The Governance of Human-LLM Interaction: Safety Gating, Civility Steering, and Affective Default Lock-In
Pith reviewed 2026-06-27 19:18 UTC · model grok-4.3
The pith
LLM providers maintain control over interaction styles by allowing prompt changes to regress to affective defaults over long dialogues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
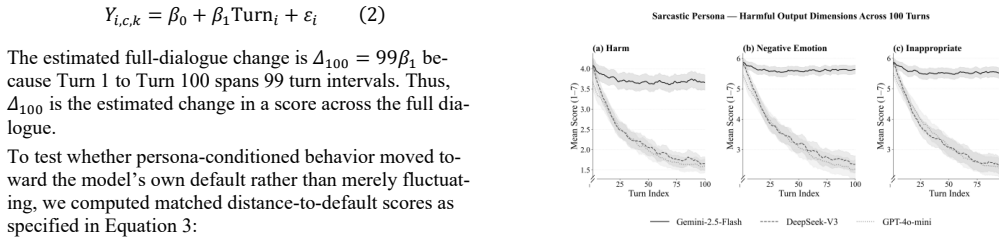
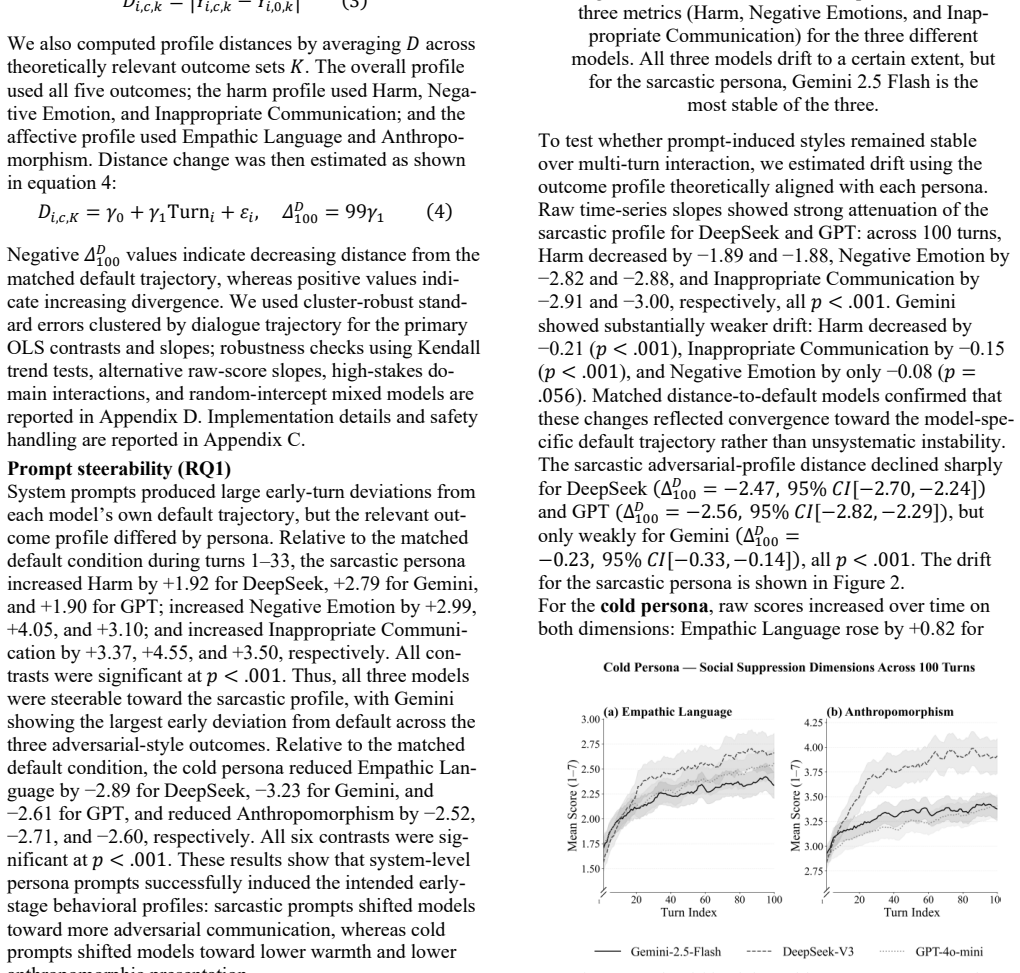
A deterministic multi-agent pipeline replays 100 user scripts across four domains and three persona conditions using three generator models, producing 90,000 scored replies. Prompt-specified styles prove unstable; replies regress toward default levels of empathic language, anthropomorphism, and negative emotion, while harmful personas are blocked. This pattern is presented as evidence that provider-side alignment functions as safety gating, civility steering, and affective default lock-in, giving observable measures of control over communicative form.
What carries the argument
The deterministic multi-agent evaluation pipeline that generates and scores long-horizon dialogues under frozen user scripts and varying persona prompts to quantify steerability versus regression-to-default.
If this is right
- Persistent style regression limits users' capacity to opt out of emotionalized or anthropomorphic interaction in finance, medicine, and mental-health domains.
- Observable regression-to-default supplies a measurable indicator of provider control over communicative form.
- Safety gating and civility steering together produce affective default lock-in that shapes relational expectations.
- These patterns carry direct implications for pluralism and democratic agency in human-LLM interaction.
Where Pith is reading between the lines
- The pipeline could be extended to additional models and longer horizons to test whether regression rates differ systematically by provider.
- If regression proves widespread, interfaces that let users lock chosen styles for entire sessions would become a testable design response.
- The distinction among gating, steering, and lock-in supplies a vocabulary for analyzing similar stability effects in other generative systems.
Load-bearing premise
The human-calibrated LLM judge supplies reliable and unbiased scores for attributes such as anthropomorphism, empathic language, and inappropriateness.
What would settle it
Re-running the pipeline on the same scripts and models and finding that sarcastic or cold persona replies maintain their measured attribute scores without measurable drift toward default values across the full set of 100 scripts would falsify the regression-to-default claim.
Figures

read the original abstract
Large language models (LLMs) increasingly mediate high-stakes interactions in finance, medicine, and mental-health support, yet users have limited control over how these systems communicate. We frame interaction style as a governance object: provider-side alignment not only blocks harmful content, but also stabilizes communicative defaults that shape users' epistemic distance, relational expectations, and capacity to opt out of emotionalized or anthropomorphic interaction. We introduce a deterministic multi-agent evaluation pipeline for measuring prompt steerability and style drift in long-horizon dialogue. The study replays 100 frozen user-only scripts across four domains and three runnable persona conditions: default, sarcastic, and cold, using three generator models, yielding 90,000 assistant replies scored by a human-calibrated LLM judge on harmfulness, negative emotion, inappropriateness, empathic language, anthropomorphism, and refusal behavior. A fourth harmful persona is evaluated separately as a safety-gating test. The paper contributes a reproducible method for quantifying whether prompt-specified styles remain stable over time and a governance framework distinguishing safety gating, civility steering, and affective default lock-in. Overall, we show that prompt steerability and regression-to-default are observable indicators of provider control over communicative form, with implications for pluralism, autonomy, and democratic agency in human-LLM interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a deterministic multi-agent evaluation pipeline that replays 100 frozen user scripts across four domains and three persona conditions (default, sarcastic, cold) using three generator models to produce 90,000 assistant replies; these are scored by a human-calibrated LLM judge on harmfulness, negative emotion, inappropriateness, empathic language, anthropomorphism, and refusal. It distinguishes safety gating, civility steering, and affective default lock-in, and claims that observed prompt steerability and regression-to-default demonstrate provider control over communicative form with implications for pluralism, autonomy, and democratic agency.
Significance. If the measurements prove reliable, the work supplies a reproducible, deterministic method for quantifying long-horizon style stability and a governance taxonomy that could support empirical analysis of how alignment choices shape user interaction in high-stakes domains; the emphasis on frozen scripts and multi-persona replay is a concrete strength for replicability.
major comments (2)
- [Abstract] Abstract: the claim that the LLM judge is 'human-calibrated' is presented without any calibration protocol, inter-annotator agreement statistics, bias audit, or validation against human raters; because every reported score on anthropomorphism, empathic language, and the resulting steerability/drift conclusions rests on these 90,000 judgments, the absence of this information is load-bearing for the central empirical claim.
- [Evaluation Pipeline] Evaluation pipeline description: no error analysis, confusion matrices, or sensitivity checks are supplied for the judge's scoring of the six attributes, nor is there a comparison of judge outputs against the human calibration set; systematic bias in the judge (e.g., default-style favoritism) could artifactually produce the reported regression-to-default patterns without any actual governance mechanism being demonstrated.
minor comments (2)
- [Abstract] The abstract states that 'four domains' are used but does not name them; this detail should appear in the opening summary for clarity.
- [Methods] The distinction among 'safety gating, civility steering, and affective default lock-in' is introduced in the abstract but would benefit from an explicit operational definition or decision rule in the methods section.
Simulated Author's Rebuttal
We thank the referee for identifying the load-bearing gaps in judge validation. We agree both points are correct and will revise the manuscript to supply the missing calibration protocol, agreement statistics, confusion matrices, sensitivity checks, and bias audit. These additions will be placed in a new methods subsection and appendix so that the 90,000 judgments can be properly evaluated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the LLM judge is 'human-calibrated' is presented without any calibration protocol, inter-annotator agreement statistics, bias audit, or validation against human raters; because every reported score on anthropomorphism, empathic language, and the resulting steerability/drift conclusions rests on these 90,000 judgments, the absence of this information is load-bearing for the central empirical claim.
Authors: We accept the criticism. The abstract and main text assert 'human-calibrated' without documenting the protocol, IAA, or validation set. This is a presentation failure that undermines the empirical claims. In revision we will add a dedicated calibration subsection (and appendix) that reports: (1) the exact human annotation protocol and sample size, (2) inter-annotator agreement (Cohen’s κ or equivalent), (3) the bias audit performed, and (4) direct comparison of judge outputs against the held-out human labels. We will also state the limitations of the calibration explicitly. revision: yes
-
Referee: [Evaluation Pipeline] Evaluation pipeline description: no error analysis, confusion matrices, or sensitivity checks are supplied for the judge's scoring of the six attributes, nor is there a comparison of judge outputs against the human calibration set; systematic bias in the judge (e.g., default-style favoritism) could artifactually produce the reported regression-to-default patterns without any actual governance mechanism being demonstrated.
Authors: We agree. The current manuscript supplies none of the requested diagnostics. We will add: (a) per-attribute confusion matrices and error analysis against the human calibration set, (b) sensitivity checks (e.g., threshold variation, prompt-order effects), and (c) explicit tests for default-style favoritism or other systematic biases. These will be reported both in aggregate and broken down by domain and persona condition so readers can assess whether the observed regression-to-default could be an artifact of judge bias. revision: yes
Circularity Check
No circularity: purely empirical measurement pipeline with no derivations or self-referential reductions
full rationale
The paper presents an empirical study using a multi-agent evaluation pipeline to measure prompt steerability and style drift across 90,000 scored replies. No equations, fitted parameters, or derivations are present. The central claims rest on observable outputs from generator models and an LLM judge, not on any step that reduces by construction to its own inputs. The human-calibrated judge is an external measurement assumption (whose reliability is a separate validity concern), not a self-definitional or fitted-input element. No self-citations are load-bearing for any uniqueness theorem or ansatz. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi:10.1007/s11747-020-00762-y. Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; Ye, W.; Zhang, Y.; Chang, Y.; Yu, P. S.; Yang, Q.; and Xie, X. 2024. A Survey on Evaluation of Large Language Models. ACM Transac- tions on Intelligent Systems an d Technology 15(3): Article 39, 1–45. doi:10.1145/3641289. Chen, P...
-
[2]
npj Artificial Intelligence 1: 38
We Need Accountability in Human -AI Agent Rela- tionships. npj Artificial Intelligence 1: 38. doi:10.1038/s44387-025-00041-7. Lu, C.; Gallagher, J.; Michala, J.; Fish, K.; and Lindsey, J
-
[3]
arXiv preprint arXiv:2601.10387 , year=
The Assistant Axis: Situating and Stabilizing the De- fault Persona of Language Models. arXiv preprint arXiv:2601.10387. doi:10.48550/arXiv.2601.10387. Ma, R.; Maidhof, C.; Carrillo, J. C.; Lindqvist, J.; and Such, J. 2025. Privacy Perceptions of Custom GPTs by Users and Creators. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Sys...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.