On Safer Reinforcement Learning for Sedation and Analgesia in Intensive Care
Pith reviewed 2026-05-21 13:30 UTC · model grok-4.3
The pith
A reinforcement learning policy for ICU sedation that also targets lower mortality aligns with better survival than one focused only on pain reduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
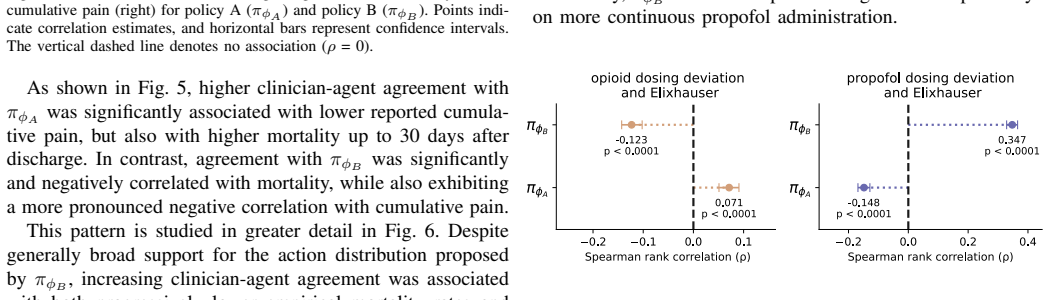
Using behavior-regularized actor-critic methods on MIMIC-IV data, the pain-only policy shows positive correlation between clinician agreement and mortality (ρ=0.119), while the joint pain-and-mortality policy shows negative correlation (ρ=-0.316); the difference arises because the two policies respond differently to high comorbidity levels.
What carries the argument
Offline behavior-regularized actor-critic model with recurrent state representations that outputs continuous medication doses, trained either to reduce pain alone or to reduce both pain and 30-day mortality.
If this is right
- Including mortality in the reward changes how the policy responds to patients with high comorbidity burdens.
- Clinician-policy agreement can serve as a retrospective proxy for safety evaluation in offline medical RL.
- Short-term pain minimization alone can produce policies whose alignment with clinicians tracks higher mortality.
- Joint optimization of immediate comfort and post-discharge survival may improve overall policy alignment with better outcomes.
Where Pith is reading between the lines
- Similar multi-objective training could be tested in other time-critical ICU decisions such as ventilator weaning.
- The observed divergence suggests that pain scores alone may be an incomplete signal for safe policy learning in critical care.
- Extending the framework to include additional long-term outcomes like organ failure rates would be a natural next measurement.
Load-bearing premise
Retrospective clinician actions recorded in the MIMIC-IV cohort form a sufficiently rich and unbiased behavioral prior so that agreement with a learned policy can be read as evidence of policy safety.
What would settle it
A prospective randomized trial that measures 30-day mortality among patients whose care follows the joint policy versus the pain-only policy or usual clinician practice.
Figures







read the original abstract
Pain management in intensive care usually involves complex trade-offs, since both inadequate and excessive treatment can compromise patient safety. Prior work on reinforcement learning for sedation and analgesia has explored how to optimize these interventions, but has not considered patient survival or partial observability. To investigate the risks of these design choices, we developed an offline deep reinforcement learning framework that suggests hourly medication doses based on recurrent state representations. Using retrospective data from 47,144 ICU stays in the MIMIC-IV database, we trained and evaluated behavior-regularized actor-critic models that prescribe continuous doses of opioids, propofol, benzodiazepines, and dexmedetomidine according to two goals: reduce pain or jointly reduce pain and 30-day post-discharge mortality. Although the two resulting policies were associated with lower pain, clinician agreement with the pain-only policy was positively correlated with mortality ($\rho$=0.119, p<0.0001), while agreement with the joint policy was negatively correlated ($\rho$=-0.316, p<0.0001). We found that such divergence arose from a different response to high levels of comorbidity. This suggests that valuing post-discharge outcomes could be critical for learning safer treatment policies, even if a short-term goal remains the primary objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops an offline deep reinforcement learning framework using behavior-regularized actor-critic models on 47,144 MIMIC-IV ICU stays to prescribe continuous doses of opioids, propofol, benzodiazepines, and dexmedetomidine. It compares a pain-reduction policy against a joint pain-and-30-day-mortality policy, both using recurrent state representations to handle partial observability. The central empirical finding is that clinician agreement with the pain-only policy correlates positively with mortality (ρ=0.119, p<0.0001) while agreement with the joint policy correlates negatively (ρ=-0.316, p<0.0001), with the divergence attributed to differential responses to high comorbidity levels. The authors conclude that incorporating post-discharge mortality into the reward is critical for learning safer sedation policies.
Significance. If the reported correlations can be shown to reflect causal differences attributable to the reward design rather than unmeasured confounding, the work would provide concrete evidence that long-term survival objectives improve the safety profile of offline RL policies for ICU sedation. The use of recurrent representations to address partial observability and the scale of the MIMIC-IV cohort are strengths that could inform subsequent studies on reward specification in medical RL.
major comments (2)
- [Abstract and Results] The central claim that the sign flip in agreement-mortality correlations demonstrates safer policies from the joint reward rests on treating clinician-policy agreement as a valid safety proxy. However, no causal identification strategy, sensitivity analysis for unmeasured confounding, or external validation cohort is provided; the policies are learned offline from the same observational trajectories, and mortality is a terminal outcome influenced by many unrecorded factors (overall care quality, discharge decisions). This issue is load-bearing for the interpretation in the abstract and results.
- [Methods (policy learning and evaluation)] The behavior-regularized actor-critic objective is described as keeping the policy close to observed actions, but the manuscript does not demonstrate that this regularization breaks the confounding between agreement and mortality. The recurrent hidden state is only partially observed, and no explicit controls for selection bias or omitted-variable bias in the comorbidity-mortality relationship are reported.
minor comments (2)
- [Abstract] The abstract states the correlations but does not specify the exact regression model or covariates used to compute ρ; adding this detail would improve reproducibility.
- [Methods] Notation for the recurrent state representation and the behavior regularization coefficient should be defined consistently between the methods and results sections.
Simulated Author's Rebuttal
We thank the referee for their insightful comments. We address the major concerns regarding causal interpretation and confounding below, and have updated the manuscript accordingly to clarify limitations and strengthen the analysis.
read point-by-point responses
-
Referee: [Abstract and Results] The central claim that the sign flip in agreement-mortality correlations demonstrates safer policies from the joint reward rests on treating clinician-policy agreement as a valid safety proxy. However, no causal identification strategy, sensitivity analysis for unmeasured confounding, or external validation cohort is provided; the policies are learned offline from the same observational trajectories, and mortality is a terminal outcome influenced by many unrecorded factors (overall care quality, discharge decisions). This issue is load-bearing for the interpretation in the abstract and results.
Authors: We concur that our findings are observational and that clinician agreement with the learned policies is used as a proxy for safety rather than establishing direct causality. The observed sign reversal in correlations indicates that the joint pain-and-mortality policy tends to disagree with clinicians in scenarios linked to higher mortality, particularly among patients with elevated comorbidity burdens. To address this, we have incorporated sensitivity analyses in the revised version, including stratification by key observed confounders such as comorbidity scores and proxies for care quality. We have also revised the abstract and results sections to frame the conclusions more cautiously as suggestive evidence requiring further validation. Unfortunately, an external validation cohort is not available in the current study, but we discuss this as a limitation. revision: partial
-
Referee: [Methods (policy learning and evaluation)] The behavior-regularized actor-critic objective is described as keeping the policy close to observed actions, but the manuscript does not demonstrate that this regularization breaks the confounding between agreement and mortality. The recurrent hidden state is only partially observed, and no explicit controls for selection bias or omitted-variable bias in the comorbidity-mortality relationship are reported.
Authors: The behavior regularization serves to anchor the policy within the distribution of observed clinician actions, thereby mitigating extrapolation risks in the offline setting. The agreement-mortality correlation is computed post-training by comparing policy recommendations to actual actions and correlating with patient outcomes. While this does not fully eliminate confounding, the differential behavior of the two policies stems directly from their reward functions, as evidenced by their contrasting handling of high-comorbidity cases. In revision, we have added regression models that control for observed comorbidities and other covariates to address omitted-variable bias, and we have clarified the partial observability of the recurrent state while noting its role in capturing temporal dynamics. revision: yes
- Complete causal identification and external validation due to the observational nature of the MIMIC-IV data.
Circularity Check
No significant circularity; empirical correlations are independent of fitted parameters
full rationale
The paper's central results consist of post-training empirical correlations (ρ=0.119 and ρ=-0.316) between clinician agreement with learned policies and mortality, computed on MIMIC-IV trajectories after offline RL training. These quantities are obtained via standard statistical association on observed data and model outputs rather than by algebraic reduction to the behavior-regularized actor-critic objective or any self-citation. No load-bearing step equates a claimed prediction to its own inputs by construction, and the derivation relies on external data benchmarks rather than internal self-definition.
Axiom & Free-Parameter Ledger
free parameters (2)
- behavior regularization coefficient
- recurrent hidden state dimension
axioms (2)
- domain assumption The ICU state can be adequately summarized by the recurrent representation of observed vital signs, labs, and prior doses.
- domain assumption Clinician agreement with a policy is a valid proxy for the policy's clinical safety.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We trained policies to prescribe opioids, propofol, benzodiazepines, and dexmedetomidine according to two goals: reduce pain or jointly reduce pain and 30-day post-discharge mortality.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
clinician agreement with the pain-only policy was positively correlated with mortality (ρ=0.119, p<0.0001), while agreement with the joint pain-and-mortality policy was negatively correlated (ρ=-0.316, p<0.0001)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Pain in the icu: a psychiatric perspective,
P. N. Azzam and A. Alam, “Pain in the icu: a psychiatric perspective,” Journal of intensive care medicine, vol. 28, no. 3, pp. 140–150, 2013
work page 2013
-
[2]
Pain management in the surgical icu patient,
J. A. Harvin and L. S. Kao, “Pain management in the surgical icu patient,”Current opinion in critical care, vol. 26, no. 6, pp. 628–633, 2020
work page 2020
-
[3]
The critical care crisis of opioid overdoses in the united states,
J. P. Stevens, M. J. Wall, L. Novack, J. Marshall, D. J. Hsu, and M. D. Howell, “The critical care crisis of opioid overdoses in the united states,” Annals of the American Thoracic Society, vol. 14, no. 12, pp. 1803–1809, 2017
work page 2017
-
[4]
Effect of analgesic treatment on the physiological consequences of acute pain,
K. S. Lewis, J. K. Whipple, K. A. Michael, and E. J. Quebbeman, “Effect of analgesic treatment on the physiological consequences of acute pain,”American Journal of Health-System Pharmacy, vol. 51, no. 12, pp. 1539–1554, 1994
work page 1994
-
[5]
N. A. Desbiens, A. W. Wu, S. K. Broste, N. S. Wenger, A. F. Connors, J. Lynn, Y . Yasui, R. S. Phillips, and W. Fulkerson, “Pain and satisfaction with pain control in seriously ill hospitalized adults: findings from the support research investigations,”Critical care medicine, vol. 24, no. 12, pp. 1953–1961, 1996
work page 1953
-
[6]
Prevalence, location, and characteristics of chronic pain in intensive care survivors,
A. K. Langerud, T. Rustøen, C. Brunborg, U. Kongsgaard, and A. Stub- haug, “Prevalence, location, and characteristics of chronic pain in intensive care survivors,”Pain Management Nursing, vol. 19, no. 4, pp. 366–376, 2018
work page 2018
-
[7]
Does the impact of the type of anesthesia on outcomes differ by patient age and comorbidity burden?
S. G. Memtsoudis, R. Rasul, S. Suzuki, J. Poeran, T. Danninger, C. Wu, M. Mazumdar, and V . V ougioukas, “Does the impact of the type of anesthesia on outcomes differ by patient age and comorbidity burden?” Regional Anesthesia & Pain Medicine, vol. 39, no. 2, pp. 112–119, 2014
work page 2014
-
[8]
Unrecognised, undertreated, pain in icu—causes, effects, and how to do better,
S. Alderson and S. Mckechnie, “Unrecognised, undertreated, pain in icu—causes, effects, and how to do better,”Open Journal of Nursing, vol. 3, no. 1, pp. 108–113, 2013
work page 2013
-
[9]
Relieving pain in america: a blueprint for transforming prevention, care, education, and research,
L. S. Simon, “Relieving pain in america: a blueprint for transforming prevention, care, education, and research,”Journal of pain & palliative care pharmacotherapy, vol. 26, no. 2, pp. 197–198, 2012
work page 2012
-
[10]
The economic costs of pain in the united states,
D. J. Gaskin and P. Richard, “The economic costs of pain in the united states,”The journal of pain, vol. 13, no. 8, pp. 715–724, 2012
work page 2012
-
[11]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
S. Levine, A. Kumar, G. Tucker, and J. Fu, “Offline reinforcement learning: Tutorial, review, and perspectives on open problems,”arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[12]
Reinforcement learning for clinical decision support in critical care: comprehensive review,
S. Liu, K. C. See, K. Y . Ngiam, L. A. Celi, X. Sun, and M. Feng, “Reinforcement learning for clinical decision support in critical care: comprehensive review,”Journal of medical Internet research, vol. 22, no. 7, p. e18477, 2020
work page 2020
-
[13]
S. Nemati, M. M. Ghassemi, and G. D. Clifford, “Optimal medication dosing from suboptimal clinical examples: A deep reinforcement learn- ing approach,” in2016 38th annual international conference of the IEEE engineering in medicine and biology society (EMBC). IEEE, 2016, pp. 2978–2981
work page 2016
-
[14]
Deep Reinforcement Learning for Sepsis Treatment
A. Raghu, M. Komorowski, I. Ahmed, L. Celi, P. Szolovits, and M. Ghassemi, “Deep reinforcement learning for sepsis treatment,”arXiv preprint arXiv:1711.09602, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Representation and Reinforcement Learning for Personalized Glycemic Control in Septic Patients
W.-H. Weng, M. Gao, Z. He, S. Yan, and P. Szolovits, “Representation and reinforcement learning for personalized glycemic control in septic patients,”arXiv preprint arXiv:1712.00654, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Electronic health records based reinforcement learning for treatment optimizing,
T. Li, Z. Wang, W. Lu, Q. Zhang, and D. Li, “Electronic health records based reinforcement learning for treatment optimizing,”Information Systems, vol. 104, p. 101878, 2022
work page 2022
-
[17]
Reinforcement learning assisted oxygen therapy for covid-19 patients under intensive care,
H. Zheng, J. Zhu, W. Xie, and J. Zhong, “Reinforcement learning assisted oxygen therapy for covid-19 patients under intensive care,”BMC medical informatics and decision making, vol. 21, no. 1, p. 350, 2021
work page 2021
-
[18]
A Reinforcement Learning Approach to Weaning of Mechanical Ventilation in Intensive Care Units
N. Prasad, L.-F. Cheng, C. Chivers, M. Draugelis, and B. E. Engelhardt, “A reinforcement learning approach to weaning of mechanical ventila- tion in intensive care units,”arXiv preprint arXiv:1704.06300, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
C. Yu, J. Liu, and H. Zhao, “Inverse reinforcement learning for intelli- gent mechanical ventilation and sedative dosing in intensive care units,” BMC medical informatics and decision making, vol. 19, no. 2, pp. 111– 120, 2019
work page 2019
-
[20]
C. Yu, G. Ren, and Y . Dong, “Supervised-actor-critic reinforcement learning for intelligent mechanical ventilation and sedative dosing in intensive care units,”BMC medical informatics and decision making, vol. 20, no. 3, pp. 1–8, 2020
work page 2020
-
[21]
D. Lopez-Martinez, P. Eschenfeldt, S. Ostvar, M. Ingram, C. Hur, and R. Picard, “Deep reinforcement learning for optimal critical care pain management with morphine using dueling double-deep q networks,” in 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 2019, pp. 3960–3963
work page 2019
-
[22]
Patient-specific sedation management via deep reinforcement learning,
N. Eghbali, T. Alhanai, and M. M. Ghassemi, “Patient-specific sedation management via deep reinforcement learning,”Frontiers in Digital Health, vol. 3, p. 608893, 2021
work page 2021
-
[23]
Reinforcement learning approach to sedation and delirium man- agement in the intensive care unit,
——, “Reinforcement learning approach to sedation and delirium man- agement in the intensive care unit,” in2023 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI), 2023, pp. 1–5
work page 2023
-
[24]
R. S. Sutton and A. G. Barto,Reinforcement learning: An introduction. MIT press, 2018
work page 2018
-
[25]
Deterministic policy gradient algorithms,
D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra, and M. Riedmiller, “Deterministic policy gradient algorithms,” inInternational conference on machine learning. Pmlr, 2014, pp. 387–395
work page 2014
-
[26]
Continuous control with deep reinforcement learning
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,”arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[27]
Off-policy deep reinforcement learning without exploration,
S. Fujimoto, D. Meger, and D. Precup, “Off-policy deep reinforcement learning without exploration,” inInternational conference on machine learning. PMLR, 2019, pp. 2052–2062
work page 2019
-
[28]
Issues in using function approximation for reinforcement learning,
S. Thrun and A. Schwartz, “Issues in using function approximation for reinforcement learning,” inProceedings of the 1993 connectionist models summer school. Psychology Press, 2014, pp. 255–263
work page 1993
-
[29]
Deep reinforcement learning with double q-learning,
H. Van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning,” inProceedings of the AAAI conference on artificial intelligence, vol. 30, no. 1, 2016
work page 2016
-
[30]
Stabilizing off- policy q-learning via bootstrapping error reduction,
A. Kumar, J. Fu, M. Soh, G. Tucker, and S. Levine, “Stabilizing off- policy q-learning via bootstrapping error reduction,”Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[31]
Conservative q-learning for offline reinforcement learning,
A. Kumar, A. Zhou, G. Tucker, and S. Levine, “Conservative q-learning for offline reinforcement learning,”Advances in Neural Information Processing Systems, vol. 33, pp. 1179–1191, 2020
work page 2020
-
[32]
Planning and acting in partially observable stochastic domains,
L. P. Kaelbling, M. L. Littman, and A. R. Cassandra, “Planning and acting in partially observable stochastic domains,”Artificial intelligence, vol. 101, no. 1-2, pp. 99–134, 1998
work page 1998
-
[33]
Mimic- iv, a freely accessible electronic health record dataset,
A. E. Johnson, L. Bulgarelli, L. Shen, A. Gayles, A. Shammout, S. Horng, T. J. Pollard, S. Hao, B. Moody, B. Gowet al., “Mimic- iv, a freely accessible electronic health record dataset,”Scientific data, vol. 10, no. 1, p. 1, 2023
work page 2023
-
[34]
A synthesis of oral morphine equivalents (ome) for opioid utilisation studies,
S. Nielsen, L. Degenhardt, B. Hoban, and N. Gisev, “A synthesis of oral morphine equivalents (ome) for opioid utilisation studies,” Pharmacoepidemiology and drug safety, vol. 25, no. 6, pp. 733–737, 2016
work page 2016
-
[35]
Propofol: a review of its use in intensive care sedation of adults,
K. McKeage and C. M. Perry, “Propofol: a review of its use in intensive care sedation of adults,”CNS drugs, vol. 17, no. 4, pp. 235–272, 2003
work page 2003
-
[36]
W. B. Cammarano, J.-F. Pittet, S. Weitz, R. M. Schlobohm, and J. D. Marks, “Acute withdrawal syndrome related to the administration of analgesic and sedative medications in adult intensive care unit patients,” Critical care medicine, vol. 26, no. 4, pp. 676–684, 1998
work page 1998
-
[37]
J. Barr, K. Zomorodi, E. J. Bertaccini, S. L. Shafer, and E. Geller, “A double-blind, randomized comparison of iv lorazepam versus midazolam for sedation of icu patients via a pharmacologic model,”The Journal of the American Society of Anesthesiologists, vol. 95, no. 2, pp. 286–298, 2001
work page 2001
-
[38]
N. Bhana, K. L. Goa, and K. J. McClellan, “Dexmedetomidine,”Drugs, vol. 59, no. 2, pp. 263–268, 2000
work page 2000
-
[39]
An extensive data processing pipeline for mimic-iv,
M. Gupta, B. Gallamoza, N. Cutrona, P. Dhakal, R. Poulain, and R. Beheshti, “An extensive data processing pipeline for mimic-iv,” in Machine learning for health. PMLR, 2022, pp. 311–325
work page 2022
-
[40]
Detecting hazardous intensive care patient episodes using real- time mortality models,
C. Hug, “Detecting hazardous intensive care patient episodes using real- time mortality models,” Ph.D. dissertation, Massachusetts Institute of Technology, 2009
work page 2009
-
[41]
Multiple imputation using chained equations: issues and guidance for practice,
I. R. White, P. Royston, and A. M. Wood, “Multiple imputation using chained equations: issues and guidance for practice,”Statistics in medicine, vol. 30, no. 4, pp. 377–399, 2011
work page 2011
-
[42]
Gradient boosting machines, a tutorial,
A. Natekin and A. Knoll, “Gradient boosting machines, a tutorial,” Frontiers in neurorobotics, vol. 7, p. 21, 2013
work page 2013
-
[43]
C. Kingsford and S. L. Salzberg, “What are decision trees?”Nature biotechnology, vol. 26, no. 9, pp. 1011–1013, 2008
work page 2008
-
[44]
Xgboost: A scalable tree boosting system,
T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,” inProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 2016, pp. 785–794
work page 2016
-
[45]
Predicting mortality of patients with acute kidney injury in the icu using xgboost model,
J. Liu, J. Wu, S. Liu, M. Li, K. Hu, and K. Li, “Predicting mortality of patients with acute kidney injury in the icu using xgboost model,”Plos one, vol. 16, no. 2, p. e0246306, 2021
work page 2021
-
[46]
On the Properties of Neural Machine Translation: Encoder-Decoder Approaches
K. Cho, B. Van Merriënboer, D. Bahdanau, and Y . Bengio, “On the properties of neural machine translation: Encoder-decoder approaches,” arXiv preprint arXiv:1409.1259, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[47]
Memory-based control with recurrent neural networks
N. Heess, J. J. Hunt, T. P. Lillicrap, and D. Silver, “Memory-based con- trol with recurrent neural networks,”arXiv preprint arXiv:1512.04455, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[48]
Addressing function approxi- mation error in actor-critic methods,
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approxi- mation error in actor-critic methods,” inInternational conference on machine learning. PMLR, 2018, pp. 1587–1596
work page 2018
-
[49]
A minimalist approach to offline reinforce- ment learning,
S. Fujimoto and S. S. Gu, “A minimalist approach to offline reinforce- ment learning,”Advances in neural information processing systems, vol. 34, pp. 20 132–20 145, 2021
work page 2021
-
[50]
B. Muellejans, T. Matthey, J. Scholpp, and M. Schill, “Sedation in the in- tensive care unit with remifentanil/propofol versus midazolam/fentanyl: a randomised, open-label, pharmacoeconomic trial,”Critical Care, vol. 10, no. 3, p. R91, 2006
work page 2006
-
[51]
F. W. Rozendaal, P. E. Spronk, F. F. Snellen, A. Schoen, A. R. van Zanten, N. A. Foudraine, P. G. Mulder, J. Bakker, and other UltiSAFE in- vestigators, “Remifentanil-propofol analgo-sedation shortens duration of ventilation and length of icu stay compared to a conventional regimen: a centre randomised, cross-over, open-label study in the netherlands,” In...
work page 2009
-
[52]
A. C. Faust, P. Rajan, L. A. Sheperd, C. A. Alvarez, P. McCorstin, and R. L. Doebele, “Impact of an analgesia-based sedation protocol on mechanically ventilated patients in a medical intensive care unit,” Anesthesia & Analgesia, vol. 123, no. 4, pp. 903–909, 2016
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.