopoulos. The explicit linear quadratic regulator for constrained systems.Automatica, 38(1):3–20, 2002. doi: 10.1016/S0005-1098(01)00174-1
-
[24]
Guided policy search
Sergey Levine and Vladlen Koltun. Guided policy search. InInternational conference on machine learning, pages 1–9. PMLR, 2013
2013
-
[25]
Combining the benefits of function approximation and trajectory optimiza- tion
Igor Mordatch and Emo Todorov. Combining the benefits of function approximation and trajectory optimiza- tion. InRobotics: Science and Systems, 2014. doi: 10.15607/RSS.2014.X.052
-
[26]
Mpc-net: A first principles guided policy search.IEEE Robotics and Automation Letters, 5(2):2897–2904, 2020
Jan Carius, Farbod Farshidian, and Marco Hutter. Mpc-net: A first principles guided policy search.IEEE Robotics and Automation Letters, 5(2):2897–2904, 2020
2020
-
[27]
Learning continuous control policies by stochastic value gradients
Nicolas Heess, Gregory Wayne, David Silver, Timothy Lillicrap, Tom Erez, and Yuval Tassa. Learning continuous control policies by stochastic value gradients. InAdvances in Neural Information Processing Systems, 2015
2015
-
[28]
Zico Kolter
Brandon Amos and J. Zico Kolter. OptNet: Differentiable optimization as a layer in neural networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), 2017
2017
-
[29]
Differentiable mpc for end-to-end planning and control.Advances in neural information processing systems, 31, 2018
Brandon Amos, Ivan Jimenez, Jacob Sacks, Byron Boots, and J Zico Kolter. Differentiable mpc for end-to-end planning and control.Advances in neural information processing systems, 31, 2018
2018
-
[30]
Making the world differentiable: On using self-supervised fully recurrent neural networks for dynamic reinforcement learning and planning in non-stationary environments
Jürgen Schmidhuber. Making the world differentiable: On using self-supervised fully recurrent neural networks for dynamic reinforcement learning and planning in non-stationary environments. Technical Report FKI-126-90, Institut für Informatik, Technische Universität München, 1990
1990
-
[31]
A path towards autonomous machine intelligence, version 0.9.2
Yann LeCun. A path towards autonomous machine intelligence, version 0.9.2. OpenReview position paper,
-
[32]
PILCO: A model-based and data-efficient approach to policy search
Marc Peter Deisenroth and Carl Edward Rasmussen. PILCO: A model-based and data-efficient approach to policy search. InProceedings of the 28th International Conference on Machine Learning, pages 465–472, 2011
2011
-
[33]
Dream to control: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. InInternational Conference on Learning Representations, 2020
2020
-
[34]
Universal planning networks: Learning generalizable representations for visuomotor control
Aravind Srinivas, Allan Jabri, Pieter Abbeel, Sergey Levine, and Chelsea Finn. Universal planning networks: Learning generalizable representations for visuomotor control. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 4732– 4741, 2018
2018
-
[35]
TD-MPC2: Scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. TD-MPC2: Scalable, robust world models for continuous control. InInternational Conference on Learning Representations, 2024
2024
-
[36]
Offline reinforcement learning as one big sequence modeling problem
Michael Janner, Qiyang Li, and Sergey Levine. Offline reinforcement learning as one big sequence modeling problem. InAdvances in Neural Information Processing Systems, volume 34, pages 1273–1286, 2021. 19 Inverse Learning for Planning and Control
2021
-
[37]
Decision Transformer: Reinforcement learning via sequence modeling
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision Transformer: Reinforcement learning via sequence modeling. InAdvances in Neural Information Processing Systems, volume 34, 2021
2021
-
[38]
Tenenbaum, and Sergey Levine
Michael Janner, Yilun Du, Joshua B. Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. InProceedings of the 39th International Conference on Machine Learning (ICML), volume 162 ofProceedings of Machine Learning Research, pages 9902–9915. PMLR, 17–23 Jul 2022
2022
-
[39]
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy P. Lillicrap, and David Silver. Mastering Atari, Go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020. doi: 10.1038/s41586-020-03051-4
work page internal anchor Pith review doi:10.1038/s41586-020-03051-4 2020
-
[40]
Vlad Sobal, Wancong Zhang, Kyunghyun Cho, Randall Balestriero, Tim G. J. Rudner, and Yann LeCun. Learning from reward-free offline data: A case for planning with latent dynamics models, 2025
2025
-
[41]
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models, 2024. URLhttps://arxiv.org/abs/2412.03572
-
[42]
Qureshi, Anthony Simeonov, Mayur J
Ahmed H. Qureshi, Anthony Simeonov, Mayur J. Bency, and Michael C. Yip. Motion planning networks. In IEEE International Conference on Robotics and Automation, pages 2118–2124, 2019. doi: 10.1109/ICRA. 2019.8793889
-
[43]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems, 2023. doi: 10.15607/RSS.2023.XIX.016
-
[44]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[45]
Sutton, Doina Precup, and Satinder Singh
Richard S. Sutton, Doina Precup, and Satinder Singh. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 112(1–2):181–211, 1999. doi: 10.1016/S0004-3702(99)00052-1
-
[46]
Hierarchical world models as visual whole-body humanoid controllers
Nicklas Hansen, Jyothir S V , Vlad Sobal, Yann LeCun, Xiaolong Wang, and Hao Su. Hierarchical world models as visual whole-body humanoid controllers. InInternational Conference on Learning Representations, 2025
2025
-
[47]
Integrated task and motion planning.Annual review of control, robotics, and autonomous systems, 4(1):265–293, 2021
Caelan Reed Garrett, Rohan Chitnis, Rachel Holladay, Beomjoon Kim, Tom Silver, Leslie Pack Kaelbling, and Tomás Lozano-Pérez. Integrated task and motion planning.Annual review of control, robotics, and autonomous systems, 4(1):265–293, 2021
2021
-
[48]
Warm start of mixed-integer programs for model predictive control of hybrid systems.IEEE Transactions on Automatic Control, 66(6):2433–2448, 2020
Tobia Marcucci and Russ Tedrake. Warm start of mixed-integer programs for model predictive control of hybrid systems.IEEE Transactions on Automatic Control, 66(6):2433–2448, 2020
2020
-
[49]
Model predictive control with signal temporal logic specifications
Vasumathi Raman, Alexandre Donzé, Mehdi Maasoumy, Richard M Murray, Alberto Sangiovanni-Vincentelli, and Sanjit A Seshia. Model predictive control with signal temporal logic specifications. In53rd IEEE Conference on Decision and Control, pages 81–87. IEEE, 2014
2014
-
[50]
Directly fine-tuning diffusion models on differen- tiable rewards
Kevin Clark, Paul Vicol, Kevin Swersky, and David Fleet. Directly fine-tuning diffusion models on differen- tiable rewards. InInternational Conference on Learning Representations, volume 2024, pages 4793–4822, 2024
2024
-
[51]
Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935, 2023
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935, 2023. 20 Inverse Learning for Planning and Control
2023
-
[52]
Fine-tuning discrete diffusion models via reward optimization with applications to dna and protein design
Chenyu Wang, Masatoshi Uehara, Yichun He, Amy Wang, Avantika Lal, Tommi Jaakkola, Sergey Levine, Aviv Regev, Hanchen Wang, and Tommaso Biancalani. Fine-tuning discrete diffusion models via reward optimization with applications to dna and protein design. InInternational Conference on Learning Represen- tations, volume 2025, pages 47871–47899, 2025
2025
-
[53]
Adjoint matching: Fine- tuning flow and diffusion generative models with memoryless stochastic optimal control
Carles Domingo i Enrich, Michal Drozdzal, Brian Karrer, and Ricky TQ Chen. Adjoint matching: Fine- tuning flow and diffusion generative models with memoryless stochastic optimal control. InInternational Conference on Learning Representations, volume 2025, pages 53791–53846, 2025
2025
-
[54]
Algorithms for inverse reinforcement learning
Andrew Y Ng, Stuart Russell, et al. Algorithms for inverse reinforcement learning. InIcml, volume 1, page 2, 2000
2000
-
[55]
CORL: Research-oriented deep offline reinforcement learning library
Denis Tarasov, Alexander Nikulin, Dmitry Akimov, Vladislav Kurenkov, and Sergey Kolesnikov. CORL: Research-oriented deep offline reinforcement learning library. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[56]
DecisionLLM: Large language models for long sequence decision exploration, 2026
Xiaowei Lv, Zhilin Zhang, Yijun Li, Yusen Huo, Siyuan Ju, Xuyan Li, Chunxiang Hong, Tianyu Wang, Yongcai Wang, Peng Sun, Chuan Yu, Jian Xu, and Bo Zheng. DecisionLLM: Large language models for long sequence decision exploration, 2026. URLhttps://arxiv.org/abs/2601.10148
-
[57]
When should we prefer offline reinforcement learning over behavioral cloning? InInternational Conference on Learning Representations, 2022
Aviral Kumar, Joey Hong, Anikait Singh, and Sergey Levine. When should we prefer offline reinforcement learning over behavioral cloning? InInternational Conference on Learning Representations, 2022
2022
-
[58]
Implicit behavioral cloning
Pete Florence, Corey Lynch, Andy Zeng, Oscar A Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. Implicit behavioral cloning. In5th Annual Conference on Robot Learning, 2021. URLhttps://openreview.net/forum?id=rif3a5NAxU6
2021
-
[59]
Paul M. Fitts. The information capacity of the human motor system in controlling the amplitude of movement. Journal of Experimental Psychology, 47(6):381–391, 1954
1954
-
[60]
E. R. F. W. Crossman and P. J. Goodeve. Feedback control of hand-movement and Fitts’ law.The Quarterly Journal of Experimental Psychology Section A, 35(2):251–278, 1983. doi: 10.1080/14640748308402133
-
[61]
David E. Meyer, Richard A. Abrams, Sylvan Kornblum, Charles E. Wright, and J. E. Keith Smith. Optimality in human motor performance: Ideal control of rapid aimed movements.Psychological Review, 95(3): 340–370, 1988. doi: 10.1037/0033-295X.95.3.340
-
[62]
Optimal control of coupled spin dynamics: design of nmr pulse sequences by gradient ascent algorithms.Journal of magnetic resonance, 172(2):296–305, 2005
Navin Khaneja, Timo Reiss, Cindie Kehlet, Thomas Schulte-Herbrüggen, and Steffen J Glaser. Optimal control of coupled spin dynamics: design of nmr pulse sequences by gradient ascent algorithms.Journal of magnetic resonance, 172(2):296–305, 2005
2005
-
[63]
Marco Dall’Ara, Martin Koppenhöfer, Florentin Reiter, Thomas Wellens, Simone Montangero, and Wal- ter Hahn. Random layers for quantum optimal control with exponential expressivity.arXiv preprint arXiv:2603.08948, 2026
-
[64]
Arash Fath Lipaei, Ebrahim Khaleghian, Selin Aslan, Gani Göral, Zidong Lin, and Özgür E Müstecaplıo˘glu. Fidelity-informed neural pulse compilation of a continuous family of quantum gates with uncertainty-margin analysis.arXiv preprint arXiv:2604.11314, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Neuroscience- inspired artificial intelligence.Neuron, 95(2):245–258, 2017
Demis Hassabis, Dharshan Kumaran, Christopher Summerfield, and Matthew Botvinick. Neuroscience- inspired artificial intelligence.Neuron, 95(2):245–258, 2017
2017
-
[66]
The hippocampus as a spatial map: preliminary evidence from unit activity in the freely-moving rat.Brain research, 1971
John O’Keefe and Jonathan Dostrovsky. The hippocampus as a spatial map: preliminary evidence from unit activity in the freely-moving rat.Brain research, 1971
1971
-
[67]
Microstructure of a spatial map in the entorhinal cortex.Nature, 436(7052):801–806, 2005
Torkel Hafting, Marianne Fyhn, Sturla Molden, May-Britt Moser, and Edvard I Moser. Microstructure of a spatial map in the entorhinal cortex.Nature, 436(7052):801–806, 2005. 21 Inverse Learning for Planning and Control
2005
-
[68]
Role for supplementary motor area cells in planning several movements ahead
Jun Tanji and Keisetsu Shima. Role for supplementary motor area cells in planning several movements ahead. Nature, 371(6496):413–416, 1994
1994
-
[69]
Combinations of muscle synergies in the construction of a natural motor behavior.Nature neuroscience, 6(3):300–308, 2003
Andrea d’Avella, Philippe Saltiel, and Emilio Bizzi. Combinations of muscle synergies in the construction of a natural motor behavior.Nature neuroscience, 6(3):300–308, 2003
2003
-
[70]
Invariant visual represen- tation by single neurons in the human brain.Nature, 435(7045):1102–1107, 2005
R Quian Quiroga, Leila Reddy, Gabriel Kreiman, Christof Koch, and Itzhak Fried. Invariant visual represen- tation by single neurons in the human brain.Nature, 435(7045):1102–1107, 2005
2005
-
[71]
Roger N. Lemon. Descending pathways in motor control.Annual Review of Neuroscience, 31:195–218,
-
[72]
doi: 10.1146/annurev.neuro.31.060407.125547
-
[73]
Jean-Alban Rathelot and Peter L. Strick. Subdivisions of primary motor cortex based on cortico-motoneuronal cells.Proceedings of the National Academy of Sciences, 106(3):918–923, 2009. doi: 10.1073/pnas. 0808362106
-
[74]
Hans-Ulrich Schnitzler and Annette Denzinger. Auditory fovea and Doppler shift compensation: Adaptations for flutter detection in echolocating bats using CF-FM signals.Journal of Comparative Physiology A, 197(5): 541–559, 2011. doi: 10.1007/s00359-010-0569-6
-
[75]
David Kleinfeld and Martin Deschênes. Neuronal basis for object location in the vibrissa scanning sensori- motor system.Neuron, 72(3):455–468, 2011. doi: 10.1016/j.neuron.2011.10.009
-
[76]
Jeheskel Shoshani, William J. Kupsky, and Gary H. Marchant. Elephant brain: Part I: Gross morphology, functions, comparative anatomy, and evolution.Brain Research Bulletin, 70(2):124–157, 2006. doi: 10.1016/j.brainresbull.2006.03.016
-
[77]
Roofline: an insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
Samuel Williams, Andrew Waterman, and David Patterson. Roofline: an insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
2009
-
[78]
Efficiently scaling transformer inference.Proceedings of machine learning and systems, 5:606–624, 2023
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference.Proceedings of machine learning and systems, 5:606–624, 2023
2023
-
[79]
Pytorch 2: Faster machine learning through dynamic python bytecode transformation and graph compilation
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael V oznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, et al. Pytorch 2: Faster machine learning through dynamic python bytecode transformation and graph compilation. InProceedings of the 29th ACM international conference on architectural support for programming lang...
2024
-
[80]
Jax: composable transforma- tions of python+ numpy programs
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, et al. Jax: composable transforma- tions of python+ numpy programs. 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.